






第1关:Pandas数值运算方法
任务描述
本关任务:获取鸢尾花数据集前30行并转换成DataFrame,然后让每一行都减去第一行的值,输出运算后的结果。
相关知识
Pandas在数值运算方面继承了NumPy的通用函数等功能,实现了一些高效技巧。
通用函数:保留索引
因为Pandas是建立在NumPy基础之上的,所以NumPy的通用函数同样适用于Pandas的Series和DataFrame对象。
import numpy as np
import pandas as pd
rng = np.random.RandomState(42) #创建随机数种子
ser = pd.Series(rng.randint(0,10,4))
df = pd.DataFrame(rng.randint(0,10,(3,4)), columns=['A','B','C','D'])
# 对Series对象使用Numpy通用函数,生成的结果是另一个保留索引的Pands对象
print(np.exp(ser))
Out:0 403.428793
1 20.085537
2 1096.633158
3 54.598150
dtype: float64
# 对DataFrame使用Numpy通用函数
print(np.sin(df*np.pi/4))
Out:
A B C D
0 -1.000000 7.071068e-01 1.000000 -1.000000e+00
1 -0.707107 1.224647e-16 0.707107 -7.071068e-01
2 -0.707107 1.000000e+00 -0.707107 1.224647e-16
通用函数:索引对齐
Series索引对齐
假如你要整合两个数据源的数据,其中一个是美国面积最大的三个州的面积数据,另一个是美国人口最多的三个州的人口数据:
# 面积
area=pd.Series({'Alaska':1723337,'Texas':695662,'California':423967},name='area')
# 人口
population=pd.Series({'California':38332521,'Texas':26448193,'New York': 19651127}, name='population'})
人口除以面积的结果:
print(population/area)
Out:
Alaska NaN
California 90.413926
New York NaN
Texas 38.018740
dtype: float64
对于缺失的数据,Pandas会用NaN填充,表示空值。这是Pandas表示缺失值的方法(后面的关卡会介绍)。这种索引对齐方式是通过Python内置的集合运算规则实现的,任何缺失值默认都用NaN填充。
DataFrame索引对齐
在计算两个DataFrame时,类似的索引对齐规则也同样会出现在共同列中:
A = pd.DataFrame(rng.randint(0, 20, (2, 2)), columns=list('AB'))
"""
A:
A B
0 1 11
1 5 1
"""
B = pd.DataFrame(rng.randint(0, 10, (3, 3)), columns=list('BAC'))
"""
B:
B A C
0 4 0 9
1 5 8 0
2 9 2 6
"""
print(A + B)
Out:: A B C
0 1.0 15.0 NaN
1 13.0 6.0 NaN
2 NaN NaN NaN
