







前言
人脸识别是一个老生常谈的话题了,至于人脸识别的算法也是多种多样。有多种实现的方式,这里就不多说了。我今天要复现的是yolo的人脸识别算法,使用预训练好的onnx模型,同时接入到我们的ROS的系统中。
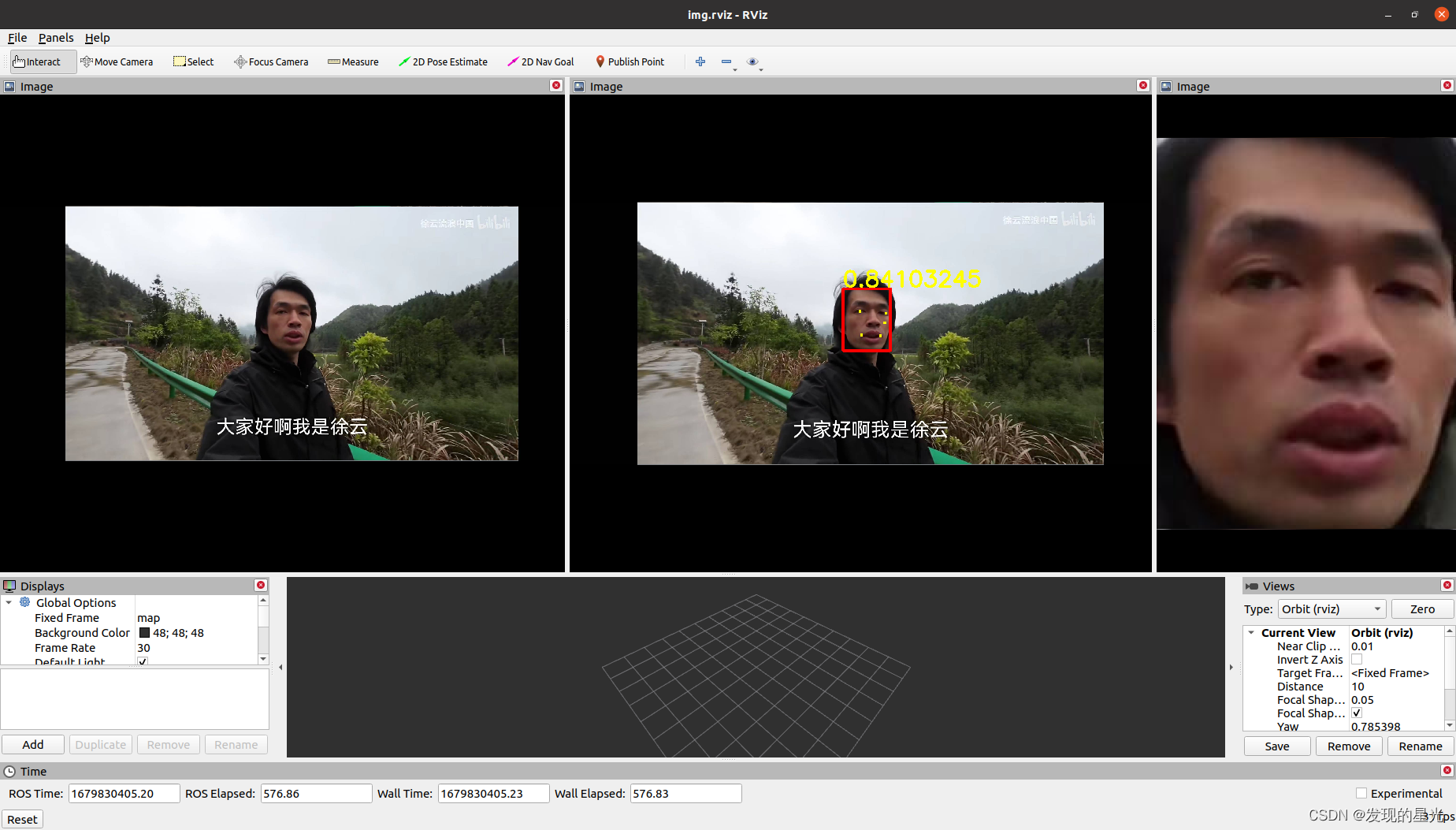
先看效果
图中是将人脸的区域标注了出来,并且有5个关键点,虽说5个关键点较比与其他的网络而言不算多,但是,胜在onnx运行速度快,支持CPU与GPU的部署,也可以比较方便的部署在Xavier中运行。并且经过了其他的测试,在即使有口罩的遮挡的情况下,仍然可以有很准确的识别度。
YOLO-FACE复现
clone仓库
仓库地址
https://github.com/derronqi/yolov7-face
https://github.com/hpc203/yolov7-detect-face-onnxrun-cpp-py
命令行
git clone https://github.com/derronqi/yolov7-face
git clone https://github.com/hpc203/yolov7-detect-face-onnxrun-cpp-py
上面的第一个仓库实际上是训练/测试使用的,为了简单,我们使用第一个仓库中的requirements文件来配置环境
下面的第二个仓库是演示使用的,我目前用的只是第二个仓库复现的
利用conda创建python虚拟环境
conda create -n rosface python=3.7
配置环境
conda activate rosface
cd yolov7-face
pip install -r requirements.txt
python是3.7版本的,若是3.8版本的,会遇到so文件的错误的一些小问题,需要重建软连接。
预训练模型的下载
在 https://github.com/hpc203/yolov7-detect-face-onnxrun-cpp-py中提供了预训练模型的下载,为百度网盘的连接,感谢大佬的工作做的如此的仔细。
测试单张图片
cd yolov7-detect-face-onnxrun-cpp-py
python main.py --imgpath selfie.jpg --modelpath ../onnx_havepost_models/yolov7-lite-e.onnx
参数的简单的说明:
--imgpath指定的是测试图片的路径
--modelpath指定的是上文预训练模型的路径
原图

