







读书的时候,不要时时刻刻都去咬文嚼字,若是遇到了瓶颈,不妨先退一步,再登高数步,尽量往高处走一走,不登山峰,不显平地。
1.集合的好处
之前保存多个数据使用的是数组,但是数组有不足的地方:
- 长度开始时必须指定,而且一旦指定,不能更改。
- 保存的必须为同一类型元素。
- 使用数组进行增加/删除元素比较麻烦。
集合的好处:
- 可以动态保存任意多个对象。
- 提供一系列方便的操作对象方法:add、remove、set、get等。
- 使用集合添加删除新元素方便。
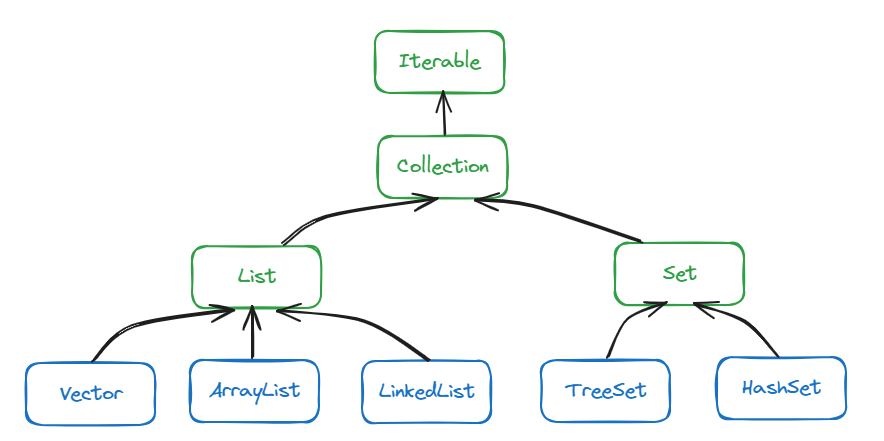
2.集合的框架体系
Java集合主要分为两大类
Collection 单列集合
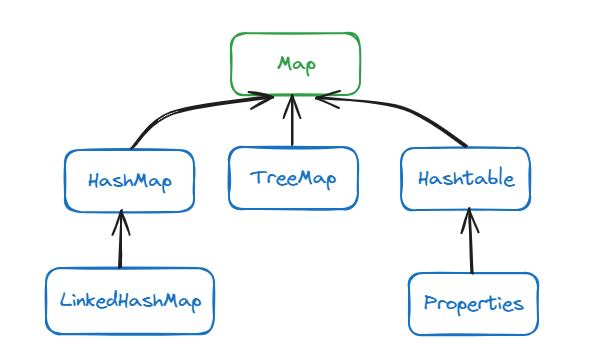
Map 双列集合 key-value
3.Collection接口
3.1 特点
- Collection实现子类可以存放多个元素,每个元素可以是Object。
- Collection的实现类,可以存放重复的元素,有些不可以。
- Collection的实现类,有些是有序的(List),有些不是有序的(Set)。
- Collection接口没有直接的实现子类,是通过它的子接口Set和List来实现的。
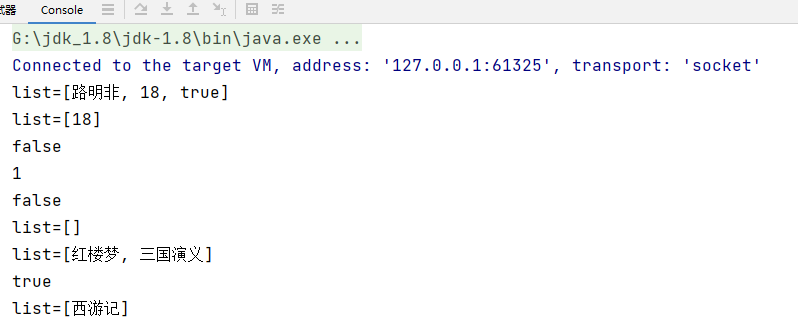
代码示例
public static void main(String[] args) {
List list = new ArrayList();
// add:添加单个元素
list.add("jack");
list.add(10);
list.add(true);
System.out.println("list=" + list);
// remove:删除指定元素
list.remove(0); //删除第一个元素
list.remove(true); //指定删除某个元素
System.out.println("list=" + list);
// contains:查找元素是否存在
System.out.println(list.contains("jack"));
// size:获取元素个数
System.out.println(list.size());
// isEmpty:判断是否为空
System.out.println(list.isEmpty());
// clear:清空
list.clear();
System.out.println("list=" + list);
// addAll:添加多个元素
