







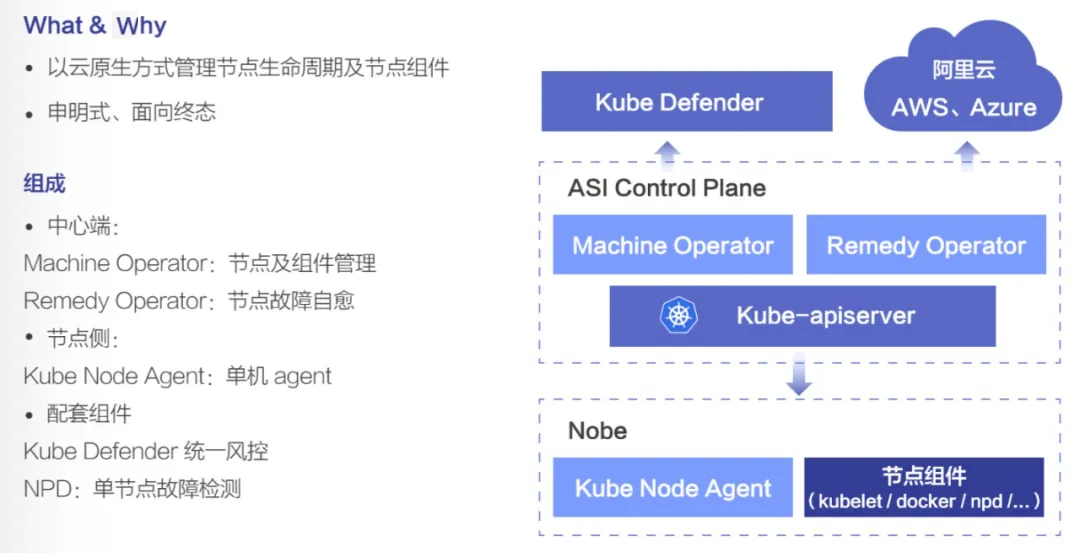
KubeNode,是阿里巴巴自研的基于云原生方式来管理和运维节点的底座项目,相比于传统的过程式的运维手段,KubeNode 通过 K8s 扩展 CRD 以及对应的一组 Operator,能提供完整的节点生命周期和节点组件生命周期管理,通过申明式、面向终态的方式,把节点及节点组件的管理变得跟管理 K8s 中的一个应用一样简单,并实现节点的高度一致性以及自愈修复的能力。
上图右侧是 KubeNode 一个简化的架构,整体是由这几个部分组成的:
中心端有 Machine Operator 负责节点和节点组件管理,Remedy Operator 负责节点的故障自愈修复。节点侧有 Kube Node Agent,这个单机 agent 组件负责 watch 中心 Machine Operator、Remedy Operator 生成的 CRD 对象实例,并执行相应的操作,像节点组件的安装、故障自愈任务的执行等。
配合着 KubeNode,阿里巴巴还使用 NPD 进行单机的故障检测,以及对接 Kube Defender (阿里自研组件) 进行统一风控。当然社区版本的 NPD 提供的故障检测项是比较有限的,阿里巴巴在社区的基础上进行了扩展,结合阿里巴巴多年节点、容器运维的实践,加入了很多节点的故障检测项,大大丰富了单机故障检测的能力。
-
github.com / kube-node:不相关,该项目 2018 年初已停止。
-
ClusterAPI:KubeNode 可以作为 ClusterAPI 节点终态的补充。
功能对比:
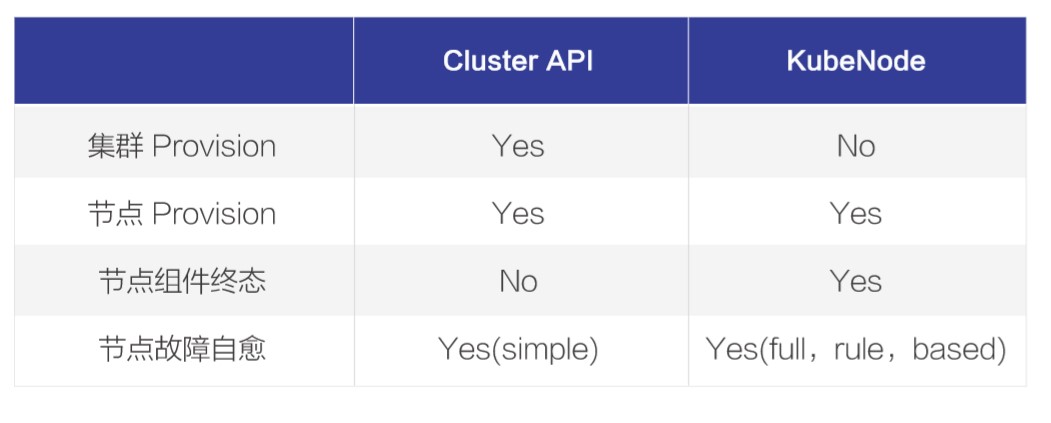
这里解释下阿里巴巴自研的 KubeNode 项目跟社区项目的关系。大家看到 kube-node 这个名字的时候,可能会觉得有点似曾相识,在 github 上是有一个同名的项目 github.com/kube-node,但其实这个项目早在 2018 年初的时候就已经停止了,所以只是名字相同,两者并没有关系。
