






hello算法
空间复杂度

-
暂存数据:用于保存算法运行过程中的各种常量、变量、对象等。
-
栈帧空间:用于保存调用函数的上下文数据。系统在每次调用函数时都会在栈顶部创建一个栈帧,函数返回后,栈帧空间会被释放。
-
指令空间:用于保存编译后的程序指令,在实际统计中通常忽略不计。
在递归函数中,需要注意统计栈帧空间.
int func() {
// 执行某些操作
return 0;
}
/* 循环 O(1) */
void loop(int n) {
for (int i = 0; i < n; i++) {
func();
}
}
/* 递归 O(n) */
void recur(int n) {
if (n == 1) return;
return recur(n - 1);
}
-
loop函数返回后释放了栈帧空间。
-
递归函数
recur()在运行过程中会同时存在 n 个未返回的recur(),从而占用 O(你) 的栈帧空间。
数据结构
-
堆是非线性的数据结构,栈是线性的数据结构
-
由于堆是动态分配内存的,所以可以用来存储非线性的数据结构,如二叉树、图等。而栈由于其先进后出的特性,适用于解决一些需要后进先出的问题,如函数调用、表达式求值等,所以它是线性的数据结构。
-
-
为什么哈希表同时包含线性数据结构和非线性数据结构?
-
从存储的角度来看,哈希表的底层是数组,其中每一个桶槽位可能包含一个值,也可能包含一个链表或一棵树。因此,哈希表可能同时包含线性数据结构(数组、链表)和非线性数据结构(树)。
-
数组
扩容数组
int *extend(int *nums,int size,int enlarge)
{
int *res = new int [size+enlarge];
for(int i=0;i<size-1,i++){
res[i]=nums[i];
}
delete[] nums;
return res;
}
数组的典型应用
数组是一种基础且常见的数据结构,既频繁应用在各类算法之中,也可用于实现各种复杂数据结构。
-
随机访问:如果我们想随机抽取一些样本,那么可以用数组存储,并生成一个随机序列,根据索引实现随机抽样。
-
排序和搜索:数组是排序和搜索算法最常用的数据结构。快速排序、归并排序、二分查找等都主要在数组上进行。
-
查找表:当需要快速查找一个元素或其对应关系时,可以使用数组作为查找表。假如我们想实现字符到 ASCII 码的映射,则可以将字符的 ASCII 码值作为索引,对应的元素存放在数组中的对应位置。
-
机器学习:神经网络中大量使用了向量、矩阵、张量之间的线性代数运算,这些数据都是以数组的形式构建的。数组是神经网络编程中最常使用的数据结构。
-
数据结构实现:数组可以用于实现栈、队列、哈希表、堆、图等数据结构。例如,图的邻接矩阵表示实际上是一个二维数组。
链表
struct Listnode{
int val;
Listnode*next;
Listnode(int x) : val(x),next(nullptr){}//构造函数
};
链表典型应用
单向链表通常用于实现栈、队列、哈希表和图等数据结构。
-
栈与队列:当插入和删除操作都在链表的一端进行时,它表现出先进后出的特性,对应栈;当插入操作在链表的一端进行,删除操作在链表的另一端进行,它表现出先进先出的特性,对应队列。
-
哈希表:链式地址是解决哈希冲突的主流方案之一,在该方案中,所有冲突的元素都会被放到一个链表中。
-
图:邻接表是表示图的一种常用方式,其中图的每个顶点都与一个链表相关联,链表中的每个元素都代表与该顶点相连的其他顶点。
双向链表常用于需要快速查找前一个和后一个元素的场景。
-
高级数据结构:比如在红黑树、B 树中,我们需要访问节点的父节点,这可以通过在节点中保存一个指向父节点的引用来实现,类似于双向链表。
-
浏览器历史:在网页浏览器中,当用户点击前进或后退按钮时,浏览器需要知道用户访问过的前一个和后一个网页。双向链表的特性使得这种操作变得简单。
-
LRU 算法:在缓存淘汰(LRU)算法中,我们需要快速找到最近最少使用的数据,以及支持快速添加和删除节点。这时候使用双向链表就非常合适。
环形链表常用于需要周期性操作的场景,比如操作系统的资源调度。
-
时间片轮转调度算法:在操作系统中,时间片轮转调度算法是一种常见的 CPU 调度算法,它需要对一组进程进行循环。每个进程被赋予一个时间片,当时间片用完时,CPU 将切换到下一个进程。这种循环操作可以通过环形链表来实现。
-
数据缓冲区:在某些数据缓冲区的实现中,也可能会使用环形链表。比如在音频、视频播放器中,数据流可能会被分成多个缓冲块并放入一个环形链表,以便实现无缝播放。
LRU算法
:LRU(Least Recently Used)算法是一种用于缓存淘汰的算法,它的基本思想是根据数据的使用情况来判断数据是否被淘汰。LRU算法将最近使用的数据放在缓存的前面,而最久未使用的数据放在缓存的末尾。 具体实现LRU算法的方式有多种,其中一种常见的方式是使用双向链表和哈希表结合的方式。 具体步骤如下:
初始化一个双向链表和一个哈希表。双向链表用于存储缓存中的数据,按照访问的时间顺序排列,链表头部是最近使用过的数据,链表尾部是最久未使用的数据。哈希表用于存储数据的键值对,键是数据的唯一标识,值是指向链表对应节点的指针。
当访问一个数据时,先在哈希表中查找是否存在该数据。如果存在,则将对应的节点从链表中摘除,并将其移动到链表的头部,表示最近使用过。如果不存在,则需要从数据源获取该数据,并将其添加到链表的头部和哈希表中。
当需要淘汰数据时,将链表尾部的节点删除,并从哈希表中删除对应的键值对。
通过这种方式,LRU算法可以保证缓存中的数据是最近使用过的,当缓存空间不足时,最久未使用的数据会被淘汰掉,从而提高缓存的命中率。 需要注意的是,实现LRU算法时需要考虑线程安全性和并发性,以及数据的同步和一致性等问题。
列表
列表类似于动态数组、
-
初始化列表
-
vector<int>nums; vector<int>nums2={1,3,2,4,5}; -
相较于数组,列表可以自由地添加与删除元素。在列表尾部添加元素的时间复杂度为 O(1) ,但插入和删除元素的效率仍与数组相同,时间复杂度为 O(n) 。
插入删除元素
-
nums.clear()//列表清空 nums.push_back(2)//在尾部添加元素 //在中间插入元素 nums.insert(nums.begin()+3, 6) //在索引三处插入元素6 //删除元素 nums.erase(nums.begin()+3)// 删除3处元素
-
遍历列表
-
count=0; for(int num:nums){ count+=num; }
拼接列表
vector<int>nums1= {6,7,8,9};
nums.insert(nums.end(),nums1.begin(),nums1.end());
列表的实现
为了加深对列表工作原理的理解,我们尝试实现一个简易版列表,包括以下三个重点设计。
-
初始容量:选取一个合理的数组初始容量。在本示例中,我们选择 10 作为初始容量。
-
数量记录:声明一个变量
size,用于记录列表当前元素数量,并随着元素插入和删除实时更新。根据此变量,我们可以定位列表尾部,以及判断是否需要扩容。 -
扩容机制:若插入元素时列表容量已满,则需要进行扩容。先根据扩容倍数创建一个更大的数组,再将当前数组的所有元素依次移动至新数组。在本示例中,我们规定每次将数组扩容至之前的 2 倍。
/* 列表类 */
class MyList {
private:
int *arr; // 数组(存储列表元素)
int arrCapacity = 10; // 列表容量
int arrSize = 0; // 列表长度(当前元素数量)
int extendRatio = 2; // 每次列表扩容的倍数
public:
/* 构造方法 */
MyList() {
arr = new int[arrCapacity];
}
/* 析构方法 */
~MyList() {
delete[] arr;
}
/* 获取列表长度(当前元素数量)*/
int size() {
return arrSize;
}
/* 获取列表容量 */
int capacity() {
return arrCapacity;
}
/* 访问元素 */
int get(int index) {
// 索引如果越界,则抛出异常,下同
if (index < 0 || index >= size())
throw out_of_range("索引越界");
return arr[index];
}
/* 更新元素 */
void set(int index, int num) {
if (index < 0 || index >= size())
throw out_of_range("索引越界");
arr[index] = num;
}
/* 在尾部添加元素 */
void add(int num) {
// 元素数量超出容量时,触发扩容机制
if (size() == capacity())
extendCapacity();
arr[size()] = num;
// 更新元素数量
arrSize++;
}
/* 在中间插入元素 */
void insert(int index, int num) {
if (index < 0 || index >= size())
throw out_of_range("索引越界");
// 元素数量超出容量时,触发扩容机制
if (size() == capacity())
extendCapacity();
// 将索引 index 以及之后的元素都向后移动一位
for (int j = size() - 1; j >= index; j--) {
arr[j + 1] = arr[j];
}
arr[index] = num;
// 更新元素数量
arrSize++;
}
/* 删除元素 */
int remove(int index) {
if (index < 0 || index >= size())
throw out_of_range("索引越界");
int num = arr[index];
// 将索引 index 之后的元素都向前移动一位
for (int j = index; j < size() - 1; j++) {
arr[j] = arr[j + 1];
}
// 更新元素数量
arrSize--;
// 返回被删除的元素
return num;
}
/* 列表扩容 */
void extendCapacity() {
// 新建一个长度为原数组 extendRatio 倍的新数组
int newCapacity = capacity() * extendRatio;
int *tmp = arr;
arr = new int[newCapacity];
// 将原数组中的所有元素复制到新数组
for (int i = 0; i < size(); i++) {
arr[i] = tmp[i];
}
// 释放内存
delete[] tmp;
arrCapacity = newCapacity;
}
/* 将列表转换为 Vector 用于打印 */
vector<int> toVector() {
// 仅转换有效长度范围内的列表元素
vector<int> vec(size());
for (int i = 0; i < size(); i++) {
vec[i] = arr[i];
}
return vec;
}
};
内存与缓存
-
数组具有更高的缓存命中率,因此它在操作效率上通常优于链表
缓存
为了尽可能达到更高的效率,缓存会采取以下数据加载机制。
-
缓存行:缓存不是单个字节地存储与加载数据,而是以缓存行为单位。相比于单个字节的传输,缓存行的传输形式更加高效。
-
预取机制:处理器会尝试预测数据访问模式(例如顺序访问、固定步长跳跃访问等),并根据特定模式将数据加载至缓存之中,从而提升命中率。
-
空间局部性:如果一个数据被访问,那么它附近的数据可能近期也会被访问。因此,缓存在加载某一数据时,也会加载其附近的数据,以提高命中率。
-
时间局部性:如果一个数据被访问,那么它在不久的将来很可能再次被访问。缓存利用这一原理,通过保留最近访问过的数据来提高命中率。
栈
//初始化栈 satck<int> stack; //元素入栈 stack.push(2); //访问栈顶元素 int top= stack.top(); //元素出栈 stack.pop(); //获取栈的长度 int size=stack.size(); //判定栈是否为空 bool empty=stack.empty();
栈的数组实现
/* 基于数组实现的栈 */
class ArrayStack {
private:
vector<int> stack;
public:
/* 获取栈的长度 */
int size() {
return stack.size();
}
/* 判断栈是否为空 */
bool isEmpty() {
return stack.size() == 0;
}
/* 入栈 */
void push(int num) {
stack.push_back(num);
}
/* 出栈 */
int pop() {
int num = top();
stack.pop_back();
return num;
}
/* 访问栈顶元素 */
int top() {
if (isEmpty())
throw out_of_range("栈为空");
return stack.back();
}
/* 返回 Vector */
vector<int> toVector() {
return stack;
}
};
队列
//初始化队列 queue<int>queue; //元素入队列 queue.push(2); //访问队首元素 int fornt=queue.front(); //元素出队列 queue.pop(); //判断队列是否为空 bool empty = queue.empty();
双向队列
//初始化双向队列 deque<int> deque; //元素入队 deque.push_bacK(2); deque.push_front(2); //访问元素 int front=deque.front(); int back= deque.back(); //元素出队 deque.pop_fornt(); deque.pop_back(); //获取双向队列的长度 int size=deque.size(); //判断双向队列是否为空 bool empty= deque.empty();
用双向列表实现双向队列
/* 双向链表节点 */
struct DoublyListNode {
int val; // 节点值
DoublyListNode *next; // 后继节点指针
DoublyListNode *prev; // 前驱节点指针
DoublyListNode(int val) : val(val), prev(nullptr), next(nullptr) {
}
};
/* 基于双向链表实现的双向队列 */
class LinkedListDeque {
private:
DoublyListNode *front, *rear; // 头节点 front ,尾节点 rear
int queSize = 0; // 双向队列的长度
public:
/* 构造方法 */
LinkedListDeque() : front(nullptr), rear(nullptr) {
}
/* 析构方法 */
~LinkedListDeque() {