ArrayList list2 = new ArrayList();
list2.add("红楼梦");
list2.add("三国演义");
list.addAll(list2);
System.out.println("list=" + list);
// containsAll:查找多个元素是否都存在
System.out.println(list.containsAll(list2));
// removeAll:删除多个元素
list.add("聊斋");
list.removeAll(list2);
System.out.println("list=" + list);//[聊斋]
}输出结果
3.2 遍历元素 - 使用 Iterator (迭代器)
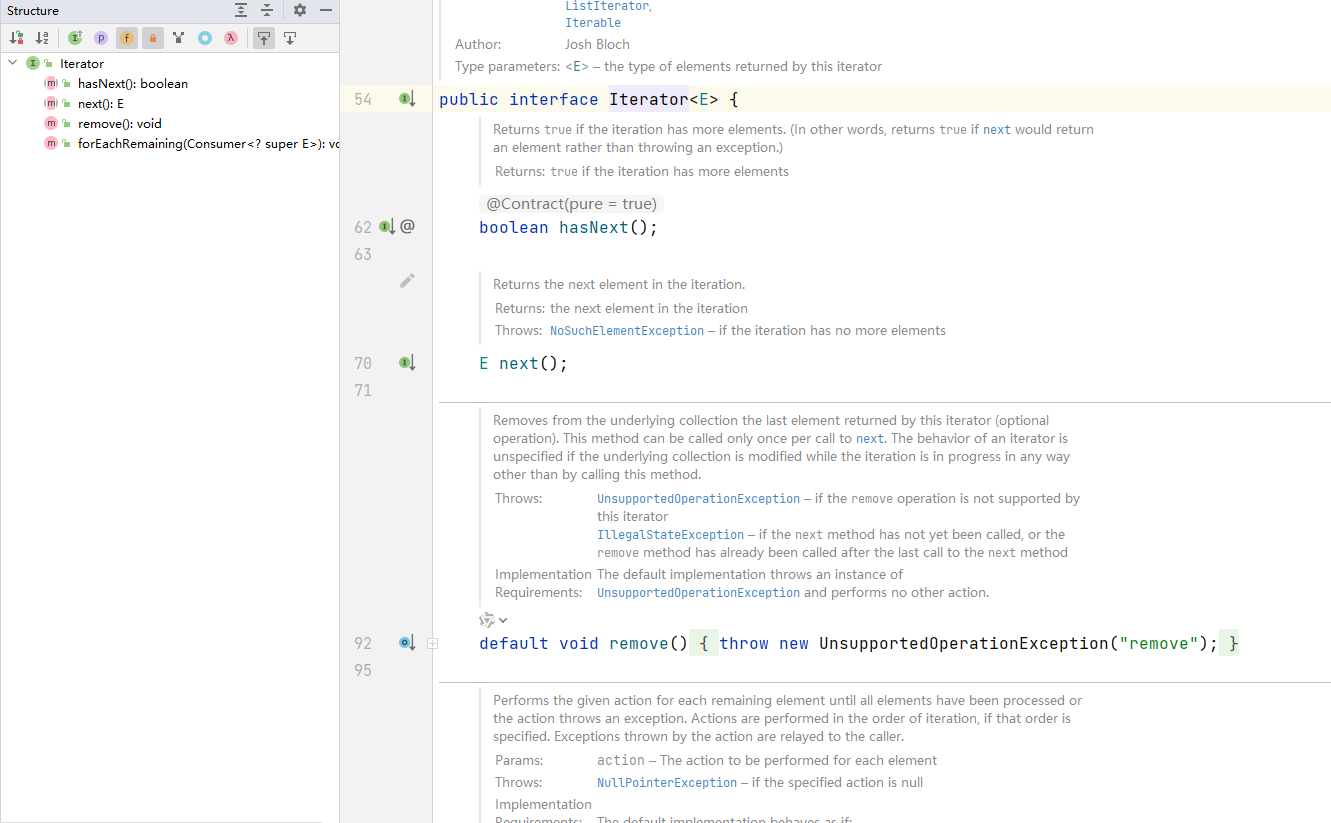
注意
在调用 iterator.next()方法之前必须要调用 iterator.hasNext()进行检测。若不调用,且下一条数据无效,直接调用 it.next()会抛出 NoSuchElementException异常。
代码示例
public static void main(String[] args) {
// 创建一个集合
Collection col = new ArrayList();
col.add(new Book("三国演义", "罗贯中", 50));
col.add(new Book("小李飞刀", "古龙", 40));
col.add(new Book("红楼梦", "曹雪芹", 60));
// 使用迭代器进行遍历
// 1. 先得到 col 对应的 迭代器
Iterator iterator = col.iterator();
// 2. 使用 while 循环遍历
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
// 3. 当退出 while 循环后 , 这时 iterator 迭代器,指向最后的元素
// iterator.next(); //NoSuchElementException
// 4. 如果希望再次遍历,需要重置我们的迭代器
iterator = col.iterator();
System.out.println("===第二次遍历===");
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
}
class Book {
private String name;
private String author;
private double price;
//......