另外社区的 ClusterAPI 是一个创建并管理 K8s 集群和节点的项目,这里对比了两个项目的关系:
-
集群创建:ClusterAPI 负责集群的创建,KubeNode 不提供此功能。
-
节点创建:ClusterAPI 和 KubeNode 都可以创建节点。
-
节点组件管理和终态维持:ClusterAPI 没有提供相应的功能,KubeNode 可以管理节点组件并保持终态。
-
节点故障自愈:ClusterAPI 主要提供基于节点健康状态重建节点的自愈能力;KubeNode 提供了更丰富的节点组件自愈功能,能对节点上的各种软硬件故障进行自愈修复。
总的来说,KubeNode 可以和 ClusterAPI 一起配合工作,是对 ClusterAPI 的一个很好补充。
这里提到的节点组件,是指运行在节点上的 kubelet,Docker 的软件,阿里内部使用 Pouch 作为我们的容器运行时。除了 kubelet,Pouch 这些调度必须的组件外,还有用于分布式容器存储、监控采集、安全容器、故障检测等总共十多个组件。
通常安装升级 kubelet,Docker 是通过类似 Ansible 等面向过程的一次性动作来完成的。在长时间运行过程中,软件版本被意外修改或是碰到 bug 不能工作的问题是很常见的,同时这些组件在阿里巴巴的迭代速度非常快,往往一两周就需要发布推平一个版本。为了满足组件快速迭代又能安全升级、版本一致的需求,阿里巴巴自研了 KubeNode,通过将节点以及节点组件通过 K8s CRD 的方式进行描述,并进行面向终态的管理,从而确保版本一致性,配置一致性以及运行态正确性。
2. KubeNode - Machine Operator

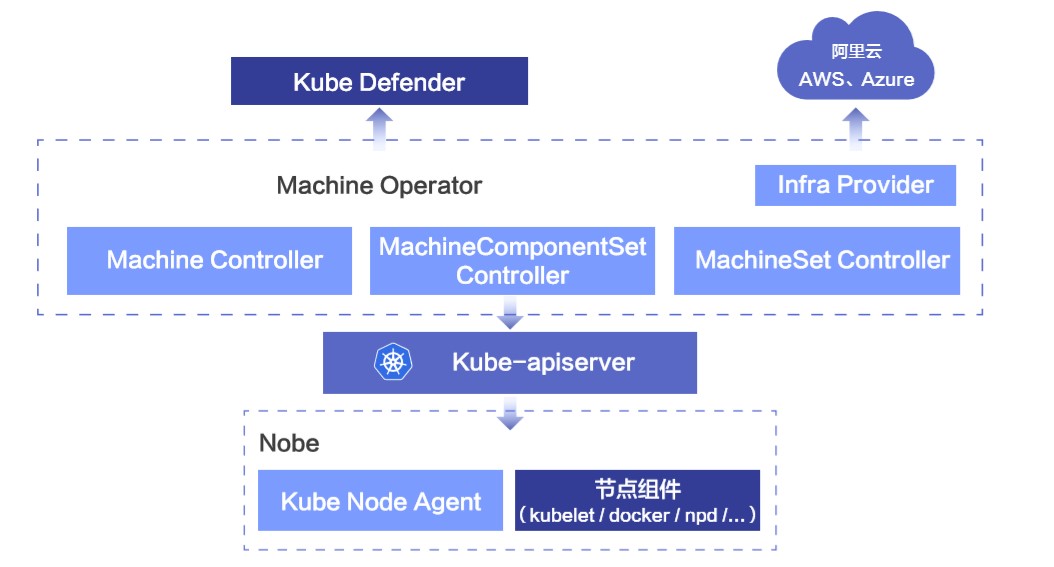
上图是 Machine Operator 的架构,一个标准的 Operator 设计:扩展的一组 CRD 再加上中心的控制器。