// 遍历链表删除节点,释放内存
DoublyListNode *pre, *cur = front;
while (cur != nullptr) {
pre = cur;
cur = cur->next;
delete pre;
}
}
/* 获取双向队列的长度 */
int size() {
return queSize;
}
/* 判断双向队列是否为空 */
bool isEmpty() {
return size() == 0;
}
/* 入队操作 */
void push(int num, bool isFront) {
DoublyListNode *node = new DoublyListNode(num);
// 若链表为空,则令 front 和 rear 都指向 node
if (isEmpty())
front = rear = node;
// 队首入队操作
else if (isFront) {
// 将 node 添加至链表头部
front->prev = node;
node->next = front;
front = node; // 更新头节点
// 队尾入队操作
} else {
// 将 node 添加至链表尾部
rear->next = node;
node->prev = rear;
rear = node; // 更新尾节点
}
queSize++; // 更新队列长度
}
/* 队首入队 */
void pushFirst(int num) {
push(num, true);
}
/* 队尾入队 */
void pushLast(int num) {
push(num, false);
}
/* 出队操作 */
int pop(bool isFront) {
if (isEmpty())
throw out_of_range("队列为空");
int val;
// 队首出队操作
if (isFront) {
val = front->val; // 暂存头节点值
// 删除头节点
DoublyListNode *fNext = front->next;
if (fNext != nullptr) {
fNext->prev = nullptr;
front->next = nullptr;
}
delete front;
front = fNext; // 更新头节点
// 队尾出队操作
} else {
val = rear->val; // 暂存尾节点值
// 删除尾节点
DoublyListNode *rPrev = rear->prev;
if (rPrev != nullptr) {
rPrev->next = nullptr;
rear->prev = nullptr;
}
delete rear;
rear = rPrev; // 更新尾节点
}
queSize--; // 更新队列长度
return val;
}
/* 队首出队 */
int popFirst() {
return pop(true);
}
/* 队尾出队 */
int popLast() {
return pop(false);
}
/* 访问队首元素 */
int peekFirst() {
if (isEmpty())
throw out_of_range("双向队列为空");
return front->val;
}
/* 访问队尾元素 */
int peekLast() {
if (isEmpty())
throw out_of_range("双向队列为空");
return rear->val;
}
/* 返回数组用于打印 */
vector<int> toVector() {
DoublyListNode *node = front;
vector<int> res(size());
for (int i = 0; i < res.size(); i++) {
res[i] = node->val;
node = node->next;
}
return res;
}
};
基于循环数组实现的双向队列
/* 基于环形数组实现的双向队列 */
class ArrayDeque {
private:
vector<int> nums; // 用于存储双向队列元素的数组
int front; // 队首指针,指向队首元素
int queSize; // 双向队列长度
public:
/* 构造方法 */
ArrayDeque(int capacity) {
nums.resize(capacity);
front = queSize = 0;
}
/* 获取双向队列的容量 */
int capacity() {
return nums.size();
}
/* 获取双向队列的长度 */
int size() {
return queSize;
}
/* 判断双向队列是否为空 */
bool isEmpty() {
return queSize == 0;
}
/* 计算环形数组索引 */
int index(int i) {
// 通过取余操作实现数组首尾相连
// 当 i 越过数组尾部后,回到头部
// 当 i 越过数组头部后,回到尾部
return (i + capacity()) % capacity();
}
/* 队首入队 */
void pushFirst(int num) {
if (queSize == capacity()) {
cout << "双向队列已满" << endl;
return;
}
// 队首指针向左移动一位
// 通过取余操作实现 front 越过数组头部后回到尾部
front = index(front - 1);
// 将 num 添加至队首
nums[front] = num;
queSize++;
}
/* 队尾入队 */
void pushLast(int num) {
if (queSize == capacity()) {
cout << "双向队列已满" << endl;
return;
}
// 计算队尾指针,指向队尾索引 + 1
int rear = index(front + queSize);
// 将 num 添加至队尾
nums[rear] = num;
queSize++;
}
/* 队首出队 */
int popFirst() {
int num = peekFirst();
// 队首指针向后移动一位
front = index(front + 1);
queSize--;
return num;
}
/* 队尾出队 */
int popLast() {
int num = peekLast();
queSize--;
return num;
}
/* 访问队首元素 */
int peekFirst() {
if (isEmpty())
throw out_of_range("双向队列为空");
return nums[front];
}
/* 访问队尾元素 */
int peekLast() {
if (isEmpty())
throw out_of_range("双向队列为空");
// 计算尾元素索引
int last = index(front + queSize - 1);
return nums[last];
}
/* 返回数组用于打印 */
vector<int> toVector() {
// 仅转换有效长度范围内的列表元素
vector<int> res(queSize);
for (int i = 0, j = front; i < queSize; i++, j++) {
res[i] = nums[index(j)];
}
return res;
}
};
哈希表
-
「哈希表 hash table」,又称「散列表」,它通过建立键
key与值value之间的映射,实现高效的元素查询。具体而言,我们向哈希表中输入一个键key,则可以在 O(1) 时间内获取对应的值value。
//初始化哈希表 unordered_map<int, string>map; //添加操作 //在哈希表中添加键值对 map[12836] = "小哈"; map[15937] = "小罗"; //查询操作 string name= map[15937]; //删除操作 map.erase(10583);
哈希表的遍历
/* 遍历哈希表 */
// 遍历键值对 key->value
for (auto kv: map) {
cout << kv.first << " -> " << kv.second << endl;
}
// 使用迭代器遍历 key->value
for (auto iter = map.begin(); iter != map.end(); iter++) {
cout << iter->first << "->" << iter->second << endl;
}
换句话说,输入一个 key ,我们可以通过哈希函数得到该 key 对应的键值对在数组中的存储位置。
输入一个 key ,哈希函数的计算过程分为以下两步。
-
通过某种哈希算法
hash()计算得到哈希值。 -
将哈希值对桶数量(数组长度)
capacity取模,从而获取该key对应的数组索引index。
index = hash(key) % capacity
随后,我们就可以利用 index 在哈希表中访问对应的桶,从而获取 value 。
-
「负载因子 load factor」是哈希表的一个重要概念,其定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度,也常作为哈希表扩容的触发条件。例如在 Java 中,当负载因子超过 0.75 时,系统会将哈希表扩容至原先的 2 倍。
哈希冲突
-
哈希表的结构改良方法主要包括“链式地址”和“开放寻址”。
链式地址的哈希表
-
值得注意的是,当链表很长时,查询效率 O(n) 很差。此时可以将链表转换为“AVL 树”或“红黑树”,从而将查询操作的时间复杂度优化至 O(logn) 。
开发地址
-
「开放寻址 open addressing」不引入额外的数据结构,而是通过“多次探测”来处理哈希冲突,探测方式主要包括线性探测、平方探测和多次哈希等。
线性探测¶
线性探测采用固定步长的线性搜索来进行探测,其操作方法与普通哈希表有所不同。
-
插入元素:通过哈希函数计算桶索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为 1 ),直至找到空桶,将元素插入其中。
-
查找元素:若发现哈希冲突,则使用相同步长向后进行线性遍历,直到找到对应元素,返回
value即可;如果遇到空桶,说明目标元素不在哈希表中,返回None。
-
然而,线性探测容易产生“聚集现象”。具体来说,数组中连续被占用的位置越长,这些连续位置发生哈希冲突的可能性越大,从而进一步促使该位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
值得注意的是,我们不能在开放寻址哈希表中直接删除元素。这是因为删除元素会在数组内产生一个空桶
None,而当查询元素时,线性探测到该空桶就会返回,因此在该空桶之下的元素都无法再被访问到,程序可能误判这些元素不存在 -
为了解决该问题,我们可以采用「懒删除 lazy deletion」机制:它不直接从哈希表中移除元素,而是利用一个常量
TOMBSTONE来标记这个桶。在该机制下,None和TOMBSTONE都代表空桶,都可以放置键值对。但不同的是,线性探测到TOMBSTONE时应该继续遍历,因为其之下可能还存在键值对。然而,懒删除可能会加速哈希表的性能退化。这是因为每次删除操作都会产生一个删除标记,随着
TOMBSTONE的增加,搜索时间也会增加,因为线性探测可能需要跳过多个TOMBSTONE才能找到目标元素。为此,考虑在线性探测中记录遇到的首个
TOMBSTONE的索引,并将搜索到的目标元素与该TOMBSTONE交换位置。这样做的好处是当每次查询或添加元素时,元素会被移动至距离理想位置(探测起始点)更近的桶,从而优化查询效率。各种编程语言采取了不同的哈希表实现策略,下面举几个例子。
Python 采用开放寻址。字典
dict使用伪随机数进行探测。Java 采用链式地址。自 JDK 1.8 以来,当
HashMap内数组长度达到 64 且链表长度达到 8 时,链表会转换为红黑树以提升查找性能。Go 采用链式地址。Go 规定每个桶最多存储 8 个键值对,超出容量则连接一个溢出桶;当溢出桶过多时,会执行一次特殊的等量扩容操作,以确保性能。
哈希算法
-
哈希算法的设计是一个需要考虑许多因素的复杂问题。然而对于某些要求不高的场景,我们也能设计一些简单的哈希算法。
-
加法哈希:对输入的每个字符的 ASCII 码进行相加,将得到的总和作为哈希值。
-
乘法哈希:利用乘法的不相关性,每轮乘以一个常数,将各个字符的 ASCII 码累积到哈希值中。
-
异或哈希:将输入数据的每个元素通过异或操作累积到一个哈希值中。
-
旋转哈希:将每个字符的 ASCII 码累积到一个哈希值中,每次累积之前都会对哈希值进行旋转操作。
-
使用大质数作为模数,可以最大化地保证哈希值的均匀分布。因为质数不与其他数字存在公约数,可以减少因取模操作而产生的周期性模式,从而避免哈希冲突。
值得说明的是,如果能够保证 key 是随机均匀分布的,那么选择质数或者合数作为模数都可以,它们都能输出均匀分布的哈希值。而当 key 的分布存在某种周期性时,对合数取模更容易出现聚集现象。
常见的哈希算法
在实际中,我们通常会用一些标准哈希算法,例如 MD5、SHA-1、SHA-2 和 SHA-3 等。它们可以将任意长度的输入数据映射到恒定长度的哈希值。
-
MD5 和 SHA-1 已多次被成功攻击,因此它们被各类安全应用弃用。
-
SHA-2 系列中的 SHA-256 是最安全的哈希算法之一,仍未出现成功的攻击案例,因此常用在各类安全应用与协议中。
-
SHA-3 相较 SHA-2 的实现开销更低、计算效率更高,但目前使用覆盖度不如 SHA-2 系列。
表 6-2 常见的哈希算法
| MD5 | SHA-1 | SHA-2 | SHA-3 | |
|---|---|---|---|---|
| 推出时间 | 1992 | 1995 | 2002 | 2008 |
| 输出长度 | 128 bit | 160 bit | 256/512 bit | 224/256/384/512 bit |
| 哈希冲突 | 较多 | 较多 | 很少 | 很少 |
| 安全等级 | 低,已被成功攻击 | 低,已被成功攻击 | 高 | 高 |
| 应用 | 已被弃用,仍用于数据完整性检查 | 已被弃用 | 加密货币交易验证、数字签名等 | 可用于替代 SHA-2 |
int num = 3; size_t hashNum = hash<int>()(num); // 整数 3 的哈希值为 3 bool bol = true; size_t hashBol = hash<bool>()(bol); // 布尔量 1 的哈希值为 1 double dec = 3.14159; size_t hashDec = hash<double>()(dec); // 小数 3.14159 的哈希值为 4614256650576692846 string str = "Hello 算法"; size_t hashStr = hash<string>()(str); // 字符串“Hello 算法”的哈希值为 15466937326284535026 // 在 C++ 中,内置 std:hash() 仅提供基本数据类型的哈希值计算 // 数组、对象的哈希值计算需要自行实现
二叉树
