






Feed流
关注推送也叫做Feed流,直译为“投喂”。为用户持续的提供“沉浸式体验”,通过无限下拉刷新获取新的信息。
Feed流(信息流)是一种常见的内容分发形式,通过动态更新的内容列表向用户展示个性化或实时信息。典型应用包括社交媒体(如微博、朋友圈)、新闻推荐(如今日头条)、短视频平台(如抖音)等。其核心是将内容按特定规则排序并持续推送给用户,提升用户粘性和参与度。
Feed流的模式

本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式实现的方案有三种:拉模式、推模式、推拉结合。
在Feed流系统中,Timeline(时间线)模式用于展示用户关注对象的动态内容,常见的实现方案包括拉模式(读扩散)、推模式(写扩散)和推拉结合模式。
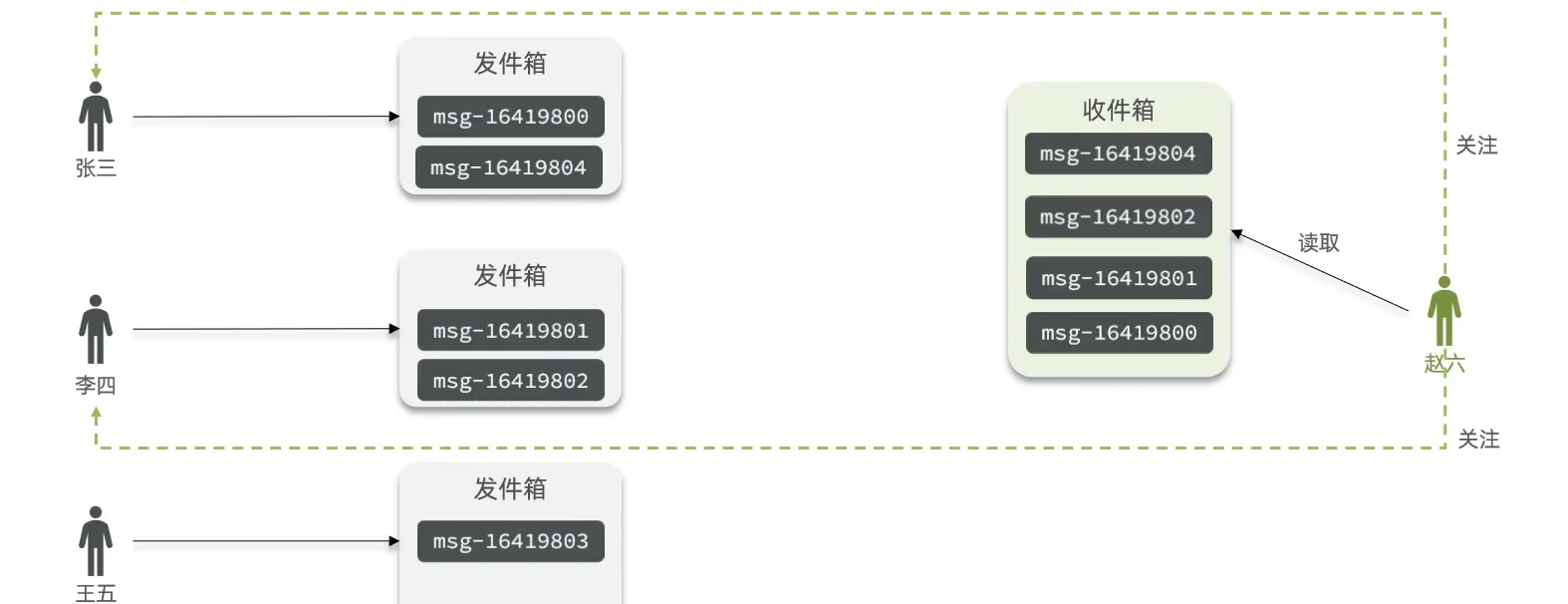
1. 拉模式(读扩散、Pull)
核心原理
-
按需拉取:当用户请求时间线时,系统实时查询其关注对象的最新内容,聚合后排序返回。
-
示例场景:用户A访问主页时,系统查询A关注的用户B、C、D的最新动态,合并后按时间倒序展示。
优点
-
写入压力小:用户发布内容只需写入自己的内容表,无需扩散。
-
存储成本低:内容仅存储一次,无冗余数据。
缺点
-
读取延迟高:每次请求需聚合多用户数据,计算开销大。
-
深分页性能差:用户翻页越深,查询效率越低(如
OFFSET 10000)。
适用场景
-
关注对象少:用户关注数较少(如<100),聚合成本可控。
-
大V场景:内容发布者粉丝量极大(如明星),避免推送海量数据。
