








在数字多媒体的浩瀚宇宙中,我们已经学会使用 FFmpeg 和 C++ 将视频文件解封装为 H.264 视频流和 AAC 音频流,就像把一个精美的礼物盒拆开,取出里面的珍贵物品。而今天,我们将继续深入探索,开启一场更加精彩的冒险 —— 使用 FFmpeg 实现 H.264 和 AAC 文件的软件解码。这就好比要将这些珍贵物品进一步加工,还原它们最原始、最纯粹的模样,让我们一起揭开音视频解码的神秘面纱!
一、解码的意义与 FFmpeg 的角色
(一)解码:从压缩数据到视听盛宴的关键一步
我们日常接触到的音视频文件压缩编码处理的。这是因为原始的音视频数据量极其庞大,如果不进行压缩,存储和传输都会面临巨大的挑战。想象一下,一部未经压缩的电影,可能需要几百 GB 甚至更多的存储空间,传输起来也需要耗费大量的时间和带宽。
而解码,就是将这些经过压缩编码的数据,还原成计算机能够直接处理和播放的原始音视频数据的过程。它就像是一个神奇的 “解压器”,把压缩的音视频数据展开,让我们能够欣赏到流畅的画面和动听的声音。没有解码,我们看到的可能只是一串毫无意义的二进制数据,听到的也只是嘈杂的噪音。
想了解H.264和AAC编码原理可以参考我的文章:
(二)FFmpeg:解码领域的 “超级工匠”
FFmpeg 在解码过程中扮演着至关重要的角色,堪称解码领域的 “超级工匠”。它拥有一套完整且强大的编解码工具集,支持几乎所有常见的音视频编码格式,包括我们今天要重点关注的 H.264 视频编码和 AAC 音频编码。
FFmpeg 就像一位经验丰富的工匠大师,手中掌握着各种精巧的工具(编解码器)。对于 H.264 视频文件,它能使用对应的 H.264 解码器,将压缩的视频数据逐帧还原;对于 AAC 音频文件,它又能切换到 AAC 解码器,把音频数据解码成原始的音频样本。凭借其高效的算法和优化的代码实现,FFmpeg 能够快速、准确地完成解码任务,为我们带来流畅的音视频播放体验。
二、H.264 视频解码:从压缩帧到动态画面
(一)H.264 编码的特点与挑战
H.264 是目前应用最为广泛的视频编码标准之一(现在H.265甚至H.266都已经开始普及,但H.264仍是最主流的视频编码标准),它采用了一系列复杂的压缩技术,如帧内预测、帧间预测、变换编码等,能够在保证较高视频质量的前提下,实现非常高的压缩比。这就好比把一幅精美的画作,通过巧妙的折叠和压缩,变成一个小巧的包裹,方便存储和传输。
然而,正是这些复杂的压缩技术,使得 H.264 视频的解码过程充满挑战。解码时,需要按照编码的逆过程,逐步还原每一帧画面的细节。例如,对于采用帧间预测编码的帧,需要参考之前的帧来计算当前帧的像素值;对于经过变换编码的数据,需要进行反变换、反量化等操作,才能恢复原始的像素数据。这就像是一个拼图游戏,需要把一块块零散的拼图(压缩数据),按照正确的顺序和方法拼接起来,才能还原出完整的画面。
(二)FFmpeg 解码 H.264 的基本流程
使用 FFmpeg 解码 H.264 视频,主要包含以下几个关键步骤:
- 初始化 FFmpeg 与解码器:首先,我们需要像准备工匠的工具箱一样,初始化 FFmpeg 库,并找到合适的 H.264 解码器。FFmpeg 提供了丰富的函数来完成这些操作,我们要确保解码器能够正确识别和处理 H.264 编码的数据。
- 打开 H.264 文件:接下来,就像打开一个装满拼图碎片的盒子,使用 FFmpeg 的函数打开 H.264 视频文件,获取文件的相关信息,如视频的分辨率、帧率等。这些信息对于后续的解码过程至关重要,它们就像是拼图的图纸,告诉我们如何拼接这些碎片。
- 读取和解码视频帧:从文件中逐帧读取压缩的视频数据,然后将这些数据送入 H.264 解码器进行解码。解码器会根据编码的规则,将压缩数据还原成原始的视频帧。这个过程就像是工匠按照图纸,小心翼翼地将拼图碎片拼接起来,每拼接好一块,就得到了一帧完整的画面。
- 处理解码后的视频帧:解码后的视频帧是原始的图像数据,我们可以对其进行各种处理,比如显示在屏幕上、保存为图片、进行图像滤镜处理等。这一步就像是对完成的拼图进行欣赏、装裱或者进一步加工,让它变得更加美观和实用。
在计算机内存中,数据存储以字节为基本单位,但为了提高数据访问效率,处理器对数据读取有着特定的要求。就像图书馆管理员整理书籍时,会按照一定的规则将书籍整齐摆放,方便读者快速找到和取用,计算机也希望数据在内存中以 “整齐” 的方式存放,这就是数据对齐的概念。
对于 H.264 视频数据,在解码前通常需要保证数据在内存中的地址满足特定的对齐要求。以常见的 32 位或 64 位处理器为例,它们在读取数据时,更倾向于从对齐的内存地址开始读取。如果数据没有正确对齐,处理器可能需要执行额外的指令来完成数据读取,这会降低解码效率,甚至可能导致解码错误。
在 FFmpeg 的 H.264 解码实现中,会通过多种方式处理数据对齐问题。一方面,在内存分配阶段,会使用特定的内存分配函数(如
