










最近受到万点暴击,由于公司业务出现问题,工作任务没那么繁重,有时间摸索selenium+python自动化测试,结合网上查到的资料自己编写出适合web自动化测试的框架,由于本人也是刚刚开始学习python,这套自动化框架目前已经基本完成了所以总结下编写的得失,便于以后回顾温习,有许多不足的的地方,也遇到了各种奇葩问题,希望大神们多多指教。
首先我们要了解什么是自动化测试,简单的说编写代码、脚本,让软件自动运行,发现缺陷,代替部分的手工测试。了解了自动化测试后,我们要清楚一个框架需要分那些模块:
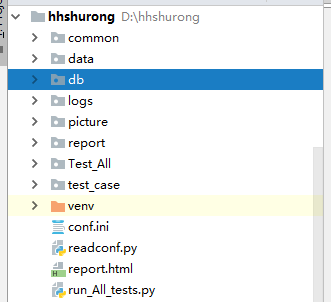
上图的框架适合大多数的自动化测试,比如web UI 、接口自动化测试都可以采用,如大佬有好的方法请多多指教,简单说明下每个模块:
common:存放一些共通的方法
data:存放一些文件信息
logs:存放程序中写入的日志信息
picture:存放程序中截图文件信息
report:存放测试报告
test_case:存放编写具体的测试用例
conf.ini、readconf.py:存放编写的配置信息
下面就具体介绍每个模块的内容:conf.ini主要存放一些不会轻易改变的信息,编写的代码如下:
-
[DATABASE] -
host = 127.0.0.1 -
username = root -
password = root -
port = 3306 -
database = cai_test -
[HTTP] -
# 接口的url -
baseurl = http://xx.xxxx.xx -
port = 8080 -
timeout = 1.0 -
readconf.py文件主要用于读取conf.ini中的数据信息 -
# *_*coding:utf-8 *_* -
__author__ = "Test Lu" -
import os,codecs -
import configparser -
prodir = os.path.dirname(os.path.abspath(__file__)) -
conf_prodir = os.path.join(prodir,'conf.ini') -
class Read_conf(): -
def __init__(self): -
with open(conf_prodir) as fd: -
data = fd.read() -
#清空文件信息 -
if data[:3] ==codecs.BOM_UTF8: -
data = data[3:] -
file = codecs.open(conf_prodir,'w') -
file.write(data) -
file.close() -
self.cf = configparser.ConfigParser() -
self.cf.read(conf_prodir) -
def get_http(self,name): -
value = self.cf.get("HTTP",name) -
return value -
def get_db(self,name): -
return self.cf.get("DATABASE",name)
这里需要注意,python3.0以上版本与python2.7版本import configparser的方法有一些区别读取一些配置文集就介绍完了,下面就说说common包下的公共文件
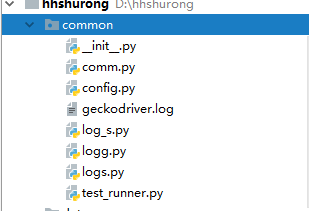
现在就从上往下结束吧!common主要是封装的一些定位元素的方法:
-
# *_*coding:utf-8 *_* -
__author__ = "Test Lu" -
from selenium import webdriver -
import time,os -
import common.config -
# from common.logs import MyLog -
project_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) -
class Comm(object): -
def __init__(self,driver): -
self.driver = driver -
# self.driver = webdriver.Firefox() -
self.driver = webdriver.Chrome() -
self.driver.maximize_window() -
def open_url(self,url): -
self.driver.get(url) -
self.driver.implicitly_wait(30) -
# selenium 定位方法 -
def locate_element(self,loatetype,value): -
if (loatetype == 'id'): -
el = self.driver.find_element_by_id(value) -
if (loatetype == 'name'): -
el = self.driver.find_element_by_name(value) -
if (loatetype == 'class_name'): -
el = self.driver.find_element_by_class_name(value) -
if (loatetype == 'tag_name'): -
el = self.driver.find_elements_by_tag_name(value) -
if (loatetype == 'link'): -
el = self.driver.find_element_by_link_text(value) -
if (loatetype == 'css'): -
el = self.driver.find_element_by_css_selector(value) -
if (loatetype == 'partial_link'): -
el = self.driver.find_element_by_partial_link_text(value) -
if (loatetype == 'xpath'): -
el = self.driver.find_element_by_xpath(value) -
return el if el else None -
# selenium 点击 -
def click(self,loatetype,value): -
self.locate_element(loatetype,value).click() -
#selenium 输入 -
def input_data(self,loatetype,value,data): -
self.locate_element(loatetype,value).send_keys(data) -
#获取定位到的指定元素 -
def get_text(self, loatetype, value): -
return self.locate_element(loatetype, value).text -
# 获取标签属性 -
def get_attr(self, loatetype, value, attr): -
return self.locate_element(loatetype, value).get_attribute(attr) -
# 页面截图 -
def sc_shot(self,id): -
for filename in os.listdir(os.path.dirname(os.getcwd())) : -