从上面的例子可以发现,两个对象的行列索引可以是不同顺序的,结果的索引会自动按顺序排列。在Series中,我们可以通过运算符方法的 fill_value参数自定义缺失值;这里我们将用A中所有值的均值来填充缺失值。
fill = A.stack().mean() # stack()能将二维数组压缩成多个一维数组
print(A.add(B,fill_value=fill))
Out:
A B C
0 1.0 15.0 13.5 #NaN值都变成了均值
1 13.0 6.0 4.5
2 6.5 13.5 10.5
下表中列举了与Python运算符相对应的Pandas对象方法。
Python运算符 Pandas方法
+ add()
- sub()、subst\fract()
* mul()、multiply()
/ truediv()、div()、divide()
// floordiv()
% mod()
** pow()
通用函数:DataFrame与Series的运算
DataFrame和Series的运算规则与Numpy中二维数组与一维数组的运算规则是一样的。来看一个常见运算,让一个二维数组减去自身的一行数据。
A = rng.randint(10, size=(3, 4))
A - A[0]
Out:
array([[ 0, 0, 0, 0],
[-1, -2, 2, 4],
[ 3, -7, 1, 4]]) # 根据Numpy的广播规则,默认是按行运算的
在Pandas里默认也是按行运算的,如果想按列计算,那么就需要利用前面介绍过的运算符方法,通过设置axis(轴)实现。
df = pd.DataFrame(A, columns=list('QRST'))
print(df - df.iloc[0])
Out:
Q R S T
0 0 0 0 0
1 -1 -2 2 4
2 3 -7 1 4
print(df.subt\fract(df['R'],axis=0))
Out:
Q R S T
0 -5 0 -6 -4
1 -4 0 -2 2
2 5 0 2 7
DataFrame/Series的运算与前面介绍的运算一样,结果的索引都会自动对齐。
编程要求
本关的编程任务是补全右侧上部代码编辑区内的相应代码,要求实现如下功能:
获取鸢尾花数据集的前30行;
将数据转换为DataFrame,列名为[‘a’,‘b’,‘c’,‘d’];
最后将每一行都减去第一行的值,输出运算后的结果;
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
无测试输入
预期输出:
示例代码如下:
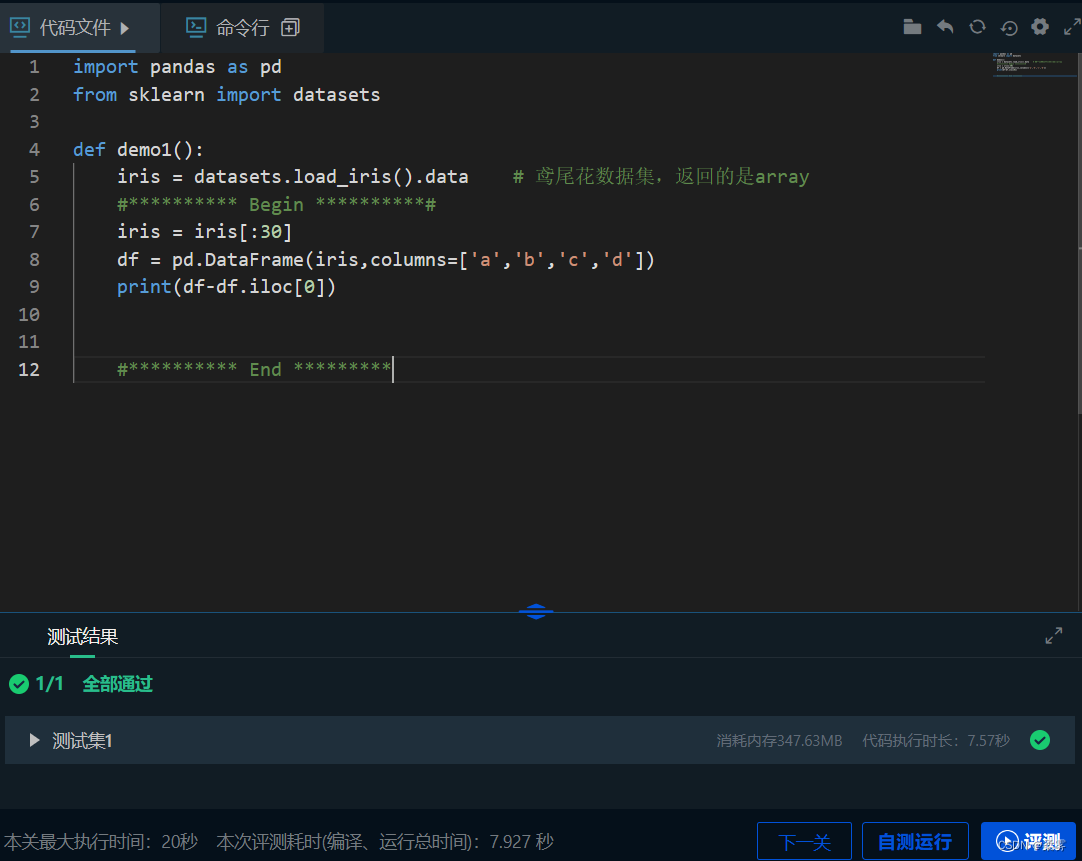
import pandas as pd
from sklearn import datasets
def demo1():
iris = datasets.load_iris().data # 鸢尾花数据集,返回的是array
#********** Begin **********#
iris = iris[:30]
df = pd.DataFrame(iris,columns=['a','b','c','d'])
print(df-df.iloc[0])
#********** End *********
第2关:Pandas缺失值类型
任务描述
本关任务:根据所学知识完成右侧选择题。
相关知识
本关卡主要介绍Pandas自带的几个处理缺失值的工具的用法,该系列Pandas实训的缺失值主要有三种形式:null、NaN或NA。
选择处理缺失值的方法