CRD 定义包括:跟节点相关的 Machine、MachineSet,以及跟节点组件相关的 MachineComponent、MachineComponentSet。
中心端的控制器包括:Machine Controller、MachineSet Controller、MachineComponentSet Controller,分别用来控制节点的创建、导入,节点组件的安装、升级。
Infra Provider 具有可扩展性,可以对接不同的云厂商,目前只对接了阿里云,但是也可通过实现相应的 Provider 实现对接 AWS、Azure 等不同的云厂商。
单机上的 KubeNode 负责 watch CRD 资源,当发现有新的对象实例时,则进行节点组件的安装升级,定期检查各个组件是否运行正常,并上报组件的运行状态。
1)Use Case:节点导入
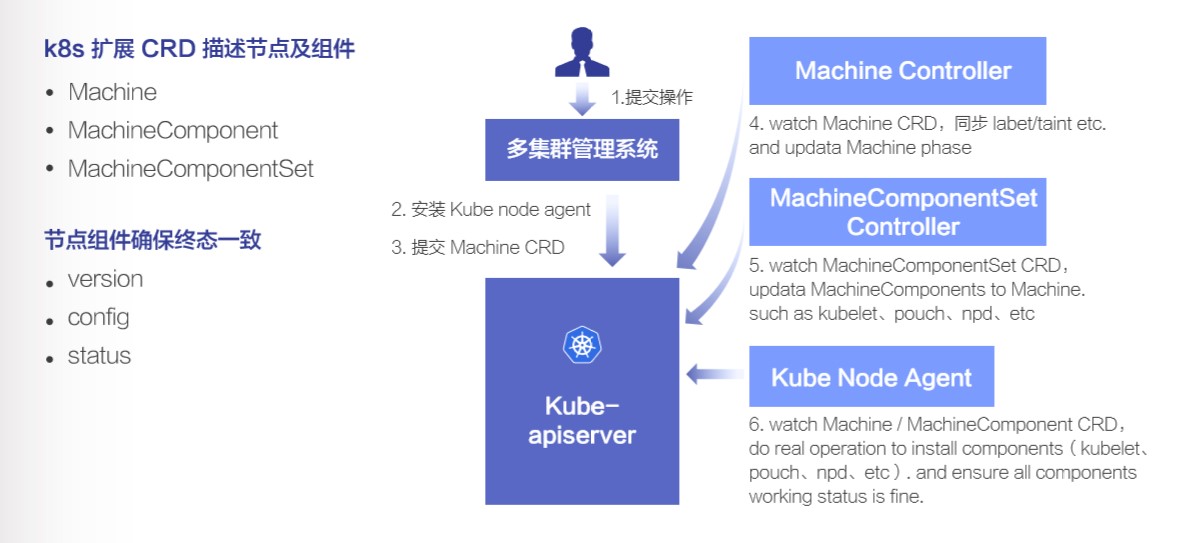
下面分享基于 KubeNode 对已有节点的导入过程。
首先用户会在我们的多集群管理系统中提交一个已有节点的导入操作,接下来系统先下发证书,并安装 KubeNode Agent,等 agent 正常运行并启动之后,第3步会提交 Machine CRD,接下来 Machine Controller 会修改状态为导入 phase,并等 Node ready 之后从 Machine 上同步 label / taint 到 Node。第 5 步是 MachineComponentSet, 根据 Machine 的信息确定要安装的节点组件,并同步到 Machine 上。最后 Kube Node Agent 会 watch 到 Machine、MachineComponent 的信息,完成节点组件的安装,并等所有组件运行正常后,节点导入操作完成。整个过程跟用户提交一个 Deployment 并最终启动一个业务 Pod 是类似的。
节点组件的终态一致主要包含了软件版本、软件配置和运行状态的正确、一致。
2)Use Case:组件升级
