






整理的内容大部分来源于《hello算法》一书,章节的安排也遵循《hello算法》,部分内容来自王道课程,自学整理,侵权请联系。
一、初识算法
1.1 算法定义
算法:在有限时间内解决特定问题的一组指令或操作步骤,具有以下特性。
问题是明确的,包含清晰的输入和输出定义。
具有可行性,能够在有限步骤、时间和内存空间下完成。
各步骤都有确定的含义,相同的输入和运行条件下,输出始终相同。
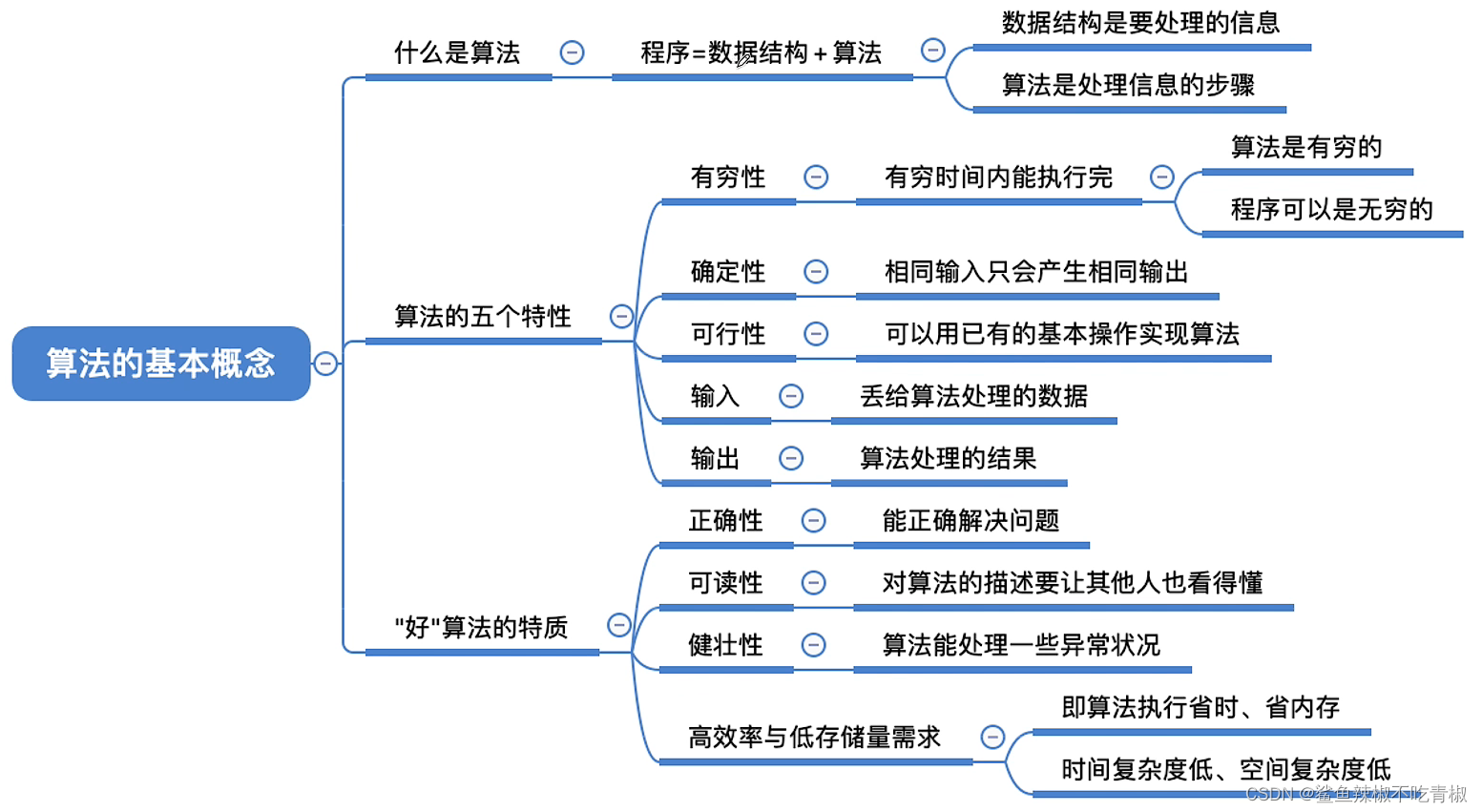
1.2 数据结构定义
数据结构是计算机中组织和存储数据的方式,具有以下设计目标。
空间占用尽量减少,节省计算机内存。
数据操作尽可能快速,涵盖数据访问、添加、删除、更新等。
提供简洁的数据表示和逻辑信息,以便使得算法高效运行。
数据之间呈现什么样的逻辑结构,针对这种结构会用到哪些常见的基本运算、基本操作,自己定义出这些操作,在使用计算机代码实现的时候,就需要考虑这些数据存储结构。

1.3 数据结构和算法的关系
数据结构与算法高度相关、紧密结合,具体表现以下三个方面。
数据结构是算法的基石。数据结构为算法提供了结构化存储的数据,以及用于操作数据的方法。
算法是数据结构发挥作用的舞台。数据结构本身仅存储数据信息,结合算法才能解决特定问题。
算法通常可以基于不同的数据结构进行实现,并往往有对应最优的数据结构,但最终执行效率可能相差很大。

如果把数据结构和算法类比为积木,此外数据结构和算法独立于编程语言。

二、复杂度分析
2.1 算法效率评估
在算法设计中,我们先后追求以下两个层面的目标。
找到问题解法:算法需要在规定的输入范围内,可靠地求得问题的正确解。
寻求最优解法:同一个问题可能存在多种解法,我们希望找到尽可能高效的算法。
在能够解决问题的前提下,可以从下面两个方面对算法的效率进行分析
时间效率:算法运行速度的快慢。
空间效率:算法占用内存空间的大小。
我们应该以设计“既快又省”的数据结构与算法为目标,对于算法效率评估主要分为两种:实际测试和理论估算。
实际测试
对于设计出的两个算法,直接在同一台计算机上运行,但是这种方式存在局限性。1 难以排除环境因素的干扰,不同硬件上不同算法运行的时间可能不一样,需要评估平均效率,不太现实。2 完整的测试太消耗资源,不同数据的输入也会对算法的效率产生影响,为了得到有说服力的结论,需要对不同的数据输入进行测试。
理论估算
由于实际测试具有较大的局限性,我们可以考虑仅通过一些计算来评估算法的效率,这种方法被简称为复杂度分析。
复杂度分析体现算法运行所需的时间(空间)资源与输入数据大小之间的关系。它描述了随着输入数据大小的增加,算法执行所需时间和空间的增长趋势。可以分为3个重点来理解:
“时间和空间资源”分别对应「时间复杂度time complexity」和「空间复杂度space complexity」。
“随着输入数据大小的增加”意味着复杂度反映了算法运行效率与输入数据体量之间的关系。
“时间和空间的增长趋势”表示复杂度分析关注的不是运行时间或占用空间的具体值,而是时间或空间增长的“快慢”。
2.2 迭代与递归
迭代
迭代是一种重复执行某个任务的控制结构。在迭代中,程序会在满足一定的条件下重复执行某
段代码,直到这个条件不再满足。
for循环
for 循环是最常见的迭代形式之一,适合预先知道迭代次数时使用。
