






最近Ultralytics 公司发布了 YOLOv11,这一最新一代实时目标检测器在之前 YOLO 版本的基础上进行了升级。YOLOv11 不仅继续优化目标检测功能,还扩展了对目标追踪、实例分割、图像分类和姿态估计等多项任务的支持,进一步增强了其在各类计算机视觉应用中的表现与灵活性。
与前几版本YOLO不同,这一版本是Ultralytics公司自行研制,在性能上都表现了卓越的性能。

主要功能:
增强型特征提取:YOLOv11 采用改进的骨干网络和颈部架构,显著提升了特征提取能力,带来了更精确的目标检测和处理复杂任务的更高性能。
优化效率与速度:通过创新的架构设计和优化的训练管道,YOLOv11 提供了更快速的处理速度,同时在准确性与性能之间保持了最佳平衡。
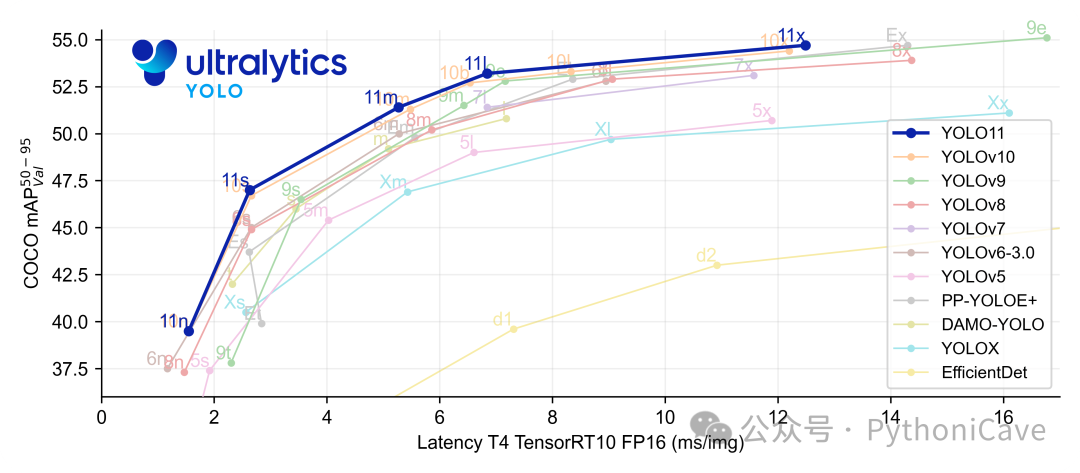
参数更少,精度更高:得益于设计的优化,YOLOv11m 在 COCO 数据集上实现了更高的平均精度(mAP),同时其参数量比 YOLOv8m 减少了 22%,在不影响精度的情况下大幅提升了计算效率。
跨环境适应性:YOLOv11 可以无缝部署于多种环境,包括边缘设备、云平台以及支持 NVIDIA GPU 的系统,确保其灵活性和可扩展性。
