










既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
}
return l;
}
每次二分需要将 **每行中`1`的个数** 和 **当前行数** 存储到对应的空间中。
所以我们可以定义一个结构体,用来专门存放两种类型的数据:
typedef struct data
{
int combat; // 战斗力
int row; // 行数
}data;
紧接着动态开辟一个结构体数组 `tmp` ,用来存储数据;一个 `k` 个大小的数组 `res` 作为返回的数组。
**在二分的过程中**:
* 如果二分出来的边界点的值 **不等于 1** ,说明二分结果错误,那么此行战斗力 `combat` 为 0 ,存到正确位置
* 如果二分出来的边界点的值 **等于 1** ,说明二分结果正确,将 `l(r) + 1` 存入结构体数组的对应位置
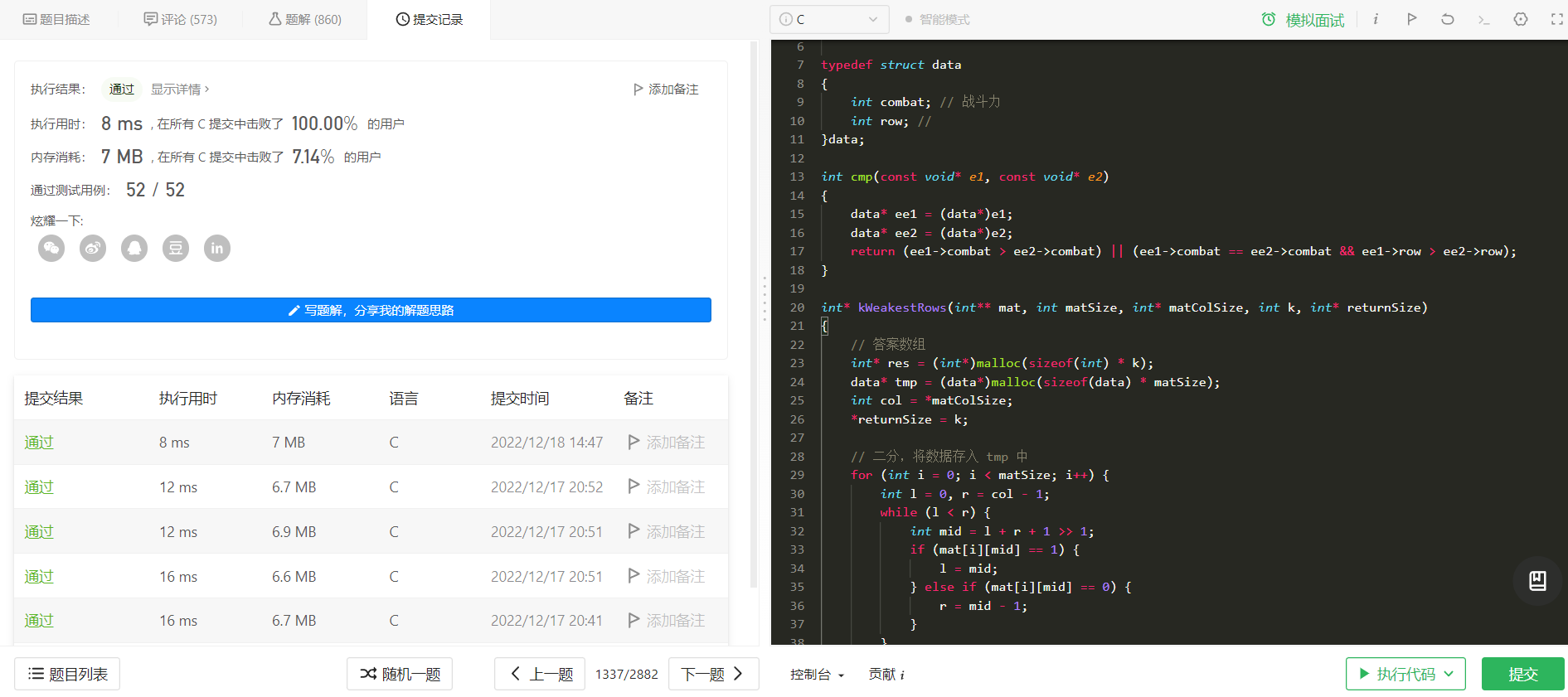
有了结构体数组,那么进行排序就好了,这里直接使用 `qsort` ,注意需要处理一下 **特殊情况** :**第 `i` 行和第 `j` 行 1 的数量相同,但是 `i < j` 那么认为 第 `i` 行的战斗力 比第 `j` 行弱** 。
最后将数据存入返回数组中,返回即可。
过程相对简单,直接上代码:
typedef struct data
{
int combat; // 战斗力
int row; // 行
}data;
int cmp(const void* e1, const void* e2)
{
data* ee1 = (data*)e1;
data* ee2 = (data*)e2;
// 战斗力大小 或 战斗力相等 行数不同
return (ee1->combat > ee2->combat) || (ee1->combat == ee2->combat && ee1->row > ee2->row);
}
int* kWeakestRows(int** mat, int matSize, int* matColSize, int k, int* returnSize)
{
// 答案数组
int* res = (int*)malloc(sizeof(int) * k);
data* tmp = (data*)malloc(sizeof(data) * matSize);
int col = *matColSize;
*returnSize = k;
// 二分,将数据存入 tmp 中
for (int i = 0; i < matSize; i++) {
int l = 0, r = col - 1;
while (l < r) {
int mid = l + r + 1 >> 1;
if (mat[i][mid] == 1) {
l = mid;
} else if (mat[i][mid] == 0) {
r = mid - 1;
}
}
if (mat[i][l] != 1) {
tmp[i].combat = 0; // 无战斗力
} else {
tmp[i].combat = l + 1;
}
tmp[i].row = i; // 存入索引
}
qsort(tmp, matSize, sizeof(data), cmp);
