






 本文介绍了一种改进的差分进化算法DE-PSO,它结合了粒子群算法的进化机制,通过粒子群差分变异策略和DE/current-rand/1变异策略提升全局搜索和多样性。此外,文章探讨了扰动策略以防止早熟,实验结果显示算法在收敛精度和速度上表现出色。
本文介绍了一种改进的差分进化算法DE-PSO,它结合了粒子群算法的进化机制,通过粒子群差分变异策略和DE/current-rand/1变异策略提升全局搜索和多样性。此外,文章探讨了扰动策略以防止早熟,实验结果显示算法在收敛精度和速度上表现出色。
为进一步提高差分进化算法优化性能,结合粒子群算法进化机制,提出DE-PSO,使用粒子群差分变异策略和DE/current-rand/1变异策略(提高算法全局能力和增加种群多样性),扰动策略(跳出局部,避免早熟)。通过测试函数知算法收敛精度和收敛速度较优。
一.粒子群差分变异策略和DE/current-rand/1变异策略
1.粒子群差分变异策略
a.随机惯性权重
随机惯性权重是为了更好的平衡全局探索和局部开发!
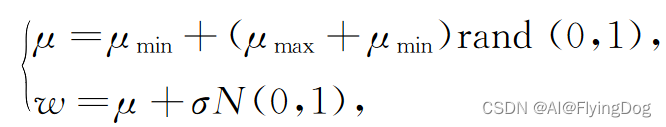
随机惯性权重最小,大值,
权重调和因子,N(0,1)标准正态分布。
b.粒子群差分变异策略
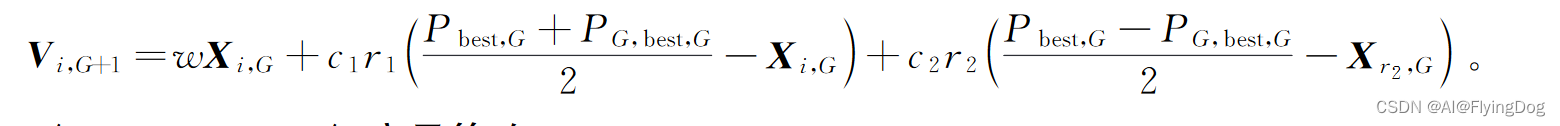
里面用到个体最好值和全局最好值。
2.DE/current-rand/1变异策略
粒子群差分变异策略用到个体最好值和全局最好值,对于单峰函数效果很好(可检验算法局部开发能力),对于多峰函数来说该策略是往当前最优值进化的,一旦当前最优是局部最优算法可能就陷入局部而停滞,为了补偿这个情况,将DE/current-rand/1作为辅助变异算子(增加种群多样性)
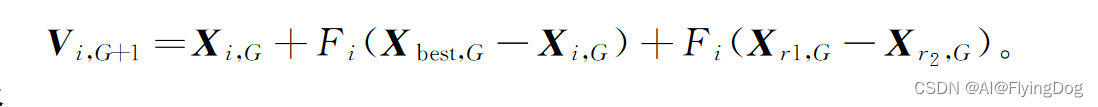
二.扰动策略
为增加种群多样性来避免早熟停滞,加入扰动。
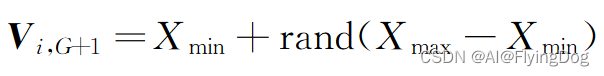
用到个体的分量最大值和分量最小值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