av_mallocz等)来确保分配的内存空间满足对齐要求。这些函数就像专业的 “空间规划师”,能够根据处理器的需求,规划出整齐且高效的内存布局。例如,av_mallocz函数在分配内存时,会自动将内存地址对齐到合适的边界(如 16 字节、32 字节等),确保后续的数据访问能够高效进行。另一方面,在数据传输和解码过程中,FFmpeg 会对数据进行必要的调整和填充。当从文件中读取 H.264 视频数据后,可能存在数据地址未对齐的情况,此时 FFmpeg 会通过填充字节(通常是添加一些无意义的空数据)的方式,将数据调整到正确的对齐位置。这就好比在拼图时,发现某些拼图块边缘不整齐,通过添加一些辅助的小块,让整个拼图能够完美契合。这种数据填充和调整操作,虽然会增加一定的内存开销,但能够显著提升解码的效率和稳定性。
在看代码实现之前介绍一个前置知识,YUV格式:
在视频处理领域,YUV 是一种广泛使用的色彩编码系统,特别适用于电视系统和视频通信领域。与我们常见的 RGB 格式不同,YUV 将色彩信息分为三个分量:
- Y(Luminance):表示亮度信息,也就是图像的黑白部分。它包含了图像的主要结构和细节,是人类视觉系统最敏感的部分。
- U(Chrominance):表示蓝色色度,即图像中的蓝色成分与亮度的差异。
- V(Chrominance):表示红色色度,即图像中的红色成分与亮度的差异。
这种分离亮度和色度的设计有两个主要优点:一是可以利用人眼对亮度敏感而对色度相对不敏感的特性,对色度信息进行降采样,从而减少数据量;二是可以在不影响亮度信息的前提下,单独处理色度信息,这在视频传输和存储中非常有用。
YUV 格式有多种采样方式,最常见的有以下几种:
- YUV 4:4:4:这是最完整的采样方式,每个 Y 分量对应一个 U 分量和一个 V 分量,没有任何色度信息的丢失。这种格式的数据量最大,但能提供最高的色彩精度。
- YUV 4:2:2:在水平方向上,每两个 Y 分量共享一组 U 和 V 分量,垂直方向上则保持完整的采样。这种格式在保持较好色彩质量的同时,将数据量减少了约三分之一。
- YUV 4:2:0:在水平和垂直方向上都进行了 2:1 的降采样,即每四个 Y 分量共享一组 U 和 V 分量。这是最常见的 YUV 采样格式,广泛应用于视频编码标准如 H.264、H.265 等,它能在保证视觉质量的前提下,大幅减少数据量。
在我们的代码中,处理的就是 YUV 4:2:0 格式的数据,这也是 H.264 解码后最常见的输出格式。
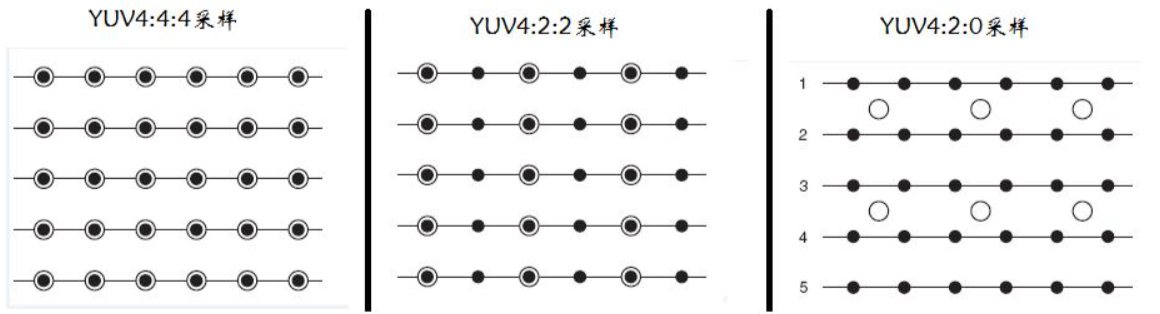
YUV 数据在内存中的存储方式主要有两种:平面存储和打包存储(也叫交错存储)。
- 平面存储(Planar):将 Y、U、V 三个分量分别存储在不同的内存区域中,形成三个独立的 “平面”。这种存储方式便于对每个分量进行单独处理,也是 FFmpeg 中最常用的存储方式。
- 打包存储(Packed):将 Y、U、V 三个分量按照一定的顺序交错存储在同一个内存区域中。例如,可能按照 YUVYUV... 的顺序依次存储每个像素的 Y、U、V 值。这种存储方式更适合直接显示或传输,但不利于单独处理各个分量。
在我们下面的代码中,处理的是平面存储的 YUV 4:2:0 数据,也就是通常所说的 I420或yuv420p 格式。在这种格式中:
- Y 分量存储在第一个平面(data [0]),其大小为 width × height。
- U 分量存储在第二个平面(data [1]),其大小为 (width/2) × (height/2)。
- V 分量存储在第三个平面(data [2]),其大小也为 (width/2) × (height/2)。
(三)代码实现H.264文件解码
我们在上一节解封装后得到了名字叫”baseball.h264“的裸流文件,下面我们通过代码对这个文件进行解码:
1.代码整体架构与核心组件
#include <iostream>
#include <stdio.h>
#include <string.h>
extern "C"
{
#include <libavcodec/avcodec.h>
#include <libavutil/frame.h>
#include <libavutil/mem.h>
}
#pragma comment(lib,"avcodec.lib")
#pragma comment(lib,"avutil.lib") 代码首先引入了必要的头文件,包括标准输入输出库和 FFmpeg 的核心编解码库。avcodec.h提供了编解码器的核心 API,frame.h用于处理视频帧数据,mem.h则提供了内存管理功能。通过#pragma comment指令链接相应的库文件,确保代码能够正确调用 FFmpeg 的功能。
2.错误处理与解码核心函数
static char err_buf[128] = { 0 };
static char* av_get_err(int errnum)
{
av_strerror(errnum, err_buf, 128);
return err_buf;
}这段代码定义了一个错误处理函数,用于将 FFmpeg 返回的错误码转换为可读的错误信息。在复杂的多媒体处理过程中,错误处理至关重要,它能帮助我们快速定位和解决问题。
解码核心函数:avcodec_send_packet 与 avcodec_receive_frame
