







 本文提供了一套全面的Linux运维学习资料,包括基础知识、进阶课程、健康检查方法、worker进程设置、高并发处理和Nginx配置技巧,旨在帮助程序员高效系统化学习和提升技能。
本文提供了一套全面的Linux运维学习资料,包括基础知识、进阶课程、健康检查方法、worker进程设置、高并发处理和Nginx配置技巧,旨在帮助程序员高效系统化学习和提升技能。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

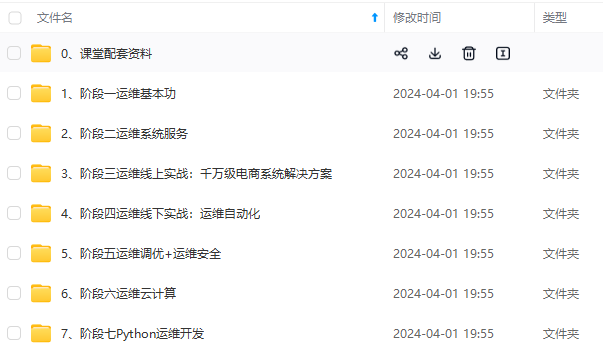
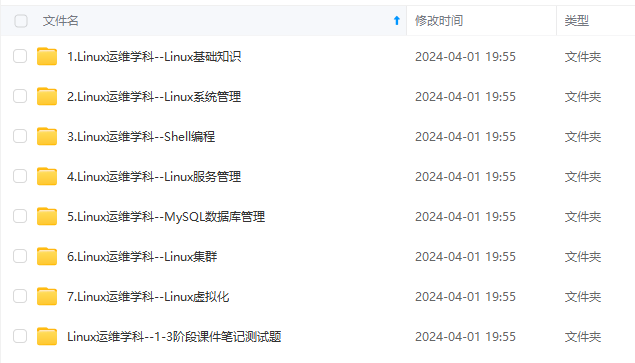
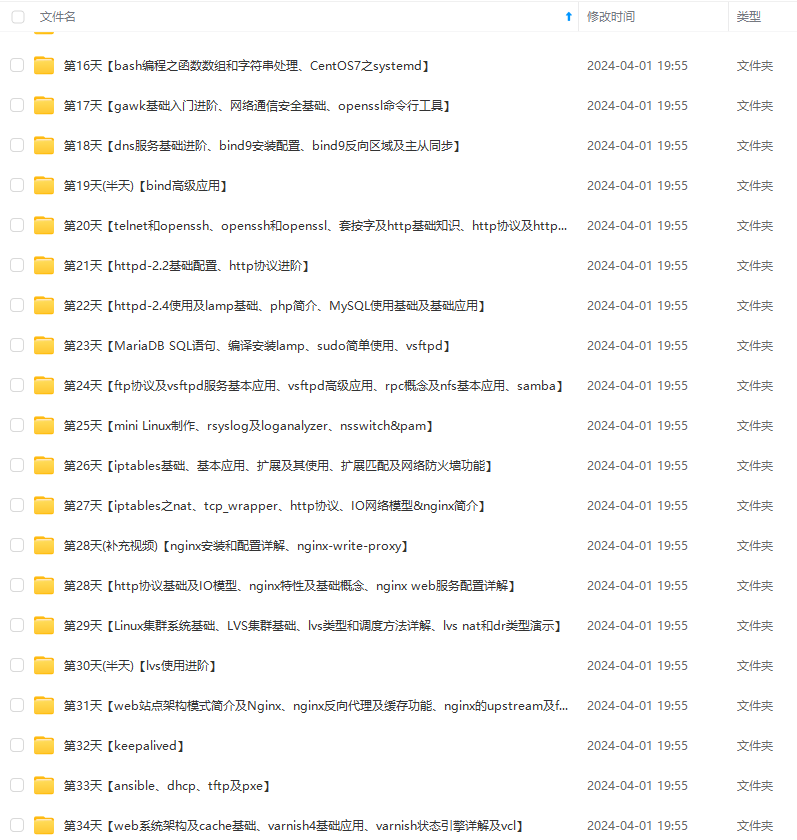
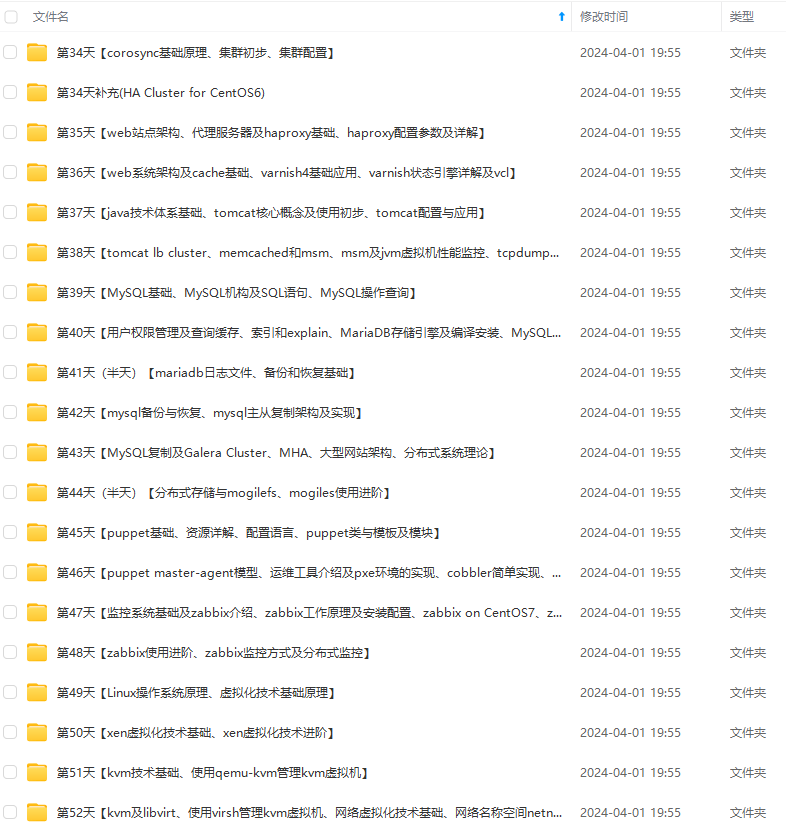
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
upstream backserver {
server 192.168.0.1;
server 192.168.0.2;
}
* weight(加权轮询)
指带权重值的轮询算法,weight值越大,分配到的概率也就越高
主要用于后端每台服务器性能不均衡的情况,或者说仅仅为在主从的情况下设置不同的权重(weight)值,可以有效的利用服务器资源
权重越高,在被访问的概率越大。如例,分别是20%,80%。
upstream backserver {
server 192.168.0.1 weight=2;
server 192.168.0.2 weight=8;
}
* ip\_hash(ip绑定)
将来自于同一个源ip地址的请求始终分发到第一次分配到的后端服务器
upstream backserver {
ip_hash;
server 192.168.0.1;
server 192.168.0.2;
}
* url\_hash(url哈希)
按照访问的url的哈希结果来进行分配,每个相同请求的url会被定向到某一台后端服务器,进一步提高后端服务器缓存的效率
如果要使用这种算法,则需要安装Nginx的hash软件包
upstream backserver {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}
* fair(智能调度)
以根据后端服务器的响应请求时间智能地进行均衡分发,比如说响应时间短的优先分配。如果要使用这种算法,则需要安装upstream\_fair模块
哪个服务器的响应速度快,就将请求分配到那个服务器上。
upstream backserver {
server server1;
server server2;
fair;
}
**能聊聊location吗**
location的作用是根据用户请求的URI来执行不同的应用,也就是根据用户请求的网站URL进行匹配,匹配成功即进行相关的操作
