







一、数据的读入和保存
1、路径的识别与更改
(1)查看工作路径
#查看工作路径
getwd()(2)更改工作路径
#设定工作路径,括号中输入需要输入详细路径
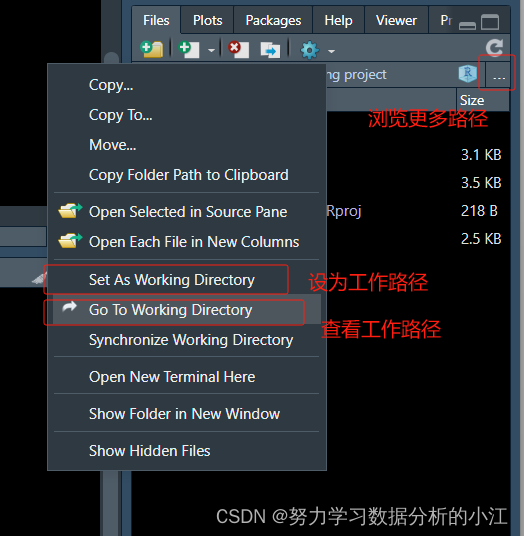
setwd()(3)也可以在【Files】窗口进行操作
①【Files】窗口

② 在【More】/【小齿轮】中进行操作
2、Excel文件的读取
在R中,有不少的拓展包来对excel文件进行读取和加工
(1)gdata包
- 基于Perl语言
- 如果电脑为linux系统或者MacOS系统,这个语言是预装好的,只要安装gdata包,并进行加载即可以使用
- 如果是Windows系统,则需要提前先加载Perl语言才能安装gdata包
- 所有Excel读取后的数据均为dataframe格式,即数据框格式
#安装gdata包
install.packages("gdata")
#调用gdata包
library("gdata")
#括号内填写excel的文件路径即可
example1 <- read.xls()
View(example1)- 当然,也可以通过鼠标进行操作:菜单栏 --File--Importdata--From Excel【更推荐】