if filename == 'picture': -
break -
else: -
os.mkdir(os.path.dirname(os.getcwd()) + '/picture/') -
photo = self.driver.get_screenshot_as_file(project_dir + '/picture/' -
+ str(id) + str('_') + time.strftime("%Y-%m-%d-%H-%M-%S") + '.png') -
return photo -
def __del__(self): -
time.sleep(2) -
self.driver.close() -
self.driver.quit()
下面介绍下,config文件主要用于读取文件中的信息:
-
import os,xlrd -
from common.logs import MyLog -
from xml.etree import ElementTree as ElementTree -
mylogger = MyLog.get_log() -
project_dir = os.path.dirname(os.getcwd()) -
def user_Add(): -
'''excel文件中读取用户登录信息''' -
with xlrd.open_workbook(project_dir+'/data/test_data.xlsx') as files: -
table_user = files.sheet_by_name('userdata') -
try: -
username = str(int(table_user.cell(1,0).value)) -
except: -
username = str(table_user.cell(1,0).value) -
try: -
passwd = str(int(table_user.cell(1,1).value)) -
except: -
passwd = str(table_user.cell(1,1).value) -
try: -
check = str(int(table_user.cell(1, 2).value)) -
except Exception: -
check = str(table_user.cell(1, 2).value) -
table_url = files.sheet_by_name('base_url') -
base_url = str(table_url.cell(1,0).value) -
return (username,passwd,base_url,check) -
#从xml文件中读取信息,定义全局一个字典来存取xml读出的信息 -
database={} -
def set_read_xml(): -
sql_path = os.path.join(project_dir,'data','SQL.xml') -
data =ElementTree.parse(sql_path) -
for db in data.findall('database'): -
name = db.get('name') -
table = {} -
for tb in db.getchildren(): -
table_name = tb.get("name") -
sql = {} -
for data in tb.getchildren(): -
sql_id = data.get("id") -
sql[sql_id] = data.text -
table[table_name] = sql -
database[name] = table -
mylogger.info("读取的xml文件的信息%s" %database) -
def get_sql_sen(database_name,table_name,sql_id): -
set_read_xml() -
db = database.get(database_name).get(table_name) -
if db.get(sql_id): -
sql = db.get(sql_id).strip() -
mylogger.info("返回sql语句信息%s" % sql) -
return sql -
else: -
mylogger.info("查下的信息为空,传递的参数有误!数据库名称:【%s】,表信息【%s】,查询的id【%s】" -
%(database_name,table_name,sql_id))
接着介绍最简单的日志logs.py模块:
-
# logging模块支持我们自定义封装一个新日志类 -
import logging,time -
import os.path -
class Logger(object): -
def __init__(self, logger,cases="./"): -
self.logger = logging.getLogger(logger) -
self.logger.setLevel(logging.DEBUG) -
self.cases = cases -
# 创建一个handler,用于写入日志文件 -
for filename in os.listdir(os.path.dirname(os.getcwd())): -
if filename == "logs": -
break -
else: -
os.mkdir(os.path.dirname(os.getcwd())+'/logs') -
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time())) -
log_path = os.path.dirname(os.getcwd()) + '/logs/' -
log_name = log_path + rq + '.log' # 文件名 -
# 将日志写入磁盘 -
fh = logging.FileHandler(log_name) -
fh.setLevel(logging.INFO) -
# 创建一个handler,用于输出到控制台 -
ch = logging.StreamHandler() -
ch.setLevel(logging.INFO) -
# 定义handler的输出格式 -
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') -
fh.setFormatter(formatter) -
ch.setFormatter(formatter) -
# 给logger添加handler -
self.logger.addHandler(fh) -
self.logger.addHandler(ch) -
def getlog(self): -
return self.logger
common模块最后一个是test_runner.py这个方法主要是用来执行全部的测试用例
-
import time,HTMLTestRunner -
import unittest -
from common.config import * -
project_dir = os.path.abspath(os.path.join(os.path.dirname(__file__),os.pardir)) -
class TestRunner(object): -
''' 执行测试用例 ''' -
def __init__(self, cases="../",title="Auto Test Report",description="Test case execution"): -