struct TreeNode{
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x): val(x),left(nullptr),right(nullptr){}
};
-
二叉树的「高度 height」:从根节点到最远叶节点所经过的边的数量。
-
节点的「深度 depth」:从根节点到该节点所经过的边的数量。
-
节点的「高度 height」:从距离该节点最远的叶节点到该节点所经过的边的数量。
二叉搜索树
-
插入节点
-
查找插入位置:与查找操作相似,从根节点出发,根据当前节点值和
num的大小关系循环向下搜索,直到越过叶节点(遍历至None)时跳出循环。 -
在该位置插入节点:初始化节点
num,将该节点置于None的位置。
注意:
-
二叉搜索树不允许存在重复节点,否则将违反其定义。因此,若待插入节点在树中已存在,则不执行插入,直接返回。
-
为了实现插入节点,我们需要借助节点
pre保存上一轮循环的节点。这样在遍历至None时,我们可以获取到其父节点,从而完成节点插入操作。
/* 插入节点 */
void insert(int num){
// 若树为空,则初始化根节点
if(root== nullptr){
root = new TreeNode(num);
return;
}
TreedNode *cur=root,*pre=nullptr;
// 循环查找,越过叶节点后跳出
while(cur!=nullptr){
// 找到重复节点,直接返回
if(cur->val=num)
return;
pre=cur;
// 插入位置在 cur 的右子树中
if(cur->val<num){
cur=cur->right;
}
// 插入位置在 cur 的左子树中
else
cur=cur->left;
}
// 插入节点
TreedNode *node=new TreedNode(num);
if(pre->val<num)
pre->right=node;
else
pre->left=node;
}
与查找节点相同,插入节点使用 O(logn) 时间。
删除节点
-
当待删除节点的度为 0 时,表示该节点是叶节点,可以直接删除。
-
当待删除节点的度为 1 时,将待删除节点替换为其子节点即可。
-
当待删除节点的度为 2 时,我们无法直接删除它,而需要使用一个节点替换该节点。由于要保持二叉搜索树“左子树 < 根节点 < 右子树”的性质,因此这个节点可以是右子树的最小节点或左子树的最大节点。
假设我们选择右子树的最小节点(中序遍历的下一个节点)
-
找到待删除节点在“中序遍历序列”中的下一个节点,记为
tmp。 -
用
tmp的值覆盖待删除节点的值,并在树中递归删除节点tmp。
-
/* 删除节点 */
void remove(int num) {
// 若树为空,直接提前返回
if (root == nullptr)
return;
TreeNode *cur = root, *pre = nullptr;
// 循环查找,越过叶节点后跳出
while (cur != nullptr) {
// 找到待删除节点,跳出循环
if (cur->val == num)
break;
pre = cur;
// 待删除节点在 cur 的右子树中
if (cur->val < num)
cur = cur->right;
// 待删除节点在 cur 的左子树中
else
cur = cur->left;
}
// 若无待删除节点,则直接返回
if (cur == nullptr)
return;
// 子节点数量 = 0 or 1
if (cur->left == nullptr || cur->right == nullptr) {
// 当子节点数量 = 0 / 1 时, child = nullptr / 该子节点
TreeNode *child = cur->left != nullptr ? cur->left : cur->right;
// 删除节点 cur
if (cur != root) {
if (pre->left == cur)
pre->left = child;
else
pre->right = child;
} else {
// 若删除节点为根节点,则重新指定根节点
root = child;
}
// 释放内存
delete cur;
}
// 子节点数量 = 2
else {
// 获取中序遍历中 cur 的下一个节点
TreeNode *tmp = cur->right;
while (tmp->left != nullptr) {
tmp = tmp->left;
}
int tmpVal = tmp->val;
// 递归删除节点 tmp
remove(tmp->val);
// 用 tmp 覆盖 cur
cur->val = tmpVal;
}
}
AVL树
AVL树平衡二叉树,
//AVL树节点类
struct TreeNode{
int val{}; //节点值
int heigjt = 0; //节点高度
TreeNode *left{};
TreeNode *right{};
TreeNode() = default;
explicit TreeNode(int x) : val(x){}
}
/* 获取节点高度 */
int height(TreeNode *node) {
// 空节点高度为 -1 ,叶节点高度为 0
return node == nullptr ? -1 : node->height;
}
/* 更新节点高度 */
void updateHeight(TreeNode *node) {
// 节点高度等于最高子树高度 + 1
node->height = max(height(node->left), height(node->right)) + 1;
}
-
“节点高度”是指从该节点到它的最远叶节点的距离,即所经过的“边”的数量。需要特别注意的是,叶节点的高度为 0 ,而空节点的高度为 −1 。我们将创建两个工具函数,分别用于获取和更新节点的高度:
节点平衡因子
-
节点的「平衡因子 balance factor」定义为节点左子树的高度减去右子树的高度,同时规定空节点的平衡因子为 0 。
/* 获取平衡因子 */
int balanceFactor(TreeNode *node) {
// 空节点平衡因子为 0
if (node == nullptr)
return 0;
// 节点平衡因子 = 左子树高度 - 右子树高度
return height(node->left) - height(node->right);
}
AVL树旋转
AVL 树的特点在于“旋转”操作,它能够在不影响二叉树的中序遍历序列的前提下,使失衡节点重新恢复平衡。换句话说,旋转操作既能保持“二叉搜索树”的性质,也能使树重新变为“平衡二叉树”。
我们将平衡因子绝对值 >1 的节点称为“失衡节点”。根据节点失衡情况的不同,旋转操作分为四种:右旋、左旋、先右旋后左旋、先左旋后右旋。
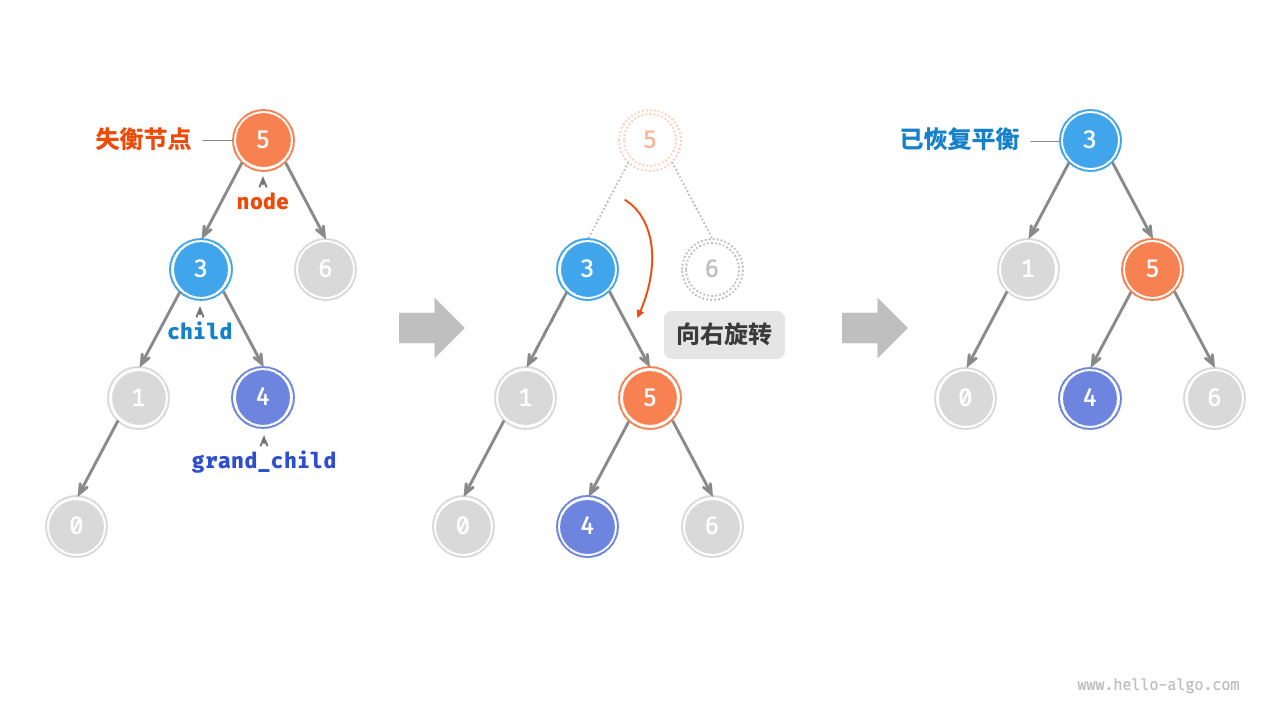
右旋
如图 7-27 所示,当节点 child 有右子节点(记为 grand_child )时,需要在右旋中添加一步:将 grand_child 作为 node 的左子节点。
/* 右旋操作 */
TreeNode *rightRotate(TreeNode *node) {
TreeNode *child = node->left;
TreeNode *grandChild = child->right;
// 以 child 为原点,将 node 向右旋转
child->right = node;
node->left = grandChild;
// 更新节点高度
updateHeight(node);
updateHeight(child);
// 返回旋转后子树的根节点
return child;
}
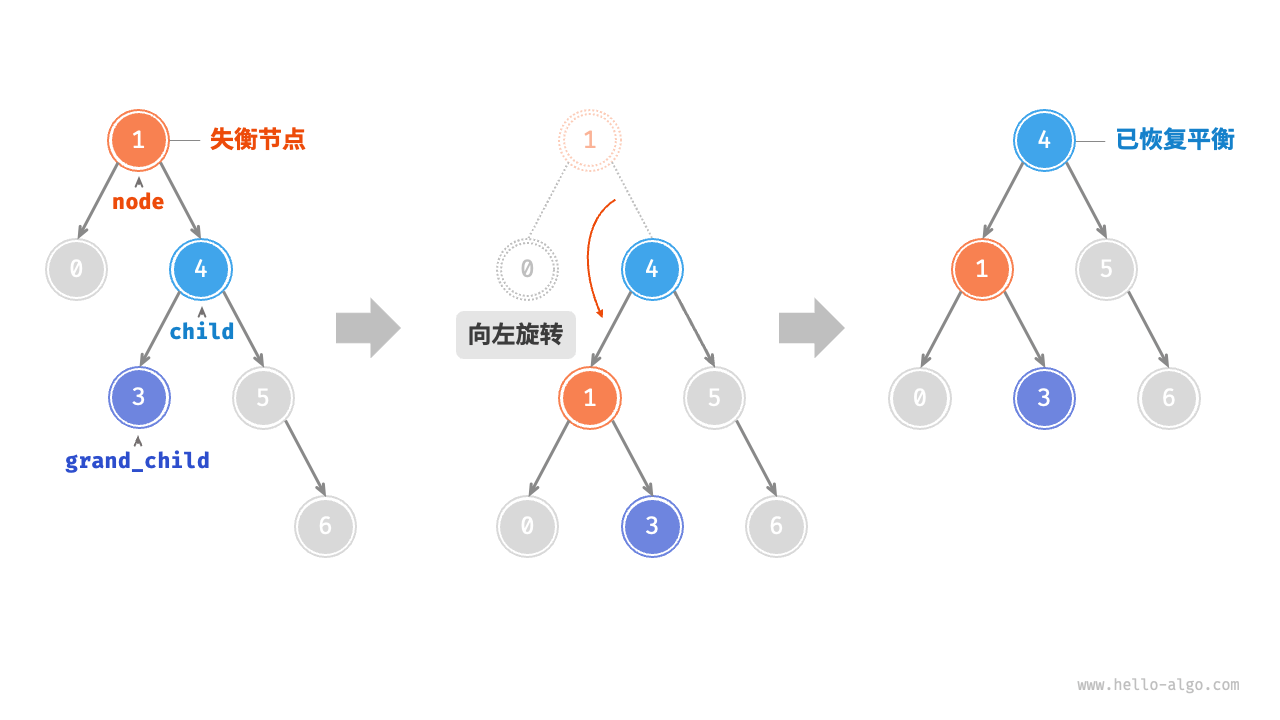
左旋
-
同理,如图 7-29 所示,当节点
child有左子节点(记为grand_child)时,需要在左旋中添加一步:将grand_child作为node的右子节点。
/* 左旋操作 */
TreeNode *leftRotate(TreeNode *node) {
TreeNode *child = node->right;
TreeNode *grandChild = child->left;
// 以 child 为原点,将 node 向左旋转
child->left = node;
node->right = grandChild;
// 更新节点高度
updateHeight(node);
updateHeight(child);
// 返回旋转后子树的根节点
return child;
}
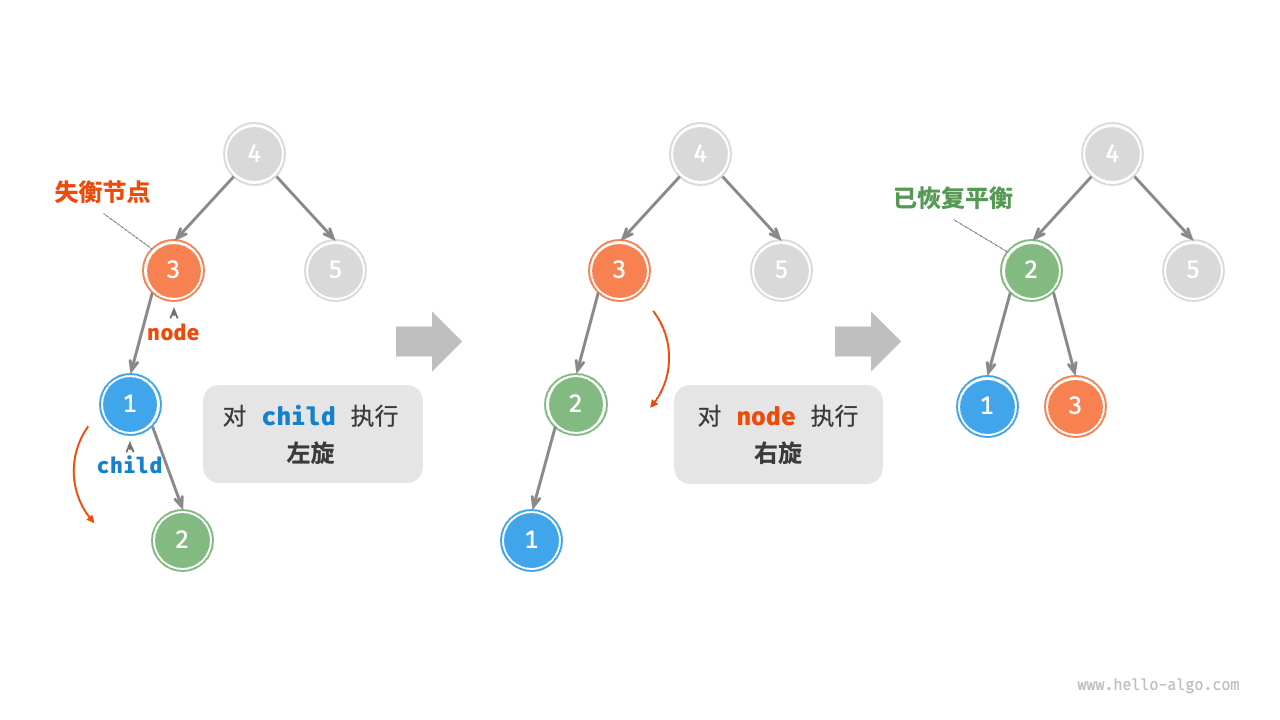
先左旋后右旋
对于图 7-30 中的失衡节点 3 ,仅使用左旋或右旋都无法使子树恢复平衡。此时需要先对 child 执行“左旋”,再对 node 执行“右旋”。
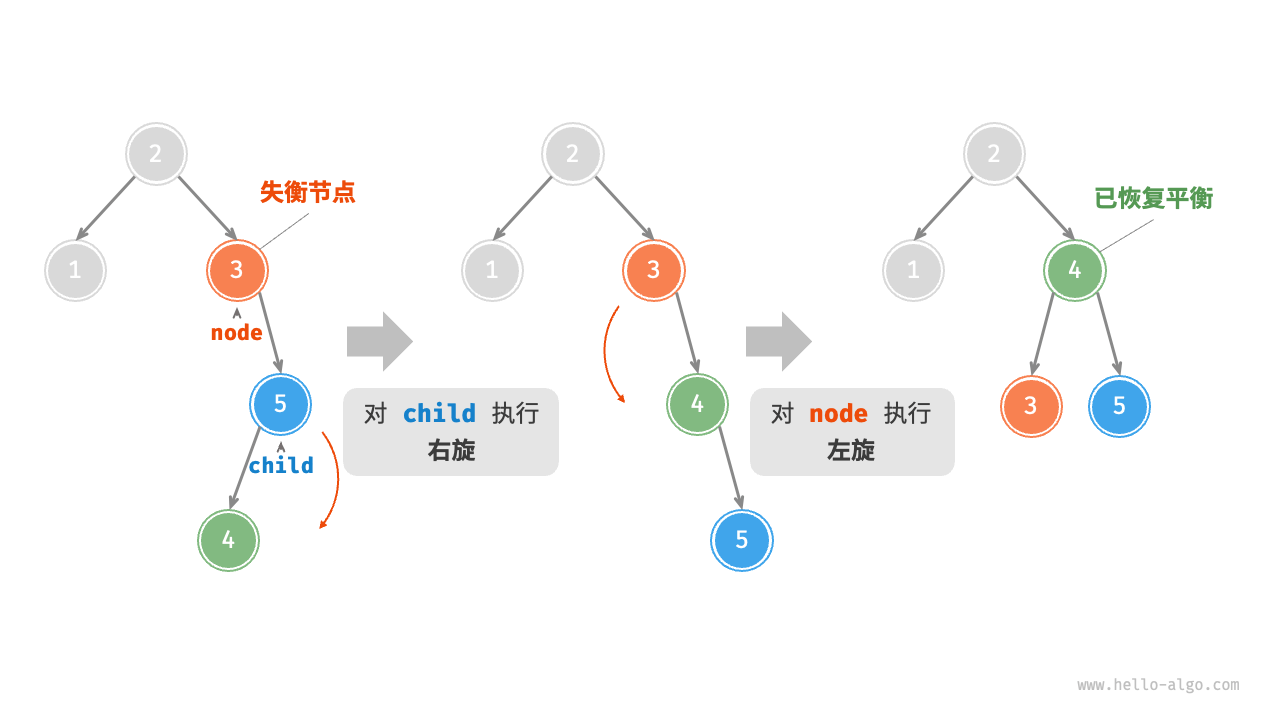
先右旋后左旋¶
如图 7-31 所示,对于上述失衡二叉树的镜像情况,需要先对 child 执行“右旋”,再对 node 执行“左旋”。
旋转选择
-
如下表所示,我们通过判断失衡节点的平衡因子以及较高一侧子节点的平衡因子的正负号,来确定失衡节点属于图 7-32 中的哪种情况。
-
表 7-3 四种旋转情况的选择条件
| 失衡节点的平衡因子 | 子节点的平衡因子 | 应采用的旋转方法 |
|---|---|---|
| >1 (左偏树) | ≥0 | 右旋 |
| >1 (左偏树) | <0 | 先左旋后右旋 |
| <−1 (右偏树) | ≤0 | 左旋 |
| <−1 (右偏树) | >0 | 先右旋后左旋 |
/* 执行旋转操作,使该子树重新恢复平衡 */
TreeNode *rotate(TreeNode *node) {
// 获取节点 node 的平衡因子
int _balanceFactor = balanceFactor(node);
// 左偏树
if (_balanceFactor > 1) {
if (balanceFactor(node->left) >= 0) {
// 右旋
return rightRotate(node);
} else {
// 先左旋后右旋
node->left = leftRotate(node->left);
return rightRotate(node);
}
}
// 右偏树
if (_balanceFactor < -1) {
if (balanceFactor(node->right) <= 0) {
// 左旋
return leftRotate(node);
} else {
// 先右旋后左旋
node->right = rightRotate(node->right);
return leftRotate(node);
}
}
// 平衡树,无须旋转,直接返回
return node;
}
AVL树常规操作
AVL 树的节点插入操作与二叉搜索树在主体上类似。唯一的区别在于,在 AVL 树中插入节点后,从该节点到根节点的路径上可能会出现一系列失衡节点。因此,我们需要从这个节点开始,自底向上执行旋转操作,使所有失衡节点恢复平衡。
-
插入节点
/* 插入节点 */ void insert(int val) { root = insertHelper(root, val); } /* 递归插入节点(辅助方法) */ TreeNode *insertHelper(TreeNode *node, int val) { if (node == nullptr) return new TreeNode(val); /* 1. 查找插入位置并插入节点 */ if (val < node->val) node->left = insertHelper(node->left, val); else if (val > node->val) node->right = insertHelper(node->right, val); else return node; // 重复节点不插入,直接返回 updateHeight(node); // 更新节点高度 /* 2. 执行旋转操作,使该子树重新恢复平衡 */ node = rotate(node); // 返回子树的根节点 return node; }
删除节点
/* 删除节点 */
void remove(int val) {
root = removeHelper(root, val);
}
/* 递归删除节点(辅助方法) */
TreeNode *removeHelper(TreeNode *node, int val) {
if (node == nullptr)
return nullptr;
/* 1. 查找节点并删除 */
if (val < node->val)
node->left = removeHelper(node->left, val);
else if (val > node->val)
node->right = removeHelper(node->right, val);
else {
if (node->left == nullptr || node->right == nullptr) {
TreeNode *child = node->left != nullptr ? node->left : node->right;
// 子节点数量 = 0 ,直接删除 node 并返回
if (child == nullptr) {
delete node;
return nullptr;
}
// 子节点数量 = 1 ,直接删除 node
else {
delete node;
node = child;
}
} else {
// 子节点数量 = 2 ,则将中序遍历的下个节点删除,并用该节点替换当前节点
TreeNode *temp = node->right;
while (temp->left != nullptr) {
temp = temp->left;
}
int tempVal = temp->val;
node->right = removeHelper(node->right, temp->val);
node->val = tempVal;
}
}
updateHeight(node); // 更新节点高度
/* 2. 执行旋转操作,使该子树重新恢复平衡 */
node = rotate(node);
// 返回子树的根节点
return node;
}
AVL 树典型应用¶
-
组织和存储大型数据,适用于高频查找、低频增删的场景。
-
用于构建数据库中的索引系统。
-
红黑树在许多应用中比 AVL 树更受欢迎。这是因为红黑树的平衡条件相对宽松,在红黑树中插入与删除节点所需的旋转操作相对较少,其节点增删操作的平均效率更高。
-
在 C++ 中,函数被划分到
private和public中,这方面有什么考量吗?为什么要将height()函数和updateHeight()函数分别放在public和private中呢?主要看方法的使用范围,如果方法只在类内部使用,那么就设计为
private。例如,用户单独调用updateHeight()是没有意义的,它只是插入、删除操作中的一步。而height()是访问节点高度,类似于vector.size(),因此设置成public以便使用。
红黑树
红黑树的删除