}
3.3 遍历元素 - 增强for循环
简化版的 iterator,本质一样。
代码示例
public static void main(String[] args) {
// 创建集合
List list = new ArrayList();
list.add(new Dog("小黑", 3));
list.add(new Dog("大黄", 100));
list.add(new Dog("大壮", 8));
// 使用 for 增强
for (Object dog : list) {
System.out.println("dog=" + dog);
}
// 使用迭代器
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object dog = iterator.next();
System.out.println("dog=" + dog);
}
}
class Dog {
private String name;
private int age;
//......
}4.List接口和常用方法
介绍
List接口是Collection的子接口。
特点
- List集合类中的元素有序、且可以重复。
- List集合中每个元素都有其对应的顺序索引,可以根据索引存取元素。
4.1 ArrayList(线程不安全,改查效率高)
介绍
- 可以加入null,并且多个。
- 底层是用数组来实现数据存储的。
- 基本等同于Vector,但是ArrayList是线程不安全的(执行效率高),在多线程的情况下,不建议使用ArrayList。
ArrayList的底层操作机制
1. ArrayList中维护了一个Object类型的数组 elementData。
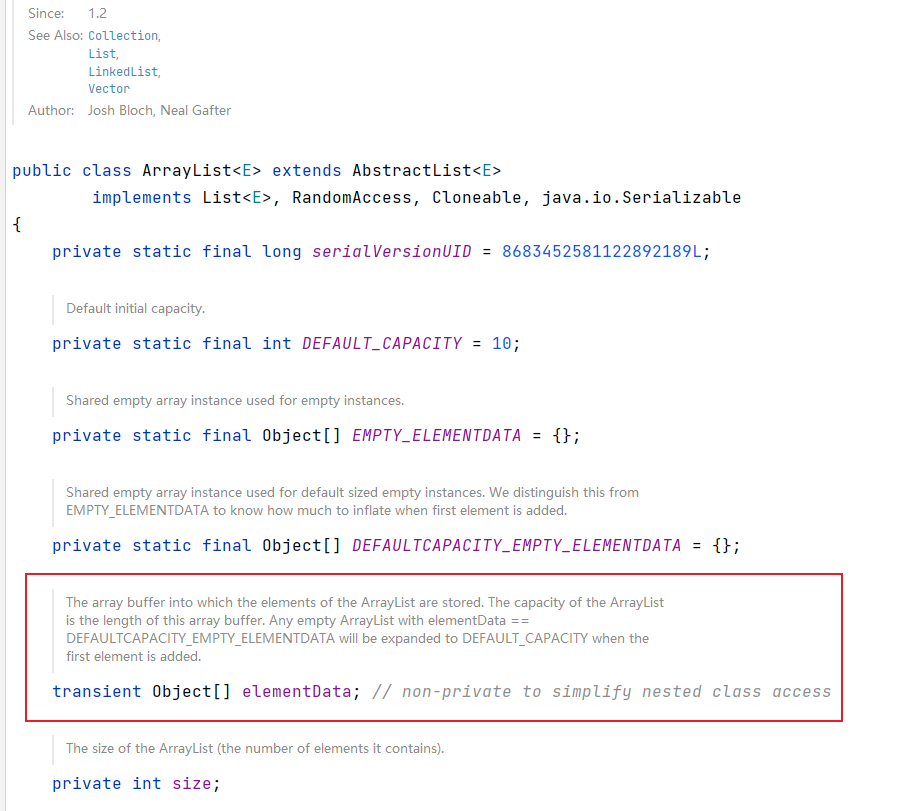
2. 当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容为10,如果需要再次扩容,则扩容elementData为1.5倍。
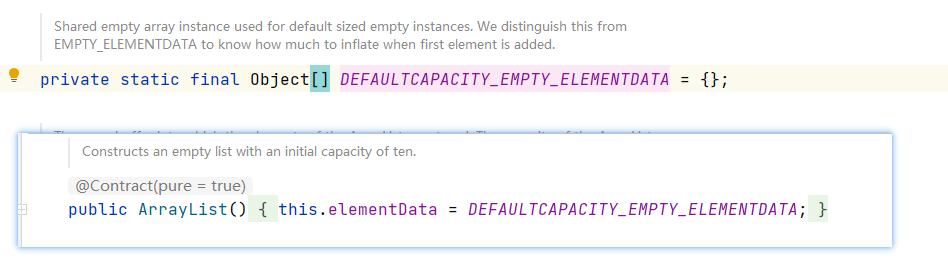
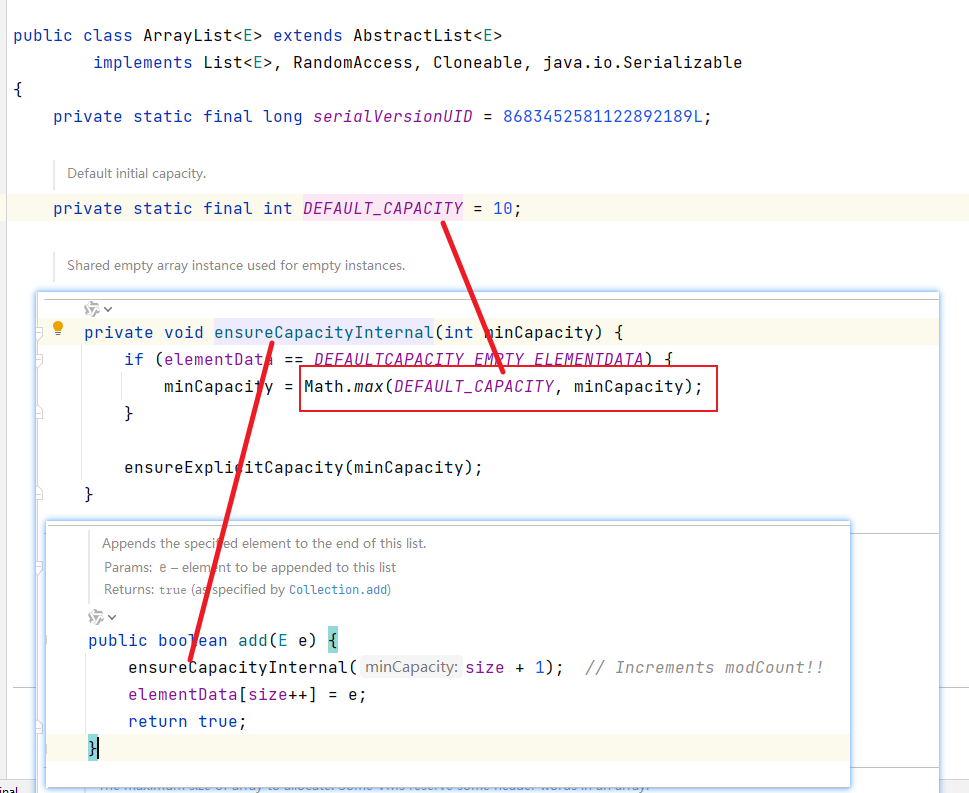
3. 如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,这直接扩容elementData为1.5倍。
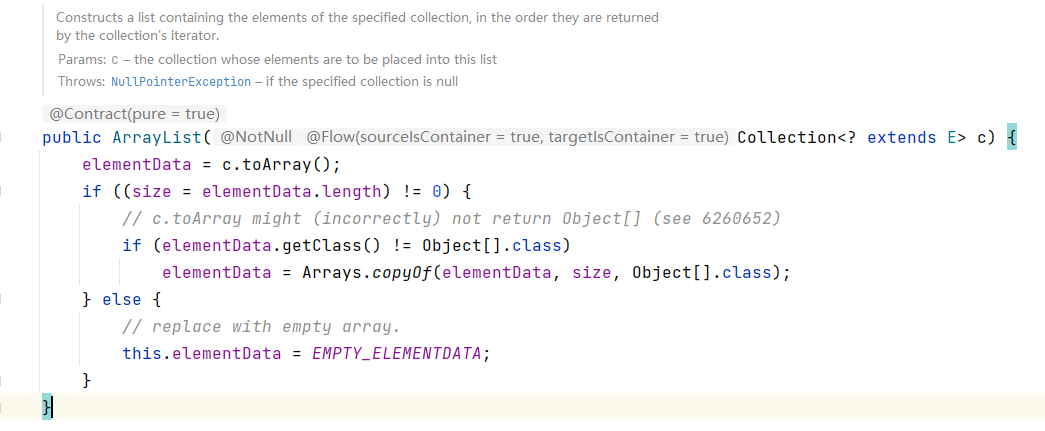
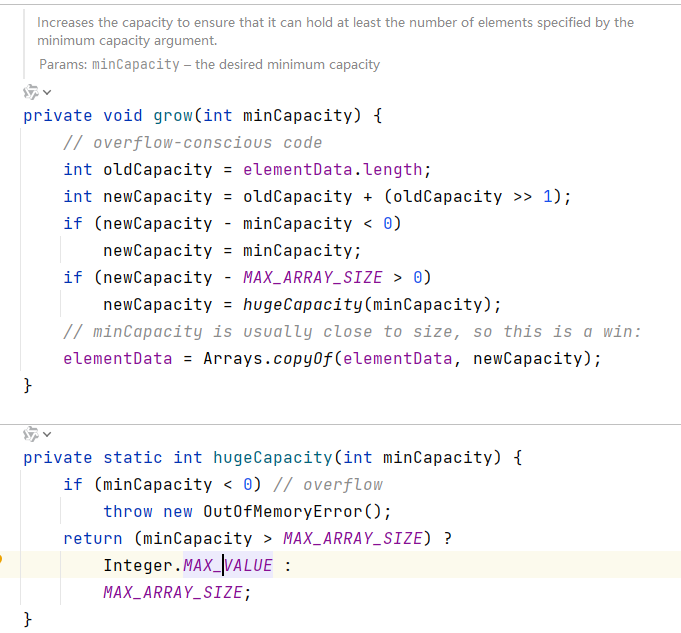
4.2 Vector(线程安全)
底层结构和源码
1. Vector底层也是一个对象数组。
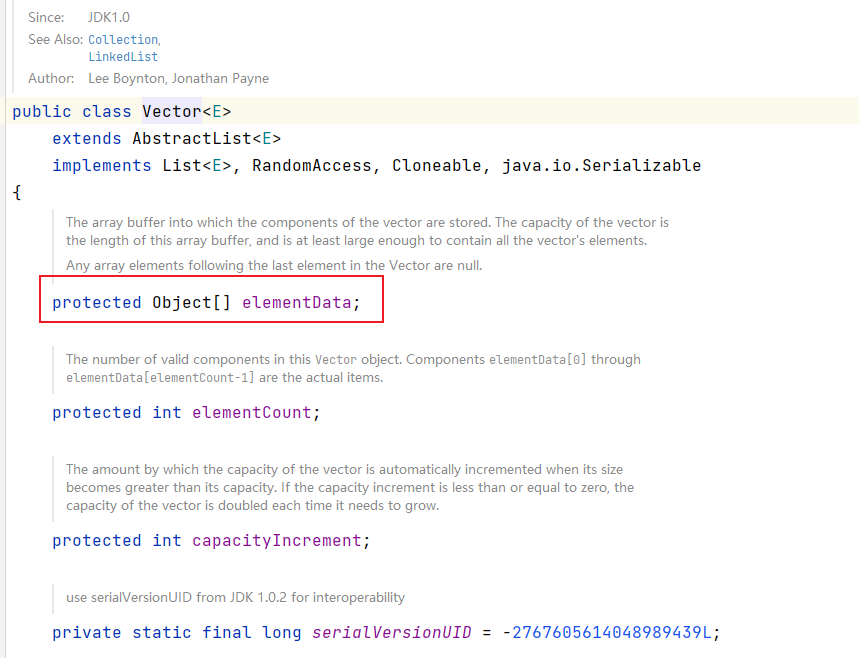
2. Vector是线程同步的,即线程安全,操作方法带有 synchronized关键字。