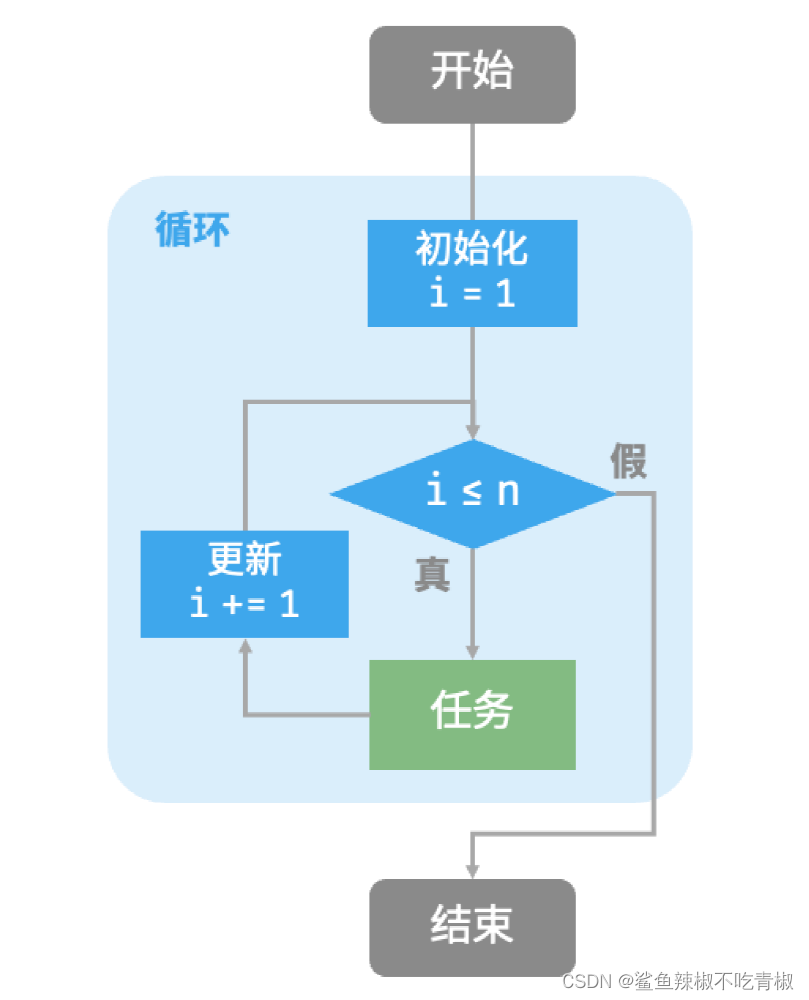
while循环
与for 循环类似,while 循环也是一种实现迭代的方法。在while 循环中,程序每轮都会先检查条件,如果条件为真则继续执行,否则就结束循环。
在while 循环中,由于初始化和更新条件变量的步骤是独立在循环结构之外的,因此它比for 循环的自由度更高。
for 循环的代码更加紧凑,while 循环更加灵活
嵌套循环
添加嵌套循环,每一次嵌套都是一次“升维”,将会使时间复杂度提高至“立方关系”、“四次方
关系”、以此类推。
递归
递归是一种算法策略,通过函数调用自身来解决问题。它主要包含两个阶段。
1. 递:程序不断深入地调用自身,通常传入更小或更简化的参数,直到达到“终止条件”。
2. 归:触发“终止条件”后,程序从最深层的递归函数开始逐层返回,汇聚每一层的结果。
而从实现的角度看,递归代码主要包含三个要素。
1. 终止条件:用于决定什么时候由“递”转“归”。
2. 递归调用:对应“递”,函数调用自身,通常输入更小或更简化的参数。
3. 返回结果:对应“归”,将当前递归层级的结果返回至上一层。
虽然从计算角度看,迭代与递归可以得到相同的结果,但它们代表了两种完全不同的思考和解决问题的范式。
‧ 迭代:“自下而上”地解决问题。从最基础的步骤开始,然后不断重复或累加这些步骤,直到任务完成。
‧ 递归:“自上而下”地解决问题。将原问题分解为更小的子问题,这些子问题和原问题具有相同的形式。
接下来将子问题继续分解为更小的子问题,直到基本情况时停止(基本情况的解是已知的)。
调用栈
递归函数每次调用自身时,系统都会为新开启的函数分配内存,以存储局部变量、调用地址和其他信息等。
这将导致两方面的结果。
‧ 函数的上下文数据都存储在称为“栈帧空间”的内存区域中,直至函数返回后才会被释放。因此,递归通常比迭代更加耗费内存空间。
‧ 递归调用函数会产生额外的开销。因此递归通常比循环的时间效率更低。
尾递归
如果函数在返回前的最后一步才进行递归调用,则该函数可以被编译器或解释器优化,使其在空
间效率上与迭代相当。这种情况被称为「尾递归tail recursion」。
‧ 普通递归:当函数返回到上一层级的函数后,需要继续执行代码,因此系统需要保存上一层调用的上下文。
‧ 尾递归:递归调用是函数返回前的最后一个操作,这意味着函数返回到上一层级后,无需继续执行其他操作,因此系统无需保存上一层函数的上下文。
递归树
当处理与“分治”相关的算法问题时,递归往往比迭代的思路更加直观、代码更加易读。
本质上看,递归体现“将问题分解为更小子问题”的思维范式,这种分治策略是至关重要的。
‧ 从算法角度看,搜索、排序、回溯、分治、动态规划等许多重要算法策略都直接或间接地应用这种思维方式。
‧ 从数据结构角度看,递归天然适合处理链表、树和图的相关问题,因为它们非常适合用分治思想进行分析。
2.3 时间复杂度
运行时间可以直观且准确地反映算法的效率。如果我们想要准确预估一段代码的运行时间,应该完成以下操作:
1. 确定运行平台 2. 评估各种计算操作所需的运行时间 3. 统计代码中所有的计算操作
但实际上,统计算法的运行时间既不合理也不现实。首先,我们不希望将预估时间和运行平台绑定,因为算法需要在各种不同的平台上运行。其次,我们很难获知每种操作的运行时间,这给预估过程带来了极大的难度。