红黑树的特性
-
节点是红色或黑色
-
根是黑色
-
叶子节点(外部节点,空节点)都是黑色,这里的叶子节点指的是最底层的空节点(外部节点),下图中的那些null节点才是叶子节点,null节点的父节点在红黑树里不将其看作叶子节点
-
红色节点的子节点都是黑色
-
红色节点的父节点都是黑色
-
从根节点到叶子节点的所有路径上不能有 2 个连续的红色节点
-
从任一节点到叶子节点的所有路径都包含相同数目的黑色节点
-
红黑树的查找,插入和删除操作,时间复杂度都是O(logN)。
堆
-
分为大顶堆,小顶堆。
-
堆通常用于实现优先队列,大顶堆相当于元素按从大到小的顺序出队的优先队列。从使用角度来看,我们可以将“优先队列”和“堆”看作等价的数据结构。
堆的常见操作
//初始化小顶堆 priority_queue<int, vector<int>, greater<int>>minHeap; //初始化大顶堆 priority_queue<int, vector<int>,less<int>>maxHeap; //元素入堆 maxHeap.push(1); //获取堆顶元素 int peek = maxHeap.top(); //堆顶元素出堆 //出堆元素会形成一个从大到小的序列 maxHeap.pop(); maxHeap.pop(); //获取堆大小 int size= maxHeap.size(); //判断堆是否为空 bool isEmpty = maxHeap.empty();
堆的实现
-
由于堆是一种完全二叉树 , 所以堆的存贮采用数组方式。
//访问堆顶元素
int peek(){
return maxHeap[0];
}
元素入堆
-
给定元素
val,我们首先将其添加到堆底。添加之后,由于val可能大于堆中其他元素,堆的成立条件可能已被破坏,因此需要修复从插入节点到根节点的路径上的各个节点,这个操作被称为「堆化 heapify」。 -
考虑从入堆节点开始,从底至顶执行堆化。我们比较插入节点与其父节点的值,如果插入节点更大,则将它们交换。然后继续执行此操作,从底至顶修复堆中的各个节点,直至越过根节点或遇到无须交换的节点时结束。
//元素入堆
void push(int val)
{
//添加节点
maxHeap.push_back(val);
//从底至顶堆化
siftUp(size()-1);
}
void siftUp(int i)
{
while(true){
int p =parent(i);
if(p < 0||maxHeap[i]<= maxHeap[p])
break;
//交换两节点
sawp(maxHeap[i],maxHeap[p]);
//循环向上
i=p;
}
}
堆顶元素出栈
-
交换堆顶元素与堆底元素(交换根节点与最右叶节点)。
-
交换完成后,将堆底从列表中删除(注意,由于已经交换,因此实际上删除的是原来的堆顶元素)。
-
从根节点开始,从顶至底执行堆化。
“从顶至底堆化”的操作方向与“从底至顶堆化”相反,我们将根节点的值与其两个子节点的值进行比较,将最大的子节点与根节点交换。然后循环执行此操作,直到越过叶节点或遇到无须交换的节点时结束。
堆的常见应用¶
-
优先队列:堆通常作为实现优先队列的首选数据结构,其入队和出队操作的时间复杂度均为 O(logn) ,而建队操作为 O(n) ,这些操作都非常高效。
-
堆排序:给定一组数据,我们可以用它们建立一个堆,然后不断地执行元素出堆操作,从而得到有序数据。然而,我们通常会使用一种更优雅的方式实现堆排序,详见“堆排序”章节。
-
获取最大的 k 个元素:这是一个经典的算法问题,同时也是一种典型应用,例如选择热度前 10 的新闻作为微博热搜,选取销量前 10 的商品等。
建堆操作
方法一:
-
我们首先创建一个空堆,然后遍历列表,依次对每个元素执行“入堆操作”,即先将元素添加至堆的尾部,再对该元素执行“从底至顶”堆化。
每当一个元素入堆,堆的长度就加一。由于节点是从顶到底依次被添加进二叉树的,因此堆是“自上而下”构建的。
设元素数量为 n ,每个元素的入堆操作使用 O(logn) 时间,因此该建堆方法的时间复杂度为 O(nlogn) 。
方法二:
-
实际上,我们可以实现一种更为高效的建堆方法,共分为两步。
-
将列表所有元素原封不动地添加到堆中,此时堆的性质尚未得到满足。
-
倒序遍历堆(层序遍历的倒序),依次对每个非叶节点执行“从顶至底堆化”。
每当堆化一个节点后,以该节点为根节点的子树就形成一个合法的子堆。而由于是倒序遍历,因此堆是“自下而上”构建的。
之所以选择倒序遍历,是因为这样能够保证当前节点之下的子树已经是合法的子堆,这样堆化当前节点才是有效的。
值得说明的是,由于叶节点没有子节点,因此它们天然就是合法的子堆,无须堆化。如以下代码所示,最后一个非叶节点是最后一个节点的父节点,我们从它开始倒序遍历并执行堆化
-
TOP—k问题
-
给定一个长度为 n 的无序数组
nums,请返回数组中最大的 k 个元素
-
我们可以基于堆更加高效地解决 Top-k 问题,
-
初始化一个小顶堆,其堆顶元素最小。
-
先将数组的前 k 个元素依次入堆。
-
从第 k+1 个元素开始,若当前元素大于堆顶元素,则将堆顶元素出堆,并将当前元素入堆。
-
遍历完成后,堆中保存的就是最大的 k 个元素。
-
/* 基于堆查找数组中最大的 k 个元素 */
priority_queue<int, vector<int>, greater<int>> topKHeap(vector<int> &nums, int k) {
// 初始化小顶堆
priority_queue<int, vector<int>, greater<int>> heap;
// 将数组的前 k 个元素入堆
for (int i = 0; i < k; i++) {
heap.push(nums[i]);
}
// 从第 k+1 个元素开始,保持堆的长度为 k
for (int i = k; i < nums.size(); i++) {
// 若当前元素大于堆顶元素,则将堆顶元素出堆、当前元素入堆
if (nums[i] > heap.top()) {
heap.pop();
heap.push(nums[i]);
}
}
return heap;
}
总共执行了 n 轮入堆和出堆,堆的最大长度为 k,因此时间复杂度为 O(nlogk) 。该方法的效率很高,当 k 较小时,时间复杂度趋向 O(n) ;当 n 较大时,时间复杂度不会超过 O(n logn) 。
图
-
对于连通图,从某个顶点出发,可以到达其余任意顶点。
-
对于非连通图,从某个顶点出发,至少有一个顶点无法到达。
图的基本操作
设图中共有 n 个顶点和 m条边,表 9-2 对比了邻接矩阵和邻接表的时间效率和空间效率。