一般情况下可以分为两种:一种方法是通过一个覆盖全局的掩码表示缺失值,另一种方法是用一个**标签值(sentinel value)**表示缺失值。
掩码方法中掩码可能是一个与原数组维度相同的完整布尔类型数组,也可能是用一个比特(0或1)表示有缺失值的局部状态;
标签方法中,标签值可能是具体的数据(例如用-9999表示缺失的整数),也可能是些极少出现的形式。
Pandas缺失值
综合考虑各种方法的优缺点,Pandas最终选择用标签方法表示缺失值,包括两种Python原有的缺失值:浮点数据类型的NaN值,以及 Python的None对象。
None:Python对象类型的缺失值
Pandas可以使用的第一种缺失值标签是None,它是一个Python单体对象,由于None是一个Python对象,所以不能作为任何NumPy / Pandas数组类型的缺失值,只能用于’object’数组类型(即由 Python对象构成的数组)。
np.array([1, None, 3, 4])
Out: array([1, None, 3, 4], dtype=object)
NaN:数值类型的缺失值
另一种缺失值的标签是NaN(全称Not a Number),是一种按照IEEE浮点数标准设计、在任何系统中都兼容的特殊浮点数:
vals2 = np.array([1, np.nan, 3, 4])
vals2.dtype
Out: dtype(‘float64’)
注意:NumPy会为这个数组选择一个原生浮点类型,这意味着和之前的 object类型数组不同,这个数组会被编译成C代码从而实现快速操作。你可以把NaN看作是一个数据类病毒——它会将与它接触过的数据同化。无论和NaN进行何种操作,最终结果都是NaN:
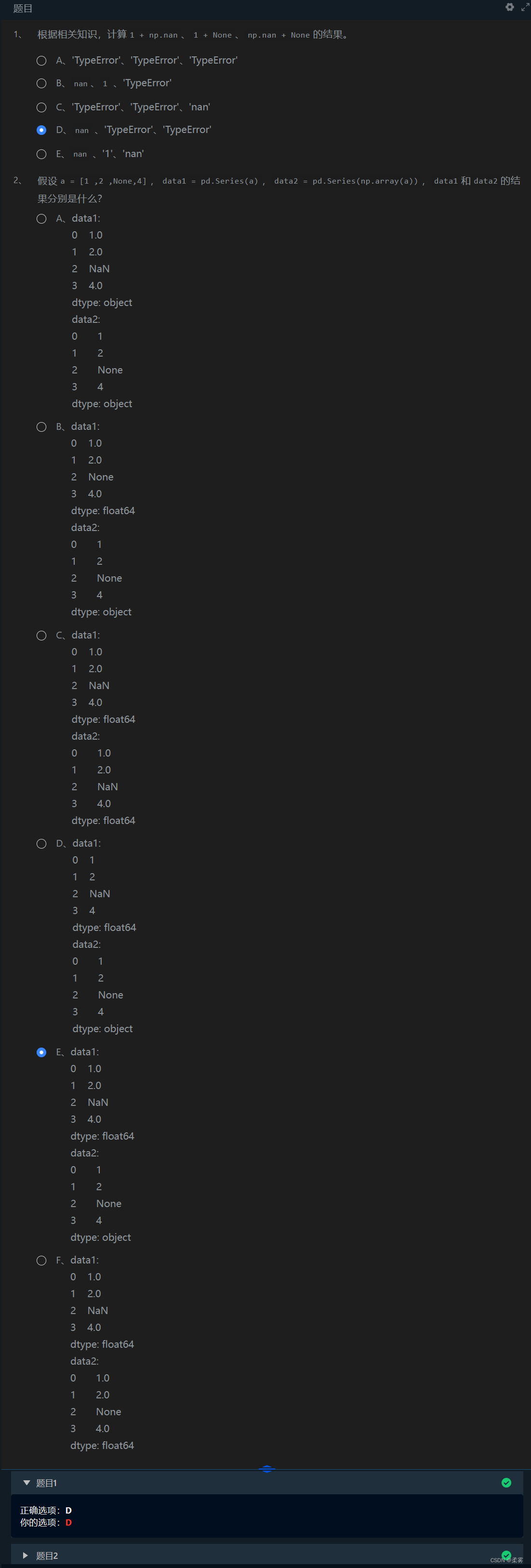
1 + np.nan
0 * np.nan #这两个的结果都为nan
虽然这些累计操作的结果定义是合理的(即不会抛出异常),但是并非总是有效的:
vals2 = np.array([1, np.nan, 3, 4])
vals2.sum(), vals2.min(), vals2.max()
Out:(nan, nan, nan)
NumPy也提供了一些特殊的累计函数,它们可以忽略缺失值的影响:
np.nansum(vals2), np.nanmin(vals2), np.nanmax(vals2)
Out: (8.0, 1.0, 4.0)
谨记,NaN是一种特殊的浮点数,不是整数、字符串以及其他数据类型。
Pandas中NaN与None的差异 虽然NaN与None各有各的用处,但是Pandas把它们看成是可以等价交换的:
pd.Series([1, np.nan, 2, None])
Out:
0 1.0
1 NaN
2 2.0
3 NaN
dtype: float64
Pandas会将没有标签值的数据类型自动转换为NA。例如我们将整形数组中的一个值设置为np.nan时,这个值就会强制转换成浮点数缺失值NA,下表表示Pandas对不同类型缺失值的转换规则:
类型 缺失值转换规则 NA标签值
floating 浮点型 无变化 np.nan
object 对象类型 无变化 np.nan或None
integer 整数类型 强制转换为 float64 np.nan
boolean 布尔类型 强制转换为 object np.nan或None
编程要求
本关无编程任务,要求完成右侧代码编辑区内相应的选择题。
测试说明
平台会对你的选择题答案结果进行测试,对比你的答案与实际正确的答案,只有所有答案全部正确才能进入下一关。
开始你的任务吧,祝你成功!