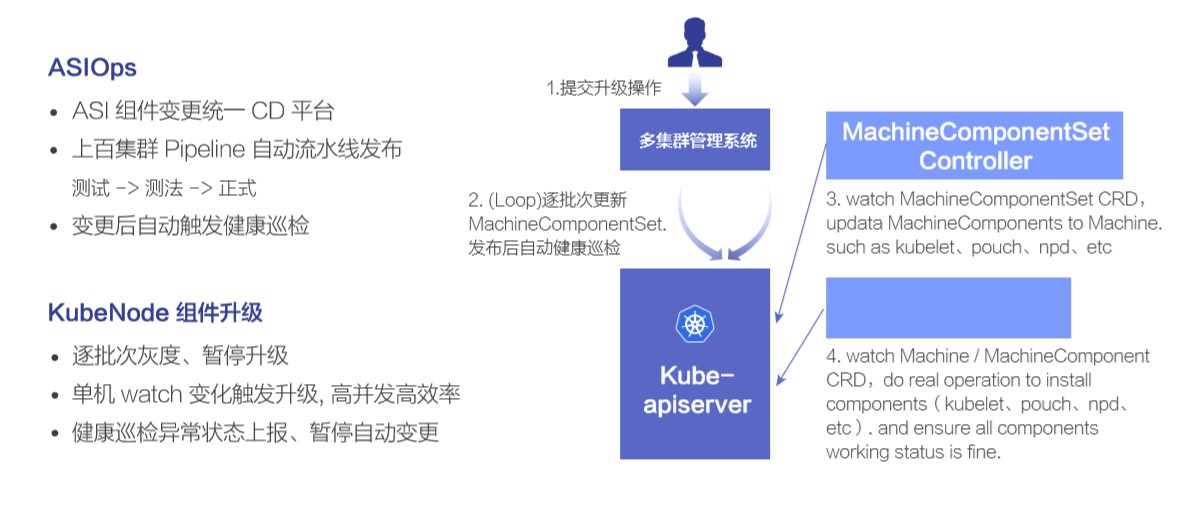
这里介绍下组件的升级过程,主要依赖的是 MachineComponentSet Controller 提供的分批次升级的能力。
首先用户在多集群管理系统上面提交一个组件升级操作,然后就进入一个逐批次循环升级的过程:先更新 MachineComponentSet 一个批次升级的机器数量是多少,之后 MachineComponentSet Controller 会计算并更新相应数量的节点上组件的版本信息。接下来 Kube Node Agent watch 到组件的变化,执行新版本的安装,并检查状态正常后上报组件状态正常。当这个批次所有的组件都升级成功后,再开始下一个批次的升级操作。
上面描述的单集群单个组件的升级流程是比较简单的,但对于线上十多个组件、上百个集群,要在所有的集群都完成版本推平工作就不那么简单了,我们通过 ASIOps 集群统一运维平台进行操作。在 ASIOps 系统中,将上百个集群配置到了有限的几个发布流水线,每条发布流水线都按照:测试 -> 预发 -> 正式 的顺序编排。一次正常的发布流程,就是选定一条发布流水线,按其预先设定好的集群顺序进行发布,在每个集群内部,又按照 1/5/10/50/100/… 的顺序进行自动发布,每一个批次发布完成,会触发健康巡检,如果有问题则暂停自动发布,没问题的话等观察期结束,则自动开始下一个批次的发布。通过这样的方式,做到了既安全又高效的完成一个组件新版本发布上线的过程。


接下来分享 KubeNode 里面的 Remedy Operator,也是一个标准的 Operator,用来做故障自愈修复。
Remedy Operator 也是由一组 CRD 以及对应的控制器组成。CRD 定义包括:NodeRemedier 和 RemedyOperationJob,控制器包括:Remedy Controller、RemedyJob Controller,同时也有故障自愈规则的注册中心,在单机侧有 NPD 和 Kube Node Agent。