观察表 9-2 ,似乎邻接表(哈希表)的时间效率与空间效率最优。但实际上,在邻接矩阵中操作边的效率更高,只需一次数组访问或赋值操作即可。综合来看,邻接矩阵体现了“以空间换时间”的原则,而邻接表体现了“以时间换空间”的原则。
图的遍历
/* 广度优先遍历 */
// 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点
vector<Vertex *> graphBFS(GraphAdjList &graph, Vertex *startVet) {
// 顶点遍历序列
vector<Vertex *> res;
// 哈希表,用于记录已被访问过的顶点
unordered_set<Vertex *> visited = {startVet};
// 队列用于实现 BFS
queue<Vertex *> que;
que.push(startVet);
// 以顶点 vet 为起点,循环直至访问完所有顶点
while (!que.empty()) {
Vertex *vet = que.front();
que.pop(); // 队首顶点出队
res.push_back(vet); // 记录访问顶点
// 遍历该顶点的所有邻接顶点
for (auto adjVet : graph.adjList[vet]) {
if (visited.count(adjVet))
continue; // 跳过已被访问的顶点
que.push(adjVet); // 只入队未访问的顶点
visited.emplace(adjVet); // 标记该顶点已被访问
}
}
// 返回顶点遍历序列
return res;
}
/* 深度优先遍历辅助函数 */
void dfs(GraphAdjList &graph, unordered_set<Vertex *> &visited, vector<Vertex *> &res, Vertex *vet) {
res.push_back(vet); // 记录访问顶点
visited.emplace(vet); // 标记该顶点已被访问
// 遍历该顶点的所有邻接顶点
for (Vertex *adjVet : graph.adjList[vet]) {
if (visited.count(adjVet))
continue; // 跳过已被访问的顶点
// 递归访问邻接顶点
dfs(graph, visited, res, adjVet);
}
}
/* 深度优先遍历 */
// 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点
vector<Vertex *> graphDFS(GraphAdjList &graph, Vertex *startVet) {
// 顶点遍历序列
vector<Vertex *> res;
// 哈希表,用于记录已被访问过的顶点
unordered_set<Vertex *> visited;
dfs(graph, visited, res, startVet);
return res;
}
二分查找
/* 二分查找(双闭区间) */
int binarySearch(vector<int> &nums, int target) {
// 初始化双闭区间 [0, n-1] ,即 i, j 分别指向数组首元素、尾元素
int i = 0, j = nums.size() - 1;
// 循环,当搜索区间为空时跳出(当 i > j 时为空)
while (i <= j) {
int m = i + (j - i) / 2; // 计算中点索引 m
if (nums[m] < target) // 此情况说明 target 在区间 [m+1, j] 中
i = m + 1;
else if (nums[m] > target) // 此情况说明 target 在区间 [i, m-1] 中
j = m - 1;
else // 找到目标元素,返回其索引
return m;
}
// 未找到目标元素,返回 -1
return -1;
}

