






Office办公文件
目录
4.2.2 读取与提取 PDF 内容 —— PyMuPDF (fitz), pdfplumber, PyPDF2
4.2.3 PyMuPDF(fitz)高效处理 PDF 与图像
这里先说明一下doc文件和docx文件以及ppt和pptx文件等带x文件和不带x文件的区别。
doc文件和docx文件的区别
对比维度 DOC格式 DOCX格式 文件格式 早期二进制格式,单一文件存储所有内容 基于XML的开放格式,实际为压缩包
(含多个XML文件和资源)
文件大小 较大(尤其含图片时) 较小(压缩技术优化存储效率) 兼容性 旧版Word原生支持(2007之前) 新版Word(2007+)原生支持,
旧版需兼容包
安全性 易携带宏病毒,风险较高 默认禁用宏,安全性更好 功能支持 仅支持基础排版和简单对象 支持高级功能,例如:SmartArt 功能 跨平台适应性 依赖Word软件解析,跨平台兼容性有限 基于开放标准,易与其他办公软件
兼容
扩展性 扩展性差,修改易损坏文件结构 模块化设计,便于内容提取和自动化处理 注意! 在对其office这些软件读取和操作时,我们不能按照普通格式文件(昨天的内容)带简单后缀进行打开,不能用
open(..., encoding=...)读取!.xlsx是 二进制格式 的 Excel 文件,内部是由多个 XML 和压缩文件组成的,不是纯文本。所以我们需要第三方库的支持。
1、Word文件
Word操作文档的库:
pip install python-docx1.1、文件基本库函数:
本小节具体说明一些关于Python对Word文档的一些基本操作,具体详细内容参考python-docx文档。
1.1.1 文件的读取
#对.docx文件的读取
from docx import Document
WriteHead = "实验模版"
WriteContent = '1, 2, 3, 4, 5, 上山打老虎'
df = Document('E:\\CSDNTEXT\\TEXT.docx')
print(df.paragraphs[0].text) # 读取第一行内容
print(df.paragraphs[0].runs[0].text) # 只读第一行中(一个字符是拥有统一格式的一段文字)
df = Document('E:\\CSDNTEXT\\TEXT.docx') # 打开已有文档或新建空文档
for i, para in enumerate(df.paragraphs):
print(f"第{i+1}段内容:{para.text}")1.1.2 文件的写入修改
# 写文件
df = Document('E:\\CSDNTEXT\\TEXT.docx') # 打开已有文档或新建空文档
df.add_heading(WriteHead, level=1) # 添加标题
df.add_paragraph(WriteContent[5]) # 添加无序列表(注意空格)
df.save('E:\\CSDNTEXT\\TEXT_结果.docx') # 保存到新文件
#改文件内容
df = Document('E:\\CSDNTEXT\\TEXT.docx') # 打开已有文档或新建空文档
for i, para in enumerate(df.paragraphs):
print(f"第{i+1}段内容:{para.text}")
