






基本问题
什么是聚类分析?
•
聚类分析将数据划分成有意义或有用的组(簇)。
•
聚类分析仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组。其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的。
什么是一个好的聚类方法?
•
一个好的聚类方法要能产生高质量的聚类结果
——
簇,这些簇要具备以下两个特点:
–
高的簇内相似性
–
低的簇间相似性
•
聚类结果的好坏取决于该聚类方法采用的相似性评估方法以及该方法的具体实现;
•
聚类方法的好坏还取决于该方法是否能发现某些还是所有的隐含模式;
聚类的复杂性
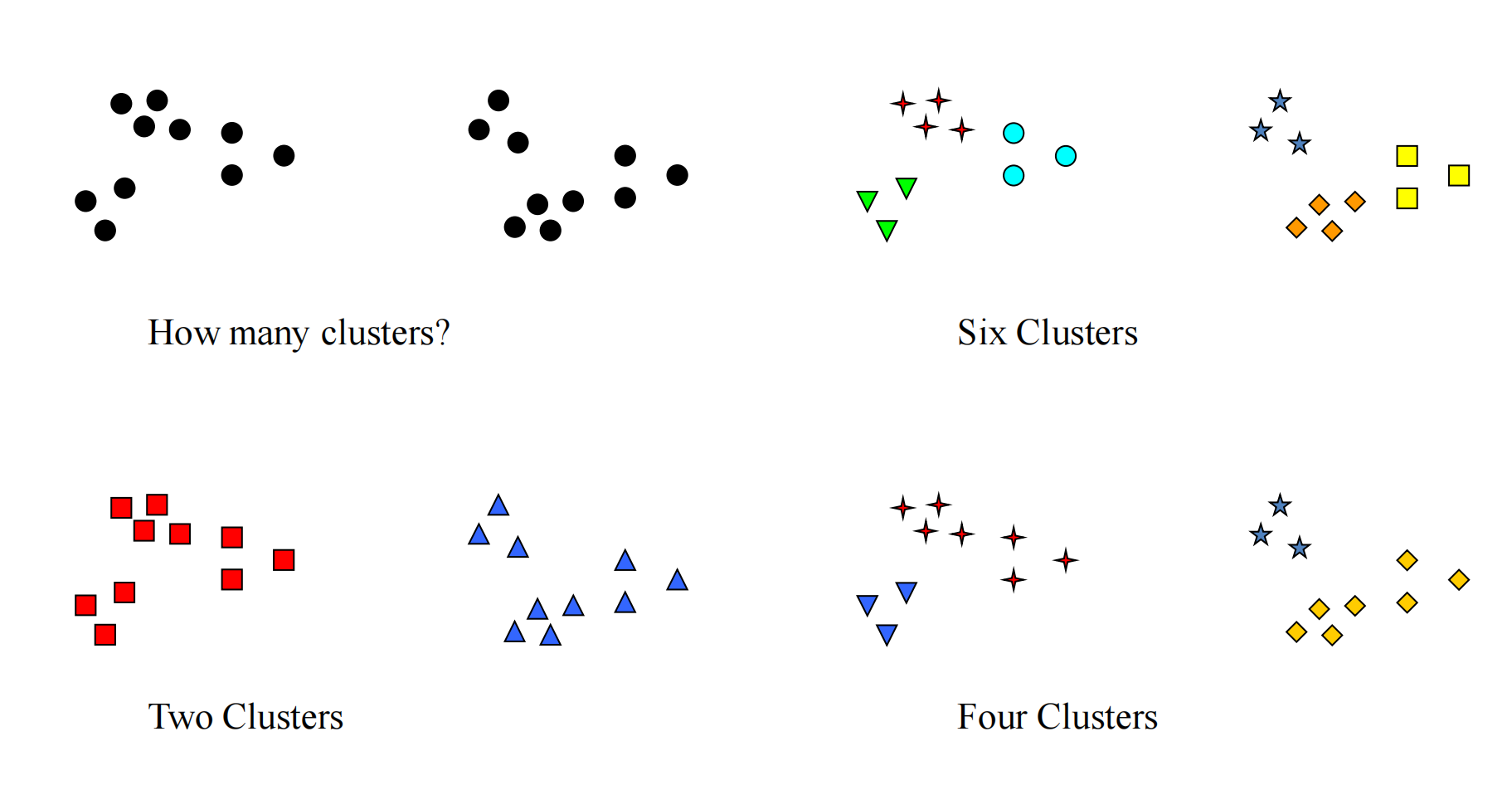
不同的聚类类型
•
划分聚类(
Partitional Clustering