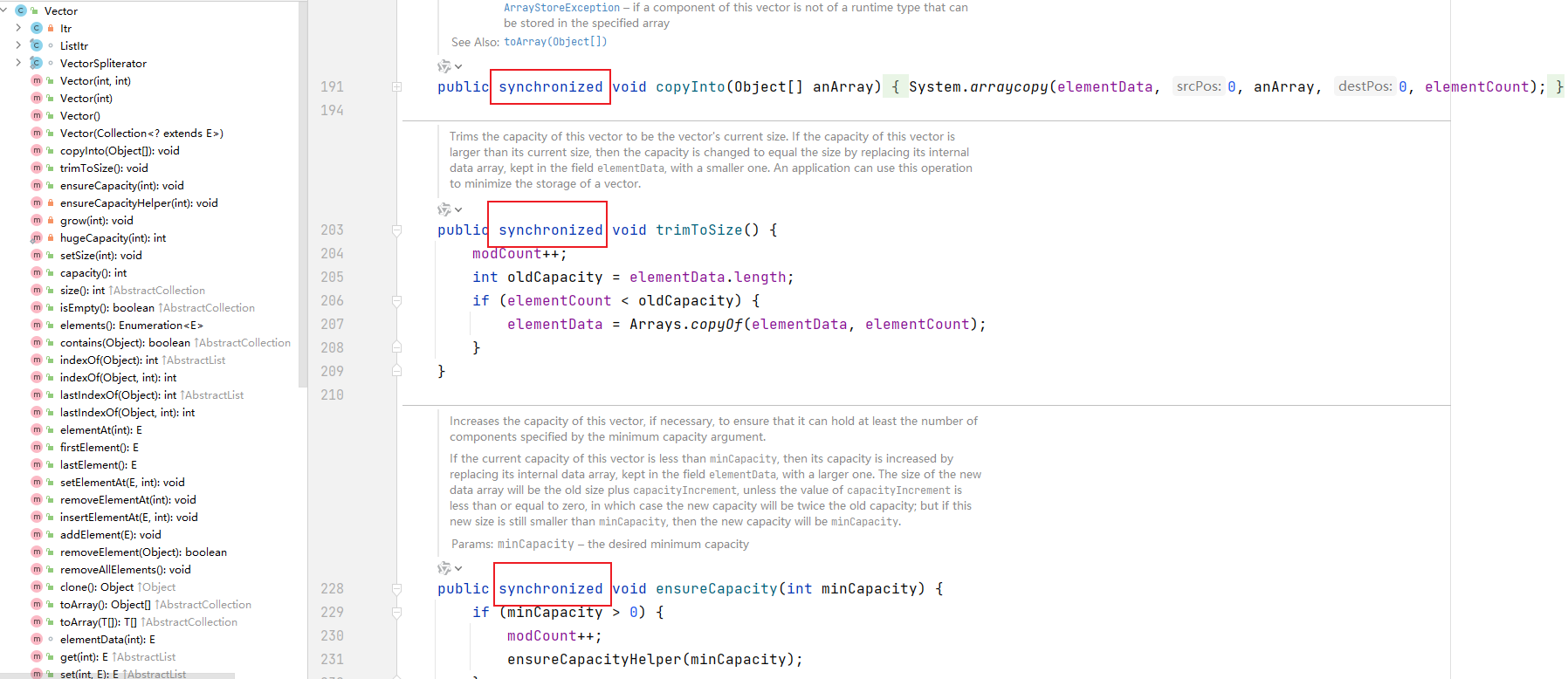

3. 在开发中,需要线程同步安全时,考虑使用Vector。
ArrayList和Vector的比较
| 底层结构 | 版本 | 线程安全 | 扩容机制 | |
|---|---|---|---|---|
| ArrayList | 可变数组 Object[] | jdk1.2 | 不安全、效率高 | 有参1.5倍 无参 第一次10 第二次开始1.5倍 |
| Vector | 可变数组 Object[] | jdk1.0 | 安全、效率不高 | 无参 默认10 满后,按2倍扩容 有参,每次2倍扩容 |
4.3 LinkedList(线程不安全,增删效率高)
特点
- LinkedList底层实现了双向链表和双端队列的特点。
- 可以添加任意元素,元素可以重复,包括null。
- 线程不安全。
底层操作机制
1. LinkedList底层维护了一个双向链表,其中维护了两个属性first和last分别指向首节点和尾节点。
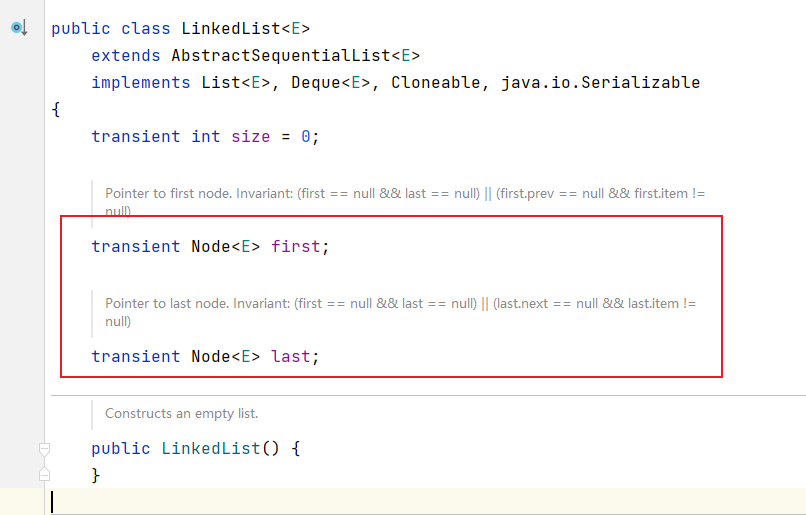
2. 每个节点(Node对象),里面又维护了prev、next、item三个属性,其中通过prev指向前一个,通过next执行后一个节点。最终实现双向链表。
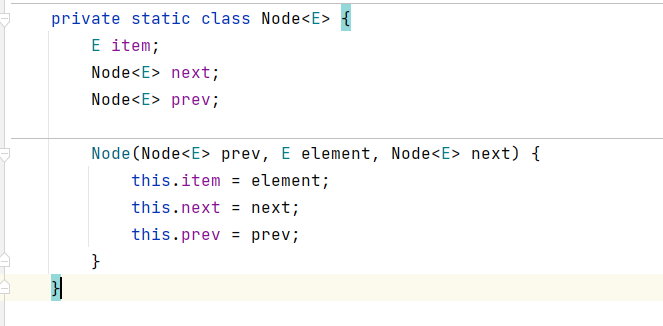
3. 所以LinkedList的元素的添加和删除,不是通过数组完成的,相对来说效率较高。

代码示例
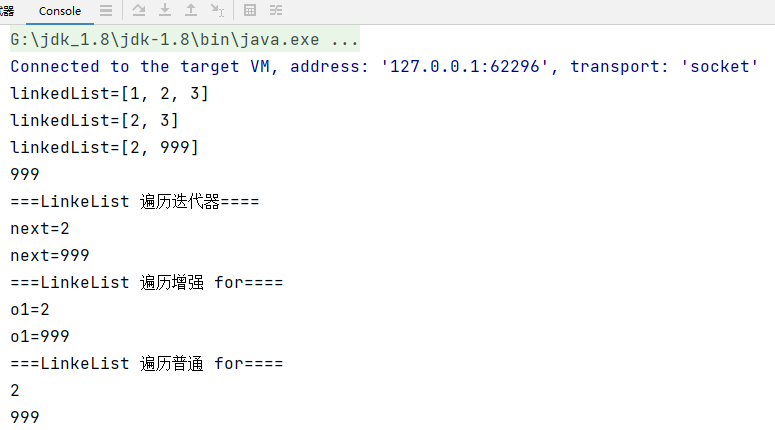
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
System.out.println("linkedList=" + linkedList);
// 演示一个删除结点的
linkedList.remove(); // 这里默认删除的是第一个结点
System.out.println("linkedList=" + linkedList);
// 修改某个结点对象
linkedList.set(1, 999);
System.out.println("linkedList=" + linkedList);
// 得到某个结点对象
Object o = linkedList.get(1);
System.out.println(o);
// 因为 LinkedList 是 实现了 List 接口, 遍历方式
System.out.println("===LinkeList 遍历迭代器====");
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("next=" + next);
}
System.out.println("===LinkeList 遍历增强 for====");