统计时间增长趋势
时间复杂度分析统计的不是算法运行时间,而是算法运行时间随着数据量变大时的增长趋势。
“时间增长趋势”这个概念比较抽象,我们通过一个例子来加以理解。假设输入数据大小为𝑛 ,给定三个算法函数A、B 和C :
// 算法A 的时间复杂度:常数阶 void algorithm_A(int n) { cout << 0 << endl; } // 算法B 的时间复杂度:线性阶 void algorithm_B(int n) { for (int i = 0; i < n; i++) {cout << 0 << endl;} } // 算法C 的时间复杂度:常数阶 void algorithm_C(int n) { for (int i = 0; i < 1000000; i++) {cout << 0 << endl;} }算法A 只有1 个打印操作,算法运行时间不随着𝑛 增大而增长。我们称此算法的时间复杂度为“常数阶”。
算法B 中的打印操作需要循环𝑛 次,算法运行时间随着𝑛 增大呈线性增长。此算法的时间复杂度被称为“线性阶”。
算法C 中的打印操作需要循环1000000 次,虽然运行时间很长,但它与输入数据大小𝑛 无关。因此C的时间复杂度和A 相同,仍为“常数阶”

相较于直接统计算法运行时间,时间复杂度分析有以下特点:
时间复杂度能够有效评估算法效率
时间复杂度的推算方法更简便
时间复杂度也存在一定的局限性
函数渐近上界
给定一个输入大小为𝑛 的函数:
void algorithm(int n) { int a = 1; // +1 a = a + 1; // +1 a = a * 2; // +1 // 循环n 次 for (int i = 0; i < n; i++) { // +1(每轮都执行i ++) cout << 0 << endl; // +1 } }设算法的操作数量是一个关于输入数据大小𝑛 的函数,记为𝑇 (𝑛) ,则以上函数的的操作数量为:𝑇 (𝑛) = 3 + 2𝑛。𝑇 (𝑛) 是一次函数,说明其运行时间的增长趋势是线性的,因此它的时间复杂度是线性阶。
我们将线性阶的时间复杂度记为O(𝑛) ,这个数学符号称为大O 记号big‑𝑂 notation,表示函数𝑇 (𝑛)的渐近上界。
推算方法
第一步:统计操作数量
针对代码,逐行从上到下计算即可。操作数量𝑇 (𝑛) 中的各种系数、常数项都可以被忽略。
忽略𝑇 (𝑛) 中的常数项。
省略所有系数。
循环嵌套时使用乘法。
第二步:判断渐近上界
时间复杂度由多项式𝑇 (𝑛) 中最高阶的项来决定。
常见类型
设输入数据大小为𝑛 ,常见的时间复杂度类型(从低到高的顺序排列)

最差、最佳、平均时间复杂度
假设输入一个长度为𝑛 的数组nums ,其中nums 由从1 至𝑛 的数字组成,每个数字只出现一次;但元素顺序是随机打乱的,任务目标是返回元素1 的索引。我们可以得出以下结论。
当nums = [?, ?, ..., 1] ,即当末尾元素是1 时,需要完整遍历数组,达到最差时间复杂度𝑂(𝑛) 。
当nums = [1, ?, ?, ...] ,即当首个元素为1 时,无论数组多长都不需要继续遍历,达到最佳时间复杂度Ω(1) 。