第3关:缺失值处理
任务描述
本关任务:按照编程要求完成任务并输出目标DataFrame。
相关知识
Pandas提供了一些方法来发现、剔除、替换数据结构中的缺失值,主要包括以下几种:
isnull() # 创建一个布尔类型的掩码标签缺失值。
notnull() # 与isnull()相反,即缺失值为False
dropna() # 返回一个提出缺失值的数据
fillna() # 返回一个填充了缺失值的数据副本
发现缺失值
Pandas有两种方法可以发现缺失值:isnull()和notnull(),这俩个中方法皆可用于Series和DataFrame。每种方法都返回布尔类型的掩码数据。
data=pd.Series([1,np.nan,'hello',None])
data.isnull()
Out:
0 False
1 True
2 False
3 True
dtype: bool
布尔类型掩码数组可以直接作为Series或DataFrame的索引使用。
data[data.notnull()]
Out:
0 1
2 hello
dtype: object
处理缺失值
dropna()删除缺失值,作用在Series对象上时,它的作用和data[data.notnull()]一样,而在DataFrame上使用它们时需要设置一些参数:
df = pd.DataFrame([[1, np.nan, 2],
[2, 3, 5],
[np.nan, 4, 6]])
# 如果不传任何参数时,dropna会删除有缺失值的所有行
df.dropna()
Out:
0 1 2
1 2.0 3.0 5
# 传入axis=1(或者axis='columns')时会删除所有包含缺失值的列
df.dropna(axis=1)
Out:
2
0 2
1 5
2 6
但是这么做也会把非缺失值一并剔除,因为可能有时候只需要剔除全部是缺失值的行或列,或者绝大多数是缺失值的行或列。这些需求可以通过设置how或thresh参数来满足,它们可以设置剔除行或列缺失值的数量阈值。
df[3] = np.nan
Out:
0 1 2 3
0 1.0 NaN 2 NaN
1 2.0 3.0 5 NaN
2 NaN 4.0 6 NaN
# 删除值全部为缺失值的列
df.dropna(axis=1,how="all")
Out:
0 1 2
0 1.0 NaN 2
1 2.0 3.0 5
2 NaN 4.0 6
#通过 thresh 参数设置行或列中非缺失值的最小数量
df.dropna(axis='rows', thresh=3) #非缺失值至少有3个
Out:
0 1 2 3
1 2.0 3.0 5 NaN
fillna()填充缺失值 有时候你可能并不想移除缺失值,而是想把它们替换成有效的数值。虽然你可以通过isnull()方法建立掩码来填充缺失值,但是Pandas为此专门提供了一个fillna()方法,它将返回填充了缺失值后的数组副本。
data=pd.Series([1, np.nan, 2, None, 3],index=list('abcd')
data.fillna(0) # 将缺失值填充为0
Out:
a 1.0
b 0.0
c 2.0
d 0.0
e 3.0
dtype: float64
可以用缺失值前面的有效值来从前往后填充(forward-fill),也可以用缺失值后面的有效值来从后往前填充(back-fill):
data.fillna(method="ffill")
Out:
a 1.0
b 1.0
c 2.0
d 2.0
e 3.0
dtype: float64
data.fillna(method='bfill')
Out:
a 1.0
b 2.0
c 2.0
d 3.0
e 3.0
dtype: float64
DataFrame的操作方法与Series类似,只是在填充时需要设置坐标轴参数axis。
df.fillna(method='ffill', axis=1) # bfill同样适用
Out:
0 1 2 3
0 1.0 1.0 2.0 2.0
1 2.0 3.0 5.0 5.0
2 NaN 4.0 6.0 6.0
编程要求
本关的编程任务是补全右侧上部代码编辑区内的相应代码,要求实现如下功能:
获取鸢尾花数据集,并转换成DataFrame对象,列名为’a’,‘b’,‘c’,‘d’;
获取DataFrame对象的前30行;
使用sub()进行减法运算,将每一行都减去第一行的值;
将所有小于0的值转成缺失值;
删除非缺失值数量最小为2的行;
最后再从前往后填充缺失值并输出结果;
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
无测试输入
预期输出:
开始你的任务吧,祝你成功!