测试图片

ROS
Subscriber
实际上单张图片测试通过了,对于ROS而言,就是一个接口的工作量了。我们需要做一个sub,去接受视频流,然后将mark或者是加了mark的image发布出去就完成了。
以main.py为基础,这里新增了一个Subscriber,订阅的topic为/image
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--modelpath', type=str, default='onnx_havepost_models/yolov7-lite-e.onnx',
help="onnx filepath")
parser.add_argument('--confThreshold', default=0.45, type=float, help='class confidence')
parser.add_argument('--nmsThreshold', default=0.5, type=float, help='nms iou thresh')
args = parser.parse_args()
# Initialize YOLOv7_face object detector
YOLOv7_face_detector = YOLOv7_face(args.modelpath, conf_thres=args.confThreshold, iou_thres=args.nmsThreshold)
rospy.init_node('yolo_face_dete_node', anonymous=True)
bridge = CvBridge()
rospy.Subscriber('/image', Image, callback)
rospy.spin()
callback & Publish
回调函数中,直接复制main.py中的数据处理的函数就可以了。这里就不赘述了
rviz演示
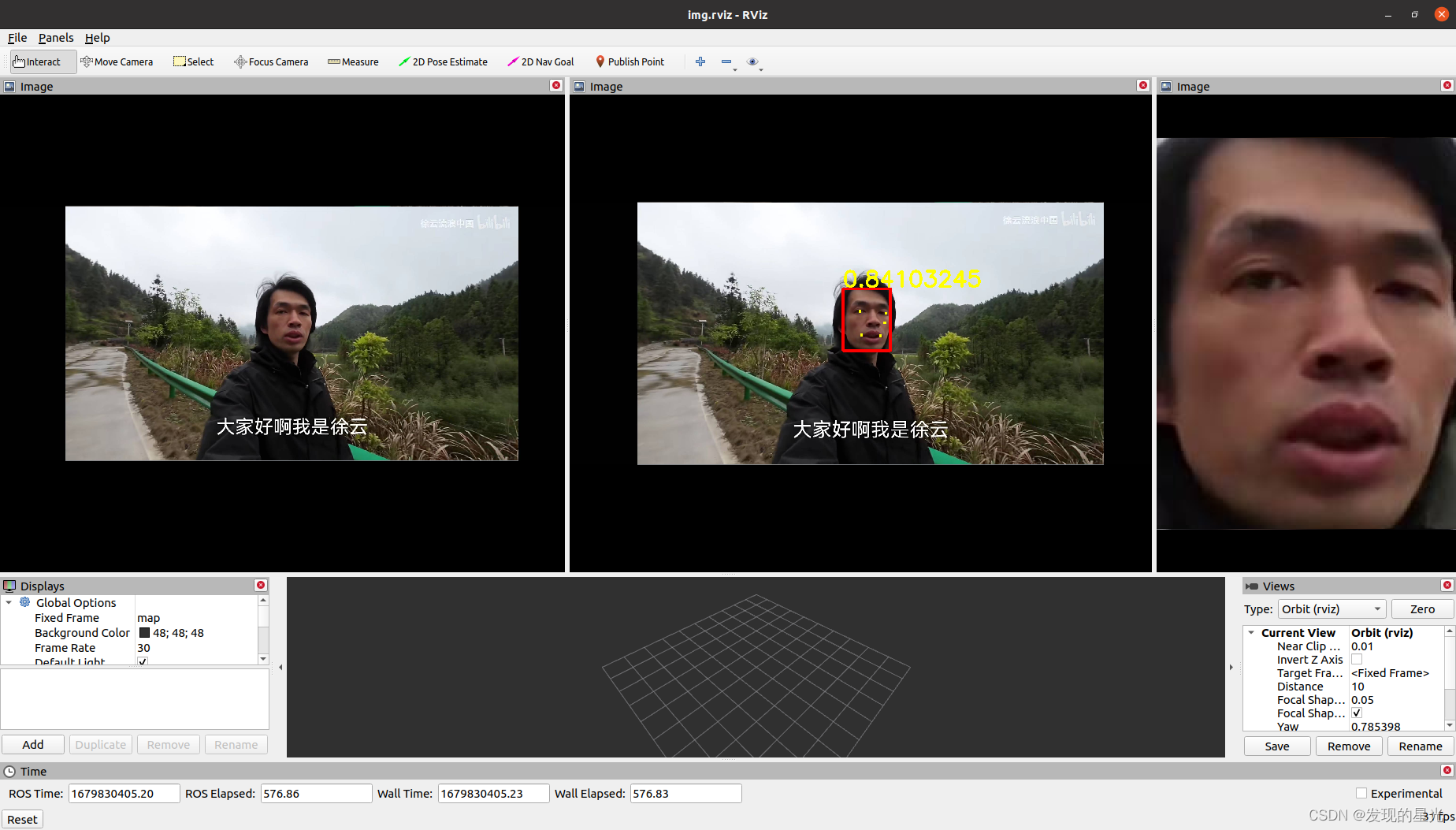
左侧是原始视频
中间为增加了人脸识别的mark
右侧是人脸识别截取的部分















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