static void decode(AVCodecContext* dec_ctx, AVPacket* pkt, AVFrame* frame,
FILE* outfile)
{
int ret;
//向解码器发送avpacket
ret = avcodec_send_packet(dec_ctx, pkt);
if (ret == AVERROR(EAGAIN))
{
fprintf(stderr, "Receive_frame and send_packet both returned EAGAIN, which is an API violation.\n");
}
else if (ret < 0)
{
fprintf(stderr, "Error submitting the packet to the decoder, err:%s, pkt_size:%d\n",
av_get_err(ret), pkt->size);
return;
}
/*每次发送一个avpacket,可能会收到多个avframe(解码内部存在缓冲区,所以当发送完全部avpacket后需要冲洗缓冲区把所有帧都取出来,有时候看
到有的解码程序视频莫名其妙最后少几帧就是没有冲洗缓冲区导致的)*/
while (ret >= 0)
{
//接收avframe
ret = avcodec_receive_frame(dec_ctx, frame);
if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF)
return;
else if (ret < 0)
{
fprintf(stderr, "Error during decoding\n");
exit(1);
}
// 一般H264默认为 AV_PIX_FMT_YUV420P
// 对齐的问题:我们在对指针累加一行数据个数时要用linesize[]而不是frame->width,原因就是其内部可能存在额外数据用于对齐,用frame->width会乱码!!!
// 正确写法 linesize[]代表每行的字节数量,所以每行的偏移是linesize[]
for (int j = 0; j < frame->height; j++)//Y
fwrite(frame->data[0] + j * frame->linesize[0], 1, frame->width, outfile);
for (int j = 0; j < frame->height / 2; j++)//U
fwrite(frame->data[1] + j * frame->linesize[1], 1, frame->width / 2, outfile);
for (int j = 0; j < frame->height / 2; j++)//V
fwrite(frame->data[2] + j * frame->linesize[2], 1, frame->width / 2, outfile);
}
} 这个decode函数是整个视频解码的核心,它实现了从数据包到视频帧的转换过程:
- 发送数据包:通过
avcodec_send_packet将压缩的 H.264 数据(AVPacket)发送给解码器。这个函数会将数据包放入解码器的输入队列中。 - 循环接收解码帧:使用
avcodec_receive_frame从解码器的输出队列中获取解码后的视频帧(AVFrame)。这里需要注意的是,由于解码器内部可能存在缓存,一个数据包可能对应多个输出帧,或者需要多个数据包才能产生一个输出帧。 - 处理解码后的 YUV 数据:解码后的视频帧通常采用 YUV 格式存储。代码中通过三层循环分别处理 Y(亮度)、U(色度)、V(色度)三个分量。这里特别使用了
frame->linesize[]而非直接使用frame->width来计算每行的字节数,这是处理内存对齐的关键!
在视频处理中,内存对齐是一个容易被忽视但却至关重要的问题。现代 CPU 为了提高数据访问效率,要求数据在内存中的起始地址满足特定的对齐条件。如果数据没有正确对齐,CPU 可能需要多次访问内存才能获取完整数据,从而降低性能。
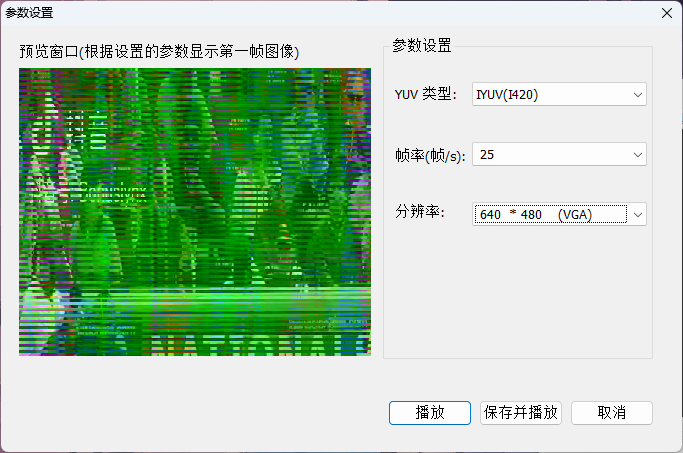
在这段代码中,linesize[]数组记录了每一行数据的实际字节数,它可能大于或等于图像的宽度(以像素为单位)。这是因为 FFmpeg 为了优化内存访问,通常会对每行数据进行对齐(如按 16 字节、32 字节对齐),在每行的末尾添加一些填充字节。如果直接使用frame->width来计算偏移量,会导致数据读取错位,最终输出的视频会出现乱码或花屏现象。

3.主函数:解码流程的完整实现
int main(int argc, char** argv)
{
const char* outfilename;
const char* filename;
const AVCodec* codec;
AVCodecContext* codec_ctx = NULL;
AVCodecParserContext* parser = NULL;
// ... 其他变量定义 ...