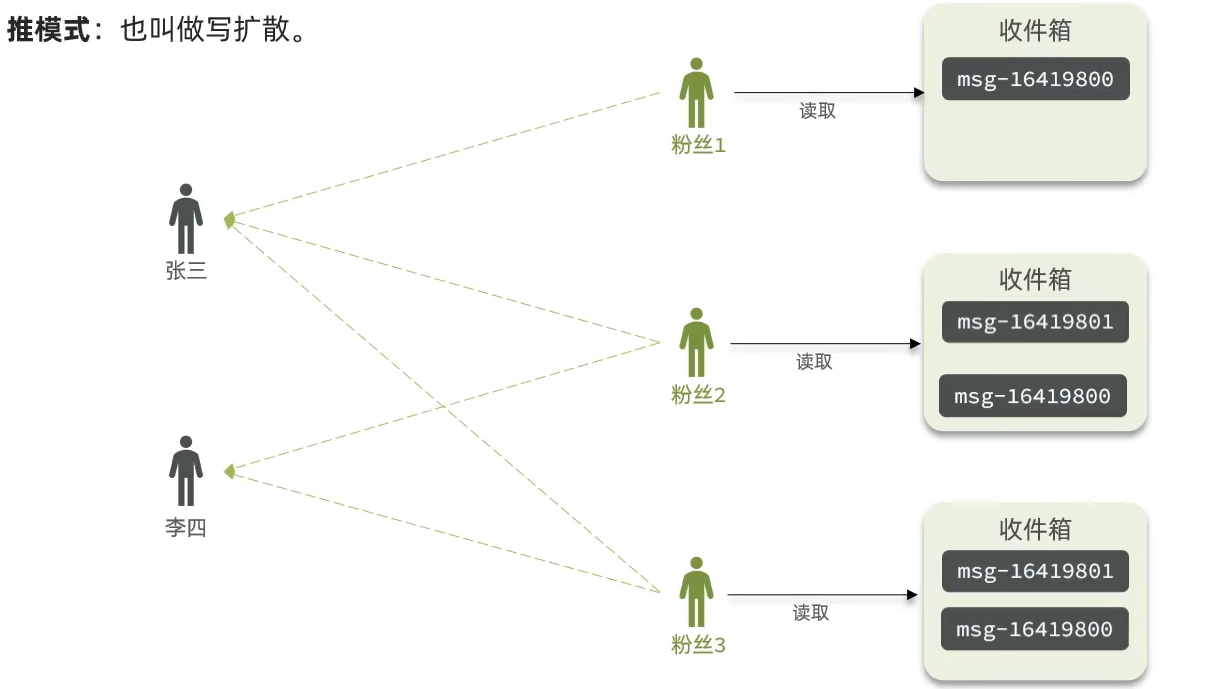
2. 推模式(写扩散、Push)
核心原理
-
预分发内容:用户发布内容时,系统立即将该内容推送到所有关注者的收件箱中。
-
示例场景:用户B发布动态,系统将该动态插入用户A、C、D的收件箱(如Redis Sorted Set)。
优点
-
读取性能高:用户访问收件箱时直接读取预排序内容,无需计算。
-
实时性强:新内容可立即出现在关注者的时间线中。
缺点
-
写入压力大:大V发布内容时需插入数百万条记录(如粉丝量百万级)。
-
存储冗余:同一内容在多个用户的收件箱中重复存储。
适用场景
-
普通用户场景:粉丝量较小(如<1万),推送成本可控。
-
强实时性需求:如社交聊天、新闻推送等需即时触达的场景。
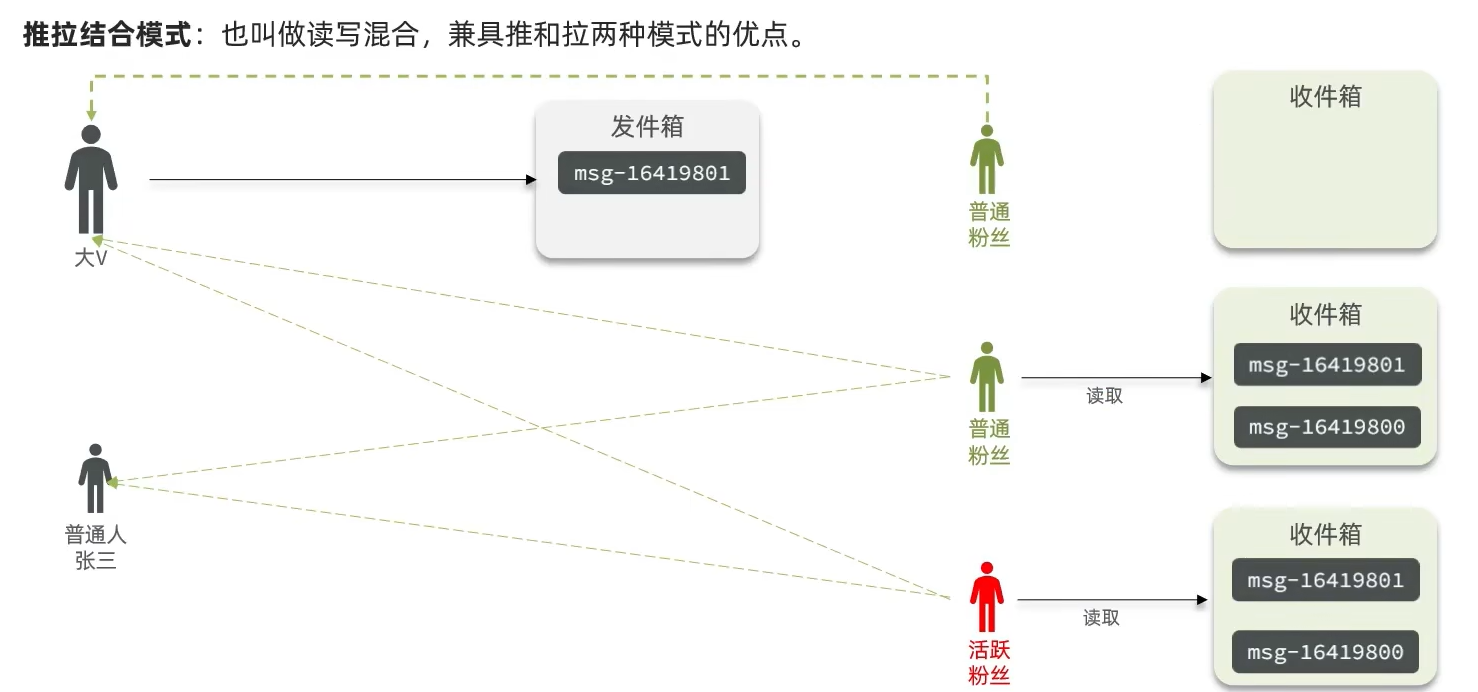
3. 推拉结合模式
核心原理
-
动态策略选择:对普通用户使用推模式,对大V使用拉模式,平衡读写压力。
-
分层处理:热数据(近期内容)推送到收件箱,冷数据(历史内容)按需拉取。
技术实现
-
用户分群:
-
普通用户:粉丝量小,发布内容时推送到所有粉丝收件箱。
-
大V用户:粉丝量大,发布内容时仅写入自己的内容表,粉丝读取时实时聚合。
-
-
冷热分离:
-
热数据:最近3天的动态推送到Redis收件箱。
-
冷数据:旧数据存储于MySQL,用户翻页时联合查询。
-
优化策略
-
动态切换阈值:根据粉丝量(如>10万)自动切换为拉模式。
-