广泛的任务支持:无论是目标检测、实例分割、图像分类、姿态估计,还是面向对象检测(OBB),YOLOv11 都能够应对各类计算机视觉任务,展现出强大的多任务处理能力。
并且YOLOv11也推出了不同的型号,来支持不同的应用场景
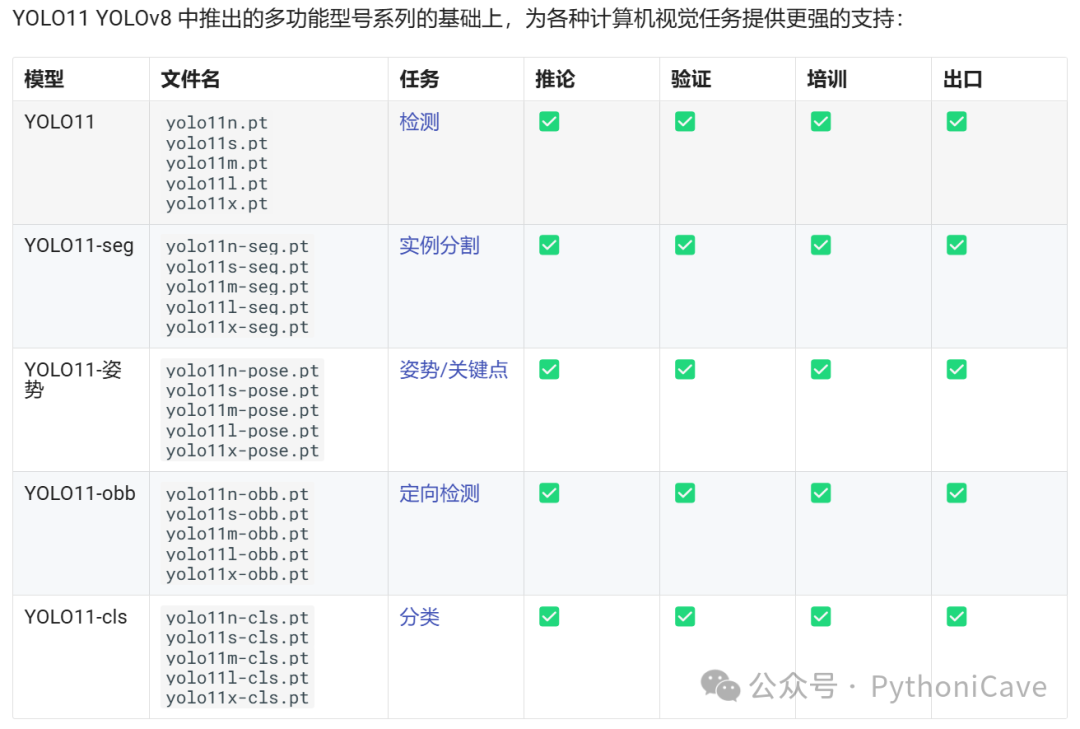
今天就按照官方文档全程过一遍训练流程,大家可以按照自己的数据去训练这个流程。

yolo环境需要torch支持,本次训练使用torch2.0.1,GPU:4060。
在官方Download文件,或者git clone到本地。解压后发现其自带一堆数据集。

解压yolo模型后需要安装ultralytics库
pip install ultralytics安装完成库后可以直接开始训练自己的数据集了,本次训练采用东北大学的NEU-DET钢材缺陷数据集。有需要的小伙伴可以关注一下后台私我。
确保自己的文件是这种格式,并且要建立data.yaml文件告诉yolo模型数据位置。
├─train│ ├─images│ └─labels└─valid├─images└─labels
data.yaml文件:
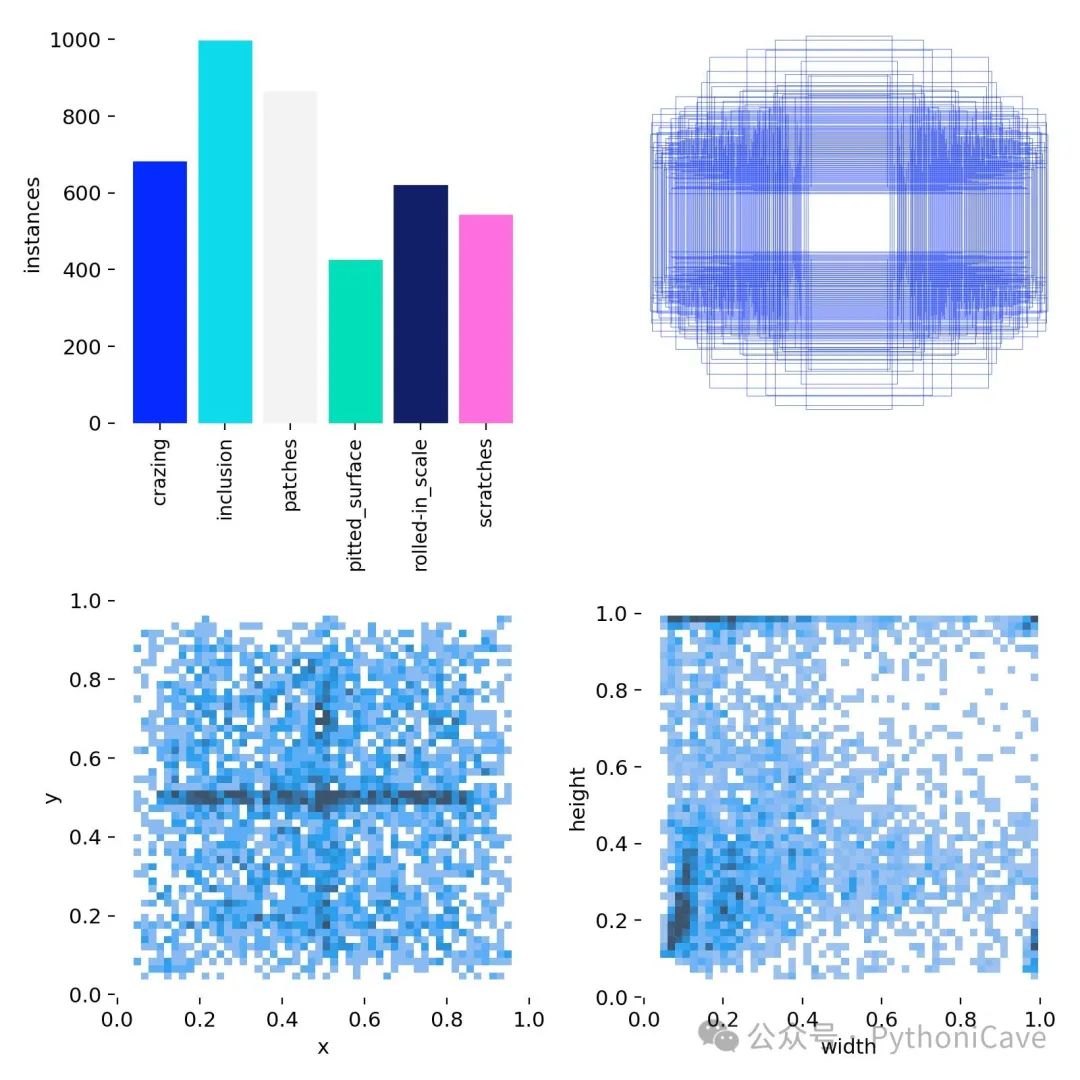