filename = "baseball.h264";
outfilename = "baseball.yuv";
// 分配AVPacket和查找H.264解码器
pkt = av_packet_alloc();
AVCodecID video_codec_id = AV_CODEC_ID_H264;
codec = avcodec_find_decoder(video_codec_id);
if (!codec) {
fprintf(stderr, "Codec not found\n");
exit(1);
}
// 初始化解析器和编解码器上下文
parser = av_parser_init(codec->id);
codec_ctx = avcodec_alloc_context3(codec);
if (avcodec_open2(codec_ctx, codec, NULL) < 0) {
fprintf(stderr, "Could not open codec\n");
exit(1);
}
// 打开输入输出文件
ret = fopen_s(&infile, filename, "rb");
ret = fopen_s(&outfile, outfilename, "wb");
// 读取H.264文件并解码
data = inbuf;
data_size = fread(inbuf, 1, VIDEO_INBUF_SIZE, infile);
while (data_size > 0)
{
if (!decoded_frame)
decoded_frame = av_frame_alloc();
// 使用解析器从H.264裸流中提取AVPacket
ret = av_parser_parse2(parser, codec_ctx, &pkt->data, &pkt->size,
data, data_size,
AV_NOPTS_VALUE, AV_NOPTS_VALUE, 0);
data += ret;
data_size -= ret;
if (pkt->size)
decode(codec_ctx, pkt, decoded_frame, outfile);
// 数据不足时从文件中补充
if (data_size < VIDEO_REFILL_THRESH) {
memmove(inbuf, data, data_size);
data = inbuf;
len = fread(data + data_size, 1, VIDEO_INBUF_SIZE - data_size, infile);
if (len > 0)
data_size += len;
}
}
/* 冲刷解码器 */
pkt->data = NULL;
pkt->size = 0;
decode(codec_ctx, pkt, decoded_frame, outfile);
// 释放资源
fclose(outfile);
fclose(infile);
avcodec_free_context(&codec_ctx);
av_parser_close(parser);
av_frame_free(&decoded_frame);
av_packet_free(&pkt);
printf("main finish, please enter Enter and exit\n");
return 0;
}主函数实现了解码流程的完整控制:
- 初始化阶段:查找 H.264 解码器,分配并初始化编解码器上下文和解析器。
- 数据读取与解析:从 H.264 文件中读取数据,使用
av_parser_parse2函数将裸流数据解析成 FFmpeg 的 AVPacket 格式。 - 循环解码:不断从文件读取数据,解析成 AVPacket 后送入解码器,调用前面的
decode函数处理解码输出。 - 缓冲区冲刷:解码完成后,通过发送一个空的 AVPacket 来冲刷解码器的内部缓冲区,确保所有剩余的视频帧都被输出。
- 资源释放:关闭文件,释放所有分配的 FFmpeg 资源,确保没有内存泄漏。
4.结果展示
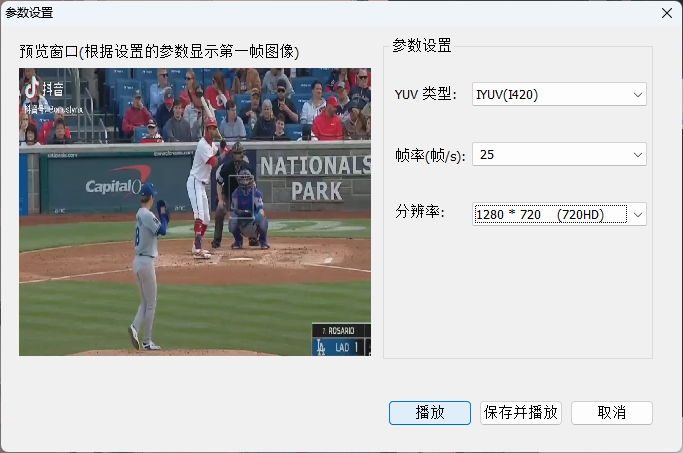
注意我的参数设置,如果yuv格式不对或者分辨率不对都产生问题:

5.视频解码总结
(1) 解析器的作用
对于 H.264 裸流文件,需要使用AVCodecParserContext来解析数据。解析器能够识别 H.264 的 NAL 单元边界,将连续的字节流转换为独立的视频数据包(AVPacket)。这在处理从文件或网络获取的裸流数据时尤为重要。
(2)解码器的工作模式
现代 FFmpeg 解码器采用 "send-receive" 模式:
avcodec_send_packet将压缩数据送入解码器avcodec_receive_frame从解码器获取解码后的帧
这种分离式设计允许解码器内部进行更复杂的优化,如多线程解码、帧重组等。
(3) 内存对齐的处理
在处理解码后的视频帧数据时,必须使用linesize[]而非直接使用图像宽度,这是确保正确处理内存对齐的关键。忽视这一点会导致输出视频出现花屏、错位等问题。
(4)缓冲区冲刷
解码器内部可能会缓存一些帧以进行优化(如 B 帧的处理),因此在解码结束时,需要通过发送空数据包来触发解码器输出所有剩余的帧,这一步骤称为 "缓冲区冲刷",是确保视频完整性的重要环节。
三、AAC 音频解码:从数字信号到美妙声音
(一)AAC 编码的原理与优势
AAC(Advanced Audio Coding)是一种高音质的音频编码标准,它通过对音频信号的频谱分析、量化、编码等一系列操作,将原始的音频数据压缩成较小的文件大小,同时保持较高的音频质量。与传统的 MP3 编码相比,AAC 在相同的码率下能够提供更好的音质,就像是用更精细的工艺,把一段美妙的音乐压缩成一个小巧的数字文件。