最差时间复杂度更为实用,因为它给出了一个效率安全值。平均时间复杂度可以体现算法在随机输入数据下的运行效率

2.4 空间复杂度
算法相关空间
算法在运行过程中使用的内存空间主要包括以下几种。
‧ 输入空间:用于存储算法的输入数据。
‧ 暂存空间:用于存储算法在运行过程中的变量、对象、函数上下文等数据。
‧ 输出空间:用于存储算法的输出数据。
一般情况下,空间复杂度的统计范围是“暂存空间”加上“输出空间”。
暂存空间可以进一步划分为三个部分。
‧ 暂存数据:用于保存算法运行过程中的各种常量、变量、对象等。
‧ 栈帧空间:用于保存调用函数的上下文数据。系统在每次调用函数时都会在栈顶部创建一个栈帧,函数返回后,栈帧空间会被释放。
‧ 指令空间:用于保存编译后的程序指令,在实际统计中通常忽略不计。
在分析一段程序的空间复杂度时,我们通常统计暂存数据、栈帧空间和输出数据三部分。

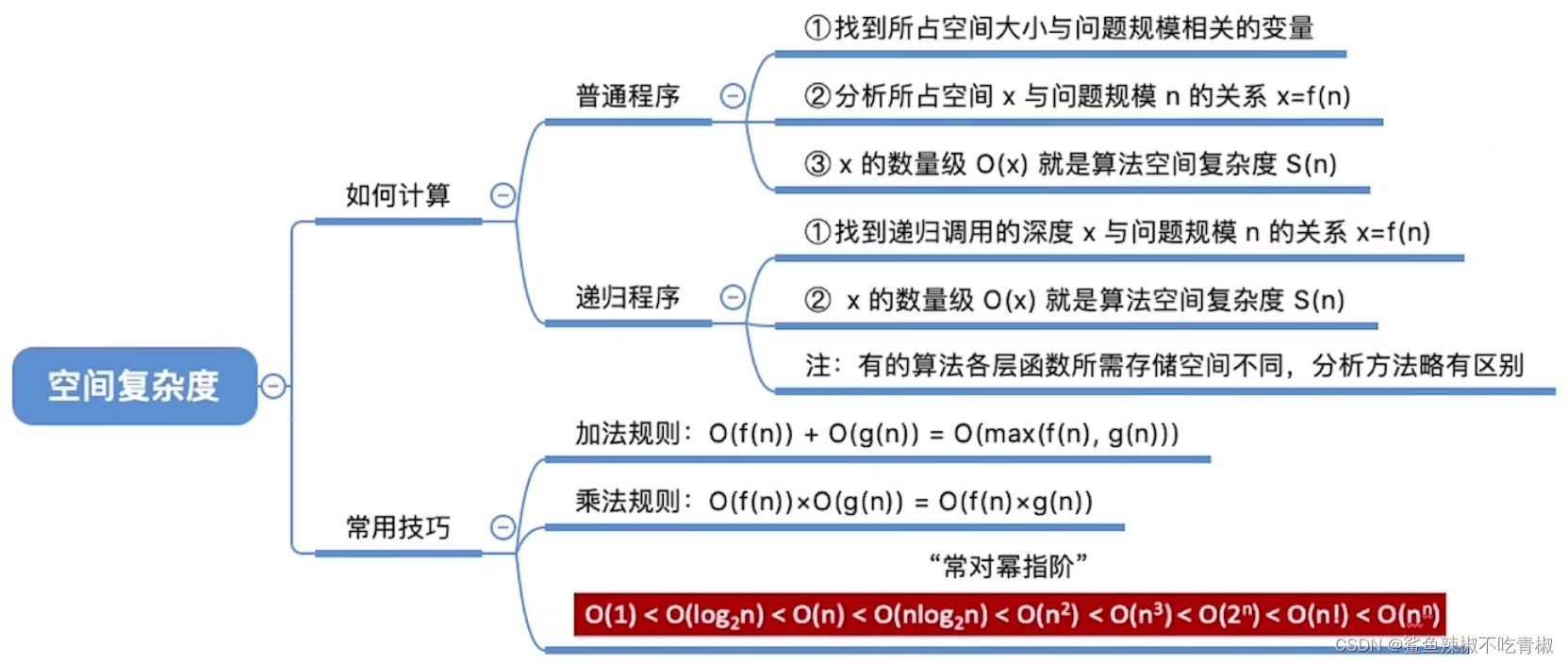
推算方法
空间复杂度的推算方法与时间复杂度大致相同,只需将统计对象从“操作数量”转为“使用空间大小”。
我们通常只关注最差空间复杂度。这是因为内存空间是一项硬性要求,我们必须确保在所有输入数据下都有足够的内存空间预留。
观察以下代码,最差空间复杂度中的“最差”有两层含义。
以最差输入数据为准
以算法运行中的峰值内存为准
常见类型
设输入数据大小为𝑛,常见的空间复杂度类型(从低到高排列)。
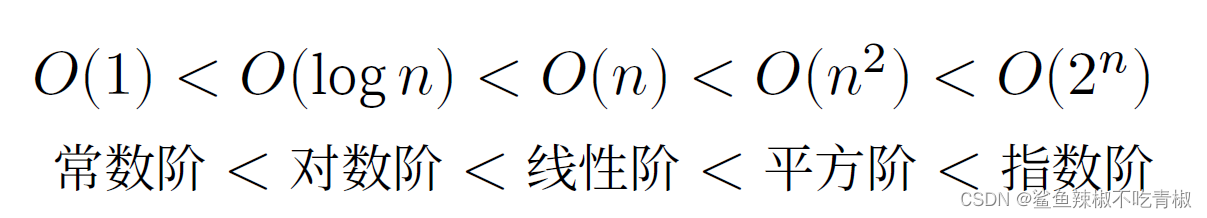
权衡时间与空间
理想情况下,我们希望算法的时间复杂度和空间复杂度都能达到最优。然而在实际情况中,同时优化时间复杂度和空间复杂度通常是非常困难的。降低时间复杂度通常需要以提升空间复杂度为代价,反之亦然。
三、数据结构
3.1 数据结构分类
常见的数据结构包括数组、链表、栈、队列、哈希表、树、堆、图,它们可以从“逻辑结构”和“物理结构”两个维度进行分类。
逻辑结构:线性和非线性
逻辑结构揭示了数据元素之间的逻辑关系。线性结构比较直观,指数据在逻辑关系上呈线性排列;非线性结构则相反,呈非线性排列。

物理结构:连续与离散
在算法运行过程中,相关数据都存储在内存中。系统通过内存地址来访问目标位置的数据。内存是所有程序的共享资源,当某块内存被某个程序占用时,则无法被其他程序同时使用了。因此在数据结构与算法的设计中,内存资源是一个重要的考虑因素。
物理结构反映了数据在计算机内存中的存储方式,可分为连续空间存储(数组)和离散空间存储(链表)。

所有数据结构都是基于数组、链表或二者的组合实现的。
3.2 基本数据类型
基本数据类型是CPU 可以直接进行运算的类型,在算法中直接被使用,主要包括以下几种类型。
‧ 整数类型byte、short、int、long 。
‧ 浮点数类型float、double ,用于表示小数。
‧ 字符类型char ,用于表示各种语言的字母、标点符号、甚至表情符号等。
‧ 布尔类型bool ,用于表示“是”与“否”判断。
基本数据类型以二进制的形式存储在计算机中。基本数据类型提供了数据的“内容类型”,而数据结构提供了数据的“组织方式”。
四、数组和链表
所有数据结构都是基于数组、链表或二者的组合实现的。对于数据的操作:创建销毁、增删改查、求表长、输出操作、判空操作