if para.text == 'TEXT':
para.text = '下山打老虎' # 修改内容
print(f"修改后的内容:{para.text}")1.2、使用场景:
我们平时写请假条,电子版每次都要到网上模版,现在我们可以建立一个模版,只需要我们输入一些合适的文件必备内容,我们就可以一键生成Word文档,通过Python实现量化生产。
我们来做一个程序请假条:
1.2.1 创建文档并写入模版:
from docx import Document
from docx.shared import Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
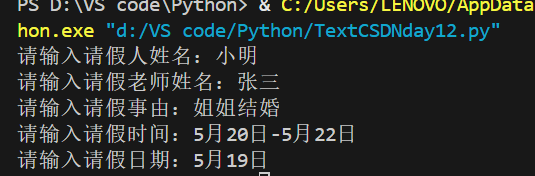
name = input("请输入请假人姓名:")
nameTeach = input("请输入请假老师姓名:")
things = input("请输入请假事由:")
time = input("请输入请假时间:")
date = input("请输入请假日期:")
# 创建文档
doc = Document()
# 设置标题 黑体居中20榜体
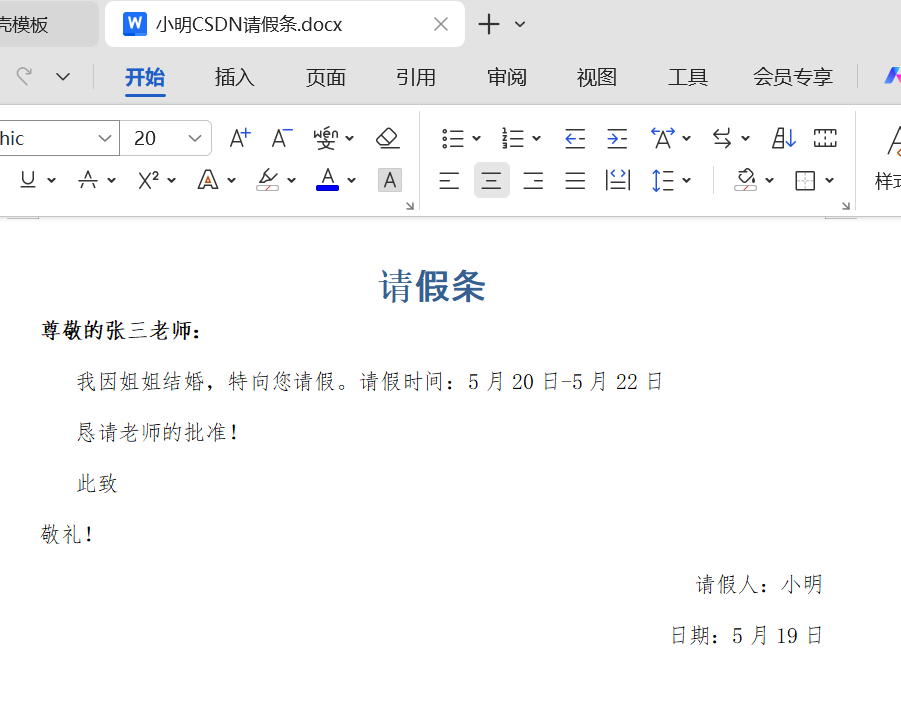
title = doc.add_heading('请假条', level=1,)
title.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
title_run = title.runs[0]
title_run.font.name = '黑体'
title_run.font.size = Pt(20)
title_run.font.bold = True
# 添加正文内容
p1 = doc.add_paragraph()
p1.add_run('尊敬的').bold = True
p1.add_run(f'{nameTeach}').bold = True
p1.add_run('老师:').bold = True
p1.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT
p2 = doc.add_paragraph(f'我因{things},特向您请假。请假时间:{time}')
p2.paragraph_format.left_indent = Pt(20) # 设置左缩进为20pt
p2.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT
p22 = doc.add_paragraph('恳请老师的批准!')
p22.paragraph_format.left_indent = Pt(20) # 设置左缩进为20pt
p22.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT
p3 = doc.add_paragraph('此致')
p3.paragraph_format.left_indent = Pt(20) # 设置左缩进为20pt
p3.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT
p33 = doc.add_paragraph('敬礼!')