AAC 编码利用了人耳的听觉特性,去除了一些人耳难以察觉的音频信息,从而实现高效的压缩。例如,它会根据音频信号的频率、强度等特征,对不同部分的音频数据采用不同的量化精度,保留重要的音频信息,舍弃次要的信息。这就像是画家在作画时,重点描绘关键的细节,而对一些不太重要的部分进行简化处理。
(二)FFmpeg 解码 AAC 的核心步骤
使用 FFmpeg 解码 AAC 音频,主要包括以下几个步骤:
- 初始化音频解码器:和视频解码一样,首先要初始化 FFmpeg 库,并找到合适的 AAC 解码器。这个解码器就像是一把神奇的钥匙,能够打开被压缩的音频数据的 “锁”。
- 打开 AAC 文件:打开 AAC 音频文件,获取音频的相关参数,如采样率、声道数、编码格式等。这些参数是解码过程的重要依据,就像是音乐的乐谱,指导着解码器如何还原出正确的声音。
- 读取和解码音频数据:从文件中读取压缩的 AAC 音频数据,将其送入 AAC 解码器进行解码。解码器会将这些数字信号还原成原始的音频样本,这些样本就像是构成音乐的一个个音符。
- 处理解码后的音频样本:解码后的音频样本可以进一步处理,比如播放出来让我们聆听美妙的音乐、进行音频剪辑、调整音量等。这一步就像是将音符组合成动听的旋律,让我们能够欣赏到完整的音乐作品。
(三)代码实现AAC文件解码
我们在上一节解封装后得到了名字叫”baseball.aac“的裸流文件,下面我们通过代码对这个文件进行解码,由于大部分解码逻辑和视频解码类似,这里只讲解部分代码:
1.核心函数:从 AAC 到 PCM 的转换
static void decode(AVCodecContext* dec_ctx, AVPacket* pkt, AVFrame* frame,
FILE* outfile)
{
int i, ch;
int ret, data_size;
// 发送压缩数据到解码器
ret = avcodec_send_packet(dec_ctx, pkt);
if (ret == AVERROR(EAGAIN))
{
fprintf(stderr, "Receive_frame and send_packet both returned EAGAIN, which is an API violation.\n");
}
else if (ret < 0)
{
fprintf(stderr, "Error submitting the packet to the decoder, err:%s, pkt_size:%d\n",
av_get_err(ret), pkt->size);
return;
}
// 循环接收解码后的音频帧
while (ret >= 0)
{
ret = avcodec_receive_frame(dec_ctx, frame);
if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF)
return;
else if (ret < 0)
{
fprintf(stderr, "Error during decoding\n");
exit(1);
}
// 计算每个样本的字节数
data_size = av_get_bytes_per_sample(dec_ctx->sample_fmt);
if (data_size < 0)
{
fprintf(stderr, "Failed to calculate data size\n");
exit(1);
}
// 首次打印音频格式信息
static int s_print_format = 0;
if (s_print_format == 0)
{
s_print_format = 1;
print_sample_format(frame);
}
// 将平面存储的音频数据转换为交错存储
for (i = 0; i < frame->nb_samples; i++)
{
for (ch = 0; ch < dec_ctx->channels; ch++)
fwrite(frame->data[ch] + data_size * i, 1, data_size, outfile);
}
}
}这个decode函数是整个音频解码的核心,它实现了从 AAC 压缩数据到 PCM 原始音频数据的转换过程:
- 发送数据包:通过
avcodec_send_packet将压缩的 AAC 数据(AVPacket)发送给解码器。 - 循环接收解码帧:使用
avcodec_receive_frame从解码器的输出队列中获取解码后的音频帧(AVFrame)。与视频解码类似,由于解码器内部可能存在缓存,需要循环接收直到返回错误码。 - 计算样本大小:使用
av_get_bytes_per_sample计算每个音频样本占用的字节数,这取决于样本格式(如 float、int16 等)。 - 平面存储到交错存储的转换:这是音频解码中的一个关键步骤,我们将在下一部分详细讨论。
2.音频数据存储格式:平面存储与交错存储
在音频处理中,数据的存储方式有两种主要形式:平面存储(Planar)和交错存储(Interleaved)。
(1)平面存储(Planar)
平面存储是指每个声道的数据单独存储在一个连续的内存区域中。例如,对于双声道音频,会有两个独立的内存平面:一个存储左声道数据,另一个存储右声道数据。每个平面的结构如下:
平面0(左声道):L1, L2, L3, L4, ..., Ln
平面1(右声道):R1, R2, R3, R4, ..., Rn这种存储方式便于对每个声道进行独立处理,例如单独调整某个声道的音量或应用特效。
(2)交错存储(Interleaved)
交错存储是指所有声道的数据按照一定顺序交替存储在同一个内存区域中。对于双声道音频,数据排列方式为:
L1, R1, L2, R2, L3, R3, ..., Ln, Rn这种存储方式更适合直接播放,因为音频设备通常需要这种格式的数据。
(3)在代码中的实现
FFmpeg 默认以平面存储方式输出多声道音频数据,但大多数音频播放器需要交错存储格式。因此,我们需要在代码中进行转换,nb_samples是样本个数,左右声道一起算一个样本。channels是通道数,对于双声道音频有2个通道(左声道、右声道)。
// 将平面存储的音频数据转换为交错存储
for (i = 0; i < frame->nb_samples; i++)
{
for (ch = 0; ch < dec_ctx->channels; ch++)
fwrite(frame->data[ch] + data_size * i, 1, data_size, outfile);
}这段代码通过嵌套循环实现了从平面存储到交错存储的转换:
- 外层循环遍历每个样本位置(从 0 到 nb_samples-1)
- 内层循环遍历每个声道,依次将各声道在当前样本位置的数据写入输出文件
- 通过
frame->data[ch] + data_size * i定位到每个声道的特定样本位置
4.音频解码总结
1. 音频解码器的选择
代码支持根据文件扩展名自动选择解码器(AAC 或 MP3),这种设计使代码具有更强的通用性,可以处理多种音频格式。
2. 平面存储与交错存储的转换
理解并正确处理音频数据的存储格式是音频解码的关键。FFmpeg 默认输出平面存储格式,而大多数播放器需要交错存储格式,因此需要进行适当的转换。我们的代码通过嵌套循环实现了这种转换,确保输出的 PCM 文件可以被正确播放。
3. 音频样本格式与大小计算
使用av_get_bytes_per_sample函数计算每个样本的字节数,这取决于样本格式(如 float、int16 等)。正确计算样本大小是确保数据正确写入文件的关键。
4. 解码器缓冲区管理
与视频解码一样,音频解码器也可能缓存数据。通过发送空的 AVPacket 进行缓冲区冲刷,确保所有音频数据都被解码输出,避免数据丢失。
四、总结
通过本文,我们深入了解了 FFmpeg 在音视频解码领域的重要作用,以及 H.264 视频和 AAC 音频的解码原理与基本流程。解码就像是一场神奇的魔法,将压缩的音视频数据还原成我们能够欣赏的视听盛宴,而 FFmpeg 就是掌握这门魔法的 “魔法师”。
我们通过具体的代码实现,将这些理论知识转化为实际的操作,亲自体验 FFmpeg 解码的魅力。相信在完成代码实践后,你会对音视频解码有更深刻的理解,也会更加熟练地运用 FFmpeg 这个强大的工具。
附录
视频解码完整代码:
#include <iostream>
#include <stdio.h>
#include <string.h>
extern "C"
{
#include <libavcodec/avcodec.h>
#include <libavutil/frame.h>
#include <libavutil/mem.h>
}
#pragma comment(lib,"avcodec.lib")
#pragma comment(lib,"avutil.lib")
#define VIDEO_INBUF_SIZE 20480
#define VIDEO_REFILL_THRESH 4096
static char err_buf[128] = { 0 };
static char* av_get_err(int errnum)
{
av_strerror(errnum, err_buf, 128);
return err_buf;
}
static void decode(AVCodecContext* dec_ctx, AVPacket* pkt, AVFrame* frame,
FILE* outfile)
{
int ret;
//向解码器发送avpacket
ret = avcodec_send_packet(dec_ctx, pkt);
if (ret == AVERROR(EAGAIN))
{
fprintf(stderr, "Receive_frame and send_packet both returned EAGAIN, which is an API violation.\n");
}
else if (ret < 0)
{
fprintf(stderr, "Error submitting the packet to the decoder, err:%s, pkt_size:%d\n",
av_get_err(ret), pkt->size);
return;
}
/*每次发送一个avpacket,可能会收到多个avframe(发送第一个avpacket后可能还会收不到avframe,
因为其内部存在缓冲区,所以当发送完全部avpacket后需要冲洗缓冲区把所有帧都取出来,有时候看
到有的解码程序视频莫名其妙最后少几帧就是没有冲洗缓冲区导致的)*/
while (ret >= 0)
{
//接收avframe
ret = avcodec_receive_frame(dec_ctx, frame);
if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF)
return;
else if (ret < 0)
{
fprintf(stderr, "Error during decoding\n");
exit(1);
}
// 一般H264默认为 AV_PIX_FMT_YUV420P
// 对齐的问题:我们在对指针累加一行数据个数时要用linesize[]而不是frame->width,原因就是其内部可能存在额外数据用于对齐,用frame->width会乱码!!!
