






蜣螂优化器基础理论
蜣螂优化器
蜣螂优化器是一种启发式全局优化算法,模拟蜣螂(粪甲虫)的滚球、跳舞、觅食、偷窃、繁殖行为。DBO算法兼顾勘探能力与开发能力,收敛快精度高,稳定性强。每种智能优化算法不同点在于迭代过程中种群优化策略,即对种群个体的组合方式,个体如何移动或进化。智能优化算法很多,例如差分进化算法DE、粒子群算法PSO、灰狼算法GWO、蚁群算法ACO、鲸鱼算法WOA,HHO优化器等等及这些算法的各种改进算法。根据没有免费午餐定理可知,没有一种算法能够解决所有的实际问题,所有算法的发掘也尤为重要。DBO算法中蜣螂的每一种行为代表一种更新规则。
有趣的蜣螂
蜣螂快速向后滚动粪球,可以防止与其它蜣螂竞争。滚球行为利用天体线索(阳光,月亮,偏振光)进行导航,准确来说就是利用光源进行直线滚球,若无光完全黑暗,滚球路径是弯曲的;其它自然因素可能使蜣螂滚球路径偏离原方向,例如风速,地面平坦度等;遇见障碍物时可能停止滚动不前进或无法前进,蜣螂可能会到粪球上跳舞(旋转、停顿等)再决定向什么方向运动;蜣螂滚球目的一方面在于产卵繁殖下一代,另一方面为幼虫提供食物;因此粪球对蜣螂很重要。
蜣螂五种行为数学建模
蜣螂滚球行为
蜣螂利用天体线索导航使粪球沿着指定方向直线运动,模拟滚球行为,蜣螂在搜索域沿给定方向移动,考虑太阳光导航,太阳光强度影响蜣螂滚球路径,滚球蜣螂位置更新为:
式中:是当前迭代次数,
是蜣螂当前位置,
是(0,1)间的常数值,
是(0,0.2]间的偏转系数,
是蜣螂上一位置,
是为1或者-1,
是全局最差位置,
是用来模拟光强度变化的。
非常重要,常取0.1,0.3;
为1说明滚球方向没有偏,为-1说明滚球方向偏了,以一定概率将其设为1或-1,
越大说明光越弱(优点1.尽可能勘探整个搜索域,2.减小局部最优可能性),
控制
的值来扩大搜索范围。
概率选择如下:

蜣螂跳舞行为
蜣螂遇障碍物跳舞重新定位获得新路线,舞蹈对于滚球蜣螂来说很重要。模仿舞蹈行为,利用[0,pi]上的正切函数值,蜣螂确定新方向向后滚球,故滚球蜣螂位置更新为
如果=0,pi/2,pi时位置是不更新的。
如何选择自己定,选择好后判断是否更新。
的选择策略如下:

蜣螂繁殖行为
蜣螂将粪球滚到安全地方藏起来,选择产卵点,用边界选择策略模拟母蜣螂产卵区域。
式子中:当前局部最佳位置,t当前迭代次数,Tmax最大迭代次数,Lb,Ub搜索域下上界,
母蜣螂产卵区域下上界。(其实做这一步的目的是产生幼蜣螂,每个母蜣螂每代只产一个幼蜣螂,产卵域位置随
动态变化)。
式中:当前局部最佳位置,
是第t次迭代第i个育球位置信息,
是1xD的随机向量,D是问题维度。
育卵球位置更新策略如下:

蜣螂觅食行为
成虫小蜣螂会爬出来找食物吃,建立好的觅食区引导小蜣螂觅食,第一先定义最佳觅食区边界,如下:
式中:是全局最佳位置,
即为最佳觅食区下上界。
根据最佳觅食区下上界得小蜣螂位置更新公式为:
式中:是第t次迭代第i只小蜣螂位置信息,
是正态分布随机数,
是(0,1]间1xD维的随机向量。
蜣螂偷窃行为
有些蜣螂会偷其它蜣螂的粪球,它们被称为小偷蜣螂,小偷蜣螂位置更新为:
式中:是最佳食物来源--全局最佳位置,
是第t次迭代第i个小偷蜣螂位置,
是1xD的正态分布随机向量,
是一个常数值,
当前局部最佳位置。
DBO算法整体流程

