







目录
0.接上篇文章
1.粗略的见一下这两个问题
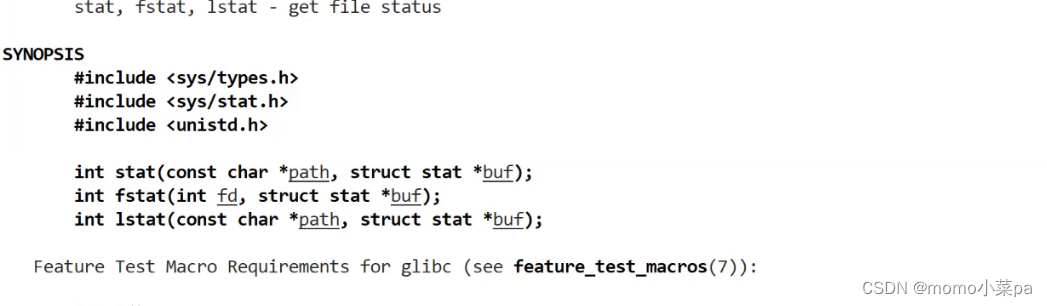
先来了解几个函数:
stat()函数用于获取指定文件或符号链接的元数据。如果文件是一个符号链接,stat()将返回该符号链接本身的元数据,而不是它所指向的目标文件的元数据。
fstat()函数用于获取已打开文件的元数据。它通常用于在文件描述符已经打开之后获取文件的元数据。
lstat()函数与stat()函数类似,但它专门用于获取符号链接的元数据。如果指定的文件是一个符号链接,lstat()将返回该符号链接本身的元数据,而不是它所指向的目标文件的元数据。
fd:一个已打开的文件描述符。
buf:一个指向struct stat的指针,用于存储符号链接的元数据。path:要检查的文件或目录的路径。这三个函数都使用
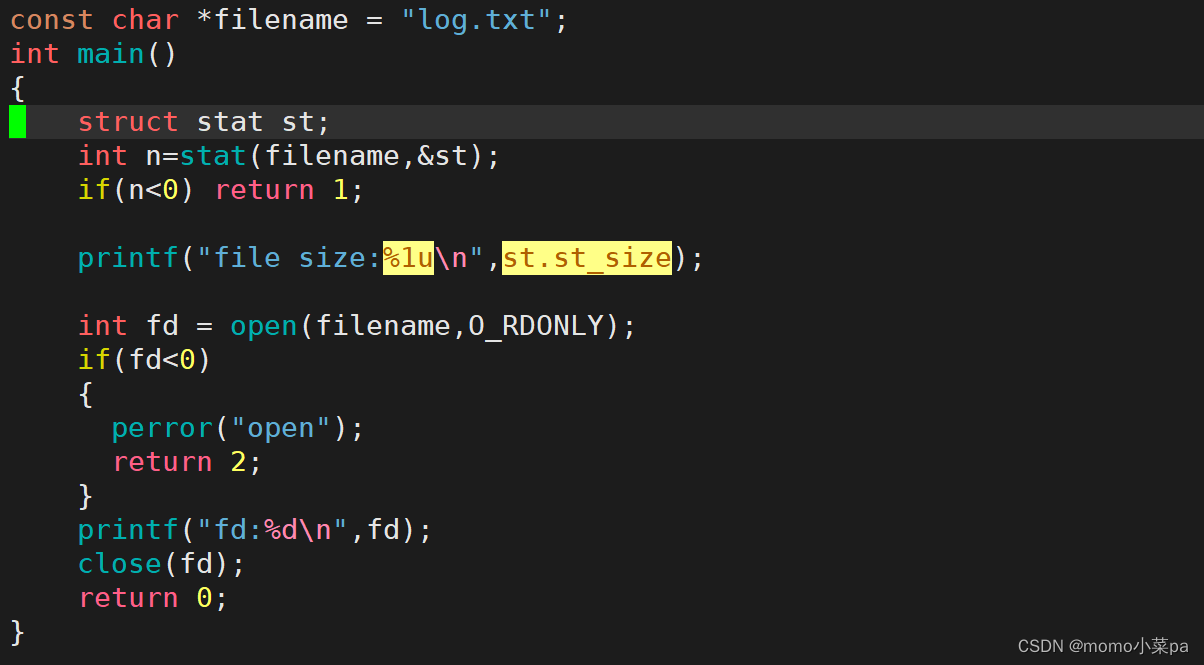