p33.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT
# 签名部分右对齐
p4 = doc.add_paragraph(f'请假人:{name}')
p4.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
p5 = doc.add_paragraph(f'日期:{date}')
p5.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
# 设置整体字体为仿宋,小四(12pt)
style = doc.styles['Normal']
font = style.font
font.name = '仿宋'
font.size = Pt(12)
# 兼容中文字体设置
style.element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋')
# 保存文档
doc.save(f'E:\\CSDNTEXT\\{name}CSDN请假条.docx')
1.2.2 写入内容:
1.2.3 生产内容:
2、Excel文件
Excel文件和.csv文件有很多相似之处和不同,具体参照文章:对csv文件,又get了新的认知。同时,在外面具体项和研究中,Excel文件我们使用非常频繁,数据库、爬虫、数据处理等都会用到。由于Python对数据处理有强大的功能我们只是简单讲解,具体后面慢慢补充。
Excel文件所需的库:
pip install xlwt xlrd xlutils数据处理的库等;
import pandas as pd2.1、文件基本操作:
2.1.1 xlrd文件读取
work = xlrd.open_workbook("E:\\CSDNTEXT\\TEXTStu.xls")
# print(work.sheet_names()) # 打印所有sheet名称
# print(work.nsheets()) # 打印所有sheet对象
# print(work.sheet_by_index(0).name) # 打印第一个sheet名称
# 打印第一个sheet第一列所有数据
sheet = work.sheet_by_index(0) # 选择第一个sheet
for i in range(sheet.nrows): # sheet.nrows是行数
print(sheet.row_values(i)[0]) # sheet.row_values(i)是第i行所有数据,sheet.row_values(i)[0]是第i行第一列数据
2.1.2 openyxl基本写入和读取
我们可以通过openyxl进行Python对Excel文件的操作,具体库的使用,参考其官网教程。
# Excel 基本操作
import openpyxl
#创建一个新的Excel工作簿
workbook = openpyxl.Workbook()
#选择活动工作表
sheet = workbook.active
#设置工作表标题
sheet.title = '一班人员名单'
#再创建一个sheet
sh2=workbook.create_sheet('二班人员名单',0) #后面参数:0是第一个位置,1是第二个位置
#操作一班人员名单表单
shOne = workbook['一班人员名单']
# shTwo = workbook['二班人员名单']
#给表单写入数据
shOne['A1'] = '姓名'
shOne['B1'] = '学号'
#特定的单元格写入数据
shOne.cell(2,1).value = '张三'
shOne.cell(2,2).value = '20230101'
#读取数据
print(shOne['A1'].value) #读取A1单元格的值
print(shOne.cell(1, 1).value) #读取A1单元格的值
# 循环写入
name = ['张三', '李四', '王五', '赵六', '钱七', '孙八', '周九', '吴十'] #姓名列表
num = ['20230101', '20230102', '20230103', '20230104', '20230105', '20230106', '20230107', '20230108'] #学号列表