)
•
层次聚类(
Hierarchical Clustering
)
•
互斥(重叠)聚类(
exclusive clustering
)
•
非互斥聚类(
non-exclusive
)
•
模糊聚类(
fuzzy clustering
)
•
完全聚类(
complete clustering
)
•
部分聚类(
partial clustering
)
划分聚类
划分聚类简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集。
划分聚类简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集。
层次聚类
层次聚类是嵌套簇的集族,组织成一棵树。
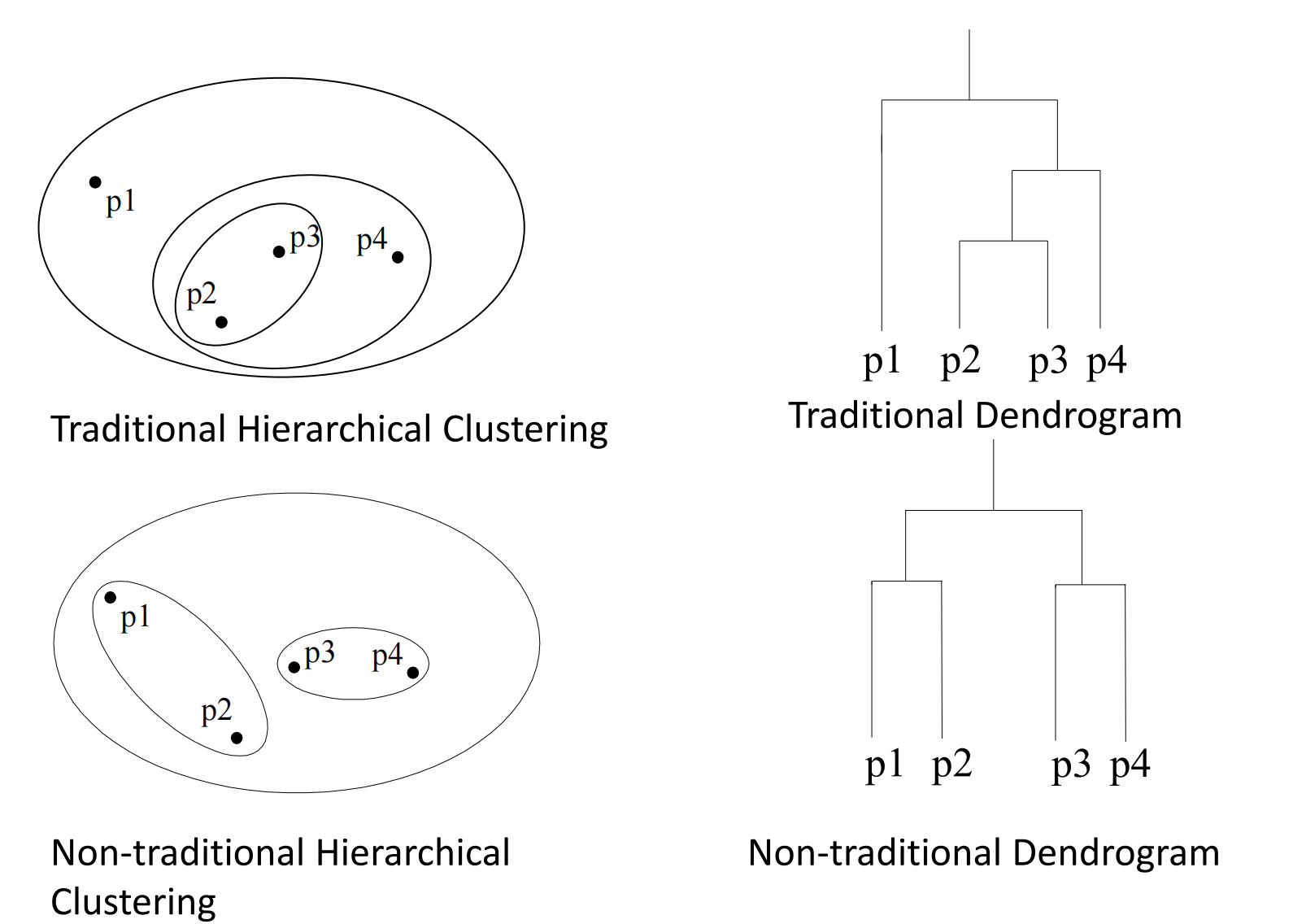
互斥的、重叠的、模糊的

不同的簇类型