for (int i = 0; i < k; i++)
{
res[i] = tmp[i].row;
}
return res;
}
### 2. 二分 + 堆
这种方法其实是我第一次就想到的,但是中途调试了很久,觉得这种思路比排序难一些就把它放到第二个。
先讲常规操作:
这里我们采用的存储结构是用 **二维数组** ,将其定义为全局变量 `int heap[100][2]` :

将每一行看作是一个元素,存放 **战斗力** 和 **索引** 。
开辟一个 `ans` 作为返回数组。
紧接着就是二分,并将元素 **战斗力存入二维数组每行的 `0` 下标处**,将 **行的索引存入二维数组每行的 `1` 下标处** 。
准备工作完成,接下来开始讲解剩余步骤。
我想到堆的原因就是因为之前的堆排序和TopK当时我看了很久,看这道题题目我就觉得可以用堆解决。
之前说过建堆的优先级是 **向下调整建堆 > 向上调整建堆** ,我们当前使用 **向下调整算法** 来构建一个大小为矩阵的行数的 **小堆** 。
直接使用 `heap` 这个全局数组,以它为基准来建堆。
就拿我们 *示例1* 给出的矩阵计算出的结果作为堆中的数据,计算结果为:
* `heap[0][0] = 2 heap[0][1] = 0`
* `heap[1][0] = 4 heap[1][1] = 1`
* `heap[2][0] = 1 heap[2][1] = 2`
* `heap[3][0] = 2 heap[3][1] = 3`
* `heap[4][0] = 5 heap[4][1] = 4`
将其写成堆的样子:

接着就是写 **向下调整算法** ,向下调整算法需要注意几点:
* 小堆是由 **战斗力强弱** 起主要衡量,战斗力相等需要看行之间的关系
* 构建的是小堆,每次交换的是最小孩子
* 求最小孩子时,需要额外判断战斗力相等时的情况
* 判断调整时也需要判断战斗力相等的情况
* 交换数据时,由于这里是二维数组,所以是交换一行的数据,传参传每行的地址,交换函数的参数要写成二级指针
**构建过程**:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hU59fTsu-1671350627615)(https://anduin.oss-cn-nanjing.aliyuncs.com/image-20221218155334931.png)]](https://img-blog.csdnimg.cn/c5657373cd1c4275b373420a0d36cb4b.png#pic_center)
**最后我们需要 *索引* 放入返回数组中**:
主要方法是给定一个 `end` 等于 **当前堆的行数** 。
在循环 `k` 次,先将 **二维数组第一行第二列的元素** 存入返回数组 `ans` 中,然后交换堆顶和堆底的元素。
向下调整重新建堆,将 `end--` ,每次丢弃堆中1个元素,最后 `ans` 中的结果就是战斗力最弱的 `K` 行 。
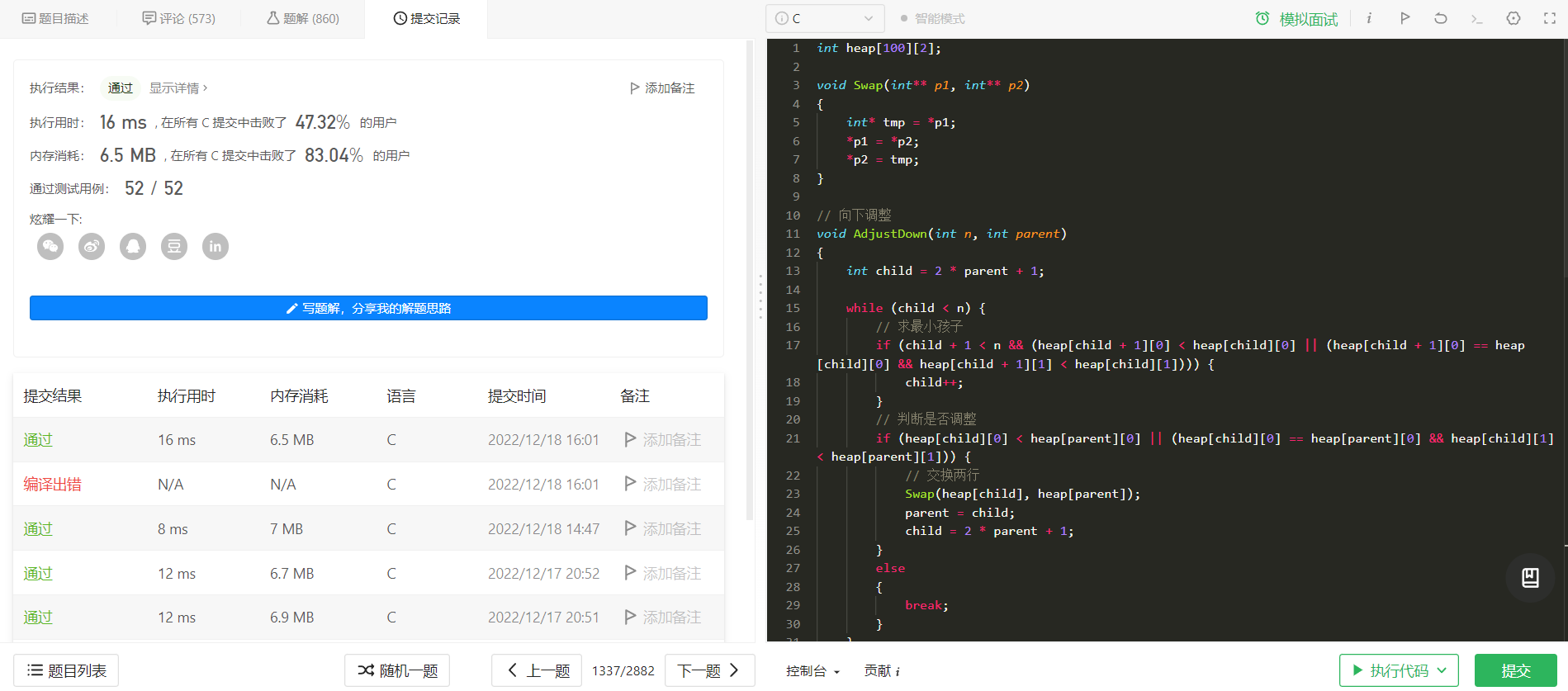
接下来看看代码怎么写:
int heap[100][2];
void Swap(int** p1, int** p2)
{
int* tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 向下调整
