






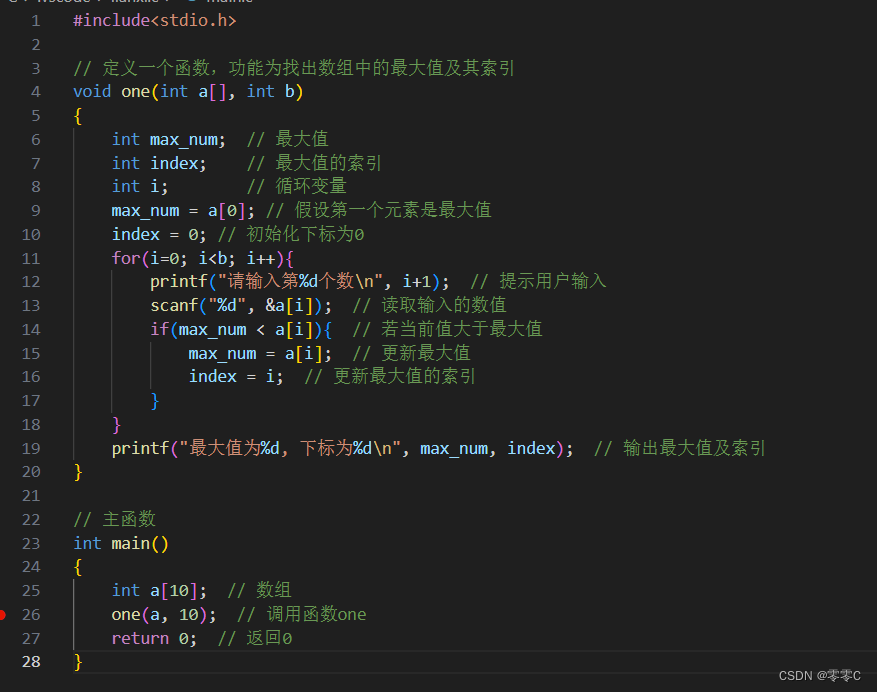
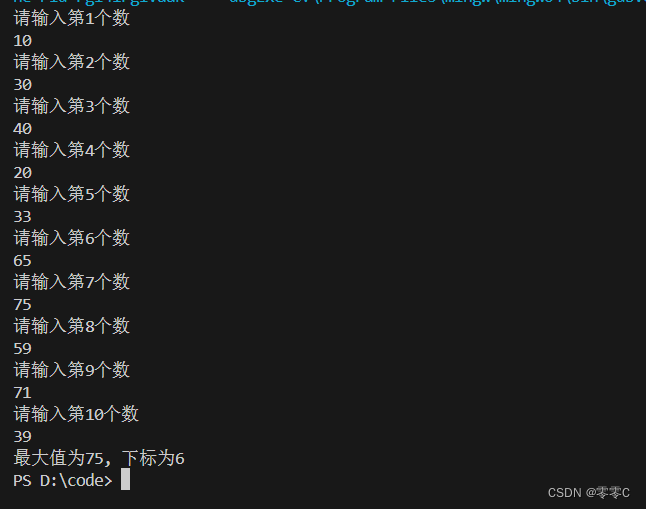
1、用数组的方式输入十个数字然后比较大小,将最大值打印出来,并将该数组对应的下标也打印出来。
2、将冒泡排序法封装成函数


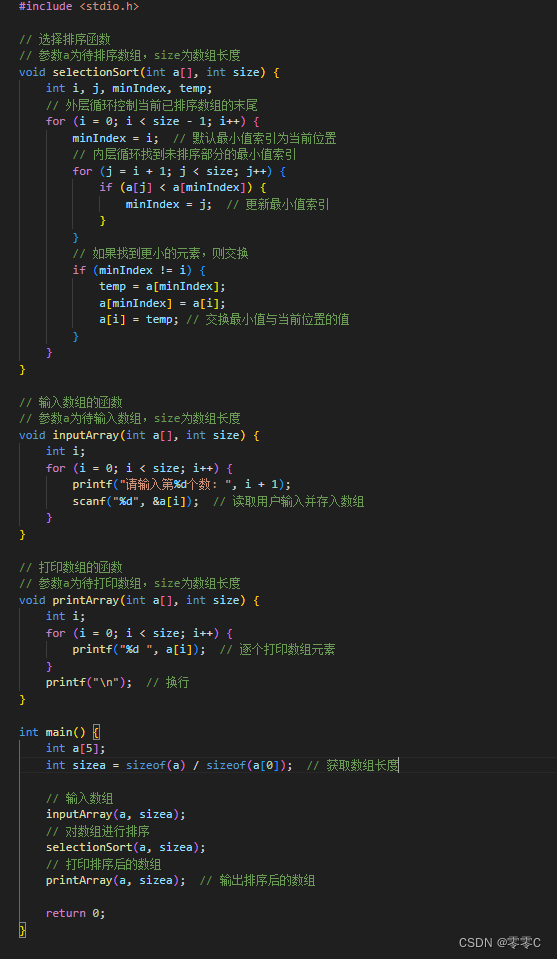
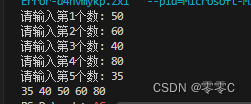
3、用函数封装简单选择排序
冒泡排序和简单选择排序的区别:
- 排序方式:
- 冒泡排序:通过重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
- 简单选择排序:首先在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
- 稳定性:
- 冒泡排序:是稳定的排序算法。如果待排序的序列中有两个或两个以上的元素相等,它们的相对位置在排序后不会发生变化。
- 简单选择排序:是不稳定的排序算法。因为简单选择排序会交换找到的最小(或最大)元素到未排序序列的起始位置,这可能会改变相等元素的相对位置。
- 效率:
- 从时间复杂度上看,两者在平均情况、最好情况和最坏情况下的时间复杂度都是O(n^2)。但是,由于冒泡排序在交换元素时可能需要多次内存读写操作(尤其是在链表中),而简单选择排序只在一轮结束时进行一次交换,所以在某些情况下,简单选择排序可能会比冒泡排序更快。
- 另一方面,冒泡排序在元素已经部分有序时,可以提前结束排序(通过设置一个标志位来判断是否进行了交换),这称为“短路冒泡排序”,而简单选择排序则没有这个优化点。
- 空间复杂度:
- 两者都是原地排序算法(in-place sorting),即只需要常数额外空间的排序算法,所以空间复杂度都是O(1)。
- 实现难度:
- 冒泡排序的实现相对简单直观,易于理解。
- 简单选择排序的实现也相对简单,但逻辑上可能比冒泡排序稍微复杂一些。
在选择使用哪种排序算法时,需要根据具体的应用场景和需求来决定。如果要求排序稳定,那么应该选择冒泡排序;如果更注重效率,尤其是在大数据集上,可能需要考虑使用更高效的排序算法,如快速排序、归并排序等。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









