






一、具体需求
1、一个可执行的吧网络爬虫程序
2、可成功爬取目标网站数据,关键项不少于5项。
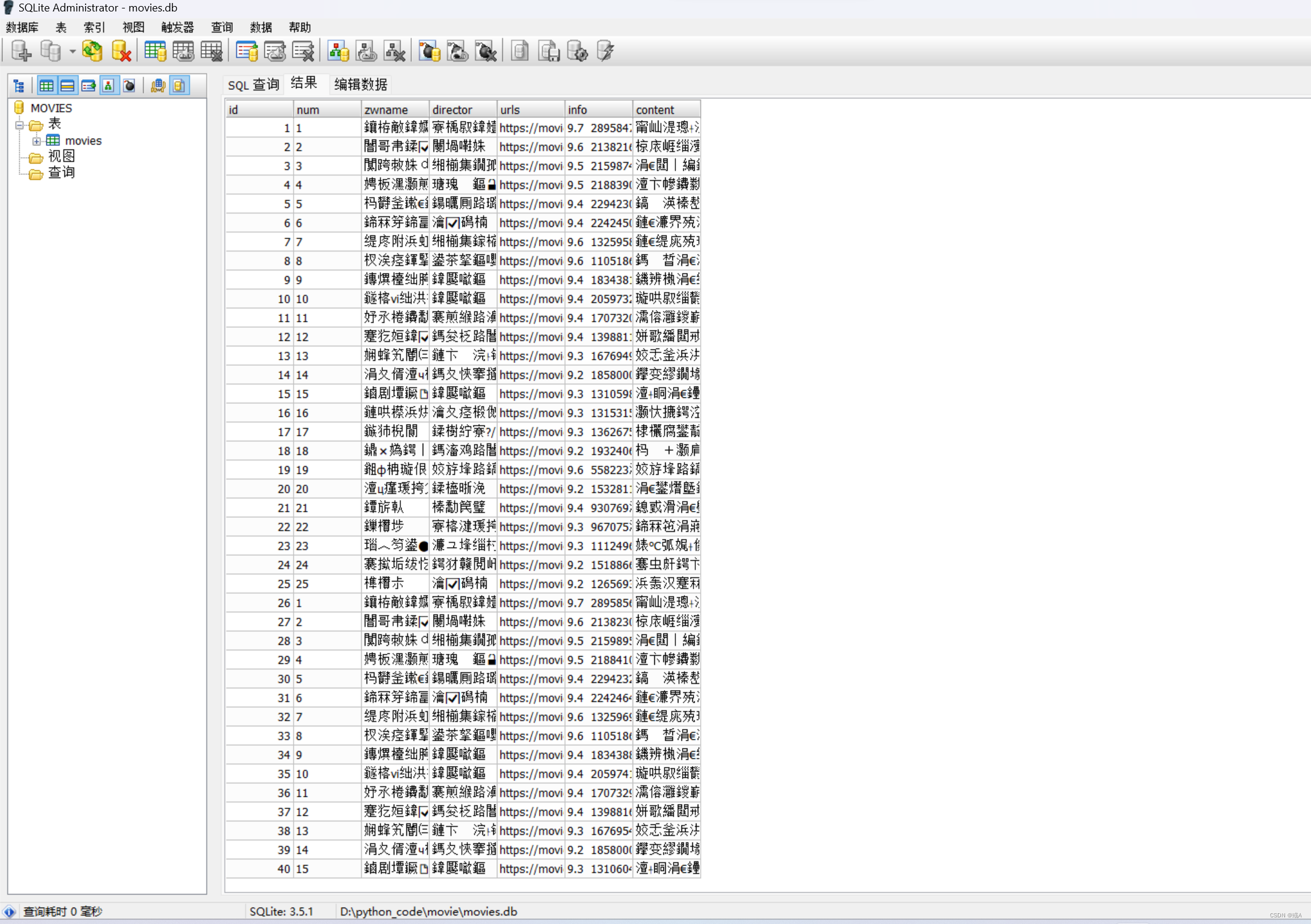
3、使用sqlite3存储数据到数据库并命名为movies,可以进行增删改查操作。
4、使用matplotlib库将库中数据进行可视化展示。
二、 代码实现
import urllib.request
from bs4 import BeautifulSoup
import sqlite3
import matplotlib.pyplot as plt
def main(url, headers,cursor):
# 发送请求
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
contents = page.read()
# 用BeautifulSoup解析网页
soup = BeautifulSoup(contents, "html.parser")
print('爬取豆瓣电影250: \n')
ratings = [] # 存储评分数据
for tag in soup.find_all(attrs={"class": "item"}):
# 爬取序号
num = tag.find('em').get_text()
print(num)
# 电影名称
name = tag.find_all(attrs={"class": "title"})
zwname = name[0].get_text()
print('[中文名称]', zwname)
# 进入详情页获取导演信息
detail_url = tag.find(attrs={"class": "hd"}).a.attrs['href']
director = get_director(detail_url, headers)
print('[导演]', director)
# 网页链接
url_movie = tag.find(attrs={"class": "hd"}).a
urls = url_movie.attrs['href']
print('[网页链接]', urls)
# 爬取评分和评论数
info = tag.find(attrs={"class": "star"}).get_text()
info = info.replace('\n', ' ')
info = info.lstrip()
print('[评分评论]', info)
# 获取评语
info_tag = tag.find(attrs={"class": "inq"})
