







地学问题往往涉及多个相互影响的因素,如温度、降水、地形、土壤类型等。多元线性回归可以将这些变量之间的关系用数学模型定量化,揭示各因素对目标变量(如降水量或地震活动等)的贡献和相互作用,帮助研究者深入理解地学过程。
通过建立回归模型,可以利用历史观测数据预测未来的地学现象。例如,在气候变化研究中,通过多元线性回归预测未来温度或降水趋势,为防灾减灾和资源管理提供科学依据。这种预测能力在实际应用中具有重要价值。
多元线性回归(Ordinary Least Squares, OLS)作为一种基础且直观的统计建模方法,在地学研究中具有广泛应用。本文将以某地降水为例,详细介绍如何利用多元线性回归模型探索和量化环境变量对降水的影响,从而为降水预测和水资源管理提供科学依据。
多元线性回归基本原理

在进行多元线性回归前,首先需要进行数据预处理和探索性分析:清洗数据、处理缺失值和异常值,确保数据的准确性;此外,根据需要对数据进行标准化或归一化处理,以消除不同尺度带来的影响,并检验残差的正态性和同方差性,从而保证模型假设得以满足,为构建稳健的回归模型做好充分准备。
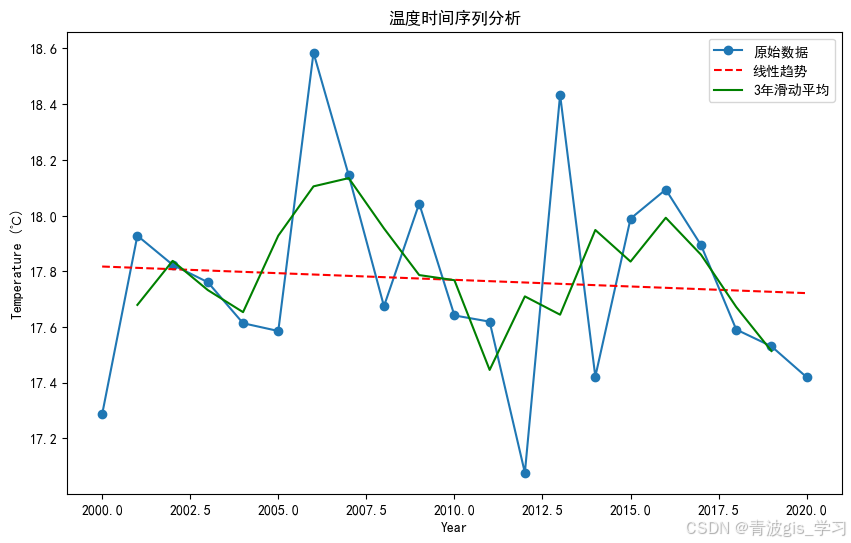
首先进行线性检验。
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
data = {'Year': np.arange(2000, 2021),
'Temperature': [17.28676471,17.92764706,17.82323529,17.76058824,17.61352941,17.58558824,18.58411765,18.14411765,17.67441176,18.04294118,17.64147059,17.61911765,17.07705882,18.43323529,17.42205882,17.98882353,18.09323529,17.89382353,17.59088235,17.53058824,17.41970588
]}
df = pd.DataFrame(data)
# 线性回归计算
X = df['Year'].values.reshape(-1, 1)
y = df['Temperature'].values
model = LinearRegression()
model.fit(X, y)
df['Trend'] = model.predict(X)
print("线性趋势率 (每年的变化量):", model.coef_[0])
# 计算3年滑动平均
df['Moving_Avg'] = df['Temperature'].rolling(window=3, center=True).mean()
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制图形
plt.figure(figsize=(10,6))
plt.plot(df['Year'], df['Temperature'], 'o-', label='原始数据')
plt.plot(df['Year'], df['Trend'], 'r--', label='线性趋势')
plt.plot(df['Year'], df['Moving_Avg'], 'g-', label='3年滑动平均')
plt.xlabel('Year')
plt.ylabel('Temperature (℃)')
plt.title('温度时间序列分析')
plt.legend()
