







 该文章描述了一个使用C++11实现的英汉双解词典项目,涉及数据结构如Trie树、AVL树和散列表,支持查找、插入和删除功能。用户界面通过QT框架构建,程序对数据结构进行了详细的操作实现,并提供了性能测试结果。
该文章描述了一个使用C++11实现的英汉双解词典项目,涉及数据结构如Trie树、AVL树和散列表,支持查找、插入和删除功能。用户界面通过QT框架构建,程序对数据结构进行了详细的操作实现,并提供了性能测试结果。
介绍
设计实现一个小型英汉双解词典
问题描述:设计一个英汉双解电子词典,支持查找、插入、删除等功能。
基本要求:实现字典常用的数据结构包括有序表、AVL树、Patricia Tree(简称PAT tree,它是一棵压缩存储的二叉树结构)、散列表等,选一种数据结构,实现字典的基本操作,查找单词、插入单词(插入时,先查找,找不到则插入,找到则提示用户)、删除单词(删除时,先查找,找到则删除,找不到则提示用户)等。字典是按字母顺序排列的,不能用顺序查找,插入或删除单词后,要保持字典的有序性。
测试数据:任一英文单词。
整体架构
首先,作品分为数据结构部分和用户界面两部分。采用的是c++11实现,用数据结构 Trie(字典树),AVL(平衡树),Hush(散列表)分别进行相应的类,没个类里面分别实现了insert(插入),delete(删除),search(查找操作) 。对于三种数据结构的具体操作会在之后进行具体说明。用户界面采用的是C++的现成框架QT实现,QT中的大多数采用的是代码进行设计,部分才取的是ui进行设计,最后通过QT中的 connect函数 对数据结构部分和用户界面部分进行连接,实现两者的结合。
使用教程
- 使用本程序首先c++需要达到c++ 11版本,QT也需要达到最高版本才可以进行运行(原因:在本程序中运用了大量的lambda表达式,而lambda表达式需要达到c++ 11版本才可以进行)
- 由于本程序设计了文件读写的操作,但是文件路径不一定与用户相同,因此需要自备相应的单词文件,并对程序修改相应的路径。
使用说明
- 网页部分分为四个文件夹,其中 C++程序设计 那个文件夹记录写整个大程序的过程, NewDataStructure 那个文件夹是包括用户交互界面,文件读取等的整体代码(用户交互用的是QT), DataStructure 那个文件夹是单纯的数据结构部分的代码, Test 文件夹里面有一个随机生成测试数据的程序,来对后端代码进行测试。