train: E:\NEU-DET\NEU-DET\train\images # 训练数据集路径val: E:\NEU-DET\NEU-DET\valid\images # 验证数据集路径nc: 6 # 类别数names: ['crazing', 'inclusion', 'patches', 'pitted_surface', 'rolled-in_scale', 'scratches'] # 类别名称
在vscode中输入下面一行代码,这是官方给的代码,可以看一下各个参数的意义
yolo detect train data=coco.yaml model=yolov10n/s/m/b/l/x.yaml epochs=500 batch=256 imgsz=640 device=0,1,2,3,4,5,6,7yolo detect train:启动目标检测模型训练。
data=coco.yaml:指定数据集配置,使用 COCO 数据集。
model=yolov10n/s/m/b/l/x.yaml:选择 YOLOv11 的不同模型版本(n, s, m, b, l, x 代表不同规模的模型)。
epochs=500:训练 500 个周期。
batch=256:每批次 256 张图像。
imgsz=640:输入图像尺寸为 640x640。
device=0,1,2,3,4,5,6,7:在多个 GPU(设备编号 0 到 7)上并行训练。
如何训练自己的模型呢,我们可以修改一下这个代码
你可以使用官方训练好的最优权重,也可以选择官方提供的预训练模型配置文件。这里选择了最优权重 yolov11n.pt 模型作为基础。
下面就是修改好的代码,直接在终端运行即可,第一次训练可以选择10个周期,device根据自己需要选择,0就是1个,每个GPU就选择device=cpu,使用cpu进行训练。
yolo detect train data=D:\yolov10-main\ultralytics\nn\modules\yolo11n.pt model=D:\yolov10-main\ultralytics\nn\modules\yolo11n.pt epochs=10 batch=16 imgsz=640 device=0这个输出列出了每一层的详细信息,包括层的类型(如 Conv、C3k2 等)、输入和输出的通道数以及其他参数(如卷积核大小、步幅等)。
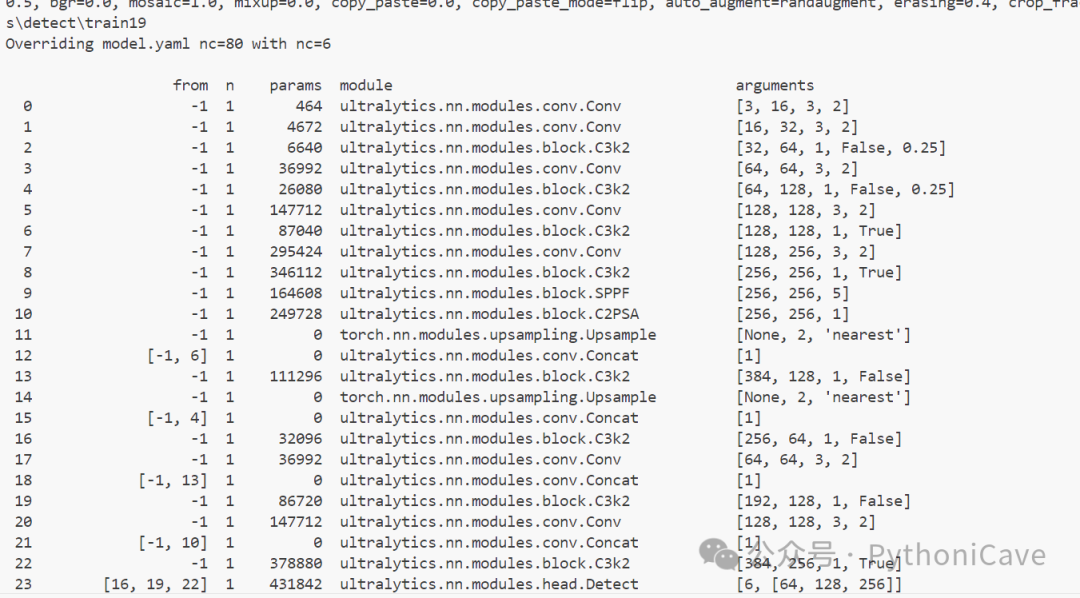
这就是正在训练了
每次听到扇叶嗡嗡的转就有成就感,不知道大家跟我是不是一样的
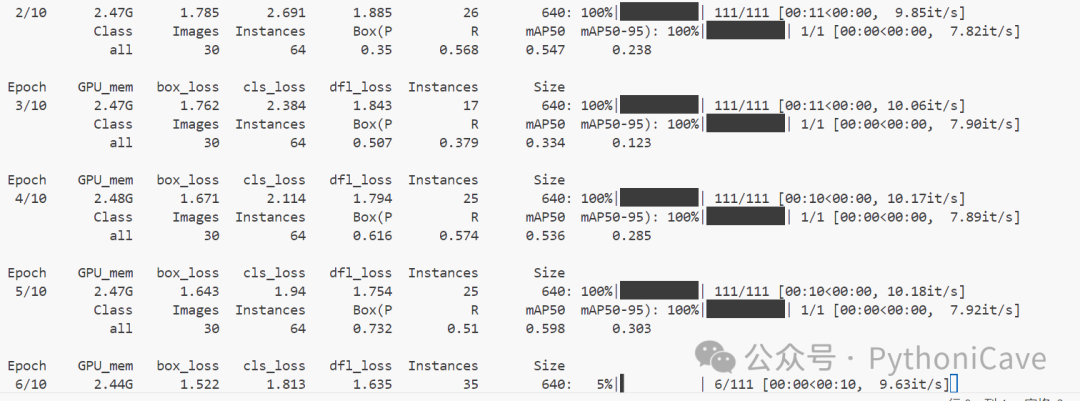