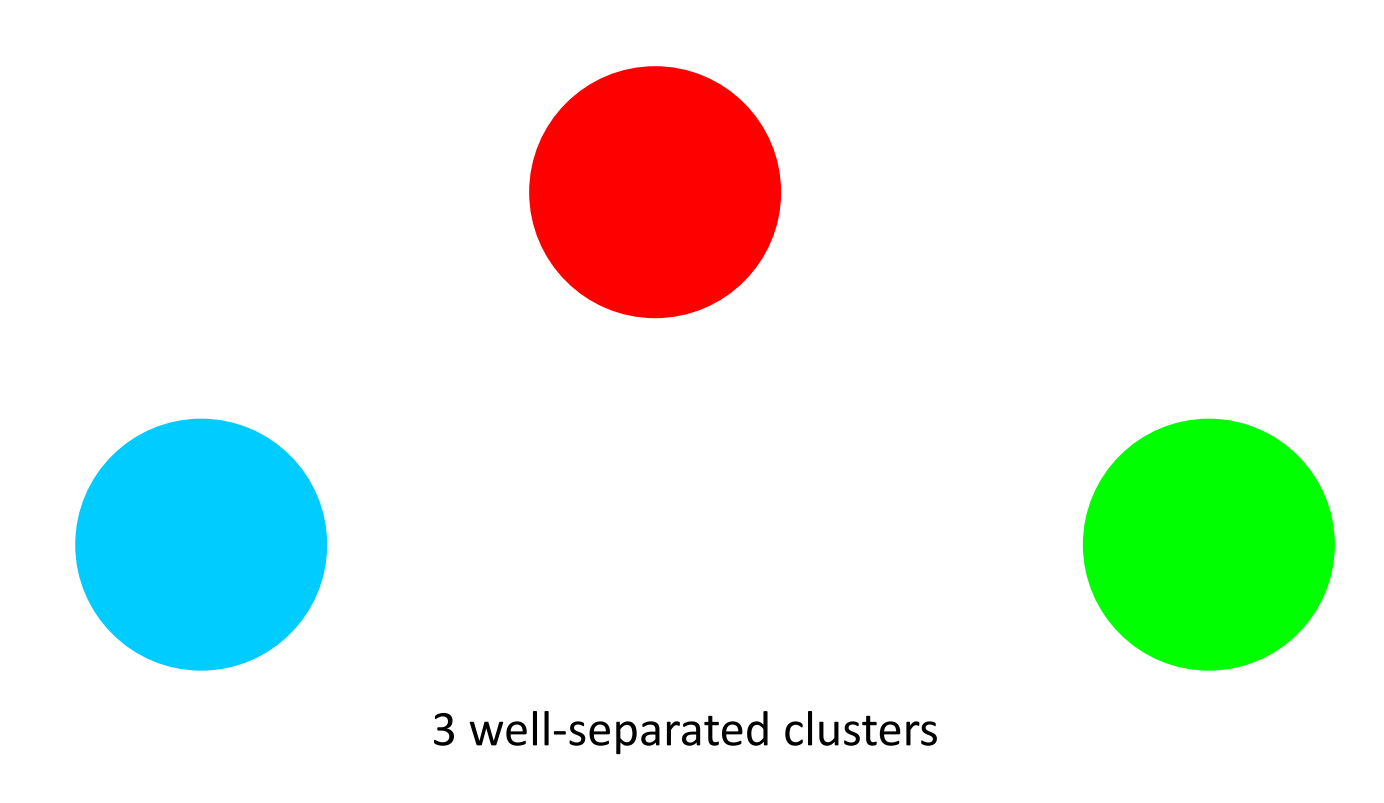
明显分离的
每个点到同簇中任一点的距离比到不同簇中所有点的距离更近。
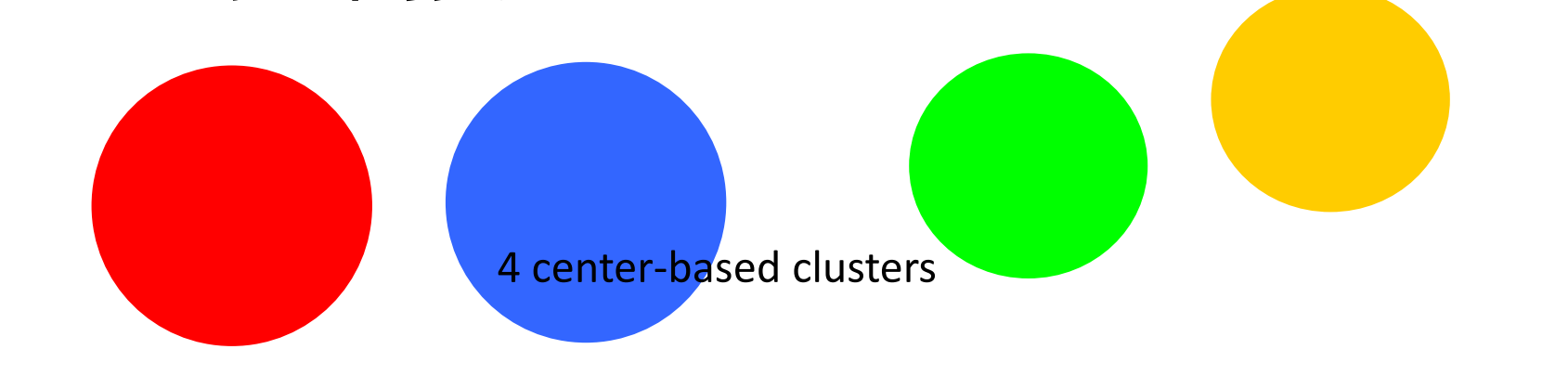
基于原型的
•
每个对象到定义该簇的原型的距离比到其他簇的原型的距离更近。对于具有连续属性的数据,簇的原型通常是质心,即簇中所有点的平均值。当质心没有意义时,原型通常是中心点,即簇中最有代表性的点
•
基于中心的( Center-Based)的簇:每个点到其簇中心的距离比到任何其他簇中心的距离更近。
 基于图的
基于图的
•
如果数据用图表示,其中节点是对象,而边代表对象之间的联系。
•
簇可以定义为连通分支(connected component):互相连通但不与组外对象连通的对象组。
•