self.cases = cases -
self.title = title -
self.des = description -
def run(self): -
for filename in os.listdir(project_dir): -
if filename == "report": -
break -
else: -
os.mkdir(project_dir+'/report') -
# fp = open(project_dir+"/report/" + "report.html", 'wb') -
now = time.strftime("%Y-%m-%d_%H_%M_%S") -
# fp = open(project_dir+"/report/"+"result.html", 'wb') -
fp = open(project_dir+"/report/"+ now +"result.html", 'wb') -
tests = unittest.defaultTestLoader.discover(self.cases,pattern='test*.py',top_level_dir=None) -
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=self.title, description=self.des) -
runner.run(tests) -
fp.close()
以上就是common公共模块所有的模块,简单说下在写这些公共模块时,出现了各种问题,特别是读取xml文件的,唉!对于一个python的小白真是心酸啊!接着说下db模块的内容,db模块主要是读取sql语句以及返回对应的值!
-
import pymysql -
import readconf -
import common.config as conf -
readconf_conf = readconf.Read_conf() -
host = readconf_conf.get_db("host") -
username = readconf_conf.get_db("username") -
password = readconf_conf.get_db("password") -
port = readconf_conf.get_db("port") -
database = readconf_conf.get_db("database") -
config_db = { -
'host': str(host), -
'user': username, -
'password': password, -
'port': int(port), -
'db': database -
} -
class Mysql_DB(): -
def __init__(self): -
'''初始化数据库''' -
self.db = None -
self.cursor = None -
def connect_db(self): -
'''创建连接数据库''' -
try: -
self.db = pymysql.connect(**config_db) -
#创建游标位置 -
self.cursor = self.db.cursor() -
# print("链接数据库成功") -
conf.mylogger.info("链接IP为%s的%s数据库成功" %(host,database)) -
except ConnectionError as ex: -
conf.mylogger.error(ex) -
def get_sql_result(self,sql,params,state): -
self.connect_db() -
try: -
self.cursor.execute(sql, params) -
self.db.commit() -
# return self.cursor -
except ConnectionError as ex: -
self.db.rollback() -
if state==0: -
return self.cursor.fetchone() -
else: -
return self.cursor.fetchall() -
def close_db(self): -
print("关闭数据库") -
conf.mylogger.info("关闭数据库") -
self.db.close()
刚开始写db模块是一直对字典模块的信息怎样传递到数据链接的模块,进过网上查询好些资料才彻底解决,对自己来说也是一种进步,哈哈,下面说下自己踩的坑,帮助自己以后学习**config_db把字典变成关键字参数传递,下面举例说明下:如果kwargs={'a':1,'b':2,'c':3}那么**kwargs这个等价为test(a=1,b=2,c=3)是不是很简单!哈哈 以上就是框架的主要模块,其他的模块每个项目与每个系统都不一样,在这里就是列举出来了,因为就算写出来大家也不能复用,下面就给大家看看小白还有哪些模块
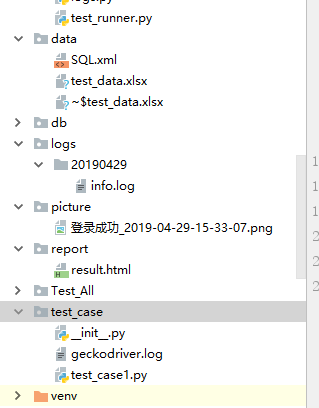
看下了下data模块下的xml模块大家可能用的到,就给大家贴出来吧!因为ui测试主要就用到select与delete语句,所以也没有写多么复杂的sql语句
-
<?xml version="1.0" encoding="utf-8" ?> -
<data> -
<database name="database_member"> -
<table name="table_member"> -
<sql id="select_member"> -
select * from user where real_name=%s -
</sql> -
<sql id="select_member_one"> -
select mobile from user where mobile=%s -
</sql> -
<sql id="delete_member"> -
delete from user where mobile=%s -
</sql> -
<sql id="insert_member"> -
insert into user(id) value(%s) -
</sql> -
<sql id="update_member"> -
uodate user set real_name = %s where uuid=%s -
</sql> -
</table> -
</database> -
</data>
下面介绍下其他模块的内容:test_data.xlsx文件主要是存放一些用户信息,以及url信息,这样修改用户信息与url信息就不要修改代码方便以后操作!logs是在代码运行时候产生的日志信息,picture是存放图片信息,report存放输入的报告信息, test_case是编写用户的模块需要所有的用例名称都要以test开头来命名哦,这是因为unittest在进行测试时会自动匹配test_case文件夹下面所有test开头的.py文件
各大互联网公司的接连裁员,政策限制的行业接连消失,让今年的求职雪上加霜,想躺平却没有资本,还有人说软件测试岗位饱和了,对此很多求职者深信不疑,因为投出去的简历回复的越来越少了。
另一面企业招人真的变得容易了吗?有企业HR吐槽,简历确实比以前多了好几倍,其实是变相的增加了招聘难度,以前是从10份中找一个合适的,现在是从100份中找一个合适的,合适的依然那么少!
问题出在哪了呢?
-
简历很多但是大部分都是初级水平;
-
想找一个全栈自动化测试很难有满足要求的;
-
要求薪水很高,实际能力却达不到。