if info_tag:
content = info_tag.get_text()
print('[影评]', content)
# 将info和content转换为字符串
info_str = str(info)
content_str = str(content)
# 插入数据到数据库
cursor.execute('''
INSERT INTO movies (num, zwname, director, urls, info, content)
VALUES (?, ?, ?, ?, ?, ?)
''', (num, zwname, director, urls, info_str, content_str))
# 提取评分并添加到ratings列表中
rating = float(info_str.split()[0])
ratings.append(rating)
print('')
print("数据插入完成")
print('')
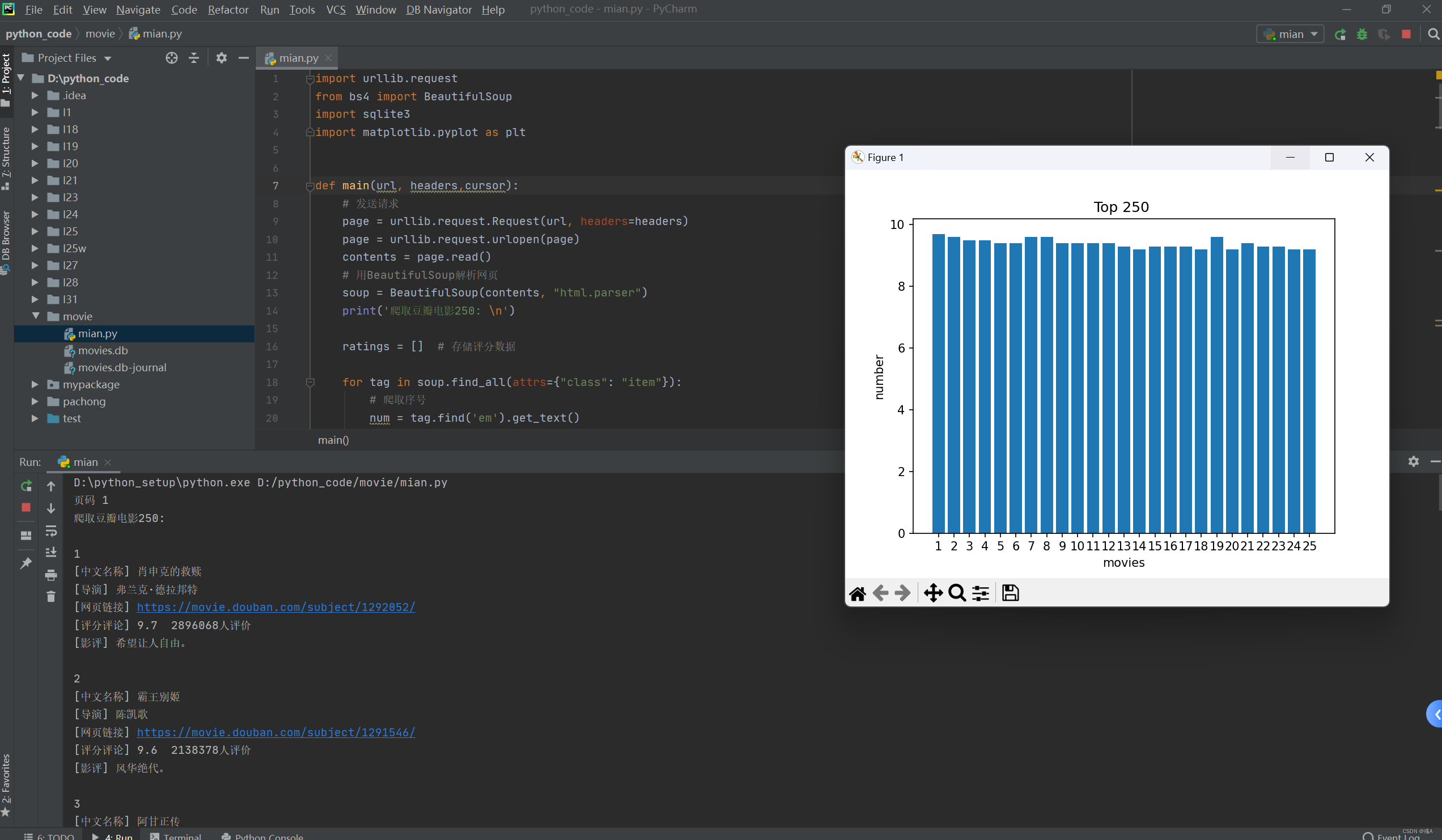
# 可视化展示电影评分条形图
plt.bar(range(len(ratings)), ratings)
plt.xlabel('movies')
plt.ylabel('number')
plt.title('Top 250 ')
plt.xticks(range(len(ratings)), range(1, len(ratings) + 1))
plt.show()
def get_director(url, headers):
detail_page = urllib.request.Request(url, headers=headers)
detail_page = urllib.request.urlopen(detail_page)
detail_contents = detail_page.read()
detail_soup = BeautifulSoup(detail_contents, "html.parser")
directors = detail_soup.find_all(attrs={"class": "attrs"})[0].get_text().split('\n')
for director in directors:
if director.strip():
return director.strip()
if __name__ == '__main__':
# 连接到SQLite数据库
conn = sqlite3.connect('movies.db')
# 创建一个游标对象
cursor = conn.cursor()
