






1.导入必要的库
导入处理数据和训练模型时需要的库
os: 这个模块提供了与操作系统交互的功能,比如文件和目录操作。
cv2: 这是OpenCV库的别名,它是一个强大的计算机视觉库,用于图像和视频处理。
numpy as np: NumPy是一个用于科学计算的库,它提供了高效的数组处理能力,对于图像处理等任务非常有用。
tensorflow as tf: TensorFlow是一个开源的机器学习库,用于构建和训练各种类型的机器学习模型。
import os
import cv2
import numpy as np
import tensorflow as tf
2.加载类别名称
with open(‘99/classes.txt’, ‘r’) as f:
with open(...) as f::这是上下文管理器(context manager),用于自动处理文件资源的打开和关闭。当with语句执行完成后,文件会自动关闭,即使遇到异常也是如此。
'99/classes.txt':这是要打开的文件的路径。
'r':这是文件打开模式,表示以只读方式打开文件。
f:这是上下文管理器创建的文件对象,可以用来读取文件内容。
classes = f.read().splitlines():
f.read():这个方法调用用于读取文件的全部内容,并将结果作为一个字符串返回。
.splitlines():这个方法调用用于将字符串按照行分隔符(通常是换行符\n)分割成一个列表。
classes:这个变量存储了分割后的列表,其中每个元素都是一个从文件中读取的标签名称。
with open('99/classes.txt', 'r') as f:
classes = f.read().splitlines()
3.创建标签映射字典
创建了一个标签映射字典,用于将标签索引转换为实际的标签名称。
label_mapping = {
'0': 'sad',
'1': 'happy',
'2': 'amazed',
'3': 'anger'
}
4.加载图像数据和对应的标签
从文件夹中加载了图像数据和对应的标签。
image_folder = '561'
label_folder = '99'
X_train = []
y_train = []
#遍历image_folder文件夹中的所有文件
for image_file in os.listdir(image_folder):
#创建一个完整的文件路径,将image_folder目录的路径和image_file(文件或子目录的名称)连接起来。
image_path = os.path.join(image_folder, image_file)
#cv2.imread(image_path):这个函数调用用于读取图像文件。
image = cv2.imread(image_path)
#如果图像成功加载,将图像数据添加到X_train列表中。
if image is not None:
X_train.append(image)
#将label_folder目录的路径和image_file(去除.jpg扩展名后的文件名)连接起来,并在最后加上.txt扩展名
label_file = os.path.join(label_folder, image_file.replace('.jpg', '.txt'))
with open(label_file, 'r') as f:
label_index = f.readline().strip().split()[0] # 只取第一个数字作为标签索引
label_name = label_mapping[label_index]
label = classes.index(label_name)
y_train.append(label)
X_train = np.array(X_train)
y_train = np.array(y_train)
5.构建和编译CNN模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(image.shape)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(len(classes), activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model = tf.keras.Sequential([ … ]):
tf.keras.Sequential:这是一个Keras模型,用于创建一个包含顺序堆叠的层的模型。
[ ... ]:这是一个列表,其中包含了模型中的层。
model:这个变量存储了创建的Keras Sequential模型。
tf.keras.layers.Conv2D(32, (3, 3), activation=‘relu’,
input_shape=(image.shape)):
tf.keras.layers.Conv2D:这是一个2D卷积层,用于提取图像的局部特征。
32:这是卷积层的输出通道数。
(3, 3):这是卷积核的大小,即每个卷积核覆盖的像素区域。
activation='relu':这是激活函数,用于在每个卷积层之后应用。
input_shape=(image.shape):这是输入层的形状,它是从image.shape获得的,确保模型的输入形状与图像数据的形状匹配。
tf.keras.layers.MaxPooling2D((2, 2)):
tf.keras.layers.MaxPooling2D:这是一个2D最大池化层,用于通过取每个池化区域的最大值来减小特征图的大小。
(2, 2):这是池化窗口的大小,即每个池化操作覆盖的像素区域。
tf.keras.layers.Flatten():
tf.keras.layers.Flatten:这是一个扁平化层,用于将2D或多维数组展平为一维数组。
tf.keras.layers.Dense(128, activation=‘relu’):
tf.keras.layers.Dense:这是一个全连接层,用于在模型中添加更多的非线性变换。
128:这是全连接层的神经元数量。
activation='relu':这是激活函数,用于在每个全连接层之后应用。
tf.keras.layers.Dense(len(classes), activation=‘softmax’):
tf.keras.layers.Dense:这是一个全连接层,用于在模型中添加更多的非线性变换。
len(classes):这是全连接层的神经元数量,它等于类别的数量。
activation='softmax':这是激活函数,用于在每个全连接层之后应用,以产生一个概率分布。
model.compile(optimizer=‘adam’,
loss=‘sparse_categorical_crossentropy’, metrics=[‘accuracy’]):
model.compile:这个方法用于编译模型,指定训练过程中使用的优化器、损失函数和评估指标。
optimizer='adam':这是模型使用的优化器,用于调整模型的权重以最小化损失函数。
loss='sparse_categorical_crossentropy':这是模型使用的损失函数,用于评估模型在训练数据上的性能。
metrics=['accuracy']:这是模型使用的评估指标,用于评估模型在训练数据上的性能。
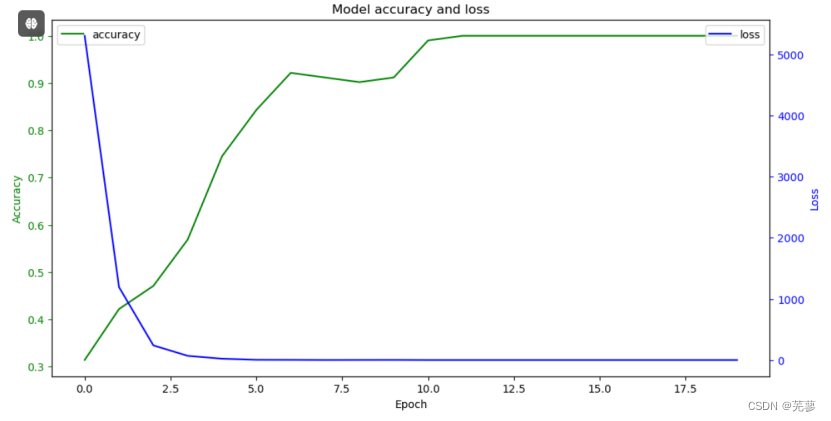
6.训练模型
model.fit(X_train, y_train, epochs=20, batch_size=32)
model.fit:这是Keras中的一个方法,用于训练模型。
X_train:这是模型的输入数据,它是一个NumPy数组。
y_train:这是模型的目标数据,它是一个NumPy数组。
epochs=20:这是训练过程中重复训练数据的次数。
batch_size=32:这是每次梯度更新的样本数量。
7.保存训练好的模型
model.save('cnn_model.h5')
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