传统手工测试模式
已成为过去式
测试行业发展到现阶段,目前测试从业者已达成共识的是:传统的手工测试模式已成为过去式!
测试行业目前从业门槛在不断提高,几乎所有测试岗都要求懂代码、掌握自动化测试技术。如果在简历里只写功能测试经验,是很难通过简历筛选的,所以,测试求职者在写简历时都会加上一些高端技能的关键字,比如自动化、appium、接口自动化、测试开发...
这样做,虽然过得了简历关却过不了面试关:
-
自动化测试中,如何解决Case依赖?
-
你们公司业务中,自动化和手工分别占比多少?分别用来做什么业务?
-
appium是如何让Case和手机进行通信的?
-
接口自动化中加解密如何处理?
几个问题下来就原形毕露。如果没有真的做过项目,是一个问题也回答不出来,只会被问的哑口无言。美化简历只是解决了表象问题,通过面试的根本,是真正掌握了自动化实战技能。

自动化测试是
新一代“Office”技能
那么,掌握了自动化能达到什么样的薪资呢?
打开招聘网站,你就会发现很多高薪职位在招聘JD中,纷纷表示“会自动化测试优先”!对于2年以上经验的自动化测试工程师年薪为18万-50万,远高于同等工作年限的功能测试。
同时腾讯、阿里、头条等大型互联网企业更是大量使用自动化,自动化测试正逐渐成为未来10年,测试工程师的新一代“Office”技能。
👇👇👇