/* 二分查找(左闭右开区间) */
int binarySearchLCRO(vector<int> &nums, int target) {
// 初始化左闭右开区间 [0, n) ,即 i, j 分别指向数组首元素、尾元素+1
int i = 0, j = nums.size();
// 循环,当搜索区间为空时跳出(当 i = j 时为空)
while (i < j) {
int m = i + (j - i) / 2; // 计算中点索引 m
if (nums[m] < target) // 此情况说明 target 在区间 [m+1, j) 中
i = m + 1;
else if (nums[m] > target) // 此情况说明 target 在区间 [i, m) 中
j = m;
else // 找到目标元素,返回其索引
return m;
}
// 未找到目标元素,返回 -1
return -1;
}

哈希优化策略


-
代码实现
/* 方法二:辅助哈希表 */
vector<int> twoSumHashTable(vector<int> &nums, int target) {
int size = nums.size();
// 辅助哈希表,空间复杂度为 O(n)
unordered_map<int, int> dic;
// 单层循环,时间复杂度为 O(n)
for (int i = 0; i < size; i++) {
if (dic.find(target - nums[i]) != dic.end()) {
return {dic[target - nums[i]], i};
}
dic.emplace(nums[i], i);
}
return {};
}
排序
选择排序
void selectionSort(vector<int> &nums)
{
int n = num.size();
for(int i =0;i<n;i++){
int k=i;
for(int j=i+1;j <n;j++){
if(nums[j]<nums[k])
k=j;
}
swap(nums[i],nums[k]);
}
}
-
非稳定性排序
冒泡排序
我们发现,如果某轮“冒泡”中没有执行任何交换操作,说明数组已经完成排序,可直接返回结果。因此,可以增加一个标志位 flag 来监测这种情况,一旦出现就立即返回。
void bubbleSortWithFlag(vector<int> &muns)
{
for(int i=nums.size()-1;i>0;i--){
bool flag= false;
for(int j=0;j<i;j++){
if(nums[j]>numsm[j+1]){
swap(nums[j],nums[j+1]);
flag=true;
}
}
if(!falg)
break;//此轮“冒泡”未交换元素,退出。
}
}
-
稳定排序
-
冒泡排序遇到相等元素不交换
插入排序

void insertionSort(vector<int> &nums)
{
for(int i=1;i<nums.size();i++){
int base = nums[i],j= i-1;
while(j >= 0&&nums[j]>base){
nums[j+1]=nums[j];//将nums[j]向右移动一位。
j--;
}
nums[j+1]= base;//将base赋予到正确的位置
}
}
-
稳定的排序
快速排序

/* 元素交换 */
void swap(vector<int> &nums, int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
/* 哨兵划分 */
int partition(vector<int> &nums, int left, int right) {
// 以 nums[left] 为基准数
int i = left, j = right;
while (i < j) {
while (i < j && nums[j] >= nums[left])
j--; // 从右向左找首个小于基准数的元素
while (i < j && nums[i] <= nums[left])
i++; // 从左向右找首个大于基准数的元素
swap(nums, i, j); // 交换这两个元素
}
swap(nums, i, left); // 将基准数交换至两子数组的分界线
return i; // 返回基准数的索引
}
/* 快速排序 */
void quickSort(vector<int> &nums, int left, int right) {
// 子数组长度为 1 时终止递归
if (left >= right)
return;
// 哨兵划分
int pivot = partition(nums, left, right);
// 递归左子数组、右子数组
quickSort(nums, left, pivot - 1);
quickSort(nums, pivot + 1, right);
}

-
非稳定性排序

基准数优化

尾递归优化

/* 快速排序(尾递归优化) */
void quickSort(vector<int> &nums, int left, int right) {
// 子数组长度为 1 时终止
while (left < right) {
// 哨兵划分操作
int pivot = partition(nums, left, right);
// 对两个子数组中较短的那个执行快速排序
if (pivot - left < right - pivot) {
quickSort(nums, left, pivot - 1); // 递归排序左子数组
left = pivot + 1; // 剩余未排序区间为 [pivot + 1, right]
} else {
quickSort(nums, pivot + 1, right); // 递归排序右子数组
right = pivot - 1; // 剩余未排序区间为 [left, pivot - 1]
}
}
}
归并排序