struct stat结构来存储文件的元数据。这个结构包含了许多字段,如文件类型(普通文件、目录、符号链接等)、权限、所有者ID、组ID、大小、时间戳等。具体的字段取决于你的系统和编译器,但你可以查阅sys/stat.h头文件以获取更多详细信息。演示:
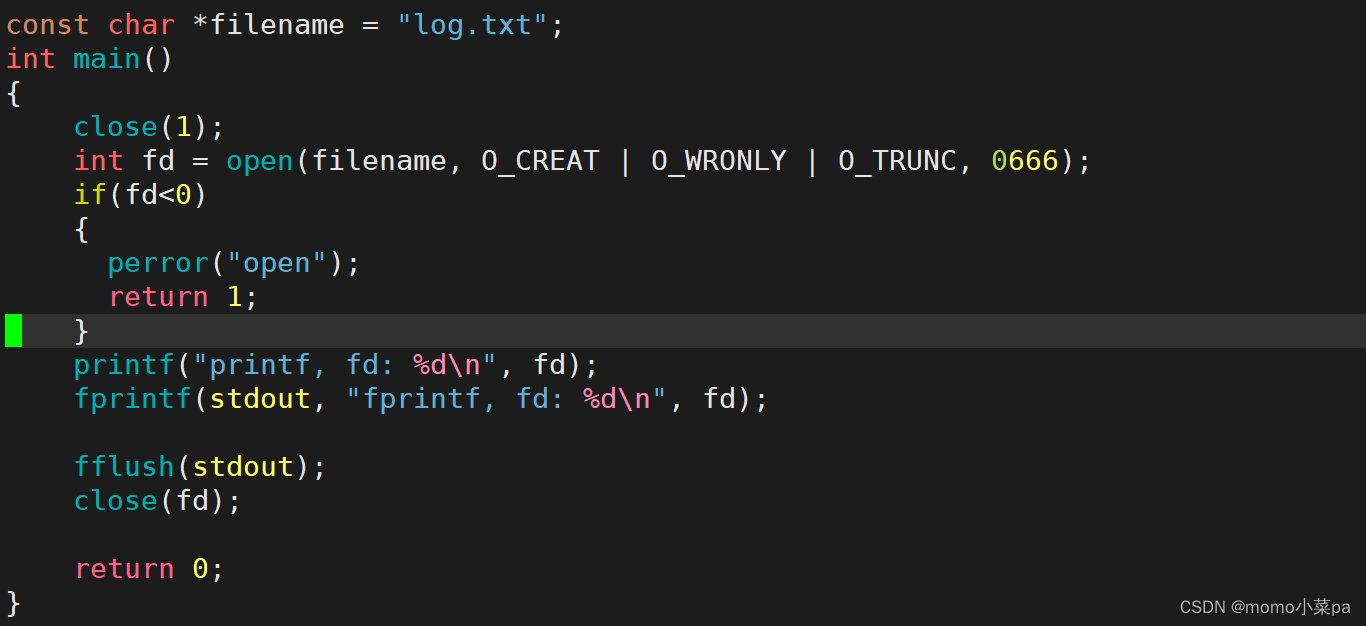
再来看一段代码:
我们打开文件的时候做了一个操作,colse(1)首先关闭了文件描述符
1,我们知道文件描述符1,表示的是显示器文件,而printf&&fprintf都是向显示器上打印的,现在关闭了显示器文件,意味着显示器上不会出现打印的内容。
文件描述符1被关闭了,意味着fd1空了出来,那么log.txt将继承fd1(文件描述符分配规则;查自己的文件描述表,分配最小的没有被使用的fd),那么现在向fd1中写就是在向log.txt中写,所以我们查看到log.txt中的内容就是printf&&fprintf输出的内容,这就是对文件做重定向(重定向的本质:是在内核中改变文件描述符表特定下标的内容,和上层无关!)