- 由于本程序整体还是在QT上进行的,并未生成exe(可执行文件),如有想要运行,可以下载QT在上面运行
- 代码并非很好,随着本人对程序设计的学习,还会对代码进行不断的优化和升级。
- 文件读取代码对文本要求很高,需要英文单词与汉字对应,并且两者之间仅有一个空格才算成功。
对使用的数据结构进行简要的介绍
Hush散列表
对于字符串则对其进行除留取余法,首先先找到一个素数和一个取余的值,本人用的是 素数 P = 233 , 余数 mod = 1001,将字符串当作一个类似p进制数来看,假设字符串为s, len 为字符串的长度,则该字符串的hush值为 hush = s[len - 1] * p + s[len - 2] * p^2 + ... + s[0] * p^(len)。在求hush的过程中不断的对hush的值进行取模,进而保证将字符串的hush值映射到 0 - 1000 之间的一个数,而对于数据的存储,采用的是单向链表,因为hush值在 0 - 1000 的范围内,因此就初始1000个链表。插入,删除,查找,则是根据hush值在相应的表头进行查找数据。
图示数据结构(画图软件使用的一般,见谅)
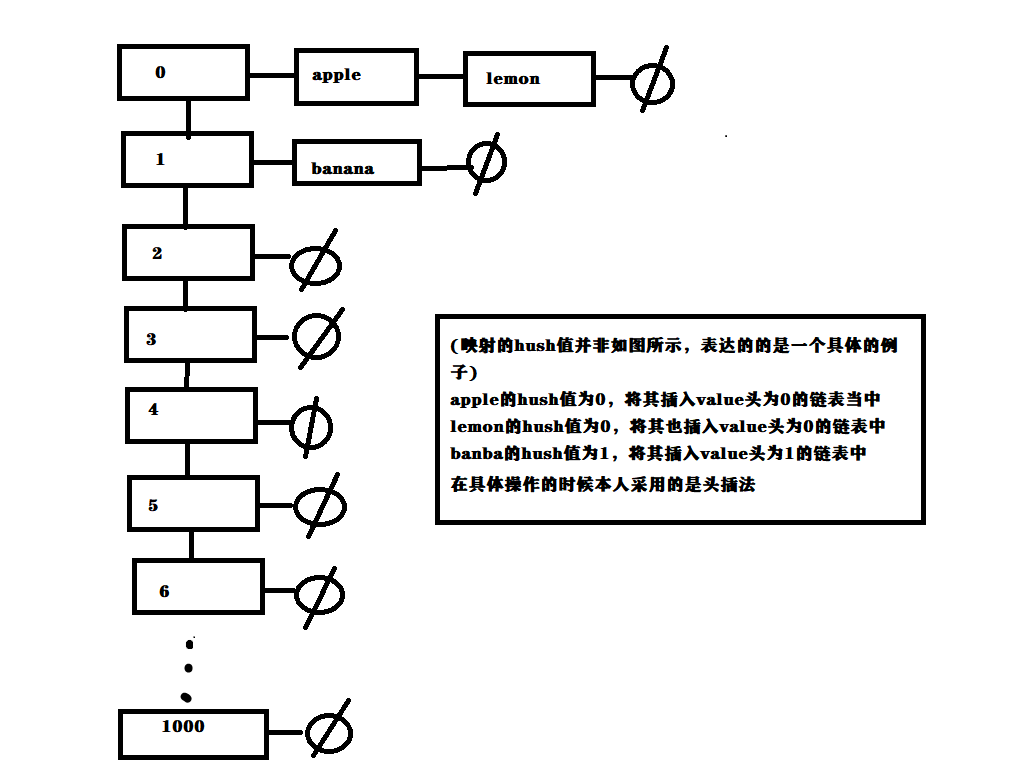
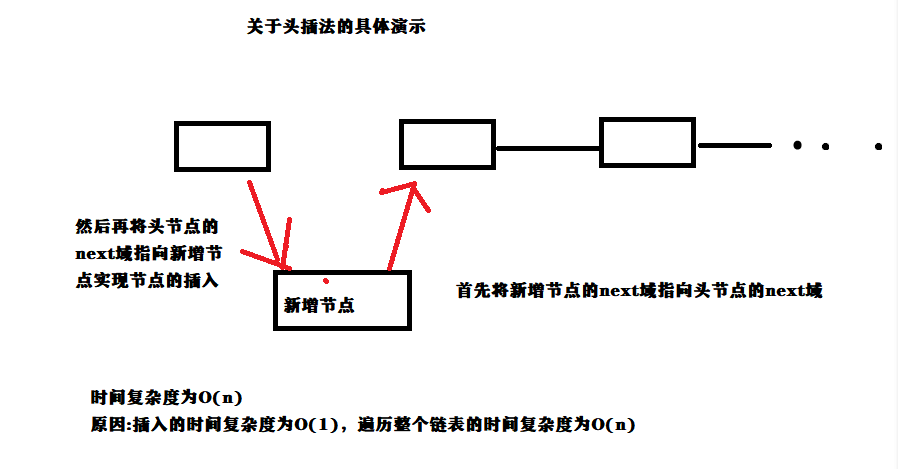
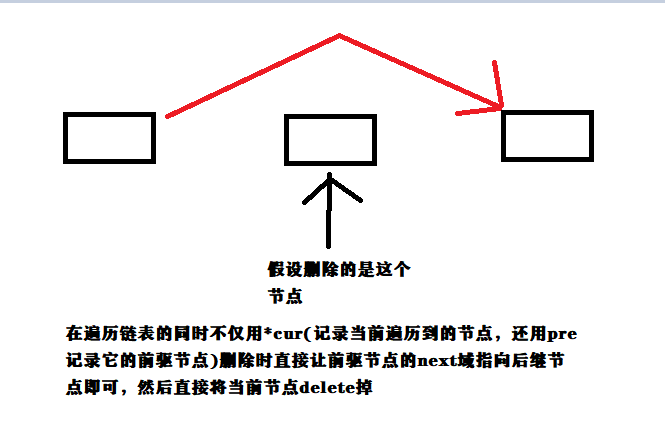
时间复杂度分析:以最理想的情况进行分析,数据量为n,这n组数据平分到 1000 个链表当中, 令 m = n / 1000,遍历整个链表为O(m)的复杂度,链表的插入,删除为O(1),整体算下来插入,删除,查找的复杂度为O(m)。当然这是最理想

。
空间复杂度分析:和单词的个数成正比
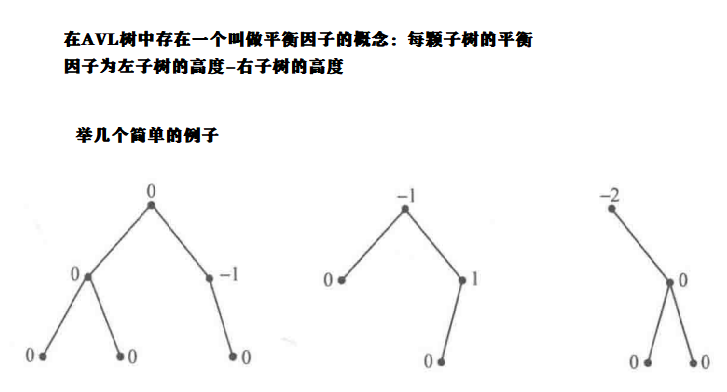
AVL(平衡树数据结构)
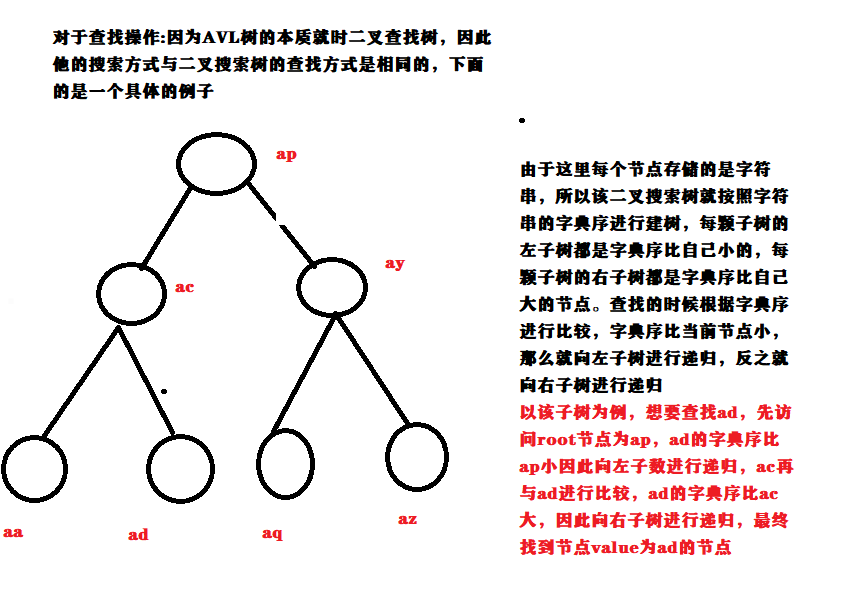
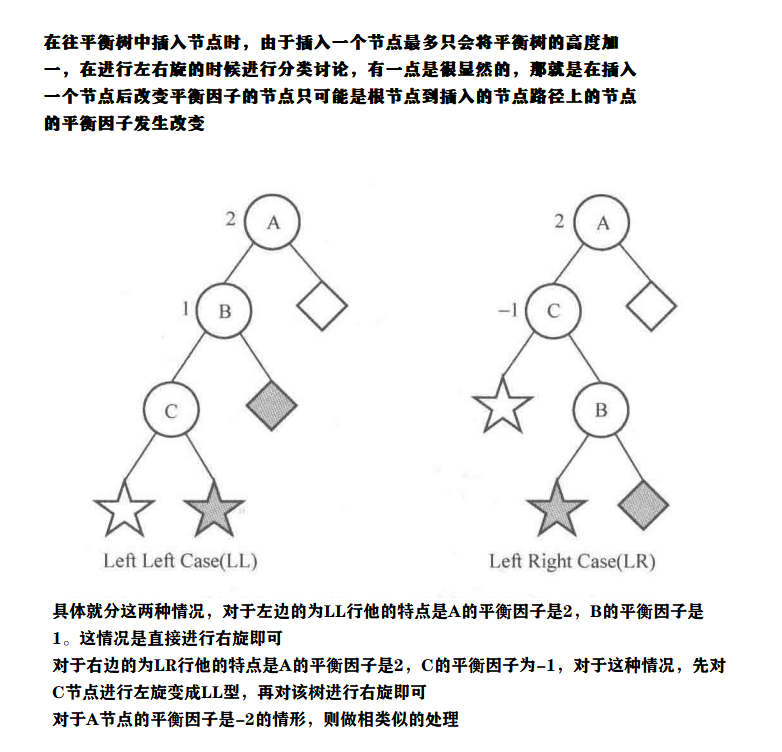
