







1. STL
1.1 priority_queue
class Task {
public:
string name;
int priority;
Task(string n, int p) : name(move(n)), priority(p) {}
// 重载操作符'>'
bool operator>(const Task& other) const {// 注意两处const
return priority > other.priority;
}
bool operator<(const Task& other) const {
return priority < other.priority;
}
};
int main() {
// 初始化优先队列(最小堆)
priority_queue<Task, vector<Task>, greater<Task>> taskQueue;
// 最大堆可以采取默认初始化:priority_queue<Task> maxHeap;
// push操作
taskQueue.push(Task("TaskA", 3));
taskQueue.push(Task("TaskB", 1));
taskQueue.push(Task("TaskC", 2));
// 判断非空
while (!taskQueue.empty()) {
Task currentTask = taskQueue.top();
cout << "Executing task: " << currentTask.name << " (Priority: " << currentTask.priority << ")\n";
taskQueue.pop();
}
}
1.2 multiset
// mutiset支持log n增删改查,而priority_queue不支持改和查
// 因此multiset爆杀优先队列,仅仅略多占用空间
mutiset<array<int, 5>> seq;
// array存储一系列节点信息,按照[0],[1],[2],[3],[4]依次排序
auto it = next(seq.begin(), n-1); // 访问第n个元素
auto pos = seq.lower_bound(target); // 获取第一个不小于target元素的迭代器
auto pre = prev(pos); // 从边界点向上寻找
if (pos != seq.end())
{
int a = (*pos) + 1;
seq.erase(pos); // 改动后需要删除,再插入
seq.insert(a);
}
1.3 unordered
// 键值唯一,实现常数级的增删改查
// getline(cin, text);
string text = "This is a sample text with some sample words. "
"This text is used for demonstration purposes.";
unordered_set<string> uniqueWords;
unordered_map<string, int> wordCount;
istringstream iss(text);
string word;
// 利用字符流,以空格为分隔读入string作为单词
while (iss >> word) {
for (char& c : word) {
c = tolower(c);
}
// 进行统计,更新数据
uniqueWords.insert(word);
wordCount[word]++;
}
// 输出每个单次出现的单词
cout << "Number of unique words: " << uniqueWords.size() << endl;
// 输出每个单词和它的出现次数
for (const auto& pair : wordCount) {
std::cout << pair.first << ": " << pair.second << " times\n";
}
// 求交集、并集、差集
set<int> a = {1,2,3,4,5}, b = {1,3,6}, c;
set_union(a.begin(), a.end(), b.begin(), b.end(), inserter(c, c.begin()));
set_difference();
set_intersection();//语法相同
1.4 stringstream
// istringstream仅读取字符流,stringstream在其基础上可以修改字符串
stringsteam ss;
int num = 42;
double pi = 3.1415926;
string words = "Combination of different objects";
ss << num << "," << pi << "," << words;
cout << ss.str() << endl;
1.5 algorithm
// 1. 找特定/最大/最小值
vector<int> number = {1, 2, 3, 4, 5};
int base[5] = {1, 2, 3, 4, 5};
cout << *max_element(number.begin(), number.end()) << ",";
cout << *min_element(base, base+5) << endl;
auto temp = find(arr.begin(), arr.end(), 3);
cout << "value: " << *temp << "index: " << temp - arr.begin() << endl;
// 更方便的写法:必须提交初始化列表作为参数
min({1, 2, 3, 4, 5});
// 2. 排序和去重
function<bool(int, int)> cmp = [&](int a, int b)->bool{
return a > b;
};
sort(number.begin(), number.end(), cmp);
auto uni = unique(number.begin(), number.end());