for i,na in enumerate(name):
shOne.cell(i+2, 1).value = name[i] #写入姓名 或者 na->name[i]
shOne.cell(i+2, 2).value = num[i] #写入学号
#保存工作簿
workbook.save('E:\\CSDNTEXT\\TEXTStu.xlsx')2.1.3 文件数据处理 pandas
我们对数据处理,Pandas 是 Python 语言的一个扩展程序库,用于数据分析。Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)。Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。清洗需要使用很多函数,数据的表格操作,这里面就有很强大的库(pandas),具体详细操作pandas官网。
# 导入pandas库
import pandas as pd
# 读取Excel文件
df = pd.read_excel('E:\\CSDNTEXT\\TEXTStu.xlsx', sheet_name='一班人员名单')
# 数据清洗
df.dropna() # 删除包含缺失值的行
df.fillna(0) # 将缺失值填充为 0
df.drop_duplicates() # 删除重复行
df.rename(columns={'旧列名': '新列名'}, inplace=True) # 重命名列
# 数据操作
print(df['列名'].mean()) # 平均值
print(df['列名'].sum()) # 总和
print(df['列名'].max()) # 最大值
print(df['列名'].min()) # 最小值
print(df['列名'].std()) # 标准差
print(df['列名'].value_counts()) # 统计每个值的出现次数
# 数据保存
df.to_excel('output.xlsx', index=False) # 保存为 Excel 文件
df.to_csv('output.csv', index=False) # 保存为 CSV 文件
df.to_json('output.json', orient='records') # 保存为 JSON 文件
3、PPT(PowerPoint)文件
PPT文件操作所需的库:
pip install python-pptx3.1、文件基本操作和基本库的使用
3.1.1 基本功能
在该小节是说明python对文件的创建,读取,修改等操作,更具体参考python-pptx官网。
from pptx import Presentation
# 创建PPTX演示文稿对象
prs = Presentation()
# 添加新的幻灯片
slide_layout = prs.slide_layouts[0] # 选择第一个幻灯片布局
slide = prs.slides.add_slide(slide_layout)
# 添加标题和内容(文本框)
title = slide.shapes.title
content = slide.placeholders[1] # 占位符1通常是内容框
title.text = "Hello, PPTX!" # 设置标题文本
content.text = "这是一个PPTX演示文稿CSDN." # 设置内容文本
# 新建一个ppt页面添加图片
slide_layout = prs.slide_layouts[5] # 选择空白幻灯片布局
slide = prs.slides.add_slide(slide_layout) # 添加新的幻灯片
img = slide.shapes.add_picture("E:\\CSDNTEXT\\TEXT.png", left=0, top=0, width=prs.slide_width, height=prs.slide_height)
# 添加表格
from pptx.util import Inches
from pptx.dml.color import RGBColor
slide_layout = prs.slide_layouts[5] # 选择空白幻灯片布局