在这段代码中:我们还需要注意一点,fflush(stdout)刷新stdout,如果不进行此操作,log.txt中是不会有任何内容的,这是为什么呢?
原因是:在struct FILE*这个结构体中存在语言级别的缓冲区,我们在使用printf&&fprintf时,并不是直接通过文件描述符写入到内核文件缓冲区中,而是先写到语言级别的缓存区中,再由C语言通过文件描述符,刷新到内核文件缓存区当中,此时外设才能看到输出的内容,因此fflush(stdout)此时的工作是将stdout缓冲区中的内容通过文件描述符1,刷新到log.txt内核文件缓存区当中去,这时候log.txt中才能看到内容。如果没有close(fd)这一语句,那么不加刷新也没关系,进程结束之后,会自动通过fd刷新到文件中。

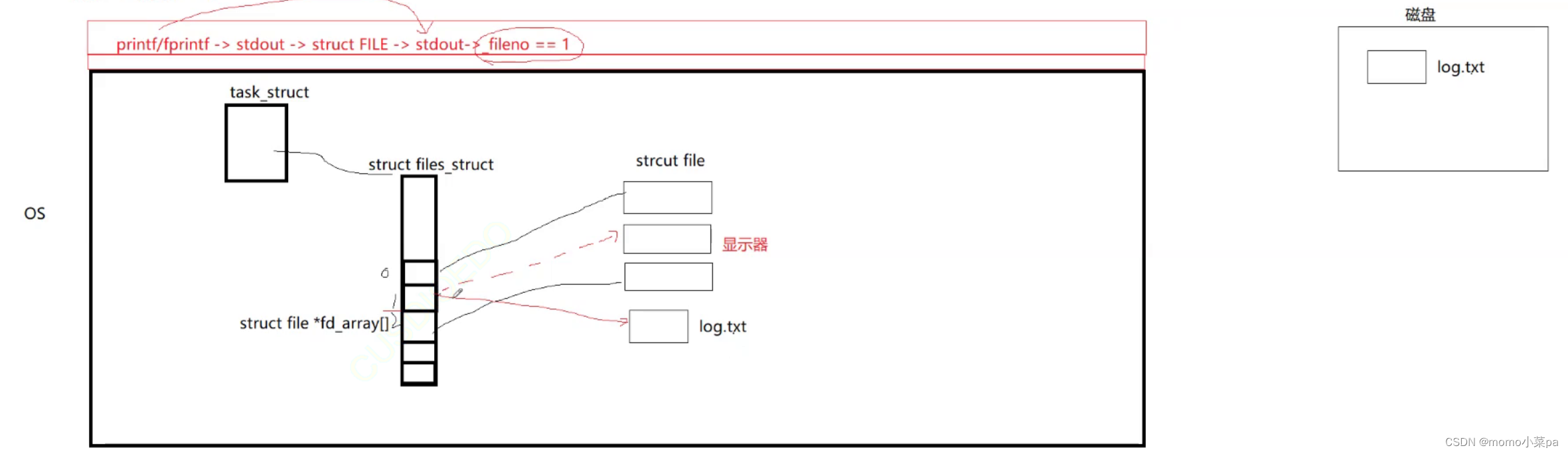
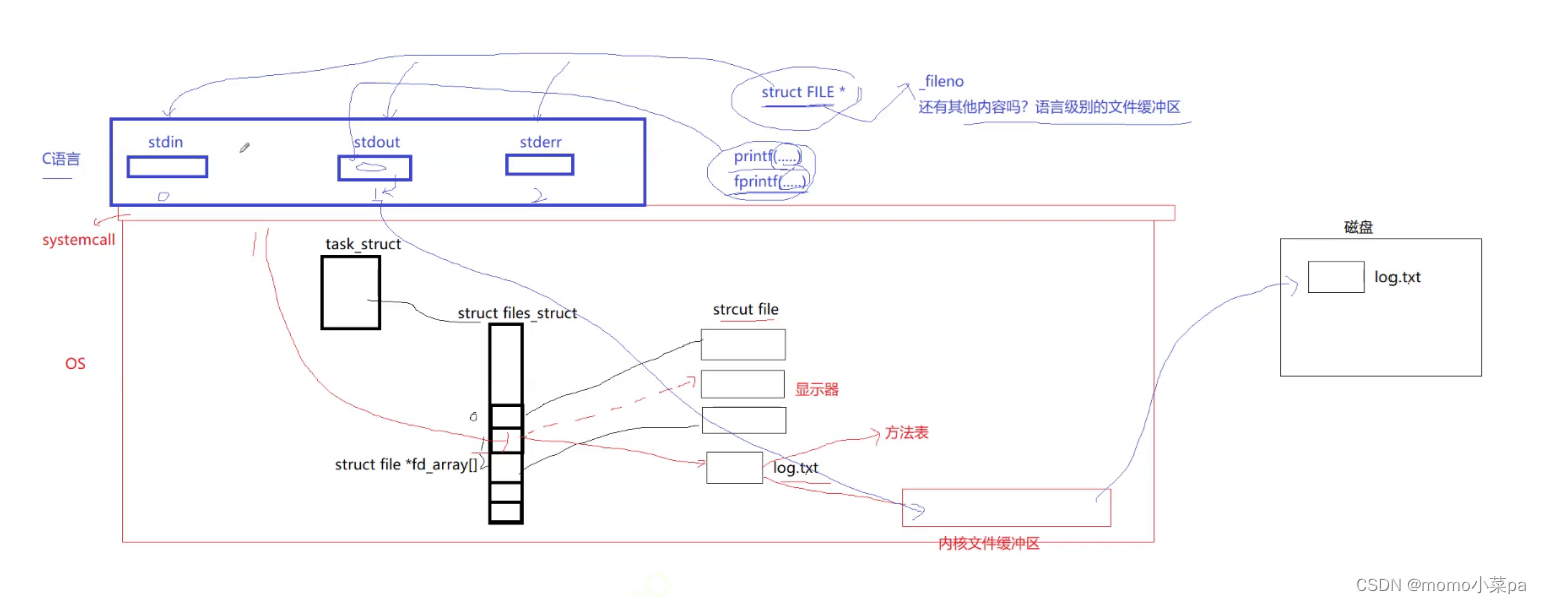
2.理解重定向
先认识一个系统调用接口:dup2
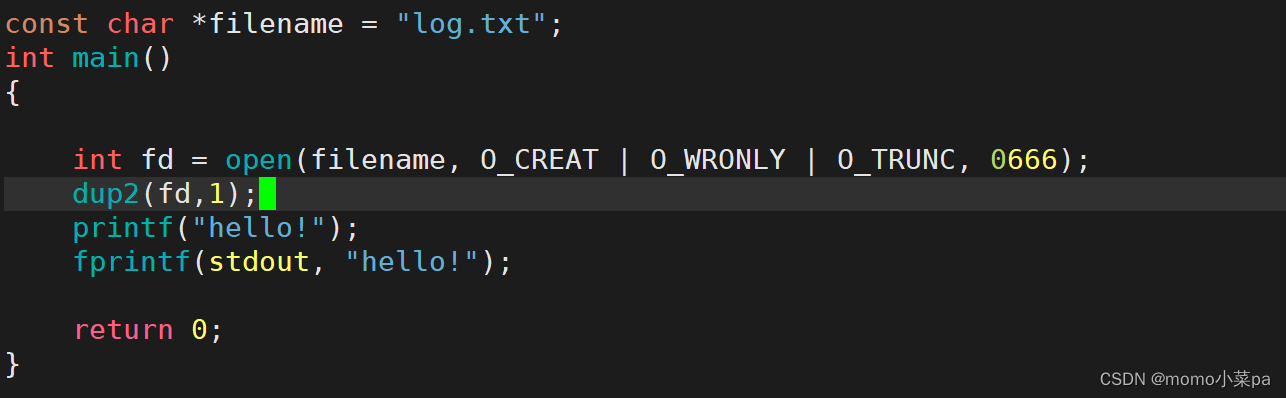
dup2的功能是将一个已存在的文件描述符复制到另一个文件描述符,如果目标文件描述符已经打开,则先将其关闭。(本质是文件描述符下标所对应内容的拷贝)。#include <unistd.h> int dup2(int oldfd, int newfd);1. 标准输出重定向,由显示器打印->log.txt打印(接上面例子,我们使用dup2系统调用接口该如何做呢?)