for (Object o1 : linkedList) {
System.out.println("o1=" + o1);
}
System.out.println("===LinkeList 遍历普通 for====");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
}输出结果
ArrayList和LinkedList比较
| 底层结构 | 增删的效率 | 改查的效率 | |
|---|---|---|---|
| ArrayList | 可变数组 | 较低 | 较高 |
| LinkedList | 双向链表 | 较高,通过链表追加 | 较低 |
怎么选择
- 如果在业务中的改查操作多,选择ArrayList。
- 如果在业务中的增删操作多,选择LinkedList。
- 一般来说,在程序中,80%-90%的业务都是查询,因此,大部分情况下会选择ArrayList。
5.Set接口和常用方法
特点
- 无序(添加和取出的顺序不一致),没有索引。
- 不允许重复元素,最多包含一个null。
5.1 HashSet(无重复元素,无序)
HashSet底层实际上是HashMap。
代码示例
public static void main(String[] args) {
HashSet set = new HashSet();
// 1. 在执行 add 方法后,会返回一个 boolean 值
// 2. 如果添加成功,返回 true, 否则返回 false
// 3. 可以通过 remove 指定删除哪个对象
System.out.println(set.add("john"));//T
System.out.println(set.add("lucy"));//T
System.out.println(set.add("john"));//F
System.out.println(set.add("jack"));//T
System.out.println(set.add("Rose"));//T
set.remove("john");
System.out.println("set=" + set);//3 个
}5.2 TreeSet(无重复元素,升序)
不允许有重复元素的有序集合。
TreeSet 中的元素默认按照自然顺序(升序)进行排序。如果你想要自定义排序顺序,可以通过提供一个 Comparator 对象给 TreeSet 的构造器来实现。
TreeSet 不是线程安全的。如果你需要在多线程环境下使用 TreeSet,你需要自己处理同步问题,或者使用 Collections.synchronizedSortedSet 方法来获取一个线程安全的 SortedSet。
代码示例
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
// 添加元素
set.add(3);