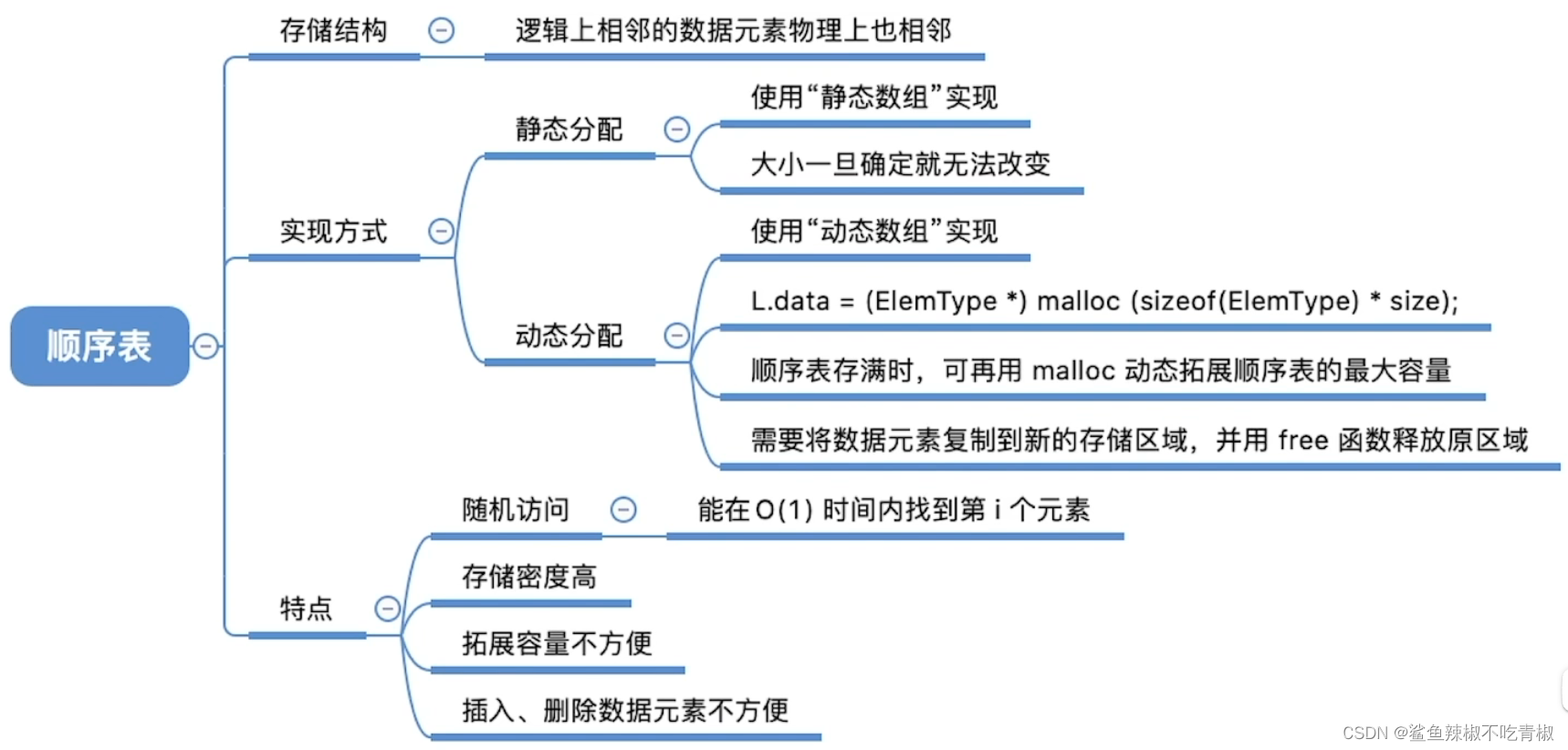
4.1 数组(静态数组)
「数组array」是一种线性数据结构,其将相同类型元素存储在连续的内存空间中。我们将元素在数组中的位置称为该元素的「索引index」

数组的基本操作
初始化(创建)
数组的两种初始化方式:无初始值(不推荐)、给定初始值。如果不知道数组防止什么元素,就设置为空。
int arr[5] = { 0 };
int nums[5] { 1, 3, 2, 5, 4 };
int* nums1 = new int[5] { 1, 3, 2, 5, 4 };访问元素
数组元素被存储在连续的内存空间中,这意味着计算数组元素的内存地址非常容易。给定数组内存地址(即首元素内存地址)和某个元素的索引,从地址计算公式的角度看,索引的含义本质上是内存地址的偏移量。

插入元素(增)
如果想要在数组中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,之后再把元素赋值给该索引。但是由于数组的长度是固定的,因此插入一个元素必定会导致数组尾部元素“丢失”。
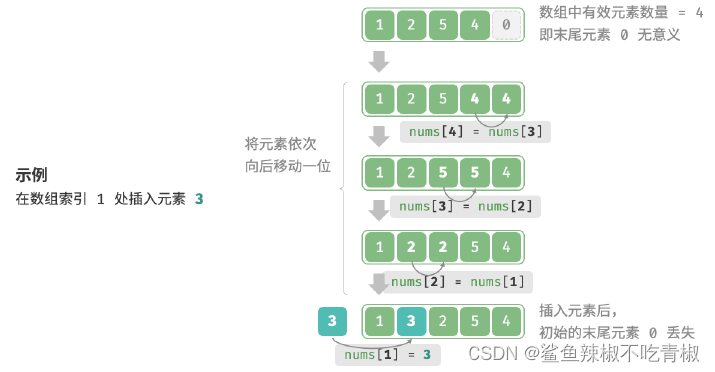
/* 在数组的索引index 处插入元素num */
void insert(int *nums, int size, int num, int index) {
// 把索引index 以及之后的所有元素向后移动一位
for (int i = size - 1; i > index; i--) {
nums[i] = nums[i - 1];
}
// 将num 赋给index 处元素
nums[index] = num;
}删除元素(删)
若想要删除索引𝑖 处的元素,则需要把索引𝑖 之后的元素都向前移动一位。
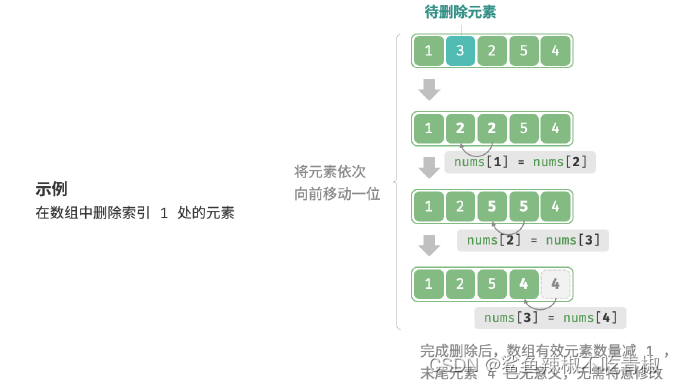
/* 删除索引index 处元素*/
void remove(int *nums, int size, int index) {
// 把索引index 之后的所有元素向前移动一位
for (int i = index; i < size - 1; i++) {
nums[i] = nums[i + 1];
}
}遍历数组(输出操作)
/* 遍历数组*/
void traverse(int *nums, int size) {
int count = 0;
// 通过索引遍历数组
for (int i = 0; i < size; i++) {
count++;
cout<<nums[count];
}
}查找元素(查)
在数组中查找指定元素需要遍历数组,每轮判断元素值是否匹配,若匹配则输出对应索引。
/* 在数组中查找指定元素*/
int find(int *nums, int size, int target) {
for (int i = 0; i < size; i++) {
if (nums[i] == target)
return i;
}
return -1;
}扩容数组
数组的长度在创建完成后是不可变的。如果想要对数组进行扩容,重新建立一个更大的数组,然后把原数组元素依次拷贝到新数组。
/* 扩展数组长度*/