* location优先级
| 匹配符 | 匹配规则 | 优先级 |
| --- | --- | --- |
| = | 精确匹配 | 1 |
| ^~ | 以某个字符串开头普通匹配 | 2 |
| ~ | 区分大小写的正则匹配 | 3 |
| ~\* | 不区分大小写的正则匹配 | 4 |
| !~ | 区分大小写不匹配的正则 | 5 |
| !~\* | 不区分大小写不匹配的正则 | 6 |
| / | 普通匹配,任何请求都会匹配到 | 7 |
* location匹配规则
首先精确匹配优先级最高,如果没有精确匹配的话就进行普通匹配,然后**保存**具有最长匹配前缀的结果(注意这里是保存,而不是匹配完成)
保存结果后开始正则匹配,如果有正则匹配则按照配置里正则表达式出现的顺序进行匹配(匹配最先出现那个),匹配到之后返回正则匹配结果
如果没有正则匹配就返回具有最长匹配前缀的结果(即一开始保存那个)
PS:如果最长匹配前缀有\*\*^~\*\*,则忽略正则匹配,直接返回结果
**Nginx如何实现后端服务健康检查**
* 利用 nginx 自带模块 ngx\_http\_proxy\_module 和 ngx\_http\_upstream\_module 对后端节点做健康检查
* 利用 nginx\_upstream\_check\_module 模块对后端节点做健康检查(**推荐使用这个**)
**生产中如何设置worker进程的数量呢**
推荐设置成auto模式,即根据系统CPU个数来自动分配worker进程
## Nginx 如何处理高并发
在Nginx里面,一般我们使用**异步非阻塞处理请求方式+epoll机制的IO多路复用网络I/O模型**
**什么是异步同步,什么是阻塞非阻塞**
* 异步:程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序
* 同步:程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应
* 阻塞:程序执行I/O操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务
* 非阻塞:程序执行I/O操作后,不会阻塞当前线程,可以继续执行其他任务,随后通过轮询或者事件通知的形式获取调用的结果
在Nginx里面,每个worker进程接收到客户端的请求之后,会进行相关的操作然后等待响应/结果,在等待的这个过程中worker进程是可以去处理其他请求的(非阻塞)
而Nginx客户端这时候也无需等待,可以去处理其他事件(异步)
如果响应/结果返回,就会通知worker进程(事件通知),这时候worker就会去返回处理请求
**I/O事件通知**
在介绍I/O多路复用之前,我们先来看一下I/O事件通知
I/O事件通知可分为水平触发(Level Trigger)和边缘触发(Eage Trigger)
* 水平触发(LT)