基于近邻的( Contiguity-Based):其中两个对象是相连的,仅当它们的距离在指定的范围内。这意味着,每个对象到该簇某个对象的距离比到不同簇中任意点的距离更近。
基于密度的
簇是对象的稠密区域,被低密度的区域环绕。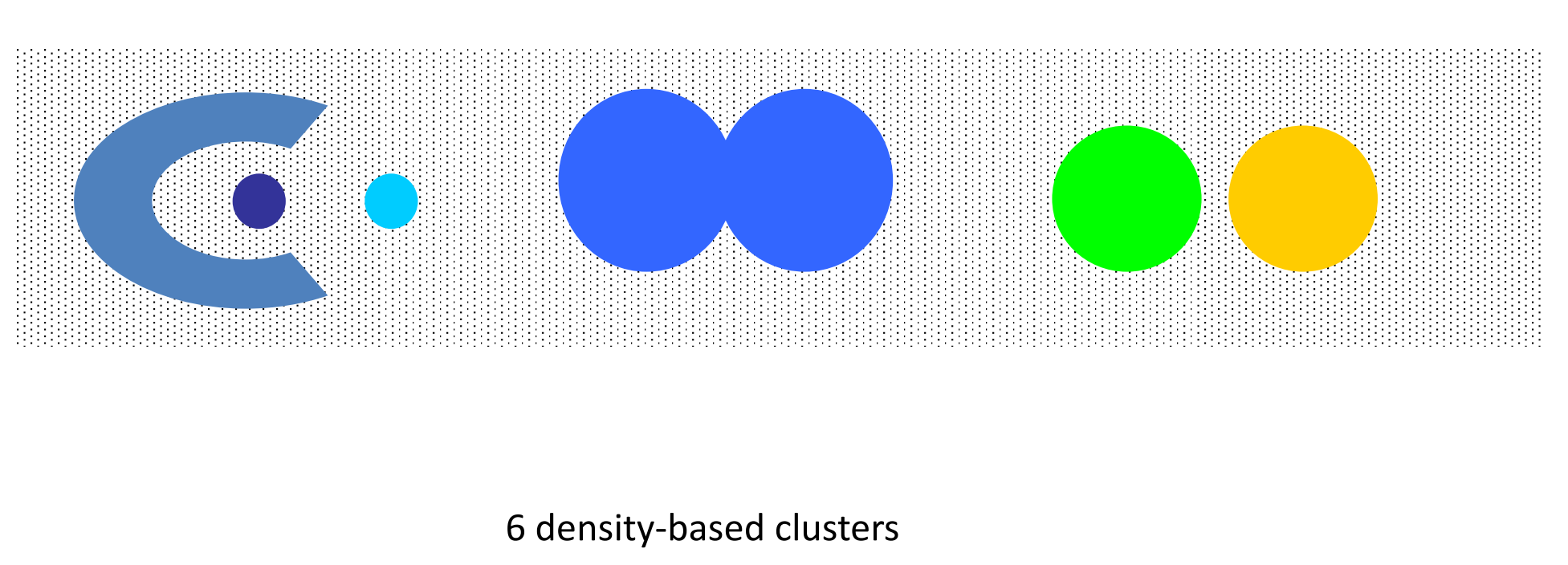
概念簇
可以把簇定义为有某种共同性质的对象的集合。例如:基于中心的聚类。还有一些 簇的共同性质需要更复杂的算法才能识别 出来。
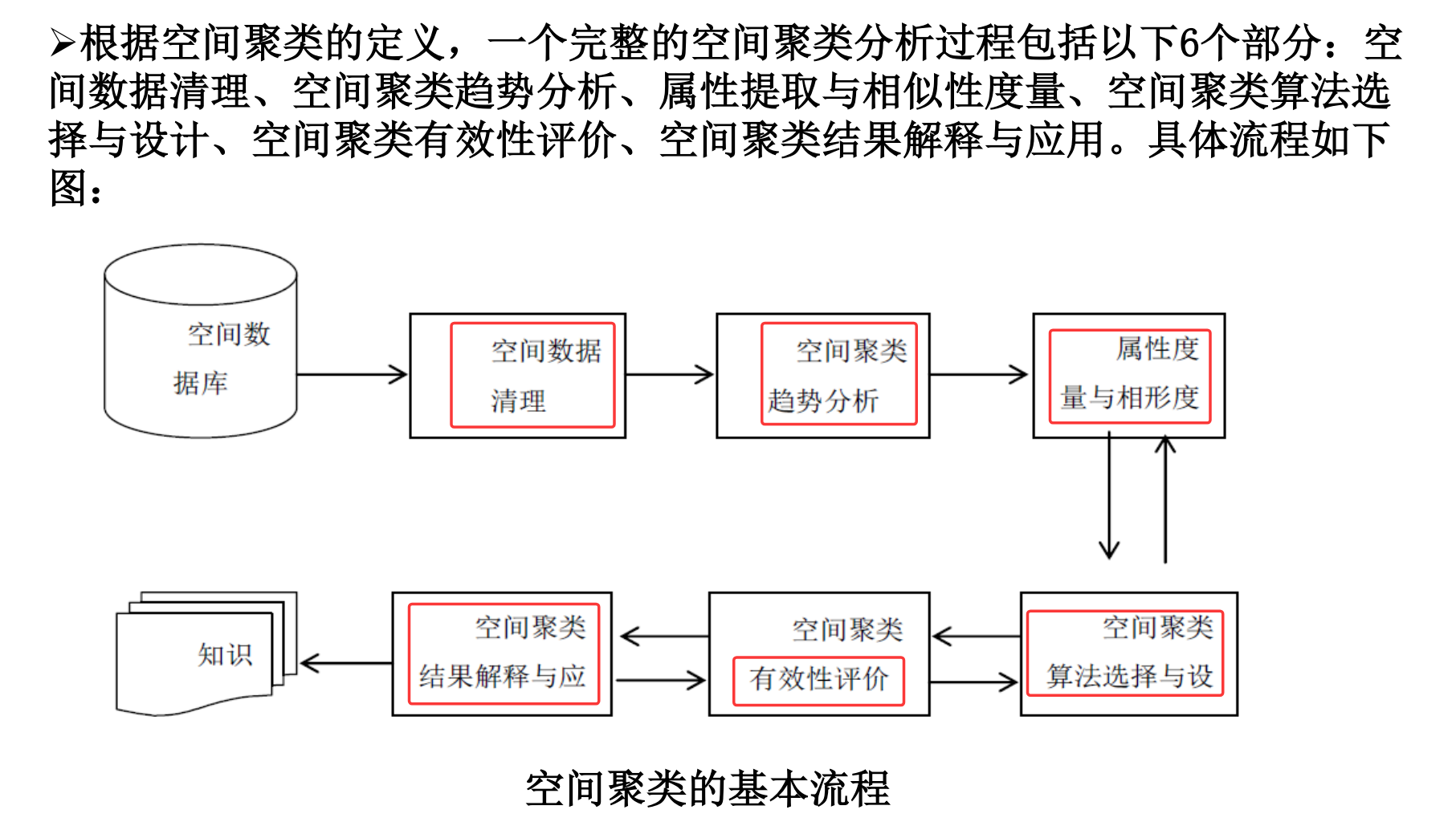
定义
(1)空间聚类作为聚类分析的一个研究方向,是指将空间数据集中的对象分成由相似对象组成的类。同类中的对象间具有较高的相似度,而不同类中的对象间差异较大。
(2)作为一种无监督的学习方法,空间聚类不需要任何先验知识。这是聚类的基本思想,因此空间聚类也是要满足这个基本思想。
(3)在空间聚类中,相似性的定义包含两方面的含义:
一是属性上的相似,这与传统的聚类分析类似;
二是空间关系上的相似,即要求空间实体在位置上接近或相邻,这是传统的聚类分析所不考虑的。
对空间聚类算法的要求


空间聚类的基本流程
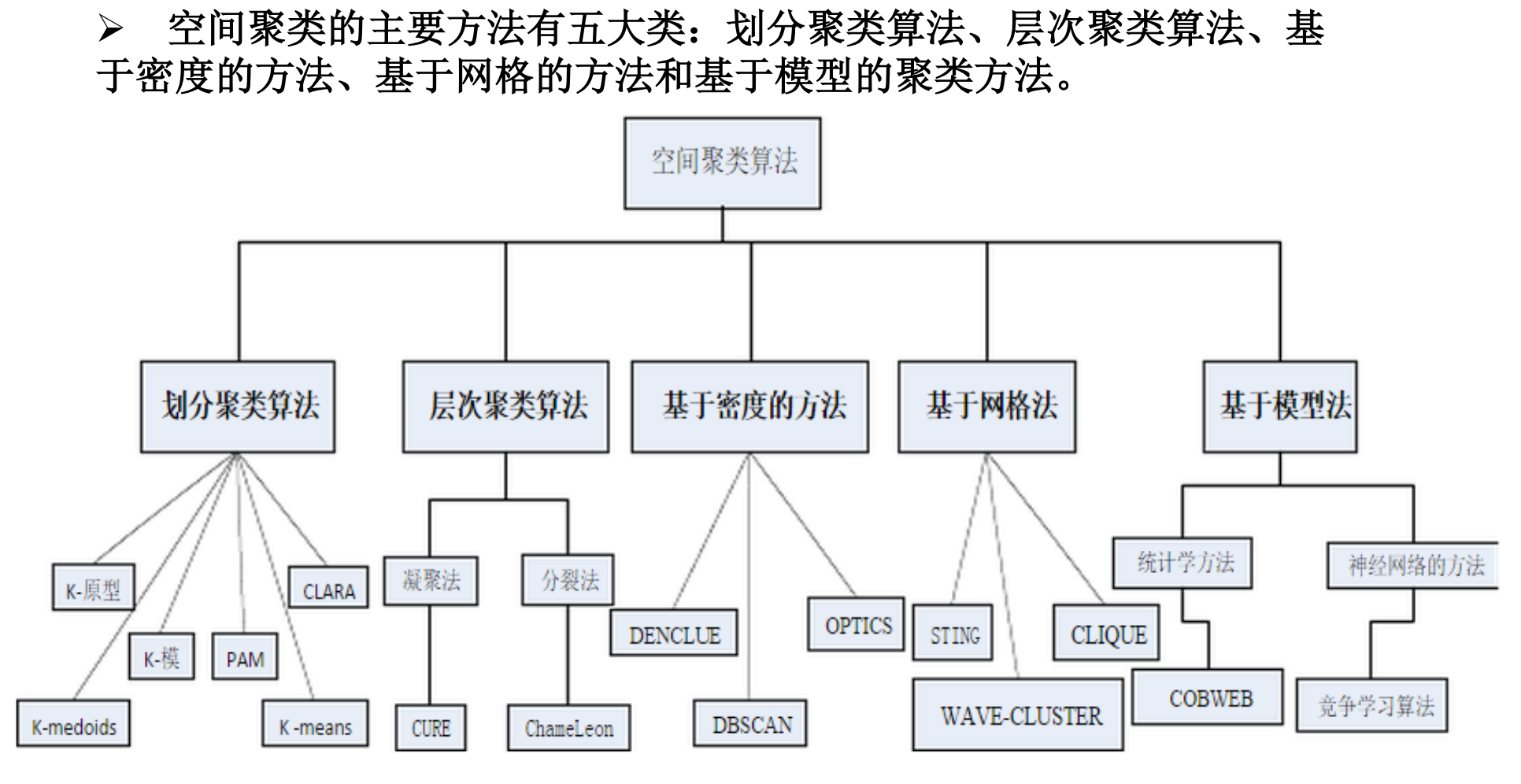
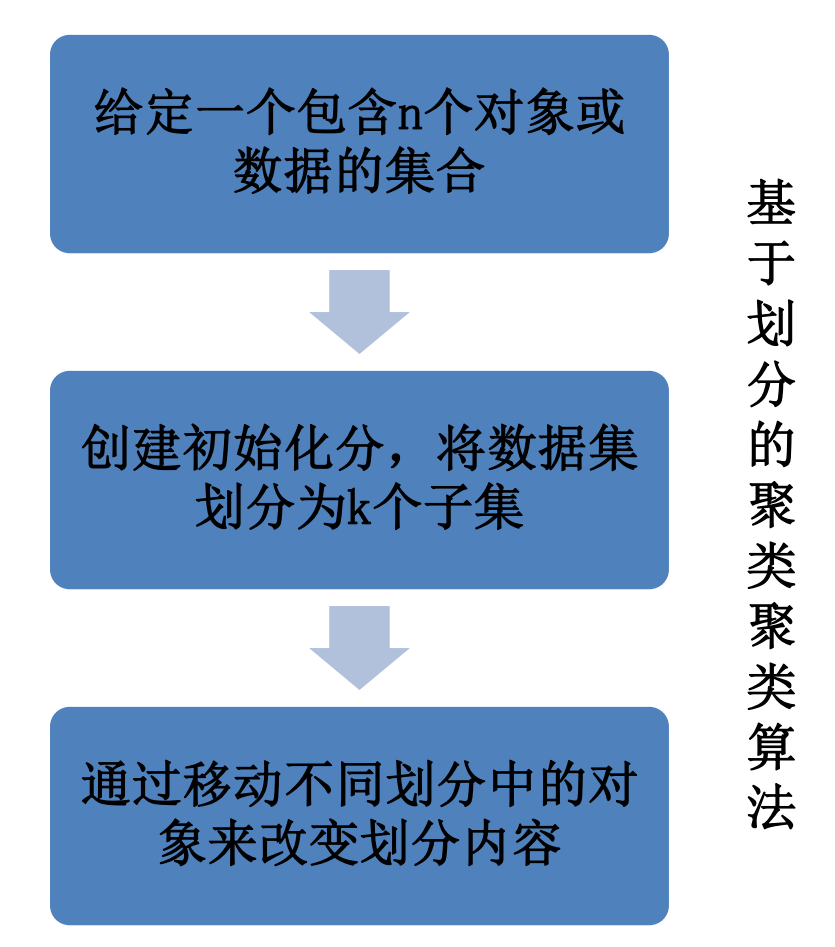
基于划分的聚类算法
基于划分的聚类算法
K-means算法


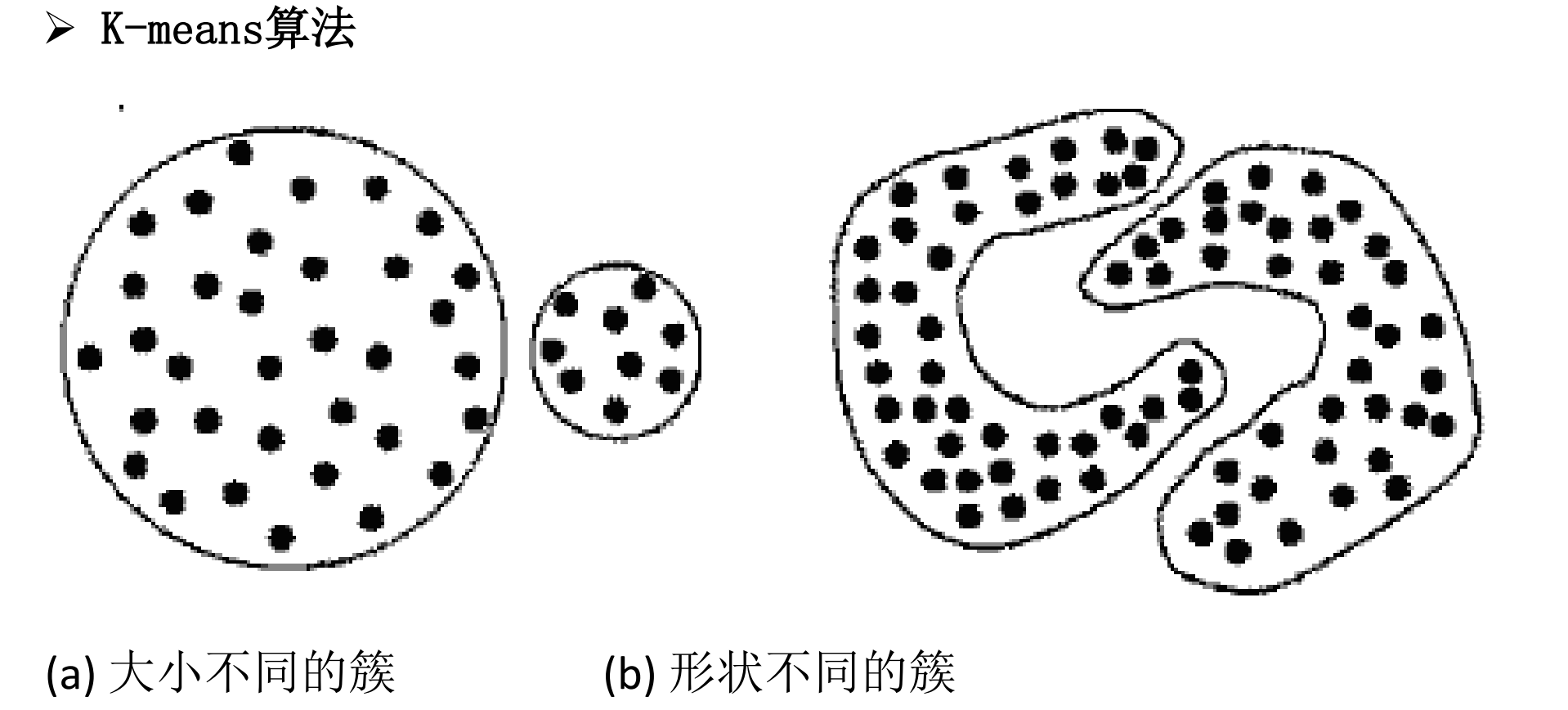
K-medoids算法

基于划分的聚类算法比较
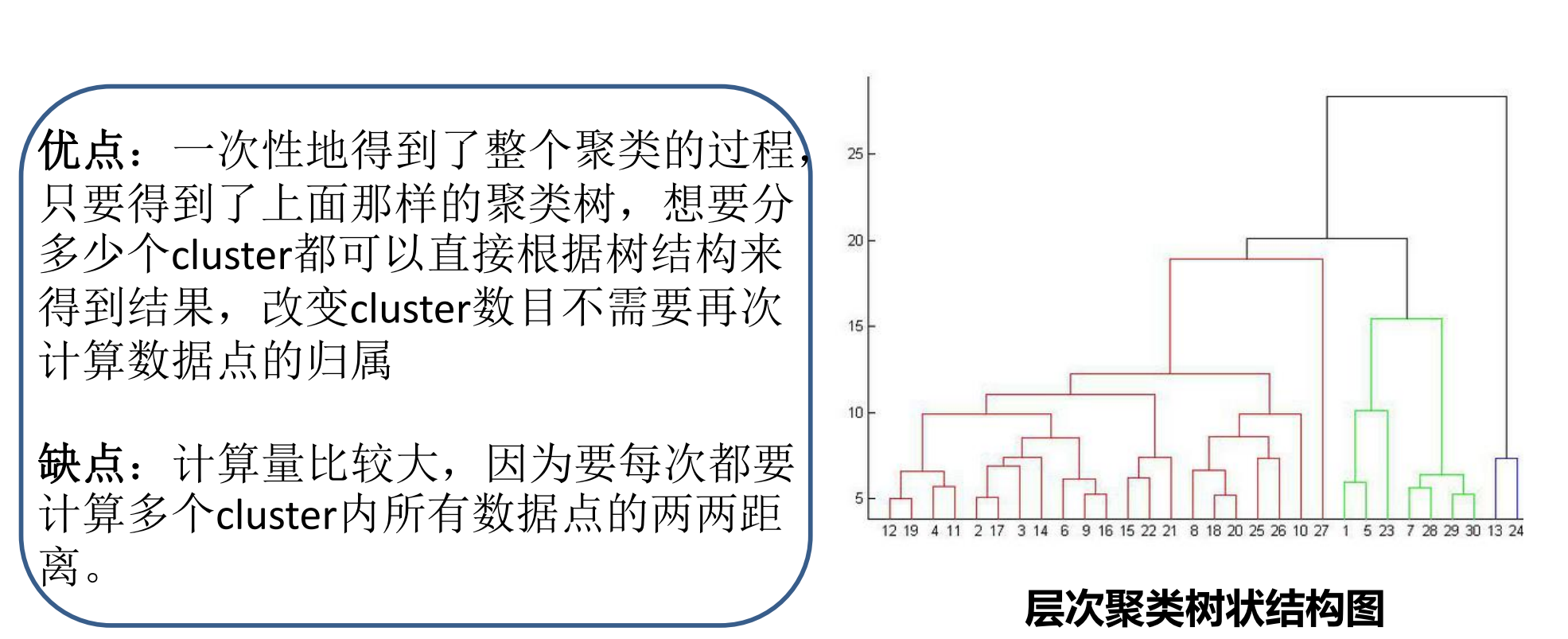
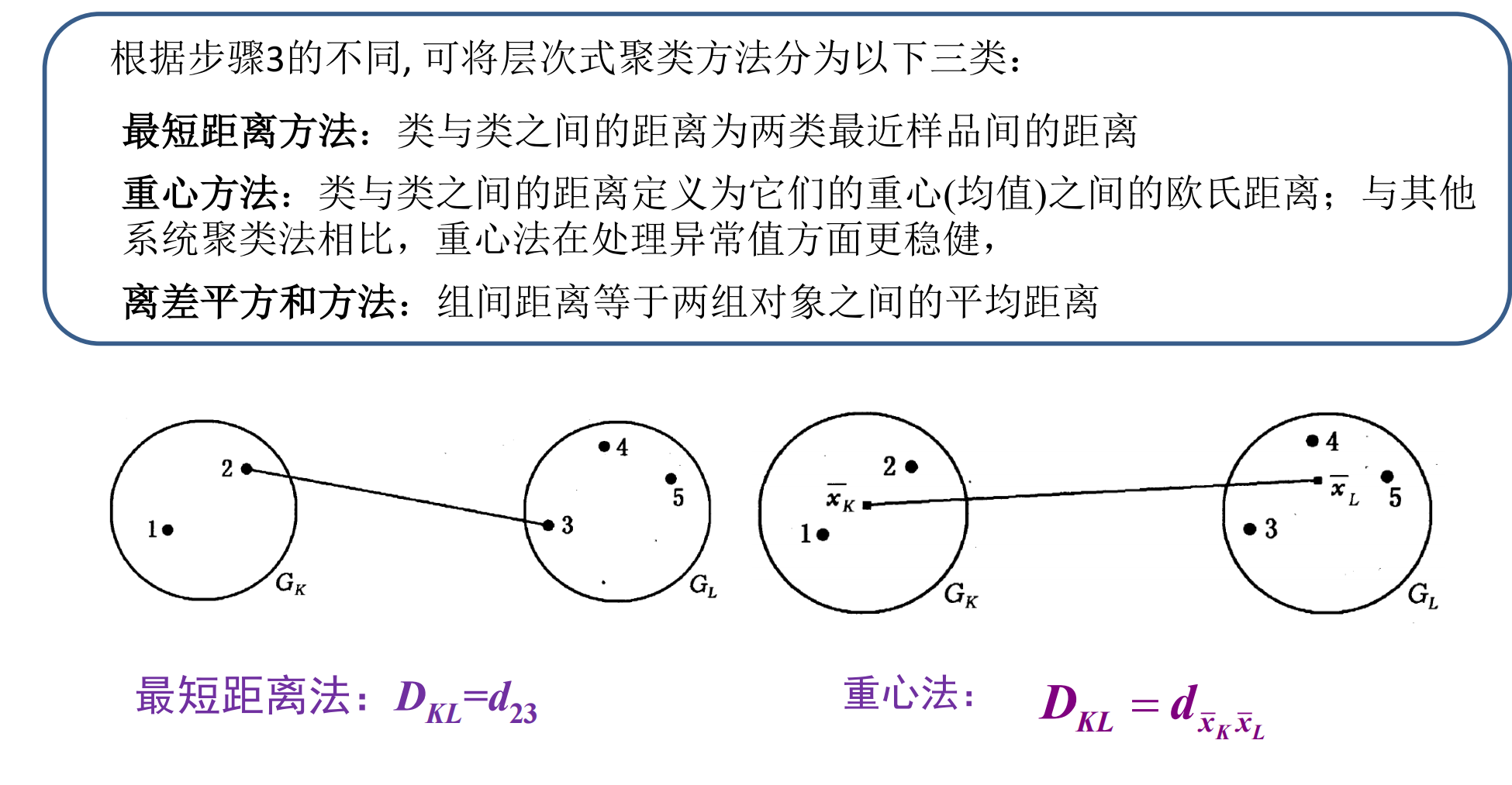
层次聚类算法



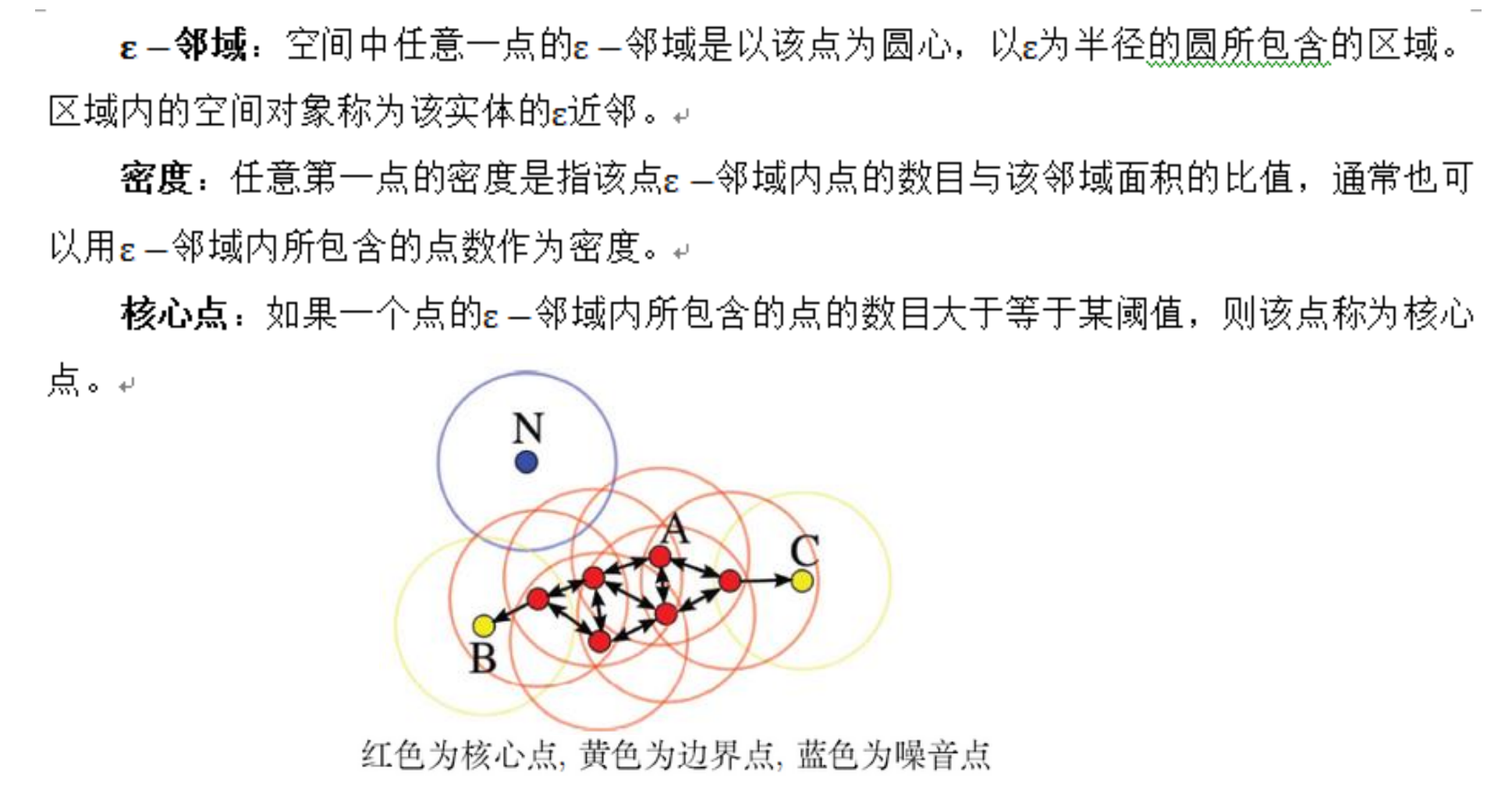