YOLO11n summary (fused): 238 layers, 2,583,322 parameters, 0 gradients, 6.3 GFLOPsClass Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<00:00, 6.08it/s]all 30 64 0.688 0.825 0.806 0.501crazing 5 8 0.552 0.625 0.505 0.185inclusion 5 15 0.484 0.8 0.743 0.448patches 5 17 0.66 1 0.972 0.655pitted_surface 5 8 0.876 1 0.995 0.707rolled-in_scale 5 9 0.857 0.666 0.728 0.383scratches 5 7 0.697 0.857 0.894 0.625Speed: 0.2ms preprocess, 1.6ms inference, 0.0ms loss, 0.6ms postprocess per image
Class:类别名称。
Images:每个类别在评估集中的图像数量。
Instances:每个类别在评估集中的目标实例数。
Box(P):预测框的精度(Precision)。
R:召回率(Recall)。
mAP50:在 IOU 阈值为 50% 时的平均精度(mean Average Precision at 50% IoU)。
mAP50-95:在多个 IOU 阈值(从 50% 到 95%)下的平均精度,通常是衡量模型精度的更全面指标。
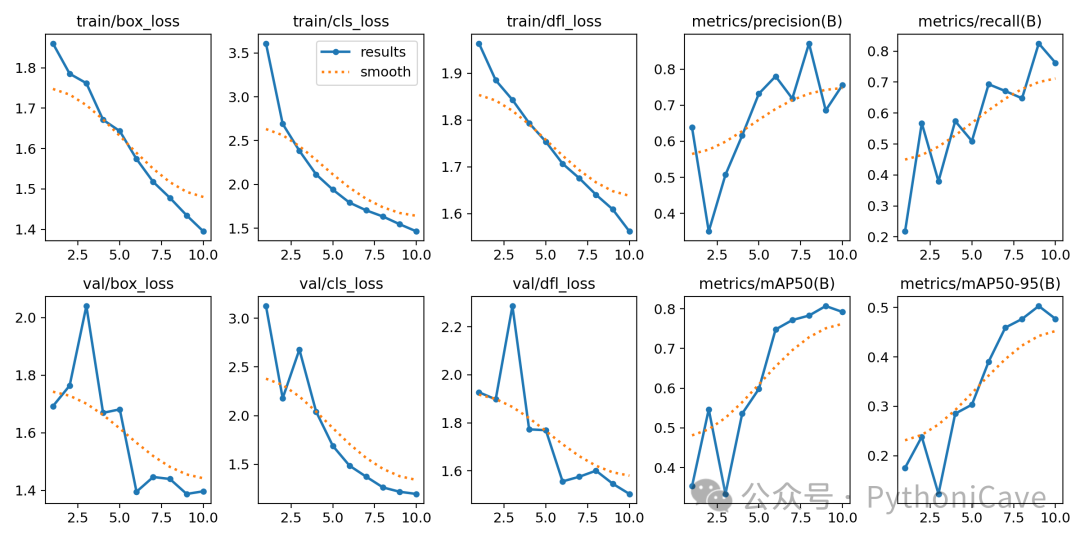
从总体指标来看,YOLOv11 在整体的 mAP50(0.806)表现较好,但在 mAP50-95(0.501)上略显不足,表示在多重 IoU 阈值下的表现不如单一阈值。
对于每个类别,表现有较大差异。像 pitted_surface 和 patches 等类别的性能相对较好,而 crazing 和 rolled-in_scale 的表现较差,尤其是在 mAP50-95 上表现较弱。
观察训练结果:


labels
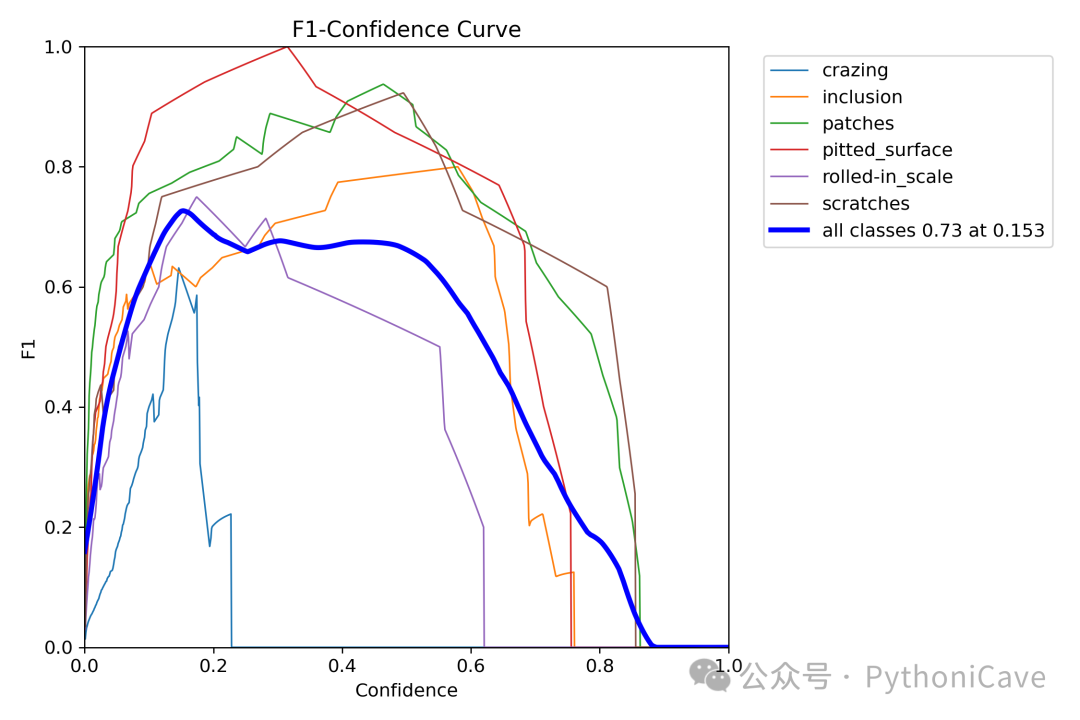
F1 Score
result
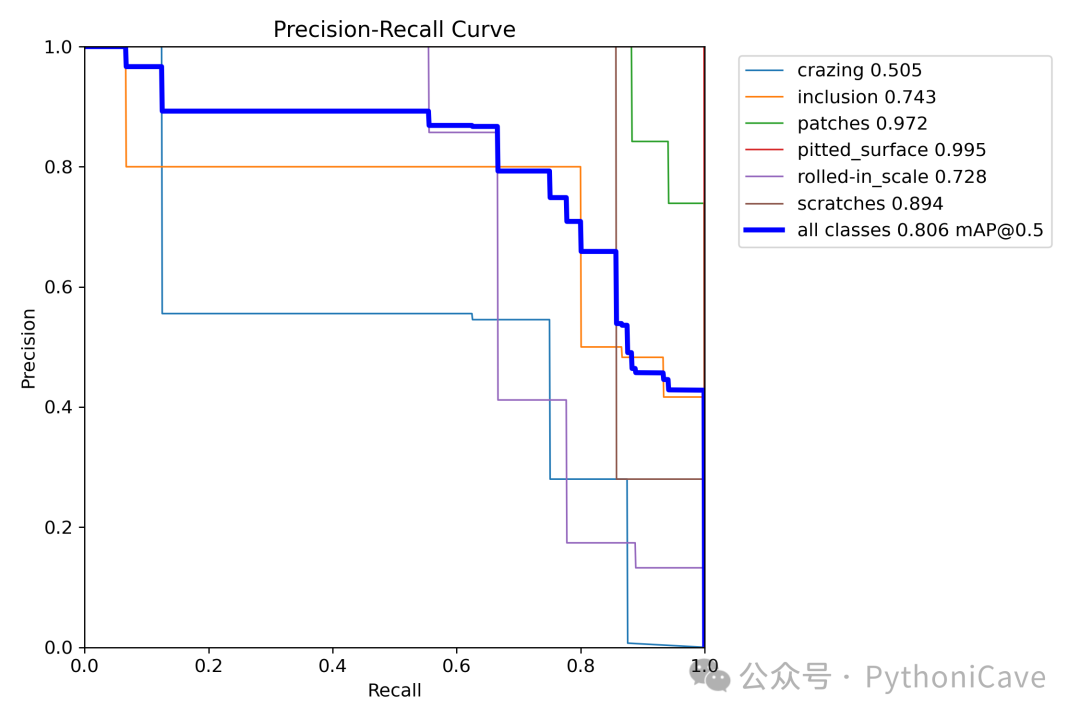
可以看出训练结果还是很棒的
需要数据和源码及权重文件的可以关注公众号PythoniCave,后台私信



















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