slide = prs.slides.add_slide(slide_layout) # 添加新的幻灯片
table = slide.shapes.add_table(rows=3, cols=3, # 表格布局和大小
left=Inches(1),
top=Inches(4),
width=Inches(5),
height=Inches(2)).table
table.cell(0, 0).text = "姓名" # 设置表格第一行第一列的文本
table.cell(0, 1).text = "学号" # 设置表格第一行第二列的文本
# 文本内容居中
table.cell(0, 0).text_frame.paragraphs[0].alignment = 1 # 设置文本居中对齐
table.cell(0, 0).text_frame.paragraphs[0].font.bold = True # 设置文本加粗
# 保存PPTX文件
prs.save("E:\\CSDNTEXT\\TEXT1.pptx") # 保存文件到指定路径3.1.2 应用场景
创建一个我们商业pptx,基本的办公ppt,可以临时制作一个模版,到时候使用时,我们只需要输入相关内容,选取合适的模版,我们就可以高效的使用文档ppt模版。
我们来创建一个基本的两页一个主题页和目录页的模版。
(1)代码内容:
# 创建一个工作汇报pptx
from pptx import Presentation
from pptx.util import Inches, Pt
from pptx.enum.text import PP_ALIGN
from pptx.dml.color import RGBColor
from pptx.enum.shapes import MSO_SHAPE
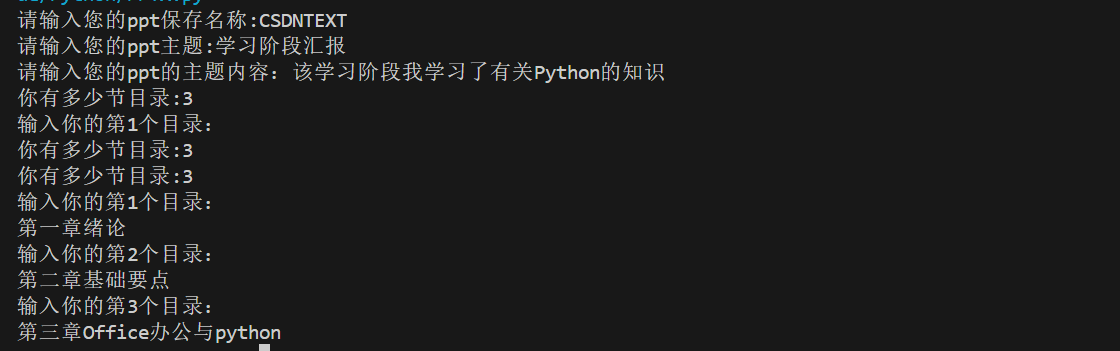
pptname = input("请输入您的ppt保存名称:")
pptItem = input("请输入您的ppt主题:")
pptMContext = input("请输入您的ppt的主题内容")
# 创建PPTX演示文稿对象
prs = Presentation()
# 添加标题幻灯片
slide_layout = prs.slide_layouts[0] # 标题幻灯片布局
slide = prs.slides.add_slide(slide_layout)
title = slide.shapes.title
subtitle = slide.placeholders[1]
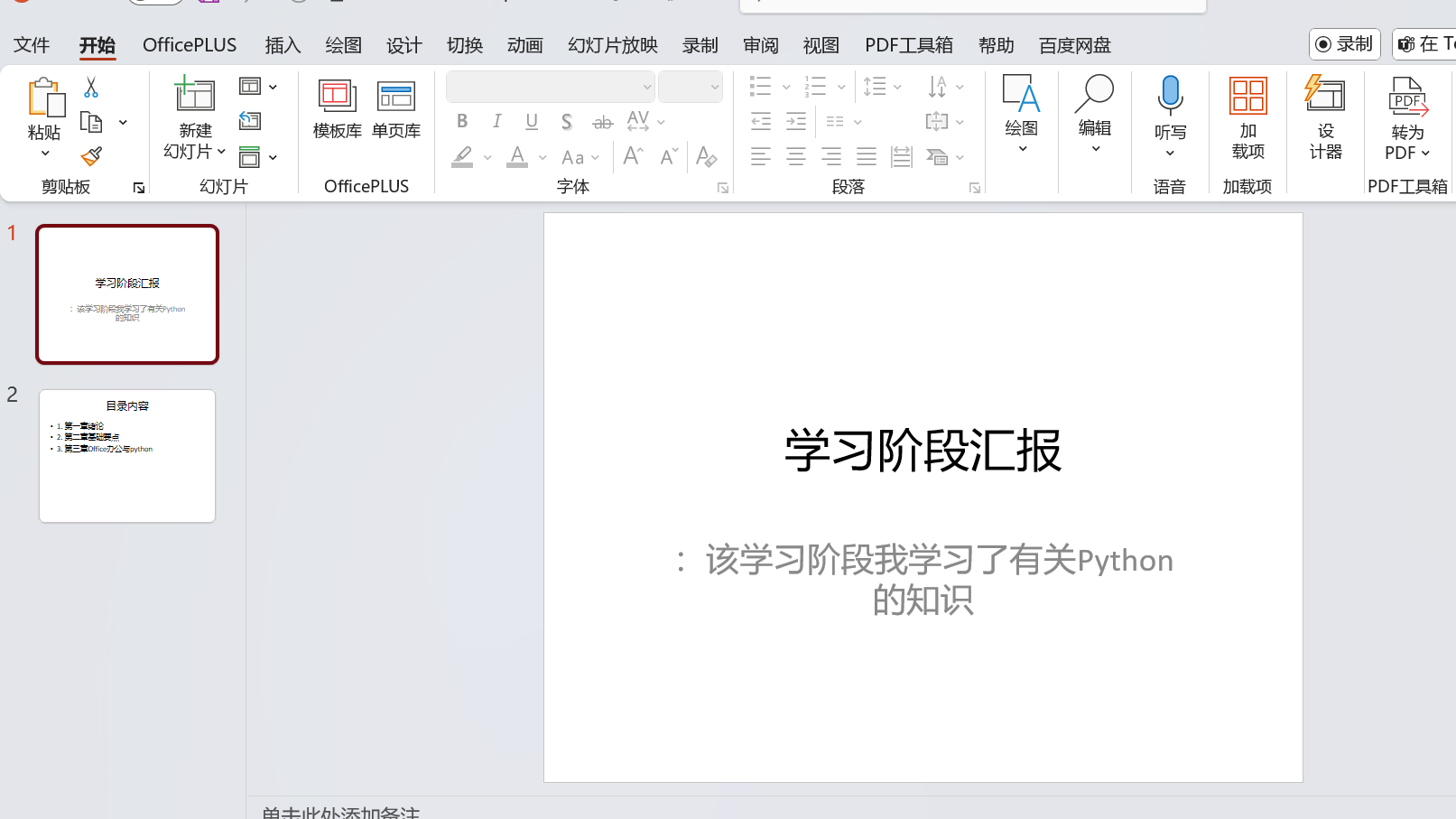
title.text = pptItem
subtitle.text = pptMContext
# 添加内容幻灯片
slide_layout = prs.slide_layouts[1] # 内容幻灯片布局
slide = prs.slides.add_slide(slide_layout)
title = slide.shapes.title
content = slide.placeholders[1]
title.text = "目录内容"
# 输入你的目录内容:
n = int(input("你有多少节目录:"))
tt = {}
for i in range(1, n + 1):
tt[i] = input(f"输入你的第{i}个目录:\n")
# 将目录内容拼接成一个字符串并设置到 content.text
content.text = "\n".join([f"{i}. {tt[i]}" for i in range(1, n + 1)])
# 保存PPTX文件
prs.save(f"E:\\CSDNTEXT\\{pptname}.pptx")(2)运行结果:
(3)生成内容:
4、PDF文件
我们也可以对PDF文件进行操作,PDF文件操作所需的库:
pip install PyPDF2 #PDF的一些基本整体操作
pip install fpdf #创建PDF
pip install pdfplumber #对PDF提取某些元素
对于我们要用的库详见PyPDF2文档,具体的相关操作。
4.1、基本操作
from PyPDF2 import PdfReader