-
归并排序:先递归左子数组,再递归右子数组,最后处理合并。
/* 合并左子数组和右子数组 */
void merge(vector<int> &nums, int left, int mid, int right) {
// 左子数组区间为 [left, mid], 右子数组区间为 [mid+1, right]
// 创建一个临时数组 tmp ,用于存放合并后的结果
vector<int> tmp(right - left + 1);
// 初始化左子数组和右子数组的起始索引
int i = left, j = mid + 1, k = 0;
// 当左右子数组都还有元素时,进行比较并将较小的元素复制到临时数组中
while (i <= mid && j <= right) {
if (nums[i] <= nums[j])
tmp[k++] = nums[i++];
else
tmp[k++] = nums[j++];
}
// 将左子数组和右子数组的剩余元素复制到临时数组中
while (i <= mid) {
tmp[k++] = nums[i++];
}
while (j <= right) {
tmp[k++] = nums[j++];
}
// 将临时数组 tmp 中的元素复制回原数组 nums 的对应区间
for (k = 0; k < tmp.size(); k++) {
nums[left + k] = tmp[k];
}
}
/* 归并排序 */
void mergeSort(vector<int> &nums, int left, int right) {
// 终止条件
if (left >= right)
return; // 当子数组长度为 1 时终止递归
// 划分阶段
int mid = (left + right) / 2; // 计算中点
mergeSort(nums, left, mid); // 递归左子数组
mergeSort(nums, mid + 1, right); // 递归右子数组
// 合并阶段
merge(nums, left, mid, right);
}
堆排序

/* 堆的长度为 n ,从节点 i 开始,从顶至底堆化 */
void siftDown(vector<int> &nums, int n, int i) {
while (true) {
// 判断节点 i, l, r 中值最大的节点,记为 ma
int l = 2 * i + 1;
int r = 2 * i + 2;
int ma = i;
if (l < n && nums[l] > nums[ma])
ma = l;
if (r < n && nums[r] > nums[ma])
ma = r;
// 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出
if (ma == i) {
break;
}
// 交换两节点
swap(nums[i], nums[ma]);
// 循环向下堆化
i = ma;
}
}
/* 堆排序 */
void heapSort(vector<int> &nums) {
// 建堆操作:堆化除叶节点以外的其他所有节点
for (int i = nums.size() / 2 - 1; i >= 0; --i) {
siftDown(nums, nums.size(), i);
}
// 从堆中提取最大元素,循环 n-1 轮
for (int i = nums.size() - 1; i > 0; --i) {
// 交换根节点与最右叶节点(交换首元素与尾元素)
swap(nums[0], nums[i]);
// 以根节点为起点,从顶至底进行堆化
siftDown(nums, i, 0);
}
}
-
非稳定的排序
桶排序

/* 桶排序 */
void bucketSort(vector<float> &nums) {
// 初始化 k = n/2 个桶,预期向每个桶分配 2 个元素
int k = nums.size() / 2;
vector<vector<float>> buckets(k);
// 1. 将数组元素分配到各个桶中
for (float num : nums) {
// 输入数据范围为 [0, 1),使用 num * k 映射到索引范围 [0, k-1]
int i = num * k;
// 将 num 添加进桶 bucket_idx
buckets[i].push_back(num);
}
// 2. 对各个桶执行排序
for (vector<float> &bucket : buckets) {
// 使用内置排序函数,也可以替换成其他排序算法
sort(bucket.begin(), bucket.end());
}
// 3. 遍历桶合并结果
int i = 0;
for (vector<float> &bucket : buckets) {
for (float num : bucket) {
nums[i++] = num;
}
}
}



计数排序


/* 计数排序 */
// 简单实现,无法用于排序对象
void countingSortNaive(vector<int> &nums) {
// 1. 统计数组最大元素 m
int m = 0;
for (int num : nums) {
m = max(m, num);
}
// 2. 统计各数字的出现次数
// counter[num] 代表 num 的出现次数
vector<int> counter(m + 1, 0);
for (int num : nums) {
counter[num]++;
}
// 3. 遍历 counter ,将各元素填入原数组 nums
int i = 0;
for (int num = 0; num < m + 1; num++) {
for (int j = 0; j < counter[num]; j++, i++) {
nums[i] = num;
}
}
}

/* 计数排序 */
// 完整实现,可排序对象,并且是稳定排序
void countingSort(vector<int> &nums) {
// 1. 统计数组最大元素 m
int m = 0;
for (int num : nums) {
m = max(m, num);
}
// 2. 统计各数字的出现次数
// counter[num] 代表 num 的出现次数
vector<int> counter(m + 1, 0);
for (int num : nums) {
counter[num]++;
}
// 3. 求 counter 的前缀和,将“出现次数”转换为“尾索引”
// 即 counter[num]-1 是 num 在 res 中最后一次出现的索引
for (int i = 0; i < m; i++) {
counter[i + 1] += counter[i];
}
// 4. 倒序遍历 nums ,将各元素填入结果数组 res
// 初始化数组 res 用于记录结果
int n = nums.size();
vector<int> res(n);
for (int i = n - 1; i >= 0; i--) {
int num = nums[i];
res[counter[num] - 1] = num; // 将 num 放置到对应索引处
counter[num]--; // 令前缀和自减 1 ,得到下次放置 num 的索引
}
// 使用结果数组 res 覆盖原数组 nums
nums = res;
}


基数排序

/* 获取元素 num 的第 k 位,其中 exp = 10^(k-1) */
int digit(int num, int exp) {
// 传入 exp 而非 k 可以避免在此重复执行昂贵的次方计算
return (num / exp) % 10;
}
/* 计数排序(根据 nums 第 k 位排序) */
void countingSortDigit(vector<int> &nums, int exp) {
// 十进制的位范围为 0~9 ,因此需要长度为 10 的桶数组
vector<int> counter(10, 0);
int n = nums.size();
// 统计 0~9 各数字的出现次数
for (int i = 0; i < n; i++) {
int d = digit(nums[i], exp); // 获取 nums[i] 第 k 位,记为 d
counter[d]++; // 统计数字 d 的出现次数
}
// 求前缀和,将“出现个数”转换为“数组索引”
for (int i = 1; i < 10; i++) {
counter[i] += counter[i - 1];
}
// 倒序遍历,根据桶内统计结果,将各元素填入 res
vector<int> res(n, 0);
for (int i = n - 1; i >= 0; i--) {
int d = digit(nums[i], exp);
int j = counter[d] - 1; // 获取 d 在数组中的索引 j
res[j] = nums[i]; // 将当前元素填入索引 j
counter[d]--; // 将 d 的数量减 1
}
// 使用结果覆盖原数组 nums
for (int i = 0; i < n; i++)
nums[i] = res[i];
}
/* 基数排序 */
void radixSort(vector<int> &nums) {
// 获取数组的最大元素,用于判断最大位数
int m = *max_element(nums.begin(), nums.end());
// 按照从低位到高位的顺序遍历
for (int exp = 1; exp <= m; exp *= 10)
// 对数组元素的第 k 位执行计数排序
// k = 1 -> exp = 1
// k = 2 -> exp = 10
// 即 exp = 10^(k-1)
countingSortDigit(nums, exp);
}

分治
-
「分治 divide and conquer」,全称分而治之,是一种非常重要且常见的算法策略。分治通常基于递归实现,包括“分”和“治”两个步骤。
-
分(划分阶段):递归地将原问题分解为两个或多个子问题,直至到达最小子问题时终止。
-
治(合并阶段):从已知解的最小子问题开始,从底至顶地将子问题的解进行合并,从而构建出原问题的解。
-
分治搜索策略
/* 二分查找:问题 f(i, j) */
int dfs(vector<int> &nums, int target, int i, int j) {
// 若区间为空,代表无目标元素,则返回 -1
if (i > j) {
return -1;
}
// 计算中点索引 m
int m = (i + j) / 2;
if (nums[m] < target) {
// 递归子问题 f(m+1, j)
return dfs(nums, target, m + 1, j);
} else if (nums[m] > target) {
// 递归子问题 f(i, m-1)
return dfs(nums, target, i, m - 1);
} else {
// 找到目标元素,返回其索引
return m;
}
}
/* 二分查找 */
int binarySearch(vector<int> &nums, int target) {
int n = nums.size();
// 求解问题 f(0, n-1)
return dfs(nums, target, 0, n - 1);
}
构建二叉树问题

/* 构建二叉树:分治 */
TreeNode *dfs(vector<int> &preorder, unordered_map<int, int> &inorderMap, int i, int l, int r) {
// 子树区间为空时终止
if (r - l < 0)
return NULL;
// 初始化根节点
TreeNode *root = new TreeNode(preorder[i]);
// 查询 m ,从而划分左右子树
int m = inorderMap[preorder[i]];
// 子问题:构建左子树
root->left = dfs(preorder, inorderMap, i + 1, l, m - 1);
// 子问题:构建右子树
root->right = dfs(preorder, inorderMap, i + 1 + m - l, m + 1, r);
// 返回根节点
return root;
}
/* 构建二叉树 */
TreeNode *buildTree(vector<int> &preorder, vector<int> &inorder) {
// 初始化哈希表,存储 inorder 元素到索引的映射
unordered_map<int, int> inorderMap;
for (int i = 0; i < inorder.size(); i++) {
inorderMap[inorder[i]] = i;
}
TreeNode *root = dfs(preorder, inorderMap, 0, 0, inorder.size() - 1);
return root;
}

回溯

框架代码
-
接下来,我们尝试将回溯的“尝试、回退、剪枝”的主体框架提炼出来,提升代码的通用性。
在以下框架代码中,
state表示问题的当前状态,choices表示当前状态下可以做出的选择:
/* 回溯算法框架 */
void backtrack(State *state, vector<Choice *> &choices, vector<State *> &res) {
// 判断是否为解
if (isSolution(state)) {
// 记录解
recordSolution(state, res);
// 不再继续搜索
return;
}
// 遍历所有选择
for (Choice choice : choices) {
// 剪枝:判断选择是否合法
if (isValid(state, choice)) {
// 尝试:做出选择,更新状态
makeChoice(state, choice);
backtrack(state, choices, res);
// 回退:撤销选择,恢复到之前的状态
undoChoice(state, choice);
}
}
}
常见回溯算法术语
表 13-1 常见的回溯算法术语
| 名词 | 定义 | 例题三 |
|---|---|---|
| 解(solution) | 解是满足问题特定条件的答案,可能有一个或多个 | 根节点到节点 7 的满足约束条件的所有路径 |
| 约束条件(constraint) | 约束条件是问题中限制解的可行性的条件,通常用于剪枝 | 路径中不包含节点 3 |
| 状态(state) | 状态表示问题在某一时刻的情况,包括已经做出的选择 | 当前已访问的节点路径,即 path 节点列表 |
| 尝试(attempt) | 尝试是根据可用选择来探索解空间的过程,包括做出选择,更新状态,检查是否为解 | 递归访问左(右)子节点,将节点添加进 path ,判断节点的值是否为 7 |
| 回退(backtracking) | 回退指遇到不满足约束条件的状态时,撤销前面做出的选择,回到上一个状态 | 当越过叶节点、结束节点访问、遇到值为 3 的节点时终止搜索,函数返回 |
| 剪枝(pruning) | 剪枝是根据问题特性和约束条件避免无意义的搜索路径的方法,可提高搜索效率 | 当遇到值为 3 的节点时,则不再继续搜索 |