int *extend(int *nums, int size, int enlarge) {
// 初始化一个扩展长度后的数组
int *res = new int[size + enlarge];
// 将原数组中的所有元素复制到新数组
for (int i = 0; i < size; i++) {
res[i] = nums[i];
}
// 释放内存
delete[] nums;
// 返回扩展后的新数组
return res;
}数组优点与局限性
优点
‧ 空间效率高: 数组为数据分配了连续的内存块,无须额外的结构开销。
‧ 支持随机访问: 数组允许在𝑂(1) 时间内访问任何元素。
‧ 缓存局部性: 当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
局限性
‧ 插入与删除效率低: 当数组中元素较多时,插入与删除操作需要移动大量的元素。
‧ 长度不可变: 数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
‧ 空间浪费: 如果数组分配的大小超过了实际所需,那么多余的空间就被浪费了。
4.2 链表
「链表linked list」是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“指针”相连接。引用记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点。链表的设计使得各个节点可以被分散存储在内存各处,它们的内存地址是无须连续的。
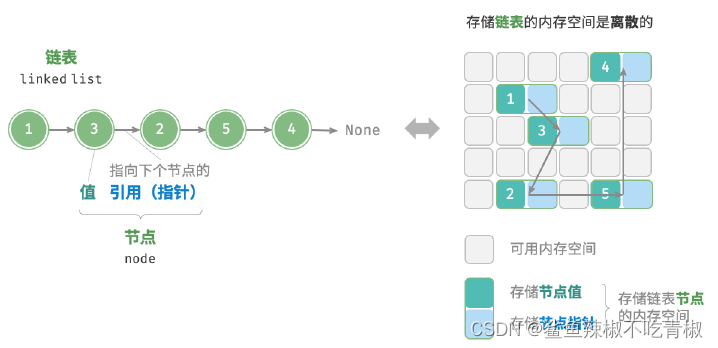
链表的组成单位是「节点node」对象。每个节点都包含两项数据:节点的“值”和指向下一节
点的“指针”。
‧ 链表的首个节点被称为“头节点”,最后一个节点被称为“尾节点”。
‧ 尾节点指向的是“空”,C++ 被记为nullptr
链表节点ListNode 除了包含值,还需额外保存一个引用(指针)。因此在相同数据量下,链
表比数组占用更多的内存空间。
结构体不能包含结构体自身,但是可以含有自身的结构体指针
/* 链表节点结构体*/
struct ListNode {
int val; // 节点值
ListNode *next; // 指向下一节点的指针
ListNode(int x) : val(x), next(nullptr) {} // 构造函数,初始化列表实现
};链表常用操作
-- 链表只能通过动态分配内存实现,
初始化链表(创建)
建立链表分为两步,第一步是初始化各个节点对象(根据需求编写上述的构造函数),第二步是构建引用指向关系。
初始化完成后,我们就可以从链表的头节点出发,通过引用指向next 依次访问所有节点。
/* 初始化链表1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
ListNode* n0 = new ListNode(1);
ListNode* n1 = new ListNode(3);
ListNode* n2 = new ListNode(2);
ListNode* n3 = new ListNode(5);
ListNode* n4 = new ListNode(4);
// 构建引用指向