from PyPDF2 import PdfMerger
from fpdf import FPDF
import pdfplumber
reader = PdfReader('E:\\CSDNTEXT\\TEXT.pdf')
for page in reader.pages:
print(page.extract_text())
pdf = FPDF() # 创建一个PDF对象
pdf.add_page()
pdf.set_font("Arial", size=12)
pdf.cell(200, 10, txt="Hello World!", ln=True, align='C')
pdf.output("E:\\CSDNTEXT\\TEXTinput.pdf")
merger = PdfMerger()# 合并pdf文件
merger.append("E:\\CSDNTEXT\\TEXT.pdf")
merger.append("E:\\CSDNTEXT\\TEXTinput.pdf")
merger.write("E:\\CSDNTEXT\\merged.pdf")
merger.close()
# 使用pdfplumber读取pdf文件
with pdfplumber.open("E:\\CSDNTEXT\\TEXT.pdf") as pdf:
for page in pdf.pages:
tables = page.extract_tables()
for table in tables:
print(table)
import fitz # PDF文件处理图片
doc = fitz.open("E:\\CSDNTEXT\\TEXT.pdf")
for page_number in range(len(doc)): # 遍历每一页
for img_index, img in enumerate(doc[page_number].get_images(full=True)): # 遍历每一页的图片
xref = img[0] # 获取图片的xref
base_image = doc.extract_image(xref) # 提取图片
image_bytes = base_image["image"] # 获取图片的字节流
with open(f"image_{page_number+1}_{img_index+1}.png", "wb") as f: # 保存图片
f.write(image_bytes)
4.2、常见的库函数的使用:
4.2.1 创建与写入 PDF —— fpdf
from fpdf import FPDF
#add_page():添加新页面
#set_font(family, size, style):设置字体
#cell(w, h, txt, ln, align):创建单元格并写入文本
#output("filename.pdf"):保存 PDF 文件4.2.2 读取与提取 PDF 内容 —— PyMuPDF (fitz), pdfplumber, PyPDF2
import pdfplumber
#pdf.pages:获取所有页面
#page.extract_text():提取纯文本
#page.extract_tables():提取表格数据
4.2.3 PyMuPDF(fitz)高效处理 PDF 与图像
import fitz # pip install pymupdf
#get_text():提取文字
#get_images():获取图片信息
#extract_image(xref):提取图片
#insert_image():插入图片
4.2.4 PyPDF2(轻量级 PDF 分页和合并工具)
from PyPDF2 import PdfReader, PdfWriter
#PdfReader("file.pdf"):读取 PDF
#reader.pages:获取页面列表
#add_page():添加页面到新 PDF
#write():写入文件五、总结
在Python对文件操作时,要先了解包内的函数和具体使用方法,可以点击**包的超链接跳入其文档,有更高效的方法进行操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