plt.show()
然后检查各因子之间的线性关系和分布情况,并通过相关性分析和散点图检测是否存在多重共线性问题;
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取 Excel 数据
df = pd.read_excel("F:/分析/2000a.xlsx", sheet_name=0)
# 选择 X 因子
x_factors = df[["海拔_米_", "经度", "纬度", "SLOPE", "LST", "NDVI"]]
# 计算相关系数矩阵
corr_matrix = x_factors.corr()
# 输出相关系数矩阵
print("X因子之间的相关系数矩阵:")
print(corr_matrix)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm", fmt=".3f", square=True,
cbar_kws={"shrink": 0.8})
plt.title("X因子相关系数矩阵")
plt.show()
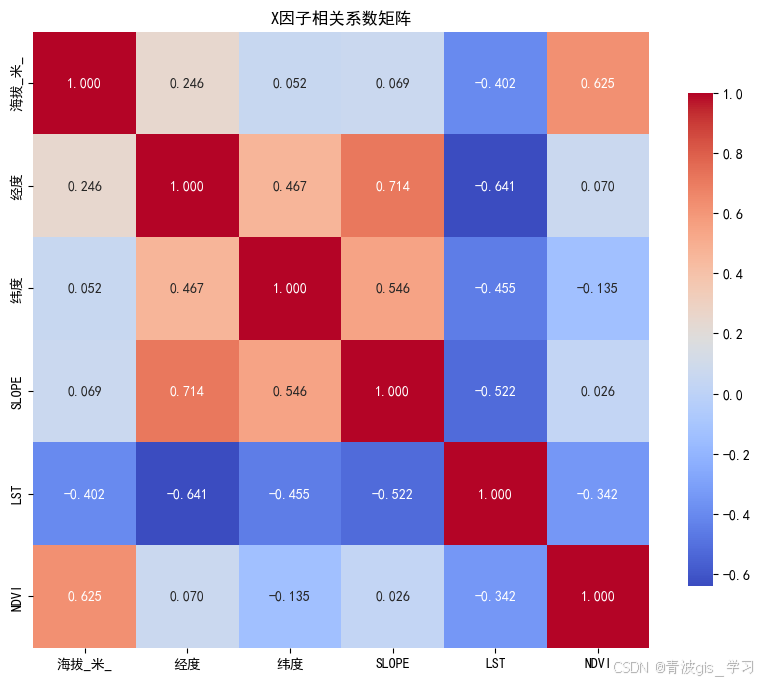
并且在构建多元线性回归模型之前检查自变量之间的多重共线性问题,即通过计算方差膨胀因子(VIF)来评估各因子是否存在较高的相关性。
import pandas as pd
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 1. 读取 Excel 数据(
df = pd.read_excel("F:/分析/2000a.xlsx", sheet_name=0)
# 2. 选择用于计算 VIF 的自变量
X = df[["海拔_米_", "经度", "纬度", "SLOPE", "LST", "NDVI"]]
# 3. 为自变量添加常数项(如果需要计算截距对多重共线性的影响,通常建议加入常数)
X = sm.add_constant(X)
# 4. 计算每个变量的 VIF
vif_data = pd.DataFrame()
vif_data["feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print("各变量的方差膨胀因子 (VIF):")
print(vif_data)
最后从Excel导入数据,用statsmodels进行多元线性回归:选择海拔、经纬度、SLOPE、LST、NDVI作为自变量,以Y为因变量,添加截距项后拟合模型,输出详细摘要,再提取各系数生成一条清晰的回归方程,直观展示各变量影响。
回归模拟方程: T = 31.753 - 0.006h - 0.078λ - 0.093φ + 0.005SLOPE + 0.014LST - 1.428NDVI
复相关系数: 0.7924662460481695模型回归摘要中包含了回归系数、p值、R²等统计指标:
回归系数:每个自变量的系数反映了该因素单位变化时对降水量的影响。例如,若海拔的系数为负,则意味着海拔每增加一个单位,降水量倾向于减少。
p值:用于判断回归系数的统计显著性。一般来说,p值小于0.05则认为该系数具有统计显著性。
R²(决定系数):衡量模型对降水数据的解释能力,数值越接近1说明模型拟合效果越好。
通过这些指标,我们可以确认哪些变量对降水变化起到了关键作用,同时也能识别模型存在的不足(如未捕捉到非线性关系或变量遗漏问题)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