set.add(1);
set.add(2);
// 输出集合,元素会按照升序排列
System.out.println(set); // 输出 [1, 2, 3]
// 尝试添加重复元素
set.add(2);
// 再次输出集合,重复的元素不会被添加
System.out.println(set); // 输出 [1, 2, 3]
// 自定义排序
TreeSet<String> stringSet = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
stringSet.add("Apple");
stringSet.add("banana");
stringSet.add("Cherry");
System.out.println(stringSet); // 输出 [Apple, banana, Cherry],字符串按照不区分大小写的顺序排列
}6.Map接口和常用方法
特点
- Map与Collection是并列存在。
- Map中的key和value可以是任何引用类型的数据。
- Map的key不允许重复,value可以重复。
- Map的key只能有一个为null,value可以有多个。
- 常用String类作为key。
- key和value之间存在单向一对一关系,即通过key总能找到对应的value。
6.1 HashMap(线程不安全)
HashMap是Map接口使用频率最高的实现类。
代码示例
public static void main(String[] args) {
Map map = new HashMap();
map.put("邓超", "孙俪");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("刘令博", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
// 第一组: 先取出 所有的 Key , 通过 Key 取出对应的 Value
Set keyset = map.keySet();
(1) 增强 for
System.out.println("-----第一种方式-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
// (2) 迭代器
System.out.println("----第二种方式--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
// 第二组: 把所有的 values 取出
Collection values = map.values();
// (1) 增强 for
System.out.println("---取出所有的 value 增强 for----");
for (Object value : values) {
System.out.println(value);