// 3. 数组操作
int books[1024];
fill(books, books + 1024, INT_MAX);
int numss[5] = {1,2,3,4,5};
reverse(numss, numss+5);
string aLine = "12345678";
reverse(aLine.begin(), aLine.end());
return 0;
1.6 numeric
vector<int> nums = {1,2,3,4,5,6,7};
// 1. 计算求和
cout << accumulate(nums.begin(), nums.end(), 0) << endl;
// 第三个参数是初始值,一般为0
// 2. 计算前缀和,时间复杂度O(n)
vector<int> partialSums(nums.size());
partial_sum(nums.begin(), nums.end(), partialSums);
// 3. 赋值数组
vector<int> arr(n+1);
iota(arr.begin(), arr.end(), 0);
vector<int> v1 = {1, 2, 3};
vector<int> v2 = {4, 5, 6};
// 4. 计算内积
int result = inner_product(v1.begin(), v1.end(), v2.begin(), 0);
cout << "Inner Product: " << result << endl;
// 5. gcd&lcd
int m = 12, n = 18;
cout << gcd(m,n) << "," << lcd(m,n) << endl;
1.7 bitset
// 1. 初始化
bitset<8> bs1; // 默认全0
bitset<8> bs2(42); // 值为42的8位二进制数
bitset<8> bs3("10101010")
// 2. 位操作
bool flag = bs2[2];
bs3.set(3); // 设置第4位为1(0号位是第1位)
bs1.flip(); // 翻转所有位的值
// 3. 位运算
bitset<8> res1 = bs1 & bs2; // 按位与
auto res2 = bs1 | bs2; // 按位或
auto res3 = bs2 ^ bs3; // 按位异或
1.7 C++特性
// 本地调试与优化输入输出
#define LOCAL
void work()
{
string acp;
cin >> acp;
cout << acp << " -checked" << endl;
}
int main(){
#ifdef LOCAL
freopen("data-in.txt", "r", stdin);
freopen("data-out.txt", "w", stdout);
#endif
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int CASES = 5;
while(CASES--) work();
return 0;
}
// 建议编译器内联展开,优化函数效率
inline void func()
{
return;
}
// remove_if-erase组合
nums.erase(remove_if(nums.begin(), nums.end(),
[](const auto &a){return a % 2 == 0;}), nums.end());
// 删除了数组中满足特定要求的元素,而不会导致迭代器紊乱
// 适用于deque、list等,而对于map等关联容器和stack、queue
// 只能通过for循环删除:
map<string, int> m = {{"a", 1}, {"b", 2}, {"c", 3}};
for (auto it = m.begin(); it != m.end(); it++)
{
if (it[0] == 'a')
it = m.erase(it);// erase返回下一个有效迭代器
}
// 判断字符串是否为整数
bool isInteger(const string& str) {
try {
stoi(str); // 尝试将字符串转换为整数
return true; // 转换成功,字符串是整数
} catch (const invalid_argument& e) {
// 转换失败,字符串不是整数
return false;
} catch (const out_of_range& e) {
// 数字超出了int的范围,但仍然是整数
return true;
}
}
// 类初始化
class person{
public:
string name;
int id;
vector<string> titles;
person(string name, int id) : name(name), id(id), titles(100, ""){};
};
// C++的结构体视作全部成员为public的类
struct person{
string name;
int id;
vector<string> titles;
person(string name, int id) : name(name), id(id), titles(100, ""){};
};
// 重构操作符
struct mat{
long long a11, a12, a21, a22;
// 如果定义了构造函数,就不可以再使用列表初始化
mat operator* (const mat&a, const mat& b){
long long c11, c12, c21, c22;
// 模拟矩阵乘法
return {c11, c12, c21, c22};
}
// 注意此处必须有friend关键字,作用是访问该类的私有属性
friend istream& operator >> (istream& in, mat& x){
return in >> x.a11 >> x.a12 >> x.a21 >> x.a22;
}
// 注意此处对象必须有const属性