# 创建存储电影信息的表(如果不存在)
cursor.execute('''
CREATE TABLE IF NOT EXISTS movies (
id INTEGER PRIMARY KEY,
num TEXT,
zwname TEXT,
director TEXT,
urls TEXT,
info TEXT,
content TEXT
)
''')
# 消息头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15'}
# 翻页
i = 0
while i < 1:
print('页码', (i + 1))
num = i * 25 # 每次显示20部 URL序号按20增加
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
main(url, headers, cursor)
i = i + 1
'''
# 查询数据
cursor.execute('SELECT * FROM movies')
rows = cursor.fetchall()
for row in rows:
print(row)
# 插入新电影信息
num = '251'
zwname = '新电影'
director = '某某导演'
urls = 'https://movie.com'
info = '8.0 1000人评论'
content = '这是一部很好的电影'
cursor.execute('INSERT INTO movies (num, zwname, director, urls, info, content) VALUES (?, ?, ?, ?, ?, ?)',
(num, zwname, director, urls, info, content))
# 更新电影信息
num = '1'
new_director = '新导演'
cursor.execute('UPDATE movies SET director = ? WHERE num = ?', (new_director, num))
# 删除电影信息
num = '1'
cursor.execute('DELETE FROM movies WHERE num = ?', (num,))
'''
# 提交更改并关闭数据库连接
conn.commit()
conn.close()
三、实验结果














 9244
9244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