// 正确写法 linesize[]代表每行的字节数量,所以每行的偏移是linesize[]
for (int j = 0; j < frame->height; j++)//Y
fwrite(frame->data[0] + j * frame->linesize[0], 1, frame->width, outfile);
for (int j = 0; j < frame->height / 2; j++)//U
fwrite(frame->data[1] + j * frame->linesize[1], 1, frame->width / 2, outfile);
for (int j = 0; j < frame->height / 2; j++)//V
fwrite(frame->data[2] + j * frame->linesize[2], 1, frame->width / 2, outfile);
}
}
int main(int argc, char** argv)
{
const char* outfilename;
const char* filename;
const AVCodec* codec;
AVCodecContext* codec_ctx = NULL;
AVCodecParserContext* parser = NULL;
int len = 0;
int ret = 0;
FILE* infile = NULL;
FILE* outfile = NULL;
// AV_INPUT_BUFFER_PADDING_SIZE 在输入比特流结尾的要求附加分配字节的数量上进行解码
uint8_t inbuf[VIDEO_INBUF_SIZE + AV_INPUT_BUFFER_PADDING_SIZE];
uint8_t* data = NULL;
size_t data_size = 0;
AVPacket* pkt = NULL;
AVFrame* decoded_frame = NULL;
filename = "baseball.h264";
outfilename = "baseball.yuv";
pkt = av_packet_alloc();
AVCodecID video_codec_id = AV_CODEC_ID_H264;
// 查找解码器
codec = avcodec_find_decoder(video_codec_id); // AV_CODEC_ID_H264
if (!codec) {
fprintf(stderr, "Codec not found\n");
exit(1);
}
// 获取裸流的解析器 正常从mp4文件中读流可以直接读到avpacket中,但本次是从本地文件中读取裸流,需要用AVCodecParser将二进制数据写入avpacket
parser = av_parser_init(codec->id);
if (!parser) {
fprintf(stderr, "Parser not found\n");
exit(1);
}
// 分配codec上下文
codec_ctx = avcodec_alloc_context3(codec);
if (!codec_ctx) {
fprintf(stderr, "Could not allocate audio codec context\n");
exit(1);
}
// 将解码器和解码器上下文进行关联
if (avcodec_open2(codec_ctx, codec, NULL) < 0) {
fprintf(stderr, "Could not open codec\n");
exit(1);
}
// 打开本地H.264文件
ret = fopen_s(&infile, filename, "rb");
if (!infile) {
fprintf(stderr, "Could not open %s\n", filename);
exit(1);
}
// 打开输出文件.yuv
ret = fopen_s(&outfile, outfilename, "wb");
if (!outfile) {
av_free(codec_ctx);
exit(1);
}
// 读取文件进行解码
data = inbuf;
data_size = fread(inbuf, 1, VIDEO_INBUF_SIZE, infile);
while (data_size > 0)
{
if (!decoded_frame)
{
//如果不存在,则申请avframe对象并分配空间
if (!(decoded_frame = av_frame_alloc()))
{
fprintf(stderr, "Could not allocate audio frame\n");
exit(1);
}
}
//从data中读数据到avpacket,每次读取大小可能小于data_size,ret返回值为实际读取大小
ret = av_parser_parse2(parser, codec_ctx, &pkt->data, &pkt->size,
data, data_size,
AV_NOPTS_VALUE, AV_NOPTS_VALUE, 0);
if (ret < 0)
{
fprintf(stderr, "Error while parsing\n");
exit(1);
}
data += ret; // 跳过已经解析的数据
data_size -= ret; // 对应的缓存大小也做相应减小
if (pkt->size)
decode(codec_ctx, pkt, decoded_frame, outfile);
if (data_size < VIDEO_REFILL_THRESH) // 如果数据少了则再次读取
{
memmove(inbuf, data, data_size); // 把之前剩的数据拷贝到buffer的起始位置
data = inbuf;
// 读取数据 长度: VIDEO_INBUF_SIZE - data_size
len = fread(data + data_size, 1, VIDEO_INBUF_SIZE - data_size, infile);
if (len > 0)
data_size += len;
}
}
/* 冲刷解码器 */
pkt->data = NULL; // 让其进入drain mode
pkt->size = 0;
decode(codec_ctx, pkt, decoded_frame, outfile);
fclose(outfile);
fclose(infile);
avcodec_free_context(&codec_ctx);
av_parser_close(parser);
av_frame_free(&decoded_frame);
av_packet_free(&pkt);
printf("main finish, please enter Enter and exit\n");
return 0;
}音频解码完整代码:
#include <iostream>
#include <stdio.h>
#include <string.h>
extern "C"
{
#include <libavcodec/avcodec.h>
#include <libavutil/frame.h>
#include <libavutil/mem.h>
}
#pragma comment(lib,"avcodec.lib")
#pragma comment(lib,"avutil.lib")
#define AUDIO_INBUF_SIZE 20480
#define AUDIO_REFILL_THRESH 4096
static char err_buf[128] = { 0 };
static char* av_get_err(int errnum)
{
av_strerror(errnum, err_buf, 128);
return err_buf;
}
static void print_sample_format(const AVFrame* frame)
{
printf("ar-samplerate: %uHz\n", frame->sample_rate);
printf("ac-channel: %u\n", frame->channels);
printf("f-format: %u\n", frame->format);// 格式需要注意,实际存储到本地文件时已经改成交错模式
}
static void decode(AVCodecContext* dec_ctx, AVPacket* pkt, AVFrame* frame,
FILE* outfile)
{
int i, ch;
int ret, data_size;
/* send the packet with the compressed data to the decoder */
ret = avcodec_send_packet(dec_ctx, pkt);
if (ret == AVERROR(EAGAIN))
{
fprintf(stderr, "Receive_frame and send_packet both returned EAGAIN, which is an API violation.\n");