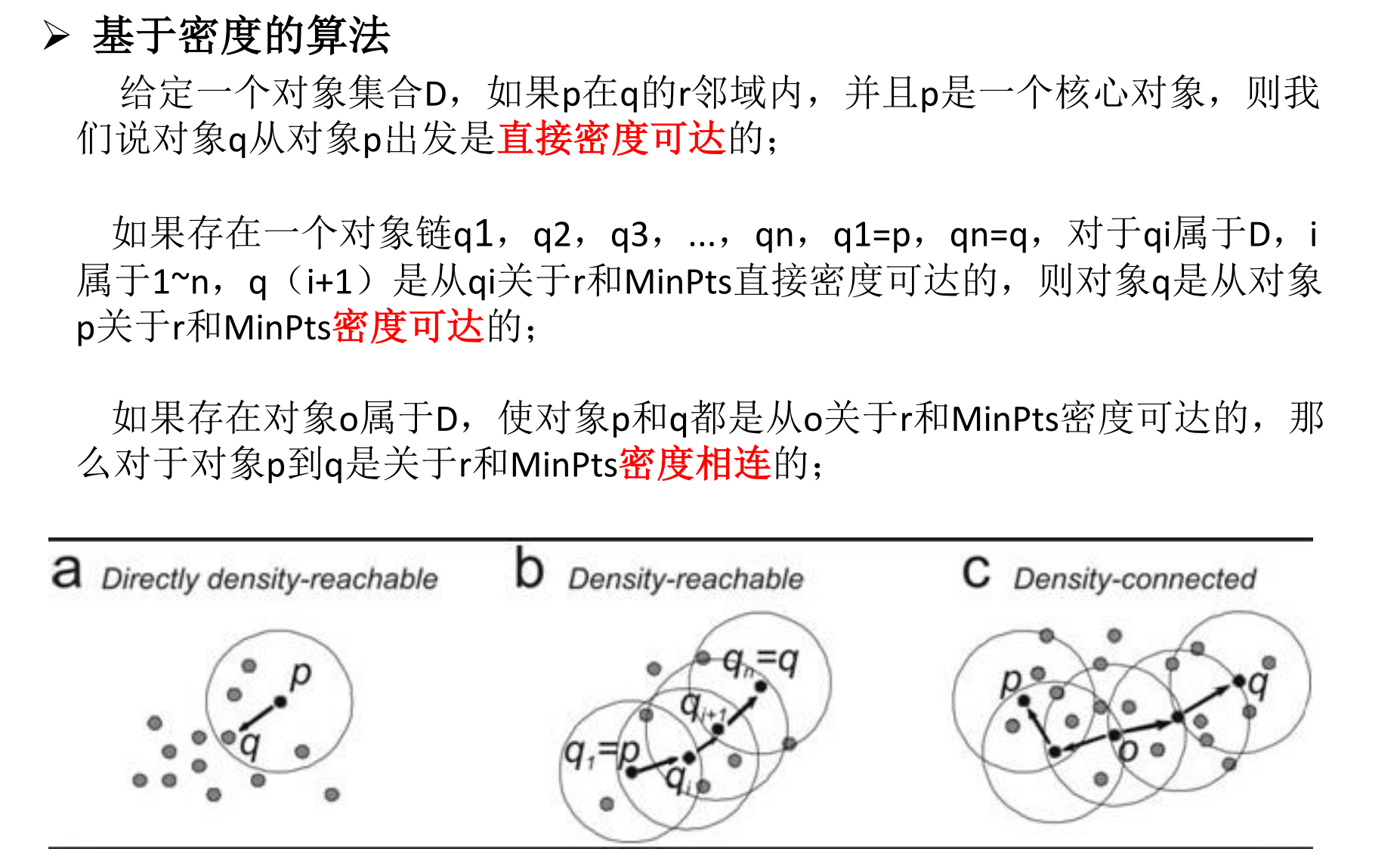
基于密度的算法
核心思想
:基于密度的聚类算法是数据挖掘技术中被广泛应用的一类方法, 其核心思想是用一个点邻域内的邻居点数量衡量该点所在空间的密度.
特点
:它可以找出形状不规则的聚类簇,且聚类时不需要事先知道聚类簇的个数。
DBSCAN算法的步骤


局部联通性的聚类方法
基于局部点连通性的聚类方法实现交叉口与非交叉口识别;
根据交叉口细节结构随道路结构详细程度的变化,分为
交叉口与非交叉口识别
、
交叉口分/合流点提取
以及
交叉口车道级结构获取
3
个层次。
➢
首先,根据轨迹跟踪获取车辆转向点对,利用基于距离和角度的生长聚类方法对其完成空间聚类
➢
然后,采用基于局部点连通性的聚类方法实现交叉口与非交叉口识别;
➢
最后,基于交叉口范围圆及转向点对类簇,提取包含分/合流点的车行道级别交叉口结构和包含转向信息的车道级别交叉口空间结构。