void AdjustDown(int n, int parent)
{
int child = 2 * parent + 1;
while (child < n) {
// 求最小孩子
if (child + 1 < n && (heap[child + 1][0] < heap[child][0] || (heap[child + 1][0] == heap[child][0] && heap[child + 1][1] < heap[child][1]))) {
child++;
}
// 判断是否调整
if (heap[child][0] < heap[parent][0] || (heap[child][0] == heap[parent][0] && heap[child][1] < heap[parent][1])) {
// 交换两行
Swap(heap[child], heap[parent]);
parent = child;
child = 2 \* parent + 1;
} else {
break;
}
}
}
int* kWeakestRows(int** mat, int matSize, int* matColSize, int k, int* returnSize)
{
int cnt = 0;
*returnSize = k;
for (int i = 0; i < matSize; i++) {
// 将 k 行元素的索引存入 heap 中
int l = 0, r = *matColSize - 1;
while (l < r) {
int mid = l + r + 1>> 1;
if (mat[i][mid] == 0) {
r = mid - 1;
}
if (mat[i][mid] == 1) {
l = mid;
}
}
// 0 下标处存战斗力
// 1 下标处存索引
if (mat[i][l] != 1)
{
heap[cnt][0] = 0;
} else {
heap[cnt][0] = l + 1;
}
heap[cnt][1] = i;
cnt++;
}
// 将 res 数组中元素建小堆,不断取出堆顶元素
int\* ans = (int\*)malloc(sizeof(int) \* k);
for (int i = (cnt - 1 - 1) / 2; i >= 0; i--) {
// 向下调整堆中元素
AdjustDown(cnt, i);
}
int end = cnt - 1, j = 0;
while (k > 0) {
// 将索引存入 ans 数组
ans[j++] = heap[0][1];
Swap(heap[0], heap[end]);
AdjustDown(end--, 0);
k--;
}
return ans;
}
>
> **完结撒花 🌹**
>



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
转存中...(img-H1LQHCOf-1715055177874)]
[外链图片转存中...(img-cguvR3gq-1715055177875)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