动态规划
「动态规划 dynamic programming」是一个重要的算法范式,它将一个问题分解为一系列更小的子问题,并通过存储子问题的解来避免重复计算,从而大幅提升时间效。

方法一:暴力搜索
/* 搜索 */
int dfs(int i) {
// 已知 dp[1] 和 dp[2] ,返回之
if (i == 1 || i == 2)
return i;
// dp[i] = dp[i-1] + dp[i-2]
int count = dfs(i - 1) + dfs(i - 2);
return count;
}
/* 爬楼梯:搜索 */
int climbingStairsDFS(int n) {
return dfs(n);
}
方法二:记忆化搜索

/* 记忆化搜索 */
int dfs(int i, vector<int> &mem) {
// 已知 dp[1] 和 dp[2] ,返回之
if (i == 1 || i == 2)
return i;
// 若存在记录 dp[i] ,则直接返回之
if (mem[i] != -1)
return mem[i];
// dp[i] = dp[i-1] + dp[i-2]
int count = dfs(i - 1, mem) + dfs(i - 2, mem);
// 记录 dp[i]
mem[i] = count;
return count;
}
/* 爬楼梯:记忆化搜索 */
int climbingStairsDFSMem(int n) {
// mem[i] 记录爬到第 i 阶的方案总数,-1 代表无记录
vector<int> mem(n + 1, -1);
return dfs(n, mem);
}

方法三:动态规划

/* 爬楼梯:动态规划 */
int climbingStairsDP(int n) {
if (n == 1 || n == 2)
return n;
// 初始化 dp 表,用于存储子问题的解
vector<int> dp(n + 1);
// 初始状态:预设最小子问题的解
dp[1] = 1;
dp[2] = 2;
// 状态转移:从较小子问题逐步求解较大子问题
for (int i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
空间优化
/* 爬楼梯:空间优化后的动态规划 */
int climbingStairsDPComp(int n) {
if (n == 1 || n == 2)
return n;
int a = 1, b = 2;
for (int i = 3; i <= n; i++) {
int tmp = b;
b = a + b;
a = tmp;
}
return b;
}
在动态规划问题中,当前状态往往仅与前面有限个状态有关,这时我们可以只保留必要的状态,通过“降维”来节省内存空间。这种空间优化技巧被称为“滚动变量”或“滚动数组”。
动态规划问题的特性
在上一节中,我们学习了动态规划是如何通过子问题分解来求解原问题的。实际上,子问题分解是一种通用的算法思路,在分治、动态规划、回溯中的侧重点不同。
-
分治算法递归地将原问题划分为多个相互独立的子问题,直至最小子问题,并在回溯中合并子问题的解,最终得到原问题的解。
-
动态规划也对问题进行递归分解,但与分治算法的主要区别是,动态规划中的子问题是相互依赖的,在分解过程中会出现许多重叠子问题。
-
回溯算法在尝试和回退中穷举所有可能的解,并通过剪枝避免不必要的搜索分支。原问题的解由一系列决策步骤构成,我们可以将每个决策步骤之前的子序列看作一个子问题。
实际上,动态规划常用来求解最优化问题,它们不仅包含重叠子问题,还具有另外两大特性:最优子结构、无后效性。
最优子结构



/* 爬楼梯最小代价:动态规划 */
int minCostClimbingStairsDP(vector<int> &cost) {
int n = cost.size() - 1;
if (n == 1 || n == 2)
return cost[n];
// 初始化 dp 表,用于存储子问题的解
vector<int> dp(n + 1);
// 初始状态:预设最小子问题的解
dp[1] = cost[1];
dp[2] = cost[2];
// 状态转移:从较小子问题逐步求解较大子问题
for (int i = 3; i <= n; i++) {
dp[i] = min(dp[i - 1], dp[i - 2]) + cost[i];
}
return dp[n];
}
无后效性


/* 带约束爬楼梯:动态规划 */
int climbingStairsConstraintDP(int n) {
if (n == 1 || n == 2) {
return 1;
}
// 初始化 dp 表,用于存储子问题的解
vector<vector<int>> dp(n + 1, vector<int>(3, 0));
// 初始状态:预设最小子问题的解
dp[1][1] = 1;
dp[1][2] = 0;
dp[2][1] = 0;
dp[2][2] = 1;
// 状态转移:从较小子问题逐步求解较大子问题
for (int i = 3; i <= n; i++) {
dp[i][1] = dp[i - 1][2];
dp[i][2] = dp[i - 2][1] + dp[i - 2][2];
}
return dp[n][1] + dp[n][2];
}
在这个问题中,下次跳跃依赖过去所有的状态,因为每一次跳跃都会在更高的阶梯上设置障碍,并影响未来的跳跃。对于这类问题,动态规划往往难以解决。
实际上,许多复杂的组合优化问题(例如旅行商问题)不满足无后效性。对于这类问题,我们通常会选择使用其他方法,例如启发式搜索、遗传算法、强化学习等,从而在有限时间内得到可用的局部最优解。
动态规划解题思路
上两节介绍了动态规划问题的主要特征,接下来我们一起探究两个更加实用的问题。
-
如何判断一个问题是不是动态规划问题?
-
求解动态规划问题该从何处入手,完整步骤是什么?
问题判断
总的来说,如果一个问题包含重叠子问题、最优子结构,并满足无后效性,那么它通常适合用动态规划求解。然而,我们很难从问题描述中直接提取出这些特性。因此我们通常会放宽条件,先观察问题是否适合使用回溯(穷举)解决。
适合用回溯解决的问题通常满足“决策树模型”,这种问题可以使用树形结构来描述,其中每一个节点代表一个决策,每一条路径代表一个决策序列。
换句话说,如果问题包含明确的决策概念,并且解是通过一系列决策产生的,那么它就满足决策树模型,通常可以使用回溯来解决。
在此基础上,动态规划问题还有一些判断的“加分项”。
-
问题包含最大(小)或最多(少)等最优化描述。
-
问题的状态能够使用一个列表、多维矩阵或树来表示,并且一个状态与其周围的状态存在递推关系。
相应地,也存在一些“减分项”。
-
问题的目标是找出所有可能的解决方案,而不是找出最优解。
-
问题描述中有明显的排列组合的特征,需要返回具体的多个方案。
如果一个问题满足决策树模型,并具有较为明显的“加分项”,我们就可以假设它是一个动态规划问题,并在求解过程中验证它。
求解步骤
动态规划的解题流程会因问题的性质和难度而有所不同,但通常遵循以下步骤:描述决策,定义状态,建立 dp表,推导状态转移方程,确定边界条件等。
贪心算法
「贪心算法 greedy algorithm」是一种常见的解决优化问题的算法,其基本思想是在问题的每个决策阶段,都选择当前看起来最优的选择,即贪心地做出局部最优的决策,以期获得全局最优解。贪心算法简洁且高效,在许多实际问题中有着广泛的应用。
贪心算法和动态规划都常用于解决优化问题。它们之间存在一些相似之处,比如都依赖最优子结构性质,但工作原理不同。
-
动态规划会根据之前阶段的所有决策来考虑当前决策,并使用过去子问题的解来构建当前子问题的解。
-
贪心算法不会考虑过去的决策,而是一路向前地进行贪心选择,不断缩小问题范围,直至问题被解决。

/* 零钱兑换:贪心 */
int coinChangeGreedy(vector<int> &coins, int amt) {
// 假设 coins 列表有序
int i = coins.size() - 1;
int count = 0;
// 循环进行贪心选择,直到无剩余金额
while (amt > 0) {
// 找到小于且最接近剩余金额的硬币
while (i > 0 && coins[i] > amt) {
i--;
}
// 选择 coins[i]
amt -= coins[i];
count++;
}
// 若未找到可行方案,则返回 -1
return amt == 0 ? count : -1;
}
优缺点
对于零钱兑换问题,贪心算法无法保证找到全局最优解,并且有可能找到非常差的解。它更适合用动态规划解决。
一般情况下,贪心算法的适用情况分以下两种。
-
可以保证找到最优解:贪心算法在这种情况下往往是最优选择,因为它往往比回溯、动态规划更高效。
-
可以找到近似最优解:贪心算法在这种情况下也是可用的。对于很多复杂问题来说,寻找全局最优解非常困难,能以较高效率找到次优解也是非常不错的。
解题步骤
贪心问题的解决流程大体可分为以下三步。
-
问题分析:梳理与理解问题特性,包括状态定义、优化目标和约束条件等。这一步在回溯和动态规划中都有涉及。
-
确定贪心策略:确定如何在每一步中做出贪心选择。这个策略能够在每一步减小问题的规模,并最终解决整个问题。
-
正确性证明:通常需要证明问题具有贪心选择性质和最优子结构。这个步骤可能需要用到数学证明,例如归纳法或反证法等。
确定贪心策略是求解问题的核心步骤,但实施起来可能并不容易,主要有以下原因。
-
不同问题的贪心策略的差异较大。对于许多问题来说,贪心策略比较浅显,我们通过一些大概的思考与尝试就能得出。而对于一些复杂问题,贪心策略可能非常隐蔽,这种情况就非常考验个人的解题经验与算法能力了。
-
某些贪心策略具有较强的迷惑性。当我们满怀信心设计好贪心策略,写出解题代码并提交运行,很可能发现部分测试样例无法通过。这是因为设计的贪心策略只是“部分正确”的,上文介绍的零钱兑换就是一个典型案例。
为了保证正确性,我们应该对贪心策略进行严谨的数学证明,通常需要用到反证法或数学归纳法。
然而,正确性证明也很可能不是一件易事。如若没有头绪,我们通常会选择面向测试用例进行代码调试,一步步修改与验证贪心策略。















 3111
3111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}