}
// (2) 迭代器
System.out.println("---取出所有的 value 迭代器----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
// 第三组: 通过 EntrySet 来获取 k-v
Set entrySet = map.entrySet();// EntrySet<Map.Entry<K,V>>
// (1) 增强 for
System.out.println("----使用 EntrySet 的 for 增强(第 3 种)----");
for (Object entry : entrySet) {
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
// (2) 迭代器
System.out.println("----使用 EntrySet 的 迭代器(第 4 种)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
}6.2 Hashtable(线程安全)
特点
- Hashtable使用方法基本上和HashMap一样。
- Hashtable的k-v都不能为null。
- Hashtable是线程安全的,HashMap是线程不安全的。
6.3 TreeMap(线程不安全,有序)
特点
TreeMap中的元素总是按照键的自然顺序或者创建TreeMap时提供的Comparator进行排序。- 和大多数的 Java 集合类一样,
TreeMap不是线程安全的。
代码示例
public static void main(String[] args) {
TreeMap<Integer, String> treeMap = new TreeMap<>();
// 添加元素
treeMap.put(3, "Three");
treeMap.put(1, "One");
treeMap.put(2, "Two");
// 输出集合,元素会按照键的升序排列
System.out.println(treeMap); // 输出 {1=One, 2=Two, 3=Three}
// 获取第一个键和最后一个键
System.out.println("First key: " + treeMap.firstKey()); // 输出 First key: 1
System.out.println("Last key: " + treeMap.lastKey()); // 输出 Last key: 3
// 获取子映射
TreeMap<Integer, String> subMap = (TreeMap<Integer, String>) treeMap.subMap(1, 3);
System.out.println("Submap: " + subMap); // 输出 Submap: {1=One, 2=Two}