重所周知平衡树是对二叉搜索树进行的优化,对于二叉搜索树而言,如果序列越有序,则对于二叉搜索树的查找也好,删除也好都是不利的,因为二叉搜索树的查找是与二叉搜索树的深度成正比的,如果给出一个序列{1,2,3,4,5}则这样二叉搜索树的查找的时间复杂度就是O(n),如果查找次数为m,则整体时间复杂度为O(mn),AVL树则是对其进行的优化,在插入删除的同时对树进行左旋和右旋操作,进而保证树的高度为log(n),这样查找的速度就成了log级别的了
图示数据结构(参考书籍算法笔记)
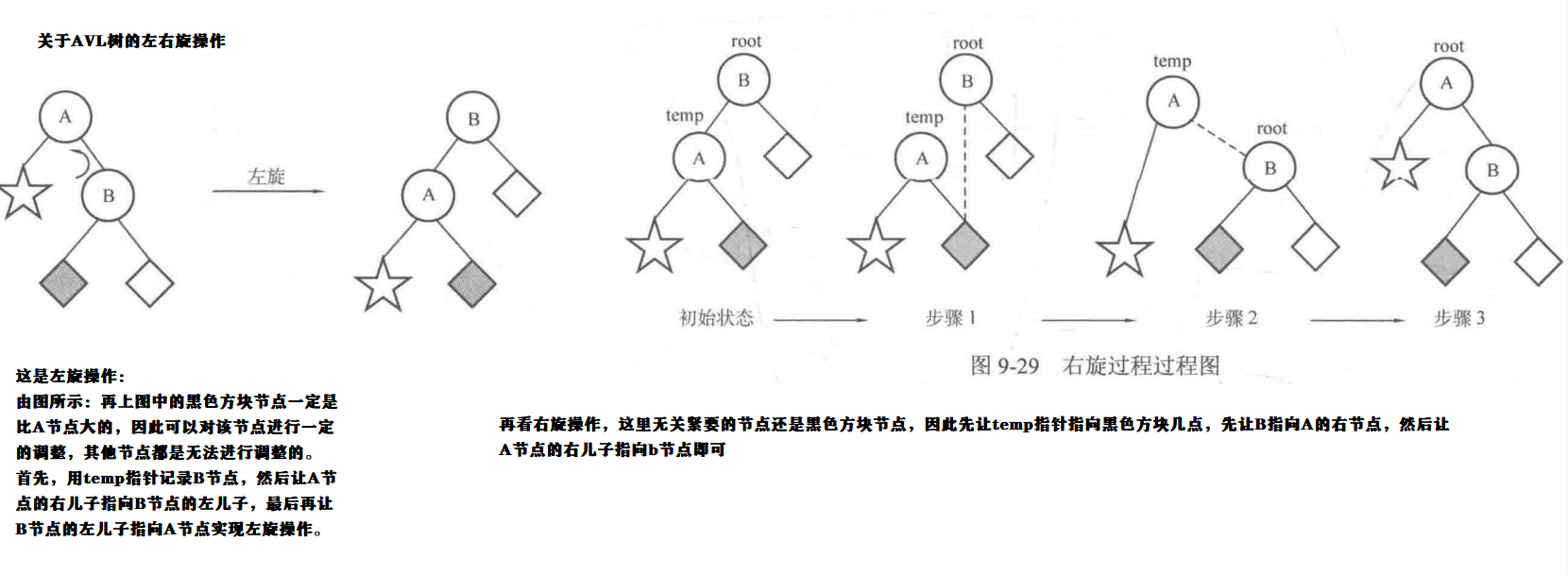
关于左旋代码
//通过左旋来对AVL树进行调整高度
AVLnode<pair<string, string> >* AVL::leftRotate(AVLnode<pair<string, string> >* u) {
//temp指向当前节点的右子树
AVLnode<pair<string, string> >* temp = u->rchild;
//调制的节点的右子树指向他右子树的左子树
u->rchild = temp->lchild;
//让右子树的左子树指向需要调制的节点
temp->lchild = u;
//更新调整的两个节点的高度,而他们的子树的高度并未发生该变