friend ostream& operator << (ostream& out, const mat& x){
return out << x.a11;
}
}
2. 进阶数据结构
2.1 并查集
力扣684. 冗余连接
https://leetcode.cn/problems/redundant-connection/
力扣685. 冗余连接 II
https://leetcode.cn/problems/redundant-connection-ii/
int find(vector<int>& parent, int index)
{
if (index != parent[index])
parent[index] = find(parent, parent[index]);
return parent[index];
}
void Union(vector<int> &parent, int node1, int node2)
{
// 2的父节点是1
parent[find(parent, node2)] = find(parent, node1);
}
// 判断新加入的边是否构成了环:
if (find(parent, u) == find(parent, v))
return {u,v}; // u和v点已经访问过(同根节点),因此再次访问则构成环
else
Union(parent, u, v);// 将含v的子树并入u的根节点
// 注意由于Union前已经调用过find(parent,u),此时parent[u] == find(parent,u)
// 所以写哪个都对
2.2 字典树/前缀树(Trie)
力扣3045. 统计前后缀下标对 II
https://leetcode.cn/problems/count-prefix-and-suffix-pairs-ii/
struct node{
unordered_map<int, node*> sons;
int cnt;
};
node root = new node();
for (string s : words)
{
auto cur = root;
for (int i = 0; i < s.length(); i++)
{
int idx = (int) s[i] - 'a';
// 一种同时统计前后缀的写法:
// int idx = (int) s[i] - 'a' << 5 | s[n-i-1] - 'a';
// 先去前缀的字母编号,再左移,腾出空间给后缀字母编号
if (cur->sons[idx] == nullptr)
{ // 添加新前缀
cur->sons[idx] = new node();
}
cur = cur->sons[idx];
ans += cur->cnt; // 计算当前具有该前缀的单词个数
}
cur->cnt++; // 以整个单词作为前缀,亦即提交给你前缀和目标单词的区分
// 如果是要在所有目标单词中统计可能的前缀,则要在最深层循环中cnt++
}
2.3 差分数组
力扣1094. 拼车
https://leetcode.cn/problems/car-pooling/
// d[i] = a[i]-a[i-1] (a[0] = 0, d[1] = a[1])
// s[i+1] = s[i] + d[i], 则有s[i] = a[i]
// 对于需要对整个区间范围(如a[l]~a[r])同时增加一个数的时候
// 只需要对差分数组的两端进行:d[l] += v, d[r+1] -= v;
// 时间复杂度由O(n)到O(2)
// map实现(不需要重构的情况下省空间):
map<int, int> diff; // 注意不能用unordered_map,要保留顺序性
for (auto it : changes)
{
int from = it[0], to = it[1], v = it[2];
diff[from] += diff;
diff[to] -= diff;
}
// 数组实现
int diff[1024], len = 1024;
auto update = [&diff](int from, int to, int v){
diff[from] += v;
if (to+1 < len)
diff[to+1] -= v;
};
// 重构结果
for (int i = 1; i < len; i++)
diff[i] += diff[i-1];
2.4 二维前缀和
力扣1277. 统计全为 1 的正方形子矩阵
https://leetcode.cn/problems/count-square-submatrices-with-all-ones/
int m = matric.size(), n = matric[0].size();
vector<vector<int>> sum(m+1, vector<int>(n+1,0));
for (int i = 0; i < m; i++)
{
for (int j = 0; j < n; j++)
{
sum[i+1][j+1]=sum[i+1][j] + sum[i][j+1] - sum[i][j] + metric[i][j];
// 往往搭配ans使用,可以ans可以metric中全体位置的总和
// 也可以是某个过程值
ans += sum[i+1][j+1]
}
}
2.5 树状数组
力扣307. 区域和检索 - 数组可修改
https://leetcode.cn/problems/range-sum-query-mutable/description/
力扣3072. 将元素分配到两个数组中 II
https://leetcode.cn/problems/distribute-elements-into-two-arrays-ii/
// 树状数组:更新/查询时间复杂度O(logN)
class treeArr{
private:
vector<int> nums;
vector<int> tree;// tree.size() = num.size()+1, 空间复杂度O(n)
int prefixSum(int i){
int s = 0;
for (; i > 0; i &= i-1)// i -= i & -i