优化问题描述
假设优化问题如下:
式中:n为变量维度,问题是一个球面函数求最小值问题,理论最小值为0,我们取函数维度为30维。球面函数三维图像如下
MATLAB代码实现
下面对算法进行实现对球面函数找最小值,代码如下:
clear all;clc;close all
%粪甲虫优化器参数初始化
np=100;%种群大小
lb=-30;ub=30;w=30;Tmax=500;%变量下界,上界,问题维数,算法最大迭代次数
pjt=0;yz=1e-5;%初始评价次数,目标阈值精度
RDBN_np= 0.2*np; % 滚球蜣螂个数
YDBN_np= 0.2*np; % 幼蜣螂个数
DDBN_np= 0.25*np; % 小蜣螂个数
TDBN_np=0.35*np; % 小偷蜣螂个数
%种群初始化并计算评价值
lb=lb.*ones(1,w);ub=ub.*ones(1,w);
for i=1:np
popx(i,:)=lb+(ub-lb).*rand(1,w);
pjpopx(i,:)=pjia(popx(i,:));
end
pjt=pjt+np;
ppopx=popx;pjppopx=pjpopx;%保存当前种群个体当前位置及评价值副本,将popx视为种群个体下一位置
ppopx1=ppopx;%保存种群个体上一位置
[fmin,BestIndex]=min(pjpopx);%找到当前最优个体信息及评价值
bestpopx=popx(BestIndex,:);%记录当前最优个体
trace(1,:)=fmin;%记录当前最优个体评价值
t=1;tic;
%算法迭代开始
while t<Tmax
[Worsepjpopx,WorseIndex]=max(pjpopx);%找到当前最差个体信息及评价值
Worsepopx=popx(WorseIndex,:);%当前最差个体
%滚球蜣螂位置更新模块,滚球蜣螂没有遇见障碍物会向后滚球,遇障碍物会跳舞重新选择方向滚球
r1=rand;%跳舞或者滚球概率
for i=1:RDBN_np
if r1<0.9%没有遇见障碍物蜣螂滚球,滚球蜣螂位置更新如下
%a选择
r2=rand;%a选择概率
if r2>0.5;a=1;else;a=-1;end
k=0.1;b=0.3;
deltax=abs(ppopx(i,:)-Worsepopx);
%滚球蜣螂位置为
popx(i,:)=ppopx(i,:)+a*k*ppopx1(i,:)+b*deltax;
else%滚球蜣螂遇见障碍物跳舞后更新位置
zeta=randperm(180,1);%随机选择theta,theta在(0,pi]间
%跳舞后滚球蜣螂位置更新为
if zeta==0||zeta==90||zeta==180%此时蜣螂不更新
popx(i,:)=ppopx(i,:);
else
theta=zeta*pi/180;
popx(i,:)=ppopx(i,:)+tan(zeta)*abs(ppopx(i,:)-ppopx1(i,:));
end
end
%对更新后的滚球蜣螂边界条件处理
for j=1:w
if popx(i,j)<lb(j)||popx(i,j)>ub(j)
popx(i,j)=lb(j)+(ub(j)-lb(j))*rand;
end
end
%更新滚球蜣螂评价值信息
pjpopx(i,:)=pjia(popx(i,:));
pjt=pjt+1;
end
%找到滚球蜣螂滚球or跳舞后滚球种群当前局部最佳位置
[Bestp,BestI]=min(pjpopx);
Bestpx=popx(BestI,:);%当前局部最佳位置
%确定母蜣螂产卵区域
R=1-t/Tmax;
lb1=max(Bestpx*(1-R),lb);ub1=min(Bestpx*(1+R),ub);%产卵区域下上界
%幼蜣螂更新
for i=(RDBN_np+1):(RDBN_np+YDBN_np)
b1=rand(1,w);b2=rand(1,w);
popx(i,:)=Bestpx+b1.*(ppopx(i,:)-lb1)+b2.*(ppopx(i,:)-ub1);