updataHeight(u);
updataHeight(temp);
return temp;
}
关于右旋代码
//通过右旋来对AVL树进行调整高度
AVLnode<pair<string, string> >* AVL::rightRotate(AVLnode<pair<string, string> >* u) {
//temp指向当前节点的左子树
AVLnode<pair<string, string> > *temp = u->lchild;
//让调制节点的左子树指向他的左节点的右子树
u->lchild = temp->rchild;
//让temp的右子树指向当前节点
temp->rchild = u;
//调整平衡树的高度
updataHeight(u);
updataHeight(temp);
return temp;
}
时间复杂度分析:查找,删除,插入均与高度成正比,因此为O(nlog(n))
空间复杂度分析:与单词个数成正比
Trie(字典树)
基本原理:Trie上的每个节点看作一个字母,在进行插入时,如果存在该字母的节点,则向这个字母的节点进行插入接下来的字母节点。直到走完整个单词为止。
图示算法
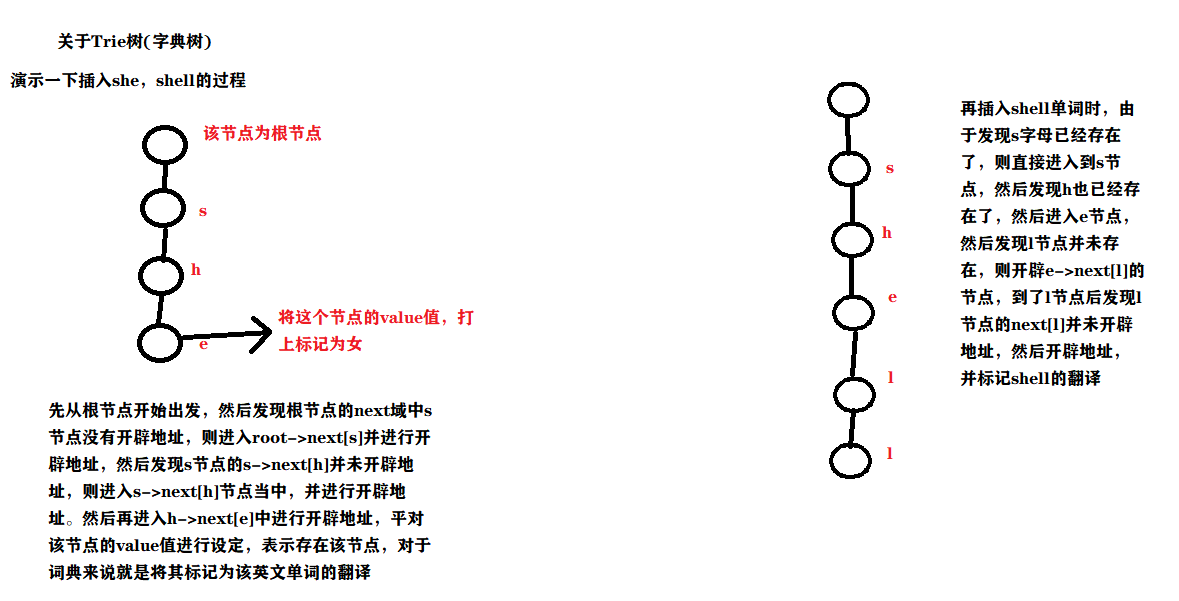
时间复杂度分析:插入单个单词,查找单个单词与单词的长度成真比,因此插入时间复杂度O(n * len(words)),查找O(m * len(words)) 其中m为操作数,len为单词长度,n为单词个数
空间分析:对于Trie的每一层分配300个节点(因为ASCII差步多300个),最长的单词有50个字母,因此一共50层,空间差步多为300 * 50;
可以看出Trie还时比较省空间的,但时其局限性也可以看出来,只能对ASCII以内的字符进行处理。
关于对软件数据的测试
对于测试数据,本人采用的是c语言的随机种子,生成相应的字符串,和相应的数字。如果有感兴趣的可以看一看Test文件夹里面的cpp程序。
生成完数据后开始对数据结构部分进行测试(QT仅负责对数据结构部分与用户界面进行连接,如若数据结构部分的测试并未出现异常,那么整个程序则不存在重要bug)
首先rand()出操作数 1 2 3;1代表插入操作,2代表删除操作,3代表查找操作。
以下为三种数据结构测试十万组随机数据的测试结果
AVL树的测试结果