s += tree[i];
return s;
}
public:
treeArr(vector<int> &nums) : nums(nums.size()), tree(nums.size() + 1){
for (int i = 0; i < nums.size(); i++)
{
update(i, nums[i]);
}
}
int update(int index, int val)
{
int d = nums[index] - val; // 初始化时默认元素值为0
nums[index] = val;
for (int i = index; i < nums.size(); i += i & -i){
tree[i] += d;
}
}
int getSumRange(int left, int right){// right left存放的是nums数组中元素的下标
return prefixSum(right+1) - prefixSum(left);
// prefixSum给出的是前i个元素的和,假设需要0~n-1的和,则为前n个数的和
// 因此前right+1个数的和减去前left个数,是[left, right]区间和
}
}
2.6 线段树
力扣2286. 以组为单位订音乐会的门票
https://leetcode.cn/problems/booking-concert-tickets-in-groups/
class SegTree{
public:
int n; // 原数组长度
vector<long long> sum;
vector<int> minVal; // 要维护的区间特征值,这里以区间和、最小值为例
// 用长度4n的数组模拟树结构,变量t是用来访问树节点的
void add(int t, int l, int r, int idx, int val)
{// 增加idx位置的值,l和r是左右端点,在二分过程中反复改变
if (l==r) {
minVal[t] += val;// 注意更新逻辑
sum[t] += val; // 只用val直接修改最底层的叶子节点
return;
}
int m = (l+r)/2;
if (idx <= m) add(t*2, l, m, idx, val);
else add(t*2+1, m+1, r, idx, val);
// 以左右子树更新当前节点
minVal[t] = min(minVal[2*t], minVal[2*t + 1]);
sumVal[t] = sumVal[2*t] + sumVal[2*t + 1];
}
long long getSum(int t, int l, int r, int L, int R)
{// 返回[L, R]区间和,关联于特征值sum
if (L <= l && r <= R) return sum[t];
// 当前区间在求和范围内,立刻返回累加
long long res = 0;
int m = (l+r)/2;
// 所求区间不规则,用二分去逼近,最终分块得到了[L,R]
if (L <= m)
res += getSum(t*2, l, m, L, R);
if (R > m)
res += getSum(t*2+1, m+1, r, L, R);
return res;
}
int index(int t, int l, int r, int R, int val)
{// 查询[1,R]区间内<=val的位置,关联于特征值minVal
if (minVal[t]> val)// 从根节点来看,都不符合条件
return 0;
if (l == r)// 找到了
return l;
int m = (l+r)/2;
if (minVal[t*2] <= val)// 左子树满足条件,规定先去左子树寻找
return index(t*2, l, m, R, val);
else if (m< R)// 左子树不满足再去右子树,要求m+1<=R
return index(t*2+1, m+1, r, R, val);
return 0; // 保证出口
}
}
2.7 网络流
力扣2850. 将石头分散到网格图的最少移动次数
https://leetcode.cn/problems/minimum-moves-to-spread-stones-over-grid/
2.8 分块数组
// 分块数组好处在于连接区间时更加直观
struct node{
// 各种数据
int op;
mat l, r;// 模拟矩阵乘法,无交换律区分左右
}arr[N];
// n为数组总长度
int LEN = max(1, (int)sqrt(n));
struct block{
int front, back, sz;
long long suml[M], sumr[M];
// idx是块编号
void build(int idx)
{
front = idx*LEN, back = min(front + LEN - 1, n - 1);
sz = back - front + 1;
for (int i = 0; i < sz; i++)
{
int c = i + front;
suml[i+1] = arr[c].l * suml[i];
sumr[i+1] = sumr[i].r*arr[c];
}
}blk[M];
for (int i = 0; i < n; i += LEN)
blk[i/LEN].build(i/LEN);
3. 图论
3.1 Dijkstra&Floyd(最短路)
Dijkstra:单源最短路径
力扣1976. 到达目的地的方案数
https://leetcode.cn/problems/number-of-ways-to-arrive-at-destination/
// 贪心算法:每次都选取最短的边进行构造
vector<vector<pair <int, int>>> edges;// <距离,终点>
vector<long long> dis(n,0);
priority_queue<pair<long long, int>, vector<pair<long long, int>>, greater<>> pq;