预加载混合内容:用户首次访问时,拉取大V的近期内容并缓存,后续增量更新。
优点
-
平衡性能:普通用户享受推送的实时性,大V避免写入瓶颈。
-
灵活扩展:可根据业务增长调整推拉策略的阈值。
缺点
-
逻辑复杂:需维护两套机制(推+拉),增加代码和维护成本。
-
数据一致性:混合模式下需处理冷热数据合并的排序问题。
适用场景
-
混合型社交平台:如微博(普通用户+明星大V共存)。
-
资源敏感场景:需根据成本动态调整推送策略的业务。
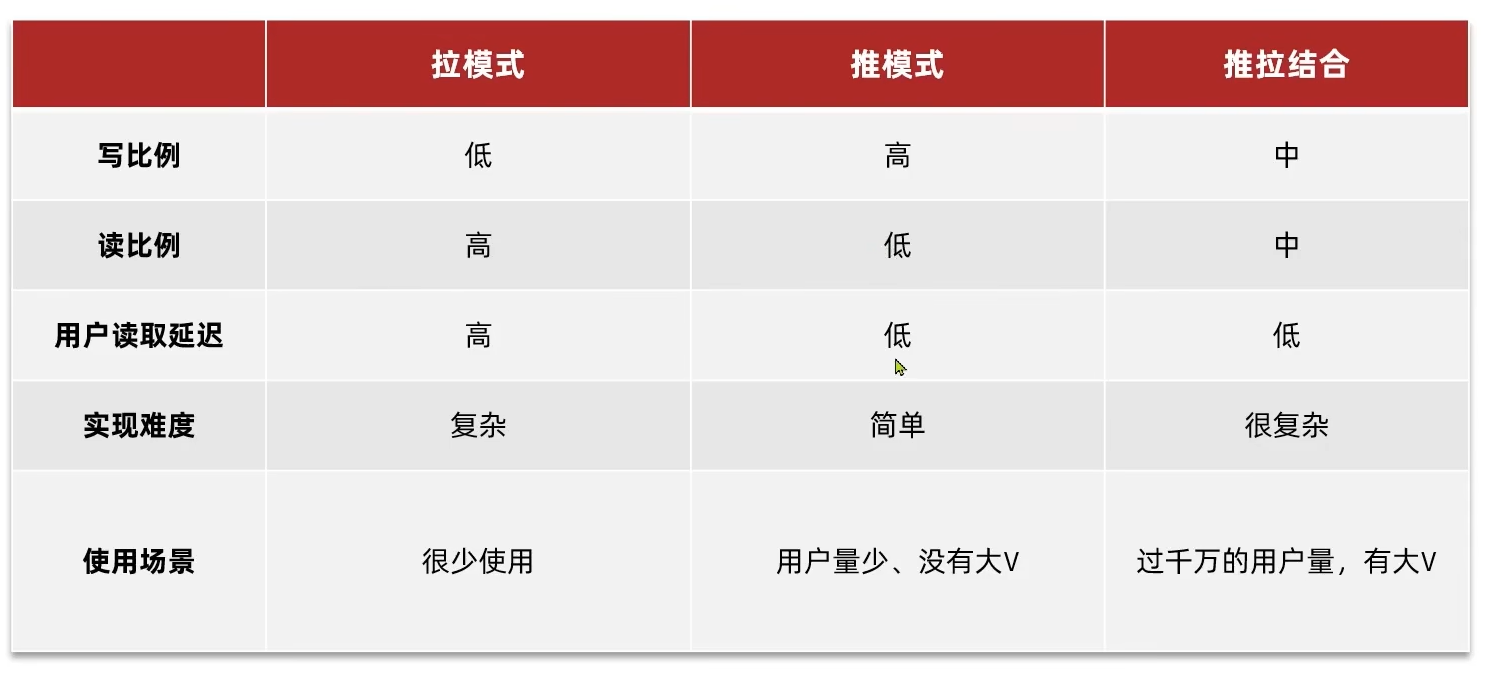
4. 小结
推送到粉丝收件箱
基于推模式实现关注推送功能

1. 为何使用推模式
(1) 业务场景适配
-
普通用户粉丝量小:
黑马点评中的用户以普通消费者为主,单个用户的粉丝量通常较小。推模式在粉丝量较少时,写入压力可控,且能保证实时性。 -
强实时性需求:
例如当用户发布探店笔记时,需即时触达粉丝,推模式通过预分发内容到粉丝收件箱(Redis),用户打开APP即可看到最新动态,无需等待实时计算。
(2) 技术优势
-
读取性能高:
用户查看收件箱时,直接访问Redis Sorted Set(按时间戳排序),时间复杂度为O(log N),远优于拉模式需要聚合多表查询的O(N)。
2. 代码实现
/**
* 新增博客
*
* @param blog
* @return
*/
public Result saveBlog(Blog blog) {
// 1.获取当前登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2.保存探店博客
