






一、具体需求
1、一个可执行的吧网络爬虫程序
2、可成功爬取目标网站数据,关键项不少于5项。
3、使用sqlite3存储数据到数据库并命名为Ranking,可以进行增删改查操作。
4、使用matplotlib库将库中数据进行可视化展示。
二、代码实现
import requests
import csv
import pandas as pd
import matplotlib.pyplot as plt
import warnings
import sqlite3
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决符号无法显示
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
}
data = {
'r': '0.9936776079863086',
'top': '50',
'type': '0',
}
resp = requests.post('https://ys.endata.cn/enlib-api/api/home/getrank_mainland.do', headers=headers, data=data)
data_list = resp.json()['data']['table0']
# 创建SQLite数据库连接
conn = sqlite3.connect('Ranking.db')
# 创建游标对象
c = conn.cursor()
# 创建排行榜表
c.execute('''CREATE TABLE IF NOT EXISTS Ranking
(Rank INTEGER, MovieName TEXT, ReleaseTime TEXT, TotalPrice REAL, AvgPrice REAL, AvgAudienceCount INTEGER)''')
for item in data_list:
rank = item['Irank'] # 排名
MovieName = item['MovieName'] # 电影名称
ReleaseTime = item['ReleaseTime'] # 上映时间
TotalPrice = item['BoxOffice'] # 总票房(万)
AvgPrice = item['AvgBoxOffice'] # 平均票价
AvgAudienceCount = item['AvgAudienceCount'] # 平均场次
# 插入数据到数据库
c.execute("INSERT INTO Ranking VALUES (?, ?, ?, ?, ?, ?)",
(rank, MovieName, ReleaseTime, TotalPrice, AvgPrice, AvgAudienceCount))
print(rank, MovieName, ReleaseTime, TotalPrice, AvgPrice, AvgAudienceCount)
# 提交更改
conn.commit()
# 关闭游标和连接
c.close()
conn.close()
def data_analyze():
# 创建SQLite数据库连接
conn = sqlite3.connect('Ranking.db')
# 读取数据
data = pd.read_sql_query("SELECT * FROM Ranking", conn)
# 从上映时间中提取出年份
data['年份'] = data['ReleaseTime'].apply(lambda x: x.split('-')[0])
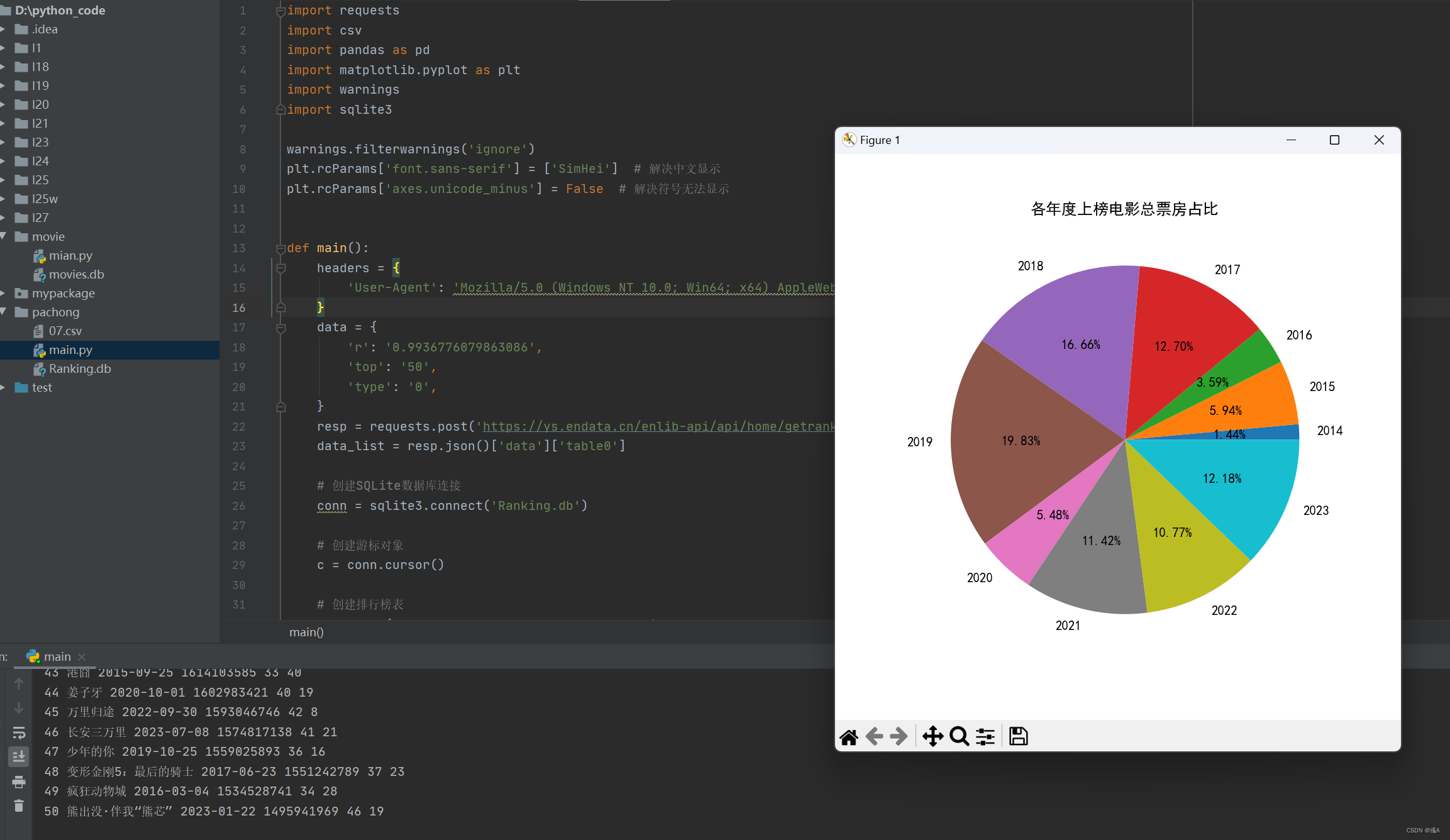
# 各年度上榜电影总票房占比
df1 = data.groupby('年份')['TotalPrice'].sum()
plt.figure(figsize=(6, 6))
plt.pie(df1, labels=df1.index.to_list(), autopct='%1.2f%%')
plt.title('各年度上榜电影总票房占比')
plt.show()