这么高薪!谁看了不心动

很多测试同学虽然也意识到自动化的重要性。但由于技术基础薄弱,缺乏系统性学习和过来人的指点,又缺少全流程的实战演练环境,很难在短时间内自学成才达到企业的用人要求。还有不少同学卡在编程语言/基础自动化测试技术这一关,更不用说掌握高级自动化实战思维和经验并灵活应用了。
自动化测试学习建议
我的自动化测试之路,一路走来都离不每个阶段的计划,因为自己喜欢规划和总结,所以,我和朋友特意花了一段时间整理编写了下面的《自动化测试工程师学习路线》,也整理了不少【网盘资源】,需要的朋友可以文末免费获取网盘链接。希望会给你带来帮助和方向。
一、先学习一门编程语言,建议python

二、Python自动化测试框架应用

三、自动化测试篇 - Web UI 自动化

四、自动化测试篇 - 移动端UI 自动化

五、自动化测试篇 - 接口自动化测试

六、自动化测试篇 - 持续集成Git、jenkins、Docker

七、自动化测试篇 - 性能测试LoadRunner、jmeter、app性能

八、自动化测试篇 - WEB安全测试、渗透测试、漏洞扫描

九、自动化测试篇 - RobotFramework、AirTest

10、测试开发篇-自动化测试平台开发

11、互联网高薪测试拓展知识、Redis、MongoDB、Nginx集群实战
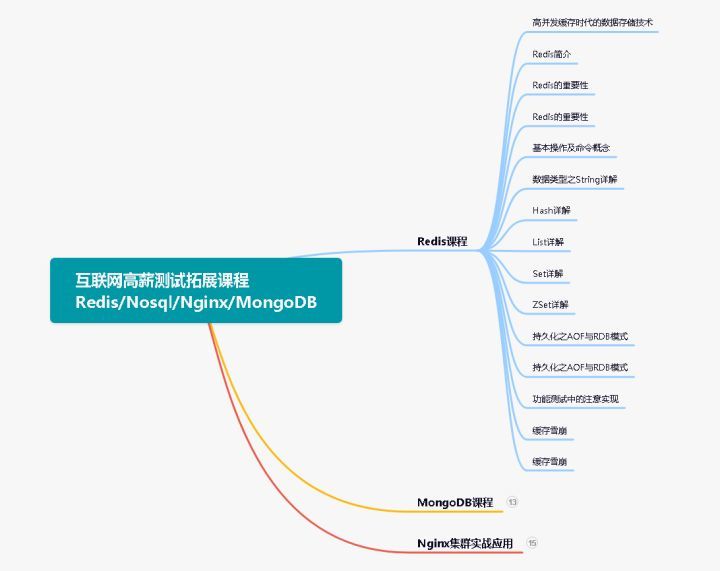
上面就是我为大家整理出来的一自动化测试工程师发展方向知识架构体系图。希望大家能照着这个体系在3-4个月完成这样一个体系的构建。可以说,这个过程会让你痛不欲生,但只要你熬过去了。以后的生活就轻松很多。正所谓万事开头难,只要迈出了第一步,你就已经成功了一半,等到完成之后再回顾这一段路程的时候,你肯定会感慨良多。
送给大家一句话:
让自己变得更强:想一想,如果你想在测试这个行业一直做下去,你的经验和测试技术是远远不够的,你需要进阶,你需要丰富你的技术栈!还等什么!
最后我邀请你进入我们的【软件测试学习交流群:455787643】, 大家可以一起探讨交流软件测试,共同学习软件测试技术、面试等软件测试方方面面,还会有免费直播课,收获更多测试技巧,我们一起进阶Python自动化测试/测试开发,走向高薪之路
作为一个软件测试的过来人,我想尽自己最大的努力,帮助每一个伙伴都能顺利找到工作。所以我整理了下面这份资源,现在免费分享给大家,有需要的小伙伴可以关注【公众号:程序员雨果】自提!

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