**文件描述符的状态没有改变(可以非阻塞的执行I/O),就会触发通知**。也就是说,应用程序可以随时检查文件描述符的状态,然后再根据状态,进行 I/O 操作
读操作:
1. 读缓冲区中有数据,且数据被读出一部分缓冲区还不为空
写操作:
1. 写缓冲区还没满,还能继续写
* 边缘触发(ET)
**只有在文件描述符的状态发生改变(也就是 I/O 请求达到)时,才发送一次通知**。
这时候,应用程序需要尽可能多地执行 I/O,直到无法继续读写,才可以停止。
如果 I/O 没执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了
读操作:
1. buffer由不可读状态变为可读状态(由空变为不空)
2. 当有新数据到达时,即缓冲区中的待读数据变多的时候
3. 当缓冲区有数据可读,且应用进程对相应的描述符进行`EPOLL_CTL_MOD` 修改`EPOLLIN`事件时
写操作:
1. buffer由不可写变为可写(由空变为不空)
2. 缓冲区中的内容变少(有数据被发送走)
3. 当缓冲区有空间可写,且应用进程对相应的描述符进行`EPOLL_CTL_MOD` 修改`EPOLLOUT`事件时
**IO多路复用**
I/O多路复用也就是我们见到的select、poll、epoll
* select和poll
selct和poll均采用**非阻塞I/O+水平触发通知**
selct和poll从文件描述符中找出哪些可以进行I/O操作,然后执行,由于是非阻塞I/O,一个线程可以**同时监控一批套接字的文件描述符**,就达到了单线程处理多请求的目的
但是selct和poll是对套接字的文件描述符列表进行**轮询**,请求多的时候就会比较耗时
而且程序每次调用select和poll时,需要把fd列表从用户空间传入内核空间,内核修改后再传出用户空间,消耗了两次系统调用,增加了处理成本
select使用固定长度的数组来表示fd的集合,所以会有最大描述符数量的限制,但是poll使用pollfd指针,没有最大描述符数量的限制(优于select)
* epoll
epoll使用红黑树,在内核中管理fd的集合,相较于select和poll少了两次系统调用,减少成本
epoll使用**事件驱动**的机制,而非select和poll的轮询;只关注有I/O事件发生的fd
由于epoll采用**边缘触发通知机制**,当有边缘触发时,应用程序就需要尽可能地多执行I/O
#为什么边缘触发机制下一旦有通知程序要尽可能I/O?
因为边缘触发的原理是文件描述符的状态发生改变才会触发通知,之后便不再触发

最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
x系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-HdvQfczR-1713386308304)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