也就是我们没有关闭fd1,那么新打开的log.txt的fd就是3,我们使用了dup2的效果就是,把fd3的内容拷贝给了fd1,也就是说,让fd1指向了文件log.txt,所以未来向fd1里写入内容,实际上就是向log.txt中写入内容,最终只会留下fd3(oldfd)。(fd1和fd3里的地址一样l)
那么代码就应该这么写:
这样输出到显示器的内容就输出到log.txt了



3.理解缓冲区
在Linux操作系统中,缓冲区是一个非常重要的概念,主要用于提高I/O(输入/输出)操作的效率。以下是关于Linux操作系统中缓冲区的理解:
- 概念:缓冲区是内存中的一块区域,用于临时存放数据。当进程需要向外部设备(如磁盘、网络等)写入数据时,它不会直接将数据写入设备,而是先将数据写入到缓冲区中。同样,当进程从外部设备读取数据时,数据也是先从设备读取到缓冲区,当缓冲区的数据到达某个值的时候,在统一的刷新到进程中。
- 作用:
- 减少对外部设备的直接访问次数,从而降低I/O操作的开销。
- 允许进程进行批量数据传输,从而提高数据传输的效率。
- 通过缓存数据,可以实现对数据的预处理和后处理,如数据压缩、加密等。
- 刷新策略:Linux中的缓冲区有不同的刷新策略,以适应不同的应用场景。
- 无缓冲:数据一写入到缓冲区就立即刷新到外部设备。(eg:1.语言级的缓冲区printf/fprintf,2.系统调用fsync)
- 行缓冲:当在输入或输出中遇到换行符(
\n)时,缓冲区会刷新一次。这种策略常用于与终端设备(如显示器)的交互。- 全缓冲:当缓冲区满时,数据才会被刷新到外部设备。这种策略常用于写入磁盘文件等场景。
- 特殊情况(1.进程退出,自动刷新;2强制刷新)