boolean isSuccess = save(blog);
if (!isSuccess) {
return Result.fail("新增博客失败!");
}
// 3.查询发布博客作者的所有粉丝 select * from tb_follow where follow_user_id = ?
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 4.推送博客id给所有粉丝
for (Follow follow : follows) {
//4.1 获取粉丝id
Long userId = follow.getUserId();
//4.2 推送到粉丝收件箱(sortedSet)
String key = FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5.返回id
return Result.ok(blog.getId());
}Feed流的滚动分页
在Feed流系统中,滚动分页(也称为游标分页)是解决动态数据场景下传统分页缺陷的核心技术。
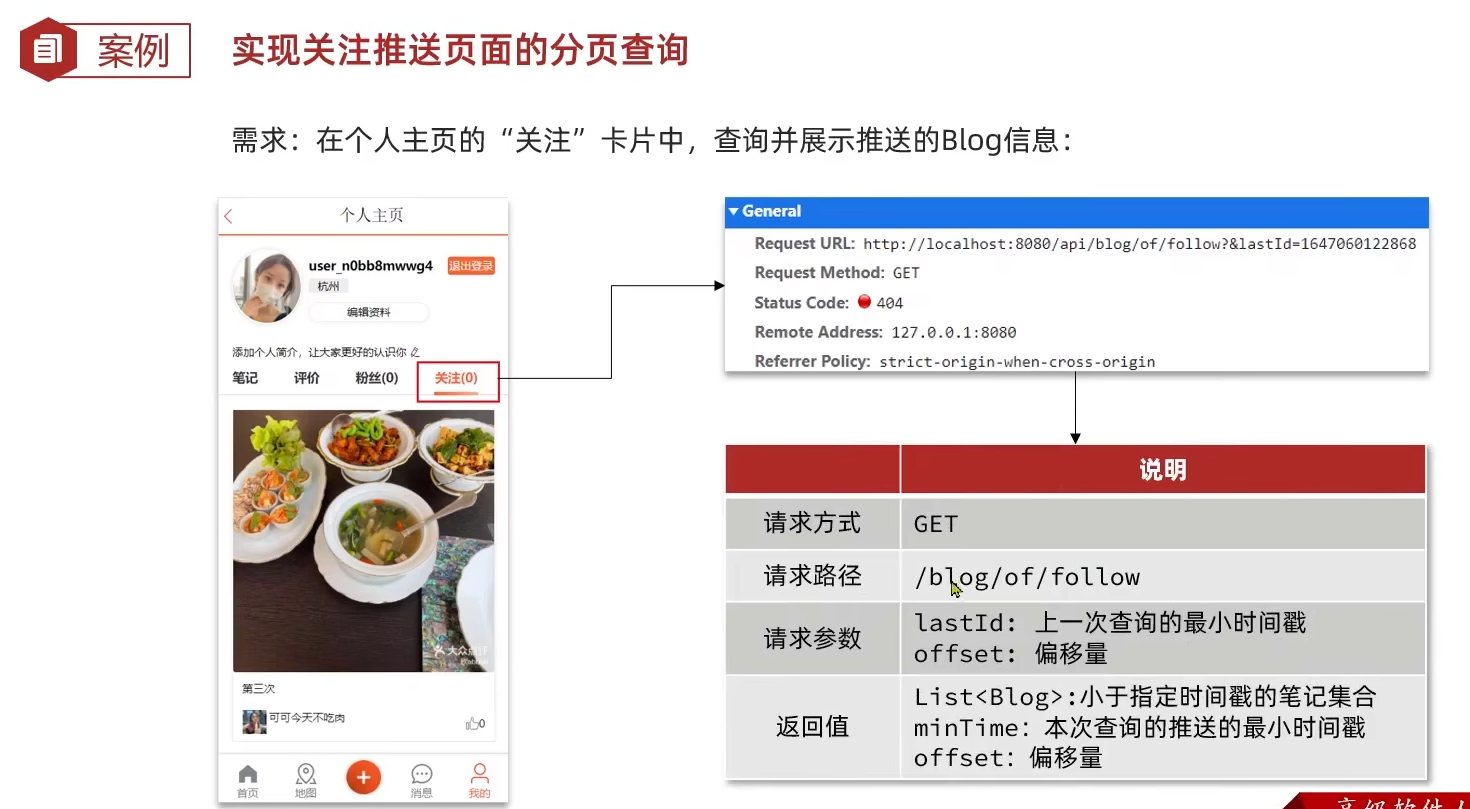
1. 为何使用滚动分页查询
(1) 动态数据场景的挑战
-
传统分页的缺陷:
使用LIMIT offset分页时,若用户翻页过程中有新数据插入(如关注对象发布新笔记),会导致后续页面数据错位(重复或遗漏)。用户无限滚动浏览动态时,避免因新数据插入导致分页重复或遗漏。 -
滚动分页的优势:
基于时间戳游标的分页(如ZREVRANGEBYSCORE命令),每次请求携带上一页最后一条数据的时间戳,确保分页稳定性。
(2) Redis Sorted Set的天然支持
-
数据结构适配:
Sorted Set以时间戳为分数(Score),动态ID为值(Value),天然支持按时间倒序排列。
分页查询时,只需使用ZREVRANGEBYSCORE指令,并指定上一次查询的终点游标。
# 示例:查询用户1001的收件箱,从时间戳1672500000开始,取10条更早的数据
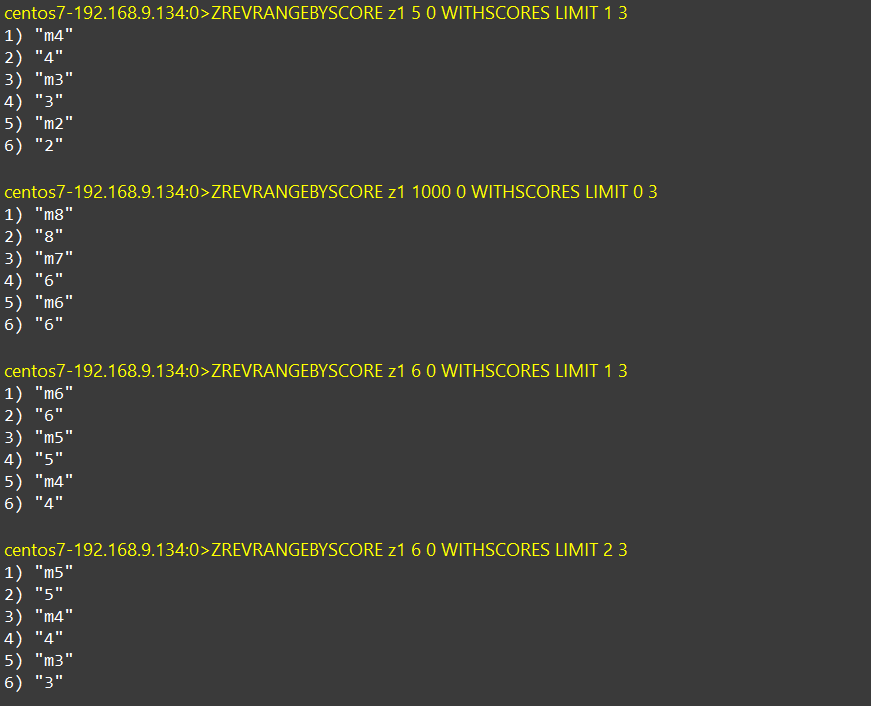
ZREVRANGEBYSCORE user:inbox:1001 1672500000 0 WITHSCORES LIMIT 0 102. 滚动分页查询参数
max(lastId):第一次查询时,为当前时间戳;否则则是上一次查询的最小时间戳
min:0
offset:第一次查询,从第一个查,值为0;否则则是在上一次查询所得结果中与最小值相同的值的个数
count:3
3. 代码实现
滚动分页查询结果返回对象:
package com.hmdp.dto;
import lombok.Data;
import java.util.List;
/**
* 滚动分页查询结果返回值对象
*/
@Data
public class ScrollResult {
//查询对象的集合
private List<?> list;
//下次查询的起始位置
private Long minTime;
//下次查询的偏移量
private Integer offset;
}
业务实现:
/**