Host Doctor 是在中心侧的一个独立的故障诊断系统,对接云厂商获取主动运维事件并转换为节点上的故障 Condition。在阿里云公有云上,ECS 所在的物理机发生的硬件类的故障或是计划中的运维操作,都会通过标准 OpenAPI 的形式获取,对接后就可以提前感知节点的问题,并提前自动迁移节点上的业务来避免故障。
Use Case:夯机自愈
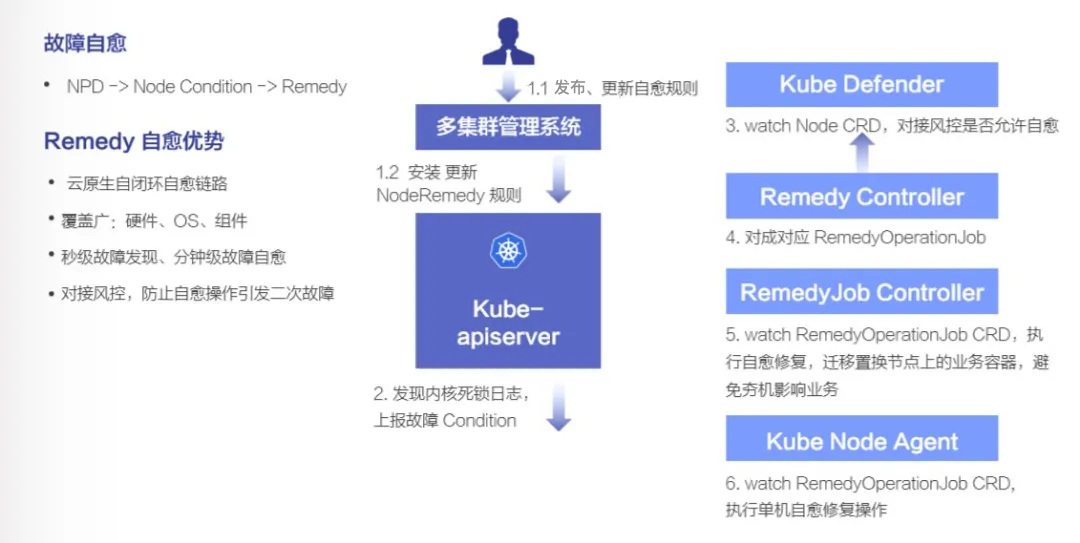
这里以夯机自愈的案例来介绍一个典型的自愈流程。
首先我们会在多集群管理系统 ASI Captain 上配置下发 CRD 描述的自愈规则,并且这些规则是可以灵活动态增加的,针对每一种 Node Condition 都可以配置一条对应的修复操作。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

总结
无论是哪家公司,都很重视高并发高可用的技术,重视基础,重视JVM。面试是一个双向选择的过程,不要抱着畏惧的心态去面试,不利于自己的发挥。同时看中的应该不止薪资,还要看你是不是真的喜欢这家公司,是不是能真的得到锻炼。其实我写了这么多,只是我自己的总结,并不一定适用于所有人,相信经过一些面试,大家都会有这些感触。
最后我整理了一些面试真题资料,技术知识点剖析教程,还有和广大同仁一起交流学习共同进步,还有一些职业经验的分享。

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
面试真题资料,技术知识点剖析教程,还有和广大同仁一起交流学习共同进步,还有一些职业经验的分享。
[外链图片转存中…(img-TUx7WIpr-1713460392204)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 2839
2839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