n0->next = n1;
n1->next = n2;
n2->next = n3;
n3->next = n4;通常将头节点当作链表的代称,比如以上代码中的链表可被记做链表n0 。
插入节点(增)
假设我们想在相邻的两个节点n0 和n1 之间插入一个新节点P ,则只需要改变两个节点引用(指针)即可。
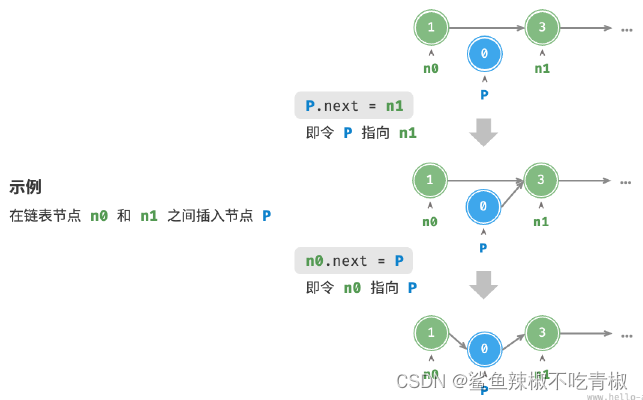
/* 在链表的节点n0 之后插入节点P */
void insert(ListNode *n0, ListNode *P) {
ListNode *n1 = n0->next; //先表明之前n0节点指向
P->next = n1;
n0->next = P;
}删除节点(删)
在链表中删除节点也非常方便,只需改变一个节点的引用(指针)即可。
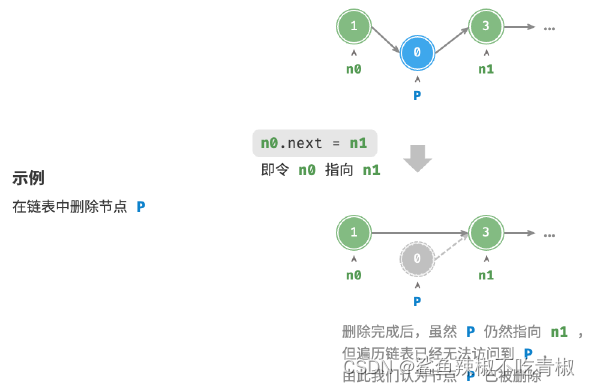
/* 删除链表的节点n0 之后的首个节点*/
void remove(ListNode *n0) {
if (n0->next == nullptr)
return;
// n0 -> P -> n1
ListNode *P = n0->next;
ListNode *n1 = P->next;
n0->next = n1;
// 释放内存
delete P;
}访问节点
在链表访问节点的效率较低。程序需要从头节点出发,逐个向后遍历,直至找到目标节点。
/* 访问链表中索引为index 的节点*/
ListNode *access(ListNode *head, int index) {
for (int i = 0; i < index; i++) {
if (head == nullptr)
return nullptr;
head = head->next;
}
return head;
}查找节点
遍历链表,查找链表内值为target 的节点,输出节点在链表中的索引。
/* 在链表中查找值为target 的首个节点*/
int find(ListNode *head, int target) {
int index = 0;
while (head != nullptr) {
if (head->val == target)
return index;
head = head->next;
index++;
}
return -1;
}数组VS 链表
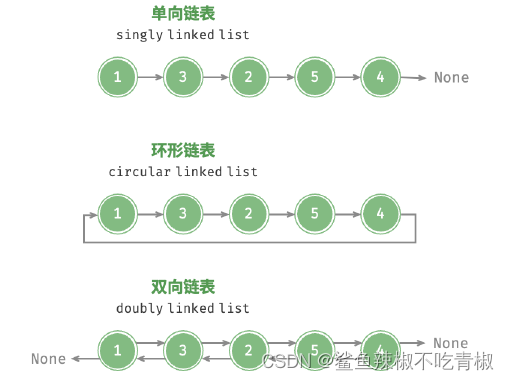
常见链表类型
常见的链表类型包括三种。
‧ 单向链表:即上述介绍的普通链表。单向链表的节点包含值和指向下一节点的引用两项数据。我们将首个节点称为头节点,将最后一个节点称为尾节点,尾节点指向空None 。
‧ 环形链表:如果我们令单向链表的尾节点指向头节点(即首尾相接),则得到一个环形链表。在环形链表中,任意节点都可以视作头节点。
‧ 双向链表:与单向链表相比,双向链表记录了两个方向的引用。双向链表的节点定义同时包含指向后继节点(下一个节点)和前驱节点(上一个节点)的引用(指针)。相较于单向链表,双向链表更具灵活性,可以朝两个方向遍历链表,但相应地也需要占用更多的内存空间。
结构体不能包含结构体自身,但是可以含有自身的结构体指针
/* 双向链表节点结构体*/