* 查询关注用户的最新博客(滚动分页查询)
*
* @param max 上次查询的最小时间,即本次查询的最大时间
* @param offset 要跳过的最后一个时间戳相同的个数
* @return
*/
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
// 2.查询收件箱 ZREVRANGEBYSCORE(按时间戳从新到旧) key Max Min LIMIT offset count
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 3);
// 3.非空判断
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
// 4.解析收件箱数据:blogId、minTime(时间戳)、offset(即typeTuples集合里score值等于最小时间的最后元素的个数)
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0;
int os = 1;
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {
// 4.1 获取id
String idStr = tuple.getValue();
ids.add(Long.valueOf(idStr));
// 4.2 获取分数(时间戳)
long time = tuple.getScore().longValue();
if (time == minTime) {
os++;
} else {
minTime = time;
os = 1;
}
}
// 5.根据博客id批量查询博客
/*
SQL逻辑:WHERE id IN (ids):按ID列表查询。
ORDER BY FIELD(id, idStr):按传入ID顺序排序,保持与 Redis 查询结果一致
*/
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
// 查询博客的相关信息
for (Blog blog : blogs) {
// 5.1 查询blog有关的用户
queryBlogUser(blog);
// 5.2 查询blog是否被点赞
isBlogLiked(blog);
}
// 6.封装并返回(供下一次分页使用)
ScrollResult scrollResult = new ScrollResult();
scrollResult.setList(blogs); // 当前页的博客列表
scrollResult.setMinTime(minTime); // 当前页最后一条数据的时间戳,用于下一次请求的max参数
scrollResult.setOffset(os); //当前页最后一条数据在相同时间戳内的偏移量,用于下一次请求的 offset 参数
return Result.ok(scrollResult);
}
















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