# 各个年份总票房趋势
df1 = data.groupby('年份')['TotalPrice'].sum()
plt.figure(figsize=(6, 6))
plt.plot(df1.index.to_list(), df1.values.tolist())
plt.title('各年度上榜电影总票房趋势')
plt.show()
# 平均票价最贵的前十名电影
print(data.sort_values(by='AvgPrice', ascending=False)[['年份', 'MovieName', 'AvgPrice']].head(10))
# 平均场次最高的前十名电影
print(data.sort_values(by='AvgAudienceCount', ascending=False)[['年份', 'MovieName', 'AvgAudienceCount']].head(10))
# 关闭连接
conn.close()
def add_movie(conn, rank, movie_name, release_time, total_price, avg_price, avg_audience_count):
c = conn.cursor()
c.execute(
"INSERT INTO Ranking(Rank, MovieName, ReleaseTime, TotalPrice, AvgPrice, AvgAudienceCount) VALUES (?, ?, ?, ?, ?, ?)",
(rank, movie_name, release_time, total_price, avg_price, avg_audience_count))
conn.commit()
c.close()
def delete_movie(conn, rank):
c = conn.cursor()
c.execute("DELETE FROM Ranking WHERE Rank=?", (rank,))
conn.commit()
c.close()
def update_movie(conn, rank, field, value):
c = conn.cursor()
c.execute(f"UPDATE Ranking SET {field}=? WHERE Rank=?", (value, rank))
conn.commit()
c.close()
def query_movie(conn, rank):
c = conn.cursor()
c.execute("SELECT * FROM Ranking WHERE Rank=?", (rank,))
row = c.fetchone()
c.close()
return row
if __name__ == '__main__':
# 创建保存数据的csv文件
with open('07.csv', 'w', encoding='utf-8', newline='') as f:
csvwriter = csv.writer(f)
# 添加文件表头
csvwriter.writerow(('排名', '电影名称', '上映时间', '总票房(万)', '平均票价', '平均场次'))
main()
# 数据分析
data_analyze()
# 创建SQLite数据库连接
conn = sqlite3.connect('Ranking.db')
# 添加电影数据
add_movie(conn, 51, '电影A', '2023-08-02', 1000, 50, 100)
# 删除电影数据
delete_movie(conn, 50)
# 更新电影数据
update_movie(conn, 49, 'AvgPrice', 60)
# 查询电影数据
row = query_movie(conn, 48)
print(row)
# 关闭数据库连接
conn.close()

















 2180
2180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