基于图的聚类算法
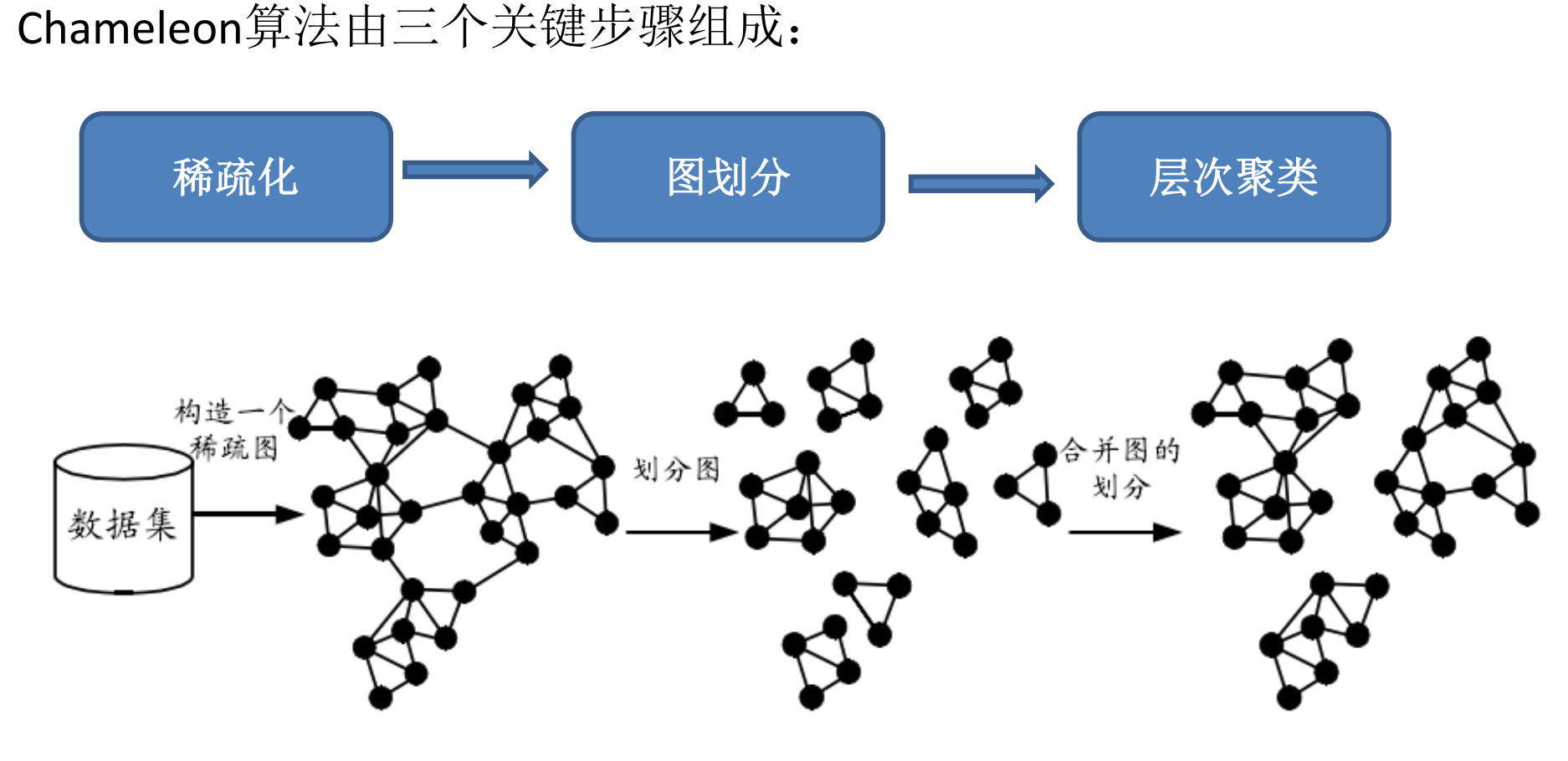
基于图的聚类算法需要用到一些重要方法
(1)
稀疏化邻近度图,只保留对象与其最近邻之间的连接。这种稀疏化有利于降低噪声和离群点的影响。可以利用为稀疏图开发的有效图划分算法来进行稀疏化。
(2)
基于共享的最近邻个数,定义两个对象之间的相似性度量。该方法基于这样的观察,对象和它的最近邻通常属于同一个簇。该方法有助于克服高维和变密度簇的问题。
(3)
定义核心对象并构建环绕它们的簇。与
DBSCAN
一样,围绕核心对象构建簇,设计可以发现不同形状和大小的簇的聚类技术。
(4)
使用邻近度图中的信息,提供两个簇是否应当合并的更复杂的评估。两个簇合并仅当结果簇具有相似于原来的两个簇的特性。

Chameleon聚类算法

聚类算法评价