for j=1:w%边界条件处理
if popx(i,j)<lb(j)||popx(i,j)>ub(j)
popx(i,j)=lb(j)+(ub(j)-lb(j))*rand;
end
end
pjpopx(i,:)=pjia(popx(i,:));%更新幼蜣螂评价值
pjt=pjt+1;
end
%找到此时最新的全局最佳位置
[Bestp1,BestI]=min(pjpopx);
Bestpx1=popx(BestI,:);%当前局部最佳位置
%确定小蜣螂最佳觅食区域
lb2=max(Bestpx1*(1-R),lb);ub2=min(Bestpx1*(1+R),ub);%小蜣螂最佳觅食区域下上界
%最佳觅食区下上界得小蜣螂位置更新为
for i=(RDBN_np+YDBN_np+1):(RDBN_np+YDBN_np+DDBN_np)
c1=randn;c2=rand(1,w);
popx(i,:)=ppopx(i,:)+c1.*(ppopx(i,:)-lb2)+c2.*(ppopx(i,:)-ub2);
for j=1:w%边界条件处理
if popx(i,j)<lb(j)||popx(i,j)>ub(j)
popx(i,j)=lb(j)+(ub(j)-lb(j))*rand;
end
end
pjpopx(i,:)=pjia(popx(i,:));%更新小蜣螂评价值
pjt=pjt+1;
end
%找到此时最新的局部最佳位置
[Bestp2,BestI]=min(pjpopx);
Bestpx2=popx(BestI,:);%当前局部最佳位置
%小偷蜣螂位置更新
for i=(RDBN_np+YDBN_np+DDBN_np+1):np
s=0.5;g=randn(1,w);
popx(i,:)=bestpopx+s*g.*(abs(ppopx(i,:)-Bestpx2)+abs(ppopx(i,:)-bestpopx));
for j=1:w%边界条件处理
if popx(i,j)<lb(j)||popx(i,j)>ub(j)
popx(i,j)=lb(j)+(ub(j)-lb(j))*rand;
end
end
pjpopx(i,:)=pjia(popx(i,:));%更新小偷蜣螂评价值
pjt=pjt+1;
end
%更新种群个体最优和全局最优
ppopx1=ppopx;%更新种群个体上一位置
for i=1:np%更新种群当前位置
if pjpopx(i)<pjppopx(i)
pjppopx(i)=pjpopx(i);
ppopx(i,:)=popx(i,:);
end
if pjppopx(i)<fmin
bestpopx=ppopx(i,:);
fmin=pjppopx(i);
end
end
trace(t+1)=fmin;
% if trace(t+1)<yz;break;end
t=t+1;
end
toc
plot(trace,'Color','r','LineWidth',2)
title('函数优化求最值');xlabel('迭代次数');ylabel('适应度变化');
grid on;box on;legend('DBO')
disp(['运行时间: ', num2str(toc)]);
disp(['最大评价次数: ', num2str(pjt)]);
disp(['全局最佳解: ', num2str(bestpopx)]);
disp(['全局最佳值: ', num2str(fmin)]);
%优化问题函数
function y=pjia(x)
y=sum(x.^2);%球面函数
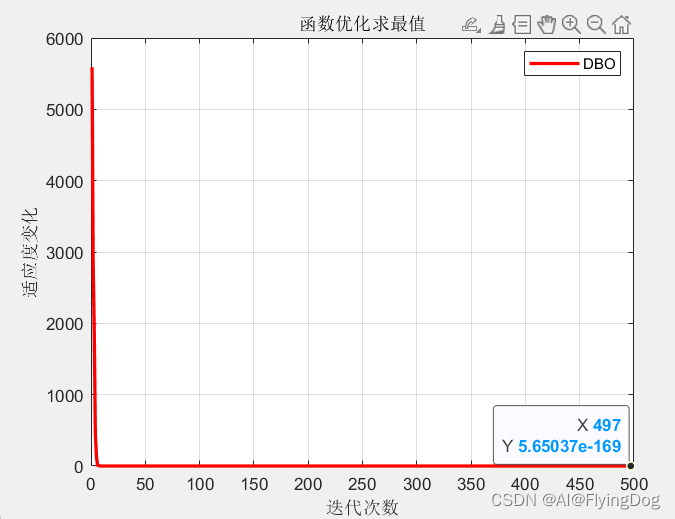
end运行结果如下图,整体结果还不错;
文献来源
部分理论来源于网络,如有侵权请联系删除!


















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