struct ListNode {
int val; // 节点值
ListNode *next; // 指向后继节点的指针
ListNode *prev; // 指向前驱节点的指针
ListNode(int x) : val(x), next(nullptr), prev(nullptr) {} // 构造函数
};4.3 列表(动态数组)
数组长度不可变导致实用性降低。为解决此问题,出现了一种被称为「动态数组dynamic array」的数据结构,即长度可变的数组,也常被称为「列表list」。列表基于数组实现,继承了数组的优点,并且可以在程序运行过程中动态扩容。我们可以在列表中自由地添加元素,而无须担心超过容量限制。
列表常用操作
初始化列表
通常使用“无初始值”和“有初始值”这两种初始化方法。
/* 初始化列表*/
// 需注意,C++ 中vector 即是本文描述的list
// 无初始值
vector<int> list1;
// 有初始值
vector<int> list = { 1, 3, 2, 5, 4 };访问元素
列表本质上是数组
/* 访问元素*/
int num = list[1]; // 访问索引1 处的元素
/* 更新元素*/
list[1] = 0; // 将索引1 处的元素更新为0插入与删除元素
相较于数组,列表可以自由地添加与删除元素。在列表尾部添加元素的时间复杂度为𝑂(1) ,但插入和删除元素的效率仍与数组相同,时间复杂度为𝑂(𝑛) 。
/* 清空列表*/
list.clear();
/* 尾部添加元素*/
list.push_back(1);
list.push_back(3);
list.push_back(2);
list.push_back(5);
list.push_back(4);
/* 中间插入元素*/
list.insert(list.begin() + 3, 6); // 在索引3 处插入数字6
/* 删除元素*/
list.erase(list.begin() + 3); // 删除索引3 处的元素遍历列表
与数组一样,列表可以根据索引遍历,也可以直接遍历各元素。
/* 通过索引遍历列表*/
int count = 0;
for (int i = 0; i < list.size(); i++) {
count++;
}
/* 直接遍历列表元素*/
count = 0;
for (int n : list) {
count++;
}拼接列表
给定一个新列表list1 ,我们可以将该列表拼接到原列表的尾部。
/* 拼接两个列表*/
vector<int> list1 = { 6, 8, 7, 10, 9 };
// 将列表list1 拼接到list 之后
list.insert(list.end(), list1.begin(), list1.end());排序列表
完成列表排序后,我们便可以使用在数组类算法题中经常考察的“二分查找”和“双指针”算法。
/* 排序列表*/
sort(list.begin(), list.end()); // 排序后,列表元素从小到大排列列表实现
















 3072
3072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