}
else if (ret < 0)
{
fprintf(stderr, "Error submitting the packet to the decoder, err:%s, pkt_size:%d\n",
av_get_err(ret), pkt->size);
// exit(1);
return;
}
/* read all the output frames (infile general there may be any number of them */
while (ret >= 0)
{
// 对于frame, avcodec_receive_frame内部每次都先调用
ret = avcodec_receive_frame(dec_ctx, frame);
if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF)
return;
else if (ret < 0)
{
fprintf(stderr, "Error during decoding\n");
exit(1);
}
data_size = av_get_bytes_per_sample(dec_ctx->sample_fmt);
if (data_size < 0)
{
/* This should not occur, checking just for paranoia */
fprintf(stderr, "Failed to calculate data size\n");
exit(1);
}
static int s_print_format = 0;
if (s_print_format == 0)
{
s_print_format = 1;
print_sample_format(frame);
}
/**
P表示Planar(平面),其数据格式排列方式为 :
LLLLLLRRRRRRLLLLLLRRRRRRLLLLLLRRRRRRL...(每个LLLLLLRRRRRR为一个音频帧)
而不带P的数据格式(即交错排列)排列方式为:
LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLRL...(每个LR为一个音频样本)
播放范例: ffplay -ar 48000 -ac 2 -f f32le believe.pcm
*/
for (i = 0; i < frame->nb_samples; i++)
{
for (ch = 0; ch < dec_ctx->channels; ch++) // 交错的方式写入, 大部分float的格式输出
fwrite(frame->data[ch] + data_size * i, 1, data_size, outfile);
}
}
}
// 播放范例: ffplay -ar 48000 -ac 2 -f f32le believe.pcm
int main(int argc, char** argv)
{
const char* outfilename;
const char* filename;
const AVCodec* codec;
AVCodecContext* codec_ctx = NULL;
AVCodecParserContext* parser = NULL;
int len = 0;
int ret = 0;
FILE* infile = NULL;
FILE* outfile = NULL;
uint8_t inbuf[AUDIO_INBUF_SIZE + AV_INPUT_BUFFER_PADDING_SIZE];
uint8_t* data = NULL;
size_t data_size = 0;
AVPacket* pkt = NULL;
AVFrame* decoded_frame = NULL;
filename = "baseball.aac";
outfilename = "baseball.pcm";
pkt = av_packet_alloc();
enum AVCodecID audio_codec_id = AV_CODEC_ID_AAC;
if (strstr(filename, "aac") != NULL)
{
audio_codec_id = AV_CODEC_ID_AAC;
}
else if (strstr(filename, "mp3") != NULL)
{
audio_codec_id = AV_CODEC_ID_MP3;
}
else
{
printf("default codec id:%d\n", audio_codec_id);
}
// 查找解码器
codec = avcodec_find_decoder(audio_codec_id); // AV_CODEC_ID_AAC
if (!codec) {
fprintf(stderr, "Codec not found\n");
exit(1);
}
// 获取裸流的解析器 AVCodecParserContext(数据) + AVCodecParser(方法)
parser = av_parser_init(codec->id);
if (!parser) {
fprintf(stderr, "Parser not found\n");
exit(1);
}
// 分配codec上下文
codec_ctx = avcodec_alloc_context3(codec);
if (!codec_ctx) {
fprintf(stderr, "Could not allocate audio codec context\n");
exit(1);
}
// 将解码器和解码器上下文进行关联
if (avcodec_open2(codec_ctx, codec, NULL) < 0) {
fprintf(stderr, "Could not open codec\n");
exit(1);
}
// 打开输入文件
ret = fopen_s(&infile, filename, "rb");
if (!infile) {
fprintf(stderr, "Could not open %s\n", filename);
exit(1);
}
// 打开输出文件
ret = fopen_s(&outfile, outfilename, "wb");
if (!outfile) {
av_free(codec_ctx);
exit(1);
}
// 读取文件进行解码
data = inbuf;
data_size = fread(inbuf, 1, AUDIO_INBUF_SIZE, infile);
while (data_size > 0)
{
if (!decoded_frame)
{
if (!(decoded_frame = av_frame_alloc()))
{
fprintf(stderr, "Could not allocate audio frame\n");
exit(1);
}
}
ret = av_parser_parse2(parser, codec_ctx, &pkt->data, &pkt->size,
data, data_size,
AV_NOPTS_VALUE, AV_NOPTS_VALUE, 0);
if (ret < 0)
{
fprintf(stderr, "Error while parsing\n");
exit(1);
}
data += ret; // 跳过已经解析的数据
data_size -= ret; // 对应的缓存大小也做相应减小
if (pkt->size)
decode(codec_ctx, pkt, decoded_frame, outfile);
if (data_size < AUDIO_REFILL_THRESH) // 如果数据少了则再次读取
{
memmove(inbuf, data, data_size); // 把之前剩的数据拷贝到buffer的起始位置
data = inbuf;
// 读取数据 长度: AUDIO_INBUF_SIZE - data_size
len = fread(data + data_size, 1, AUDIO_INBUF_SIZE - data_size, infile);
if (len > 0)
data_size += len;
}
}
/* 冲刷解码器 */
pkt->data = NULL; // 让其进入drain mode
pkt->size = 0;
decode(codec_ctx, pkt, decoded_frame, outfile);
fclose(outfile);
fclose(infile);
avcodec_free_context(&codec_ctx);
av_parser_close(parser);
av_frame_free(&decoded_frame);
av_packet_free(&pkt);
printf("main finish, please enter Enter and exit\n");
getchar();
return 0;
}
















 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