- 与文件系统的关系:在Linux文件系统中,缓冲区也起着重要的作用。当应用程序读取文件时,内核会将文件数据读入内核空间缓冲区中,然后再将数据从内核空间缓冲区复制到用户空间缓冲区中。同样地,当应用程序向文件写入数据时,数据也是先写入到用户空间缓冲区中,然后再由内核将数据从用户空间缓冲区复制到内核空间缓冲区,并最终写入到磁盘上。
- 缓冲区就在struct FILE*结构体中,每一个文件都有自己的缓冲区(这是在语言层面的)
补充示例
刷新策略发生改变,看下面的两段代码:
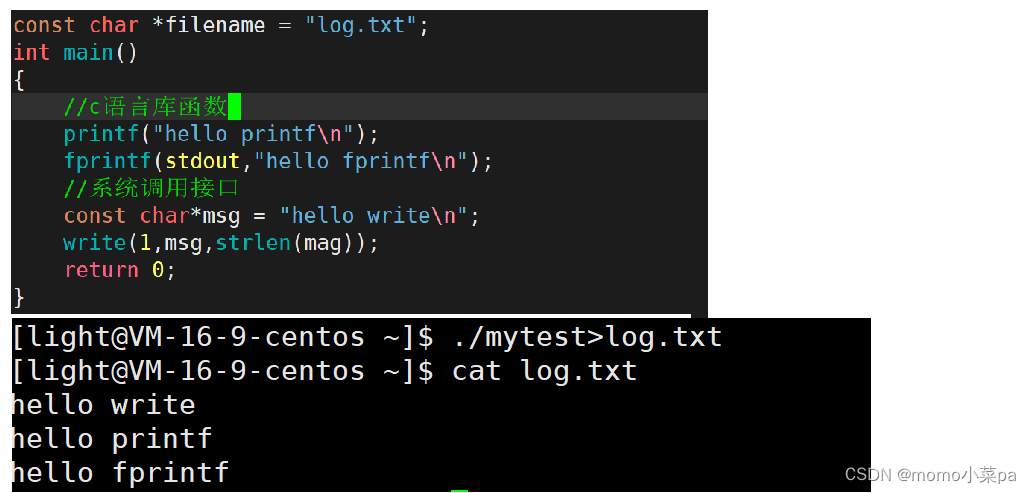
第一段代码及它的运行结果(我们将打印到屏幕的内容重定向到文件中)
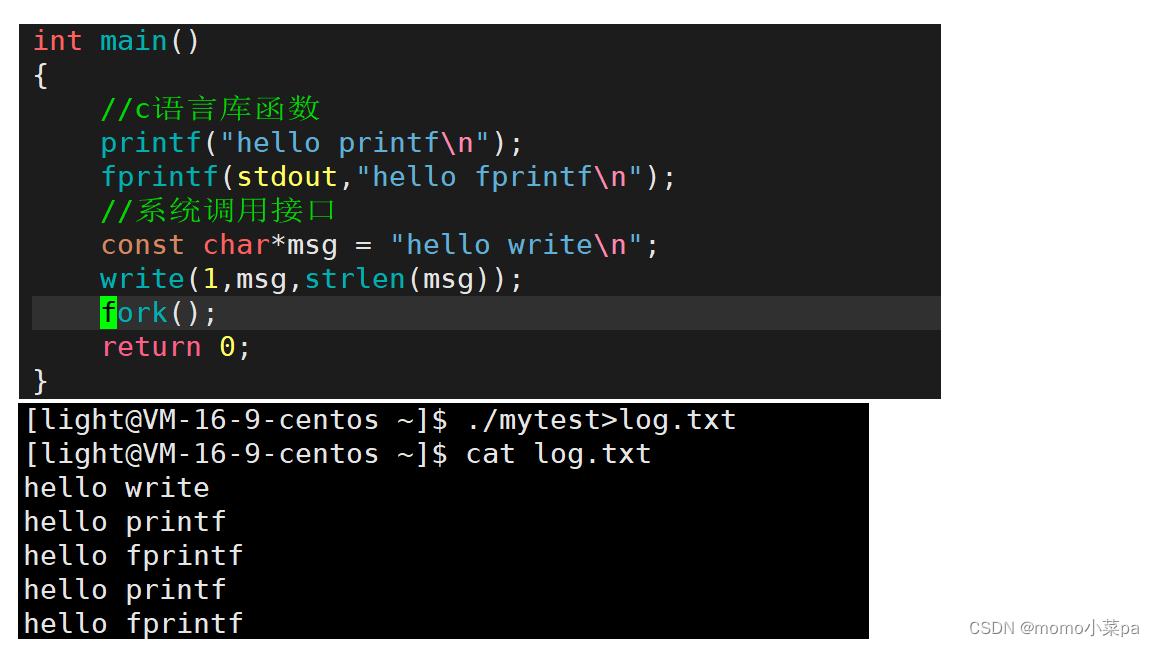
第二段代码及它的运行结果(与第一段代码不同的是,加入了一个fork函数)
问题:为什么加了fork之后,会打印两次内容,fork不是只会继承父进程下面的代码吗?为什么C语言库函数的内容打印了两次,而系统调用的只打印了一次呢?
首先./mytest这个操作是向显示器文件打印,显示器文件的刷新策略是行缓冲,现在转为向普通文件打印,普通文件的刷新策略是全缓冲,由显示器文件转向普通文件打印,这里刷新策略就发生了改变。此时printf/fprintf在执行完之后,缓冲区还没有写满(因为是全缓冲),不做刷新,最后fork的时候就出现了父子进程,fork结束后进程就直接退出了,此时父子进程都要执行刷新,所以就打印了两次内容,而系统调用接口是直接向内核级缓冲区中写的,所以不存在刷新两次的问题了。















 3734
3734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