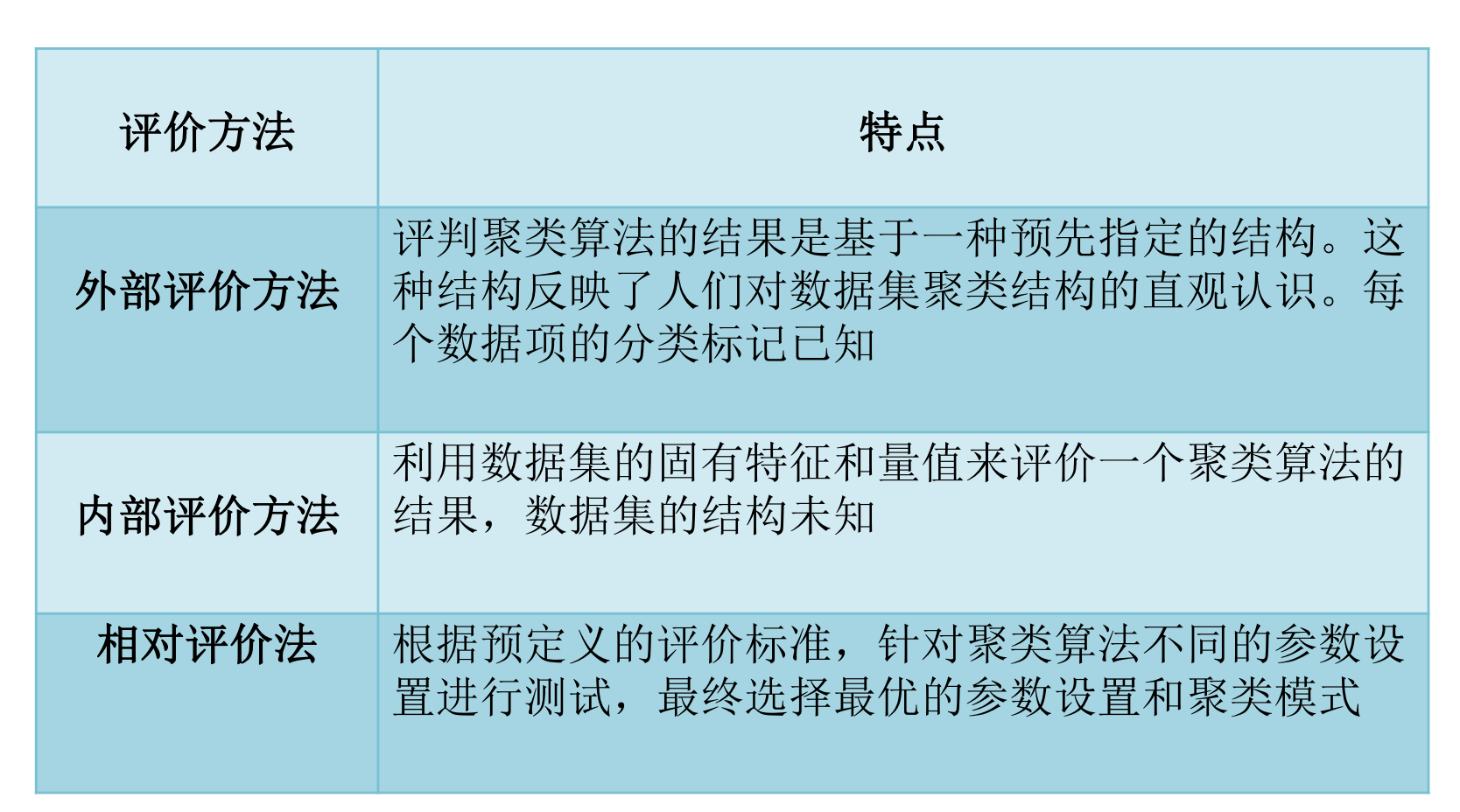
如何用一种客观公正的质量评价方法来评判聚类结果的有效性是一个困难而复杂的问题。常用的聚类有效性评价方法有外部评价法、内部评价法和相对评价法。
高质量的簇:高的簇内相似度和低的簇间相似度。
评估聚类结果质量的准则有两种
:
内部质量评价准则
(internal quality measures)
通过计算簇内部平均相似度、簇间平均相似度或整体相似度来评价聚类效果,这类指标常用的包括DB
指标
,Dunn
指标, I
指标
,
CH
指标,
Xie-Beni
指标等。
外部质量评价准则
(external quality measures)
基于一个已经存在的人工分类数据集
(
已经知道每个对象的类别)
进行评价



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