}7.开发中如何选择集合实现类
在开发中,选择什么集合实现类,主要取决于业务操作特点,然后根据集合实现特性进行选择。
1. 先判断存储的类型
是一组对象【单列】还是一组键值对【双列】。
2. 在判断是否允许重复
如果是一组对象【单列】:Collection接口
允许重复:List
- 增删多:LinkedList【底层是一个双向链表】
- 改查多:ArrayList【底层是一个可变数组】
不允许重复:Set
- 无序:HashSet
- 排序:TreeSet
- 插入和取出顺序一致:LinkedHashSet
8.Collections工具类
介绍
- Collections是一个操作Set、List、Map等集合的工具类。
- Collections中提供了一系列静态方法对集合元素进行排序、查询、和修改等操作。
主要方法和功能
1. 排序
sort(List<T> list):对列表进行自然排序。sort(List<T> list, Comparator<? super T> c):使用指定的比较器对列表进行排序。reverse(List<?> list):反转列表中元素的顺序。shuffle(List<?> list):对列表中的元素进行随机排序(洗牌)。swap(List<?> list, int i, int j):在列表中交换指定位置的两个元素。
2. 搜索与查找
binarySearch(List<? extends Comparable<? super T>> list, T key):使用自然顺序对列表进行二分查找。binarySearch(List<?> list, T key, Comparator<? super T> c):使用指定的比较器对列表进行二分查找。max(Collection<? extends T> coll)和min(Collection<? extends T> coll):返回集合中的最大和最小元素(根据自然顺序或比较器)。frequency(Collection<?> c, Object o):返回指定元素在集合中出现的次数。
3. 不可变集合
emptyList()、emptyMap()、emptySet():返回不可变的空集合。singletonList(T o)、singletonMap(K key, V value)、singleton(T o):返回只包含一个元素的不可变集合。unmodifiableList(List<? extends T> list)、unmodifiableSet(Set<? extends T> set)、unmodifiableMap(Map<? extends K, ? extends V> m)等:返回指定集合的不可变视图。
















 3021
3021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