(2)XLConnect包
- 该包需要两个命令进行Excel的读取,且命令具有先后顺序
#加载Excel文件
loadworkbook()
#读取Excel文件
readworkbook()(3)xlsx包
- 适合Windows系统
read.xlsx()3、其他类型文件的读取
(1)txt文件
#读取txt文件
read.table()(2)csv文件
#读取csv文件
read.csv()鼠标操作与Excel类似
4、保存为RDS文件
- RDS文件是R独有的文件类型
(1)保存在当前工作路径下
#(1)保存在当前工作路径下
saveRDS(file,file = "filename.fileformat")(2)保存在当前工作路径的某一个子文件夹下
#(2)保存在当前工作路径的某一个子文件夹下
saveRDS(file,file = "subfolder/filename,fileformat")
(3)保存在完全不同的路径下
#(3)保存在完全不同的路径下
saveRDS(file,file = "C:/folder/……")(4)重新读入RDS文件
#(4)重新读入RDS文件
readRDS()二、数据概览
- 进行以下操作之前,需要先载入以下R包
#下载“dplyr”包,这个包是处理数据的包
install.packages("dplyr")
library("dplyr")
#安装"gdata"包,读取Excel文件的安装包
install.packages("gdata")
library("gdata")1、数据的基本格式与行列数
class();dim();nrow();ncol()
#查看数据的格式,class()
class(example)
#查看数据的维度,dim(),看有多少和列
dim(example)
#单独查看行数
nrow(example)
#单独查看列数
ncol(example)
> #查看数据的格式,class() > class(example) [1] "tbl_df" "tbl" "data.frame" > View(example) > #查看数据的维度,dim(),看有多少和列 > dim(example) [1] 9 4 > #单独查看行数 > nrow(example) [1] 9 > #单独查看列数 > ncol(example) [1] 4
2、数据的概览
head() ; tail()
#预览前6行,一般在数据量比较小的时候使用
head(example)
#预览后6行
tail(example)> #预览前6行 > head(example) # A tibble: 6 × 4 Name Region Price Kilogram <chr> <chr> <dbl> <dbl> 1 Apple North 1.3 2.5 2 Orange South 1.7 1.5 3 Strawberry South 2.6 1.5 4 Kiwi Foregin 4.1 2 5 Blueberry Foregin 3.6 1 6 Tomato North 2.5 2.5 > #预览后6行 > tail(example) # A tibble: 6 × 4 Name Region Price Kilogram <chr> <chr> <dbl> <dbl> 1 Kiwi Foregin 4.1 2 2 Blueberry Foregin 3.6 1 3 Tomato North 2.5 2.5 4 Cucumba North 1.5 NA 5 Lemon East 2.1 0.5 6 Grape West 3.3 2
3、数据的行列名
rownames() ; colnames()
#查看数据的行名和列名
rownames(example)[c(1:3)]
colnames(example)> #查看数据的行名和列名 > rownames(example)[c(1:3)] [1] "1" "2" "3" > colnames(example) [1] "Name" "Region" "Price" "Kilogram"
三、查看数据细节
1、查看单行/列数据的格式与内容
class(,);View();View([,])
(1)查看数据行列格式
#查看某一行或某一列数据的格式,可以使用class(数据名$数据列名)
class(example$Name)
class(example$Kilogram)
> #查看某一行或某一列数据的格式,可以使用class(数据名$数据列名) > class(example$Name) [1] "character" > class(example$Kilogram) [1] "numeric"
(2)查看数据内容
#当数据比较小时,可以直接预览整个数据内容,注意这里的V要大写
View(example)
#当数据比较大时,可以预览某几行和某几列的内容
View(example[c(1:3),c(1:3)])四、缺失值的处理
1、查看是否有缺失值(基础)
is.na() ;is.nan()
NA:表示没有值
NaN:表示没有Number,没有数值
#当出现TRUE的时候,表示是缺失值或是不是数值
v1 <- c(1:10)
is.na(v1)
is.nan(v1)> v1 <- c(1:10) > is.na(v1) [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [9] FALSE FALSE > is.nan(v1) [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [9] FALSE FALSE
2、对于矩阵或数据集查看某行/列是否有缺失值
any(is.na())
#对于矩阵或数据集查看某行/列是否有缺失值
any(is.na(example[,1]))
any(is.na(example[,3]))
any(is.na(example[,4]))> #对于矩阵或数据集查看某行/列是否有缺失值 > any(is.na(example[,1])) [1] FALSE > any(is.na(example[,3])) [1] FALSE > any(is.na(example[,4])) [1] TRUE
另一种更快速的方式是使用apply()
#对数据集的每一列都查看是否有缺失值
#apply(数据集名称,2(2表示列,1表示行),function(x) any(is.na(x))),对每一列都执行any(is.na的命令
apply(example,2,function(x) any(is.na(x)))
apply(example,1,function(x) any(is.na(x)))
> #对数据集的每一列都查看是否有缺失值
> #apply(数据集名称,2(2表示列,1表示行),function(x) any(is.na(x))),对每一列都执行any(is.na的命令
> apply(example,2,function(x) any(is.na(x)))
Name Region Price Kilogram
FALSE FALSE FALSE TRUE
> apply(example,1,function(x) any(is.na(x)))
[1] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
3、对缺失值的处理
可以删除具有缺失值的某一行数据,再形成一个新的,具有完整数据的数据集
#删除具有缺失值所在的行的数据,只保留了没有缺失值的行,列均保留
example.complete <- example[complete.cases(example),]五、数据的总结
1、数据整体总结
summary() ; rowSums() ; colSums()
#对数据进行总结
#对每一列进行简单总结
summary(example)
> #对每一列进行简单总结
> summary(example)
Name Region Price Kilogram
Length:9 Length:9 Min. :1.300 Min. :0.500
Class :character Class :character 1st Qu.:1.700 1st Qu.:1.375
Mode :character Mode :character Median :2.500 Median :1.750
Mean :2.522 Mean :1.688
3rd Qu.:3.300 3rd Qu.:2.125
Max. :4.100 Max. :2.500
NA's :1
#对每一行或列进行求和,其要求是该行或该列必须全是数值形式的数据
colSums(example.complete[,3])
colSums(example.complete[,4])
> #对每一行或列进行求和,其要求是该行或该列必须全是数值形式的数据
> colSums(example.complete[,3])
Price
21.2
> colSums(example.complete[,4])
Kilogram
13.5
2、进行额外计算
mutate()
#对数据集某几列进行计算,并将结果生成新的一列
t1 <- mutate(example.complete,Total = Price * Kilogram)
t1> #对数据集某几列进行计算 > t1 <- mutate(example.complete,Total = Price * Kilogram) > t1 # A tibble: 8 × 5 Name Region Price Kilogram Total <chr> <chr> <dbl> <dbl> <dbl> 1 Apple North 1.3 2.5 3.25 2 Orange South 1.7 1.5 2.55 3 Strawberry South 2.6 1.5 3.9 4 Kiwi Foregin 4.1 2 8.2 5 Blueberry Foregin 3.6 1 3.6 6 Tomato North 2.5 2.5 6.25 7 Lemon East 2.1 0.5 1.05 8 Grape West 3.3 2 6.6
#以上内容均来自于医咖会的R语言的基础课程笔记,仅供参考~















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