while(true)
{
auto [dx, x] = pq.top();
// dx:迄今为止路径总长
pq.pop();
if (x == n-1)
break;// 算法结束,已找到0->n-1的最短路
if (dx > dis[x])
continue;
for (auto &[dy, y] : edges[x])
{
int new_dis=dy+dis[x];
if (new_dis < dis[y])
{
dis[y] = new_dis;
pq.push(new_dis, y); // 加入可能最短的0->y路径
// 如果不是最短,已经在if(dx>dis[x])排除了
}
}
}
Floyd:全源最短路径
力扣1334. 阈值距离内邻居最少的城市
https://leetcode.cn/problems/find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance/description/
// 查找所有两点间最短路径
// 关键点:dp(k+1, i, j) = max( dp(k, i, j), dp(k, i, k) + dp(k, k, j) )
// 把除了ij以外的所有点视作中间节点,用选与不选缩小问题范围
// k从n-1开始遍历,意为前k个节点,即考虑了所有编号<=k的节点
vector<vector<int>> edges(n, vector<int>(n, INT_MAX/2));
// 回溯+记忆化
int memo[128][128][128] = {0};
auto dfs = [&memo] (int k, int i, int j){
if (k<0) // 遍历到k=-1,算法结束
return edges[i][j];
return memo[k][i][j] = min(dfs(k-1, i, j), dfs(k-1, i, k) + dfs(k-1, k, j));
}
// 动态规划O(n^3)空间
vector<vector<vector<int>>> dp(n, vector<int>(n, vector<int> (n) ) );
dp[0] = edges;// 当k=0,意为无中间节点,则距离等于单边
for (int k = 0; k < n; k++)
{
for (int i = 0; i < n; i++)
{
for (int j = 0;j < n; j++)
{
dp[k+1][i][j] = min(dp[k][i][j], dp[k][i][k]+dp[k][k][j];
// 对于dp[k][i][k],可知i到k的中间节点肯定没有k
// 所以推导出dp[k][i][k] = dp[k-1][i][k]
// 则对于所有的z,dp[z][i][z] = dp[z-1][i][z-1],dp[k][k][j]同理
// 说明位置前后不改变,可以放心变成二维
}
}
}
// 动态规划O(n^2)空间
vector<vector<int>> dp = edges;
for (int k = 0; k < n; k++)
{
for (int i = 0; i < n; i++)
{
for (int j = 0;j < n; j++)
{
dp[i][j] = min(dp[i][j], dp[i][k]+dp[k][j];
}
}
}
3.2 Kruskal&Prim(MST,Minimum Spanning Tree)
力扣1584. 连接所有点的最小费用
https://leetcode.cn/problems/min-cost-to-connect-all-points/
3.3 SPFA(Shortest Path Faster Algorithm)
3.4 二分图
4. 树上
4.1 树链剖分
设nd.sz表示以某个节点为根的子树的节点个数
对于每个非叶子节点,sz值最大的子节点就是重儿子,其他为轻儿子
重儿子及父节点连起来就是重链
树链剖分就是把重链放在一起做成线性区间,按该顺序以线段树维护
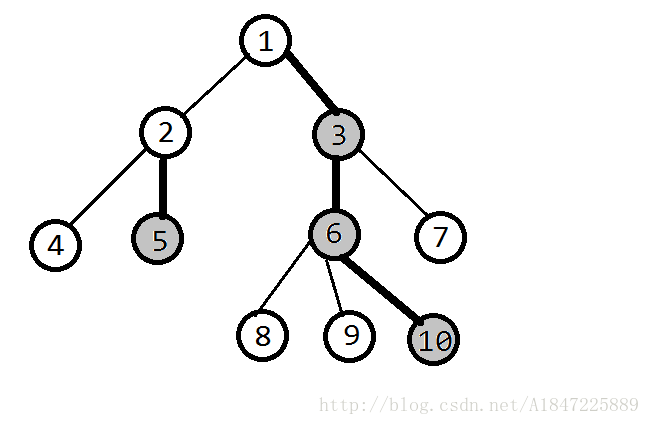
顺序为1,3,6,10,8,9,7,2,5,4
首先,使用O(n)的dfs(dfs1),求出depth(深度),father,size,heavy_son(重儿子)。
然后,再使用O(n)的dfs(dfs2),求出top、to_tree、to_num
对于点x,若x为重儿子,top为x所在重链的顶端;若x为轻儿子,top=x(可以将每个轻儿子当成一条重链)。
求top其实很简单,递归时设一个参数k,表示x.top。
递归给重儿子时,k不变;
递归给轻儿子时,k为它本身。
对于点x,to_tree表示x在线段树中的位置。对于线段树中的第i个位置,to_num为它对应树中的位置。
const int N = 100010, M = N << 1;
int n, m, rt, mod;
int w[N], h[N], e[M], ne[M], idx;
int id[N], nw[N], cnt;
int dep[N], sz[N], top[N], fa[N], son[N];
struct segtree
{
int l, r;
ll add, sum;
}tr[N << 3];
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
return;
}
void dfs1(int p, int father, int depth)
{
dep[p] = depth, fa[p] = father, sz[p] = 1;
for(int i = h[p]; ~i; i = ne[i])
{
int j = e[i];
if(j == father) continue;
dfs1(j, p, depth + 1);
sz[p] += sz[j];
if(sz[son[p]] < sz[j]) son[p] = j;
}
return;
}
void dfs2(int p, int t)
{
id[p] = ++cnt, nw[cnt] = w[p], top[p] = t;
if(!son[p]) return;
dfs2(son[p], t);