示例代码如下:
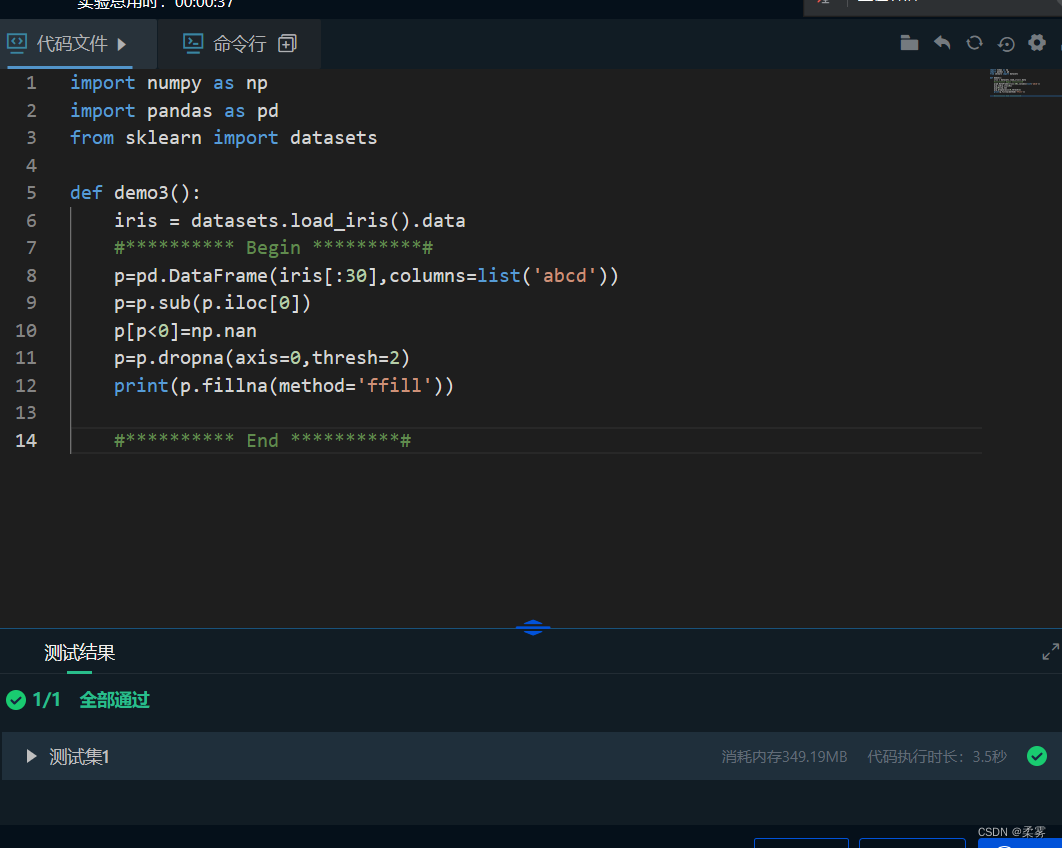
import numpy as np
import pandas as pd
from sklearn import datasets
def demo3():
iris = datasets.load_iris().data
#********** Begin **********#
p=pd.DataFrame(iris[:30],columns=list('abcd'))
p=p.sub(p.iloc[0])
p[p<0]=np.nan
p=p.dropna(axis=0,thresh=2)
print(p.fillna(method='ffill'))
#********** End **********#















 2767
2767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