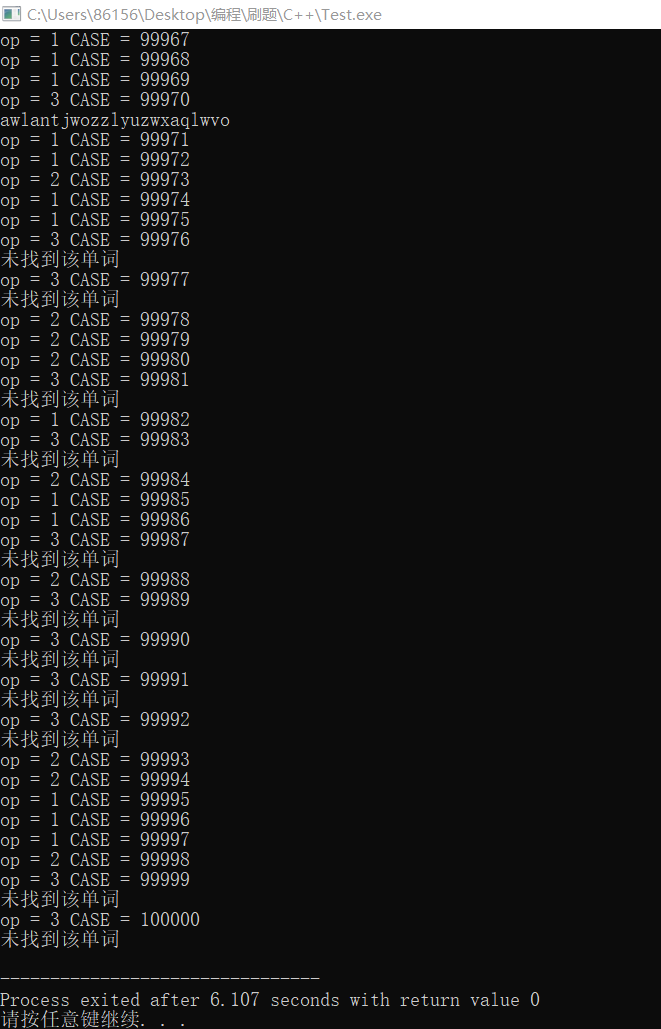
Trie树的测试结果
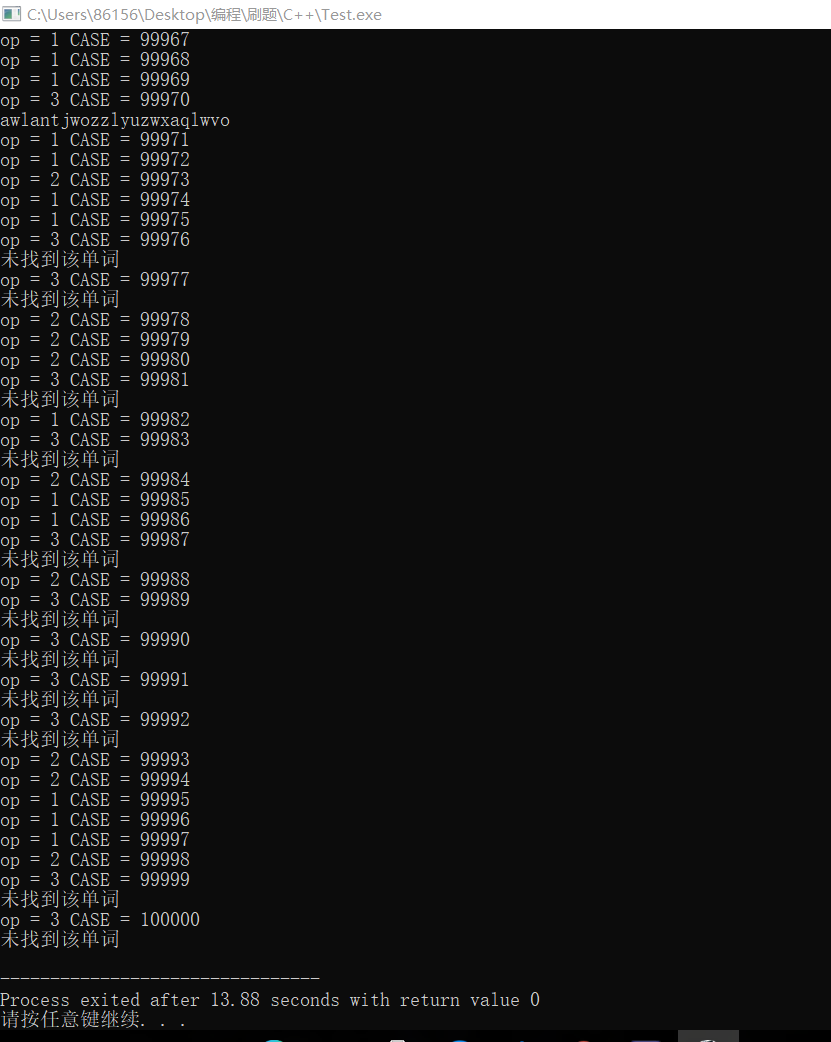
Hush散列表的测试结果
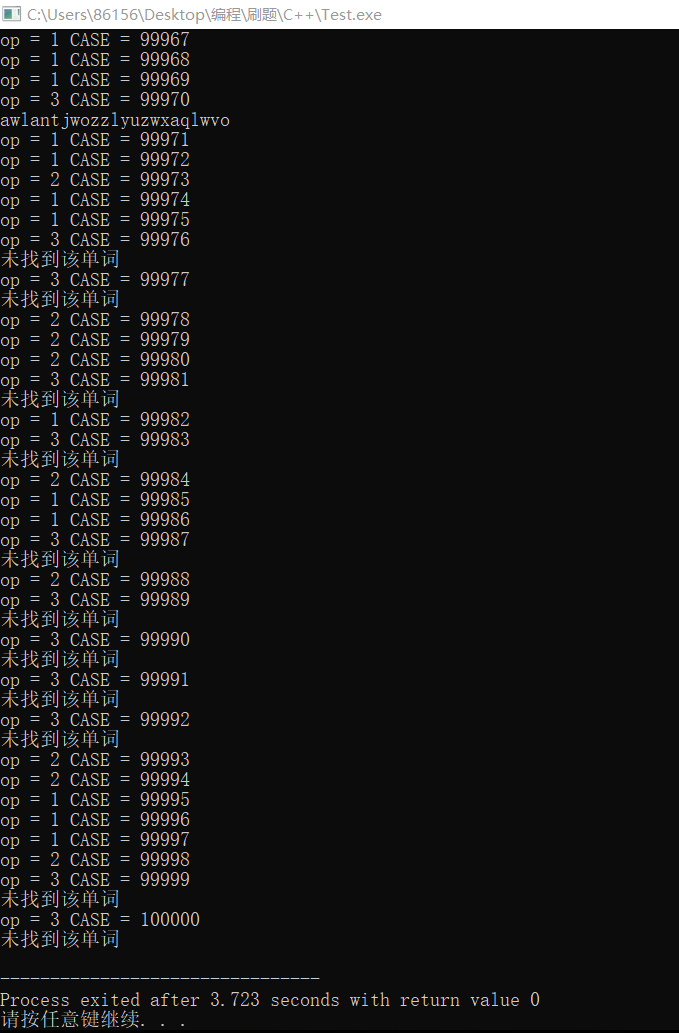
可以从编译到运行,最慢的也仅用了14秒,这里面包括了打印数据的时间,如果是直接往文件里写数据,则会更快
用户交互界面的一些截图
初始界面(点击start进入下一个页面)

选择数据结构界面
词典使用时的界面

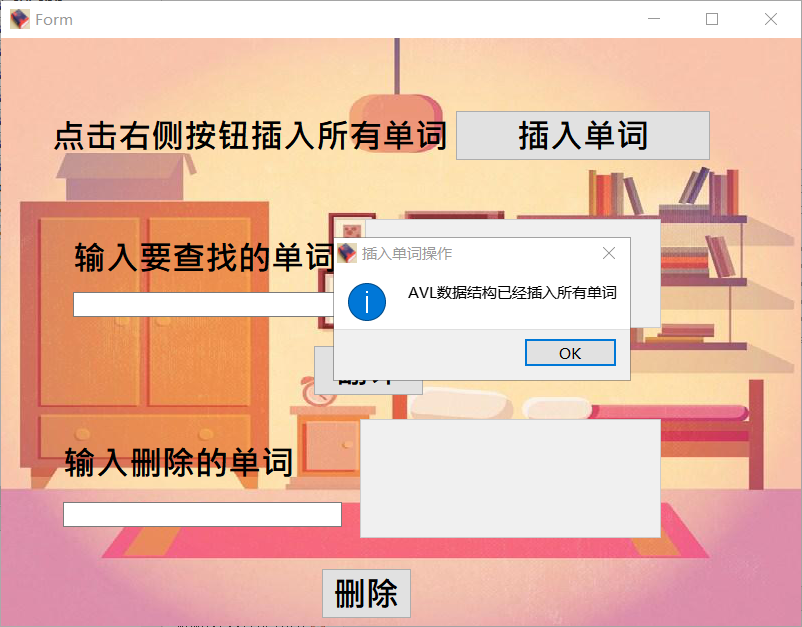
插入所有单词的界面
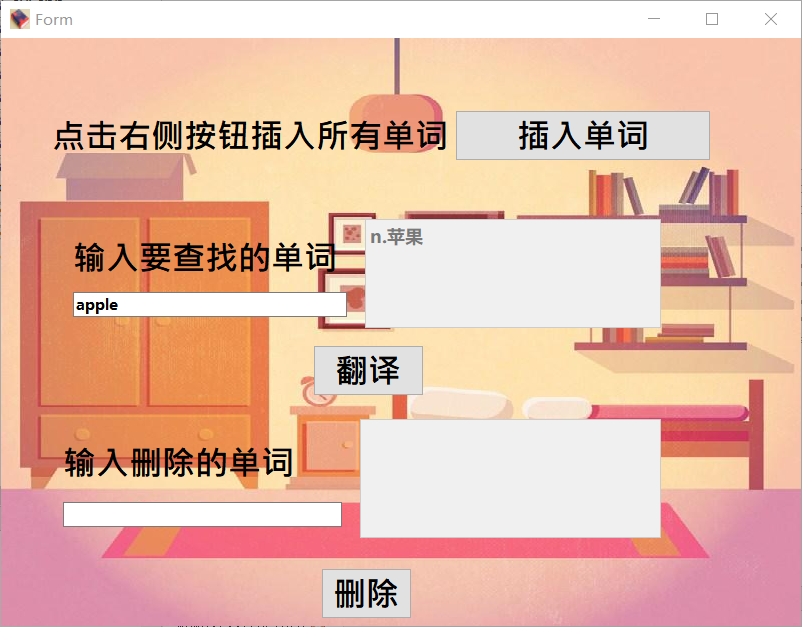
查找单词的界面
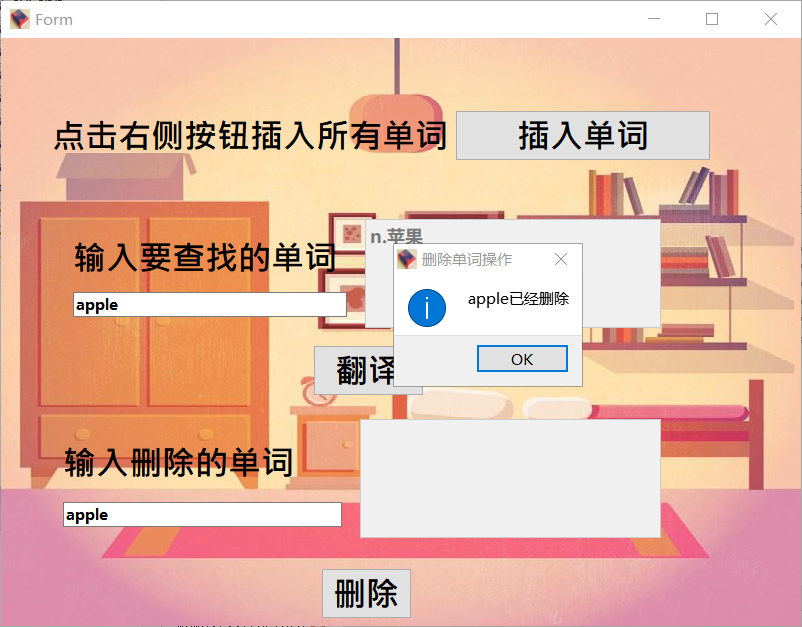
删除单词界面
完整代码下载地下:C++使用字典树,平衡树,散列表实现英汉字典源代码


















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