for(int i = h[p]; ~i; i = ne[i])
{
int j = e[i];
if(j == fa[p] || j == son[p]) continue;
dfs2(j, j);
}
return;
}
void pushup(int p)
{
tr[p].sum = (tr[p << 1].sum + tr[p << 1 | 1].sum) % mod;
return;
}
void pushdown(int p)
{
auto &root = tr[p], &left = tr[p << 1], &rght = tr[p << 1 | 1];
if(root.add)
{
left.add = (left.add + root.add) % mod;
left.sum = (left.sum + root.add * (left.r - left.l + 1)) % mod;
rght.add = (rght.add + root.add) % mod;
rght.sum = (rght.sum + root.add * (rght.r - rght.l + 1)) % mod;
root.add = 0;
}
return;
}
void build(int p, int l, int r)
{
tr[p] = { l, r, 0, nw[r] };
if(l == r) return;
int mid = (l + r) >> 1;
build(p << 1, l, mid);
build(p << 1 | 1, mid + 1, r);
pushup(p);
return;
}
void segadd(int p, int l, int r, int k)
{
if((l <= tr[p].l) && (r >= tr[p].r))
{
tr[p].add = (tr[p].add + k) % mod;
tr[p].sum = (tr[p].sum + k * (tr[p].r - tr[p].l + 1)) % mod;
return;
}
pushdown(p);
int mid = (tr[p].l + tr[p].r) >> 1;
if(l <= mid) segadd(p << 1, l, r, k);
if(r > mid) segadd(p << 1 | 1, l, r, k);
pushup(p);
return;
}
ll segsum(int p, int l, int r)
{
if((l <= tr[p].l) && (r >= tr[p].r)) return tr[p].sum;
pushdown(p);
int mid = (tr[p].l + tr[p].r) >> 1;
ll res = 0;
if(l <= mid) res += segsum(p << 1, l, r);
if(r > mid) res += segsum(p << 1 | 1, l, r);
return res % mod;
}
4.2 树上DP
5. 算法模板
5.1 字符串
5.1.1 扩展KMP(Z函数)
力扣3036. 匹配模式数组的子数组数目 II
https://leetcode.cn/problems/number-of-subarrays-that-match-a-pattern-ii/
5.1.2 字符串哈希
力扣1392. 最长快乐前缀
https://leetcode.cn/problems/longest-happy-prefix/
5.1.3 AC自动机
5.2 DP
5.2.1 状态压缩DP
5.2.2 数位DP
5.2.3 划分DP
6. 数学
#include <cmath>
sin(), cos(), tan();
double intPart, fracPart, toBeSplit = 3.125;
fracPart = modf(toBeSplit, &intPart);
// 筛法判断素数
vector <int> pms;
bool isPrime[N];
fill(isPrime + 1, isPrime + N + 1, true);
void isPm()
{
for (int i = 2; i*i <=n; i++)
{
if (isPrime[i])
{
pms.push_back(i);
for (int j = i*i; j <=n; j+=i)
isPrime[j] = false;
}
}
}
// 分解质因子
typedef vector<pair<int, int>> vpii;
vpii divide(int n)
{
vpii res;
for (int i= 2; i*i <= n; i++)
{
if (n%i==0)
{
int j = 0;
while(n%i==0)
{
n/=i;
j++;
}
res.push_back({i,j});
}
}
}
6.1 位运算技巧
// 按位 &与, |或, ^亦或, ~取反
int n, x, k;
x << n; // 左移n位
x >> n; // 右移n位
// 逻辑右移
x|1; // 最后一位变为1
(x|1)-1; // 最后一位变为0
x^1; // 最后一位取反
x|(1<<(k-1)) // 右数第k位变1
x& ~(1<<(k-1)) // 右数第k位变0
x^(1<<(k-1)) // 右数第k位取反
x&(1<<k -1) // 取末k位数字
x>>(k-1) &1 // 取右数第k位数字
x&(x+1) // 把右起连续的1变0, 前面的不变, 如010111->010000
x|(x+1) // 把右起第一个0变1
void swap(int &a, int &b)
{
a ^= b;
b ^= a;
a ^= b;
}
int change(int a)
{
return ~a +1;
}
// 统计二进制1个数
int count(int x){
int cnt = 0;
while(x){
cnt += x & 1;
x = x >> 1;
}
return cnt;
}















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









