






方案
opencv先给每个同事自动打标签,减少人力物力,然后使用Yolov5进行训练模型操作。
项目结构

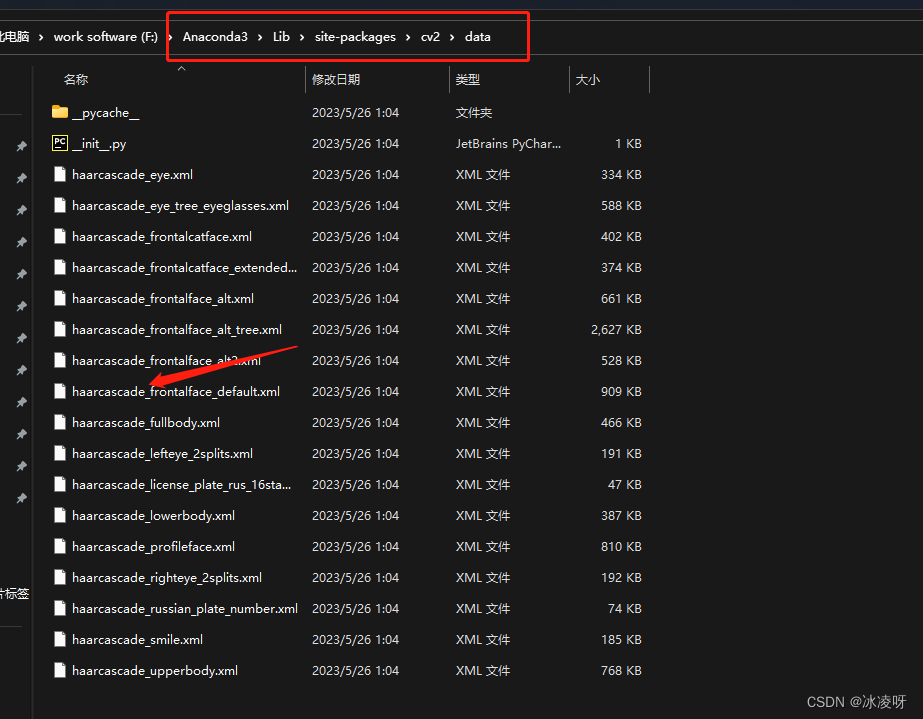
其中xml文件从Anaconda中cv模块安装目录中找到,以下是推荐查找目录
代码【opencv篇】
采集.py
# 导入cv模块
import cv2 as cv
# 导入time模块
import time
# 获取本地摄像头
capture = cv.VideoCapture(0)
# 人脸分类器路径
classifier_path = "haarcascade_frontalface_default.xml"
# 导入人脸分类器
face_classifier = cv.CascadeClassifier(classifier_path)
face_classifier.load(classifier_path)
name_dict = {
"wujie": 0,
"moshiyu": 1,
"wengli": 2,
"wangchaolong": 3,
"xiongjiyuan": 4,
"wangxuefei": 5,
"leitao": 6,
"wangzhi": 7,
"xumeifang": 8,
"wangjun": 9,
"wuxingqiao": 10
}
print("采集图片开始")
name = input("请输入你名字的完整拼音表式[如吴杰就输入wujie]:")
name = name.lower()
# 花名册里没有此同事名字
if name not in name_dict:
print("名字拼音输入出错,程序结束")
exit(0)
# 人物分类
count_of_type = name_dict[name]
# 打开花名册查看该同事是否已经采集过图片了
with open("name.txt", "r") as file:
lines = file.readlines()
for line in lines:
if line == name + "\n":
print("你已经采集过图片了,程序结束")
exit(0)
with open("name.txt", "a") as file:
file.write(name + "\n")
# 已采集图片数量
count_of_frame = 0
# 最大采集图片数量
max_count = 600
# 死循环
while True:
# 获取一帧图片
ret, frame = capture.read()
# 获取失败就退出循环
if ret is False:
break
# 将图片转换成灰度图,因为此人脸分类器只会对灰度图进行识别
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 获取识别出来的框
face_rects = face_classifier.detectMultiScale(gray)
# 给图片命名,与时间相关可以使其不重复
preffix = str(time.time()).replace('.', '_')
# 图片名字长度均为18
while len(preffix) < 18:
preffix += '0'
# 图片名称与同事名字相对应,以便后期删除标注的维护
preffix = name + "_" + preffix
# 前500张为训练集
if count_of_frame < 500:
image_src = "person_face_detected/train/images/" + preffix + '.jpg'
image_label = "person_face_detected/train/labels/" + preffix + '.txt'
# 后100张为测试集
else:
image_src = "person_face_detected/val/images/" + preffix + '.jpg'
image_label = "person_face_detected/val/labels/" + preffix + '.txt'
# 600张图片收集完成后退出采集
if count_of_frame >= max_count:
print(f"采集图片已达{max_count}张,自动退出采集")
break
# 识别出结果的情况下
if len(face_rects) > 0:
# 保存图片
cv.imwrite(image_src, frame)
# 记录采集数量增加1张
count_of_frame += 1
print(f"已采集图片{count_of_frame}张")
# 保存yolo格式的标注
with open(image_label, 'a', encoding='gbk') as file:
for face_rect in face_rects:
x, y, w, h = face_rect
# 给每个识别到的图片绘制一个框,方便实时检验人脸识别的效果
cv.rectangle(frame, (x, y), (x + h, y + w), (255, 0, 0), 3)
# 归一化
x, y, w, h = float(x) / 640, float(y) / 480, float(w) / 640, float(h) / 480
xc = (x + x + w) / 2
yc = (y + y + h) / 2
# yolo标注方式为[类别代号,中心点,宽,高],其中使用空格进行分隔
file.write(f"{count_of_type} {xc} {yc} {w} {h}")
# 把图片显示出来
cv.imshow("", frame)
# 接收用户的按键
key = cv.waitKey(1) & 0xFF
# 按键为esc则提前退出采集程序
if key == 27:
break
# 释放摄像头
capture.release()
# 关闭所有的窗口
cv.destroyAllWindows()
如果采集过程中出现干扰,需要清除已采集的同事的图片和标签,请运行清除.py
import os
name_dict = {
"wujie": 0,
"moshiyu": 1,
"wengli": 2,
"wangchaolong": 3,
"xiongjiyuan": 4,
"wangxuefei": 5,
"leitao": 6,
"wangzhi": 7,
"xumeifang": 8,
"wangjun": 9,
"wuxingqiao": 10
}
name = input("请输入要清除的同事的完整拼音表式[如吴杰就输入wujie]:")
name = name.lower()
# 花名册里没有此同事名字
if name not in name_dict:
print("名字拼音输入出错,程序结束")
exit(0)
flag = False
lines = None
# 打开花名册查看该同事是否已经采集过图片了
with open("name.txt", "r") as file:
lines = file.readlines()
for line in lines:
if line == name + "\n":
flag = True
if flag is True:
lines.remove(name + "\n")
with open("name.txt", "w") as file:
for line in lines:
file.write(line)
else:
print("该同事没有进行过采集操作,清除程序结束")
exit(0)
count = 0
# 清除train文件夹中该同事的image和label
dir = "person_face_detected/train/images/"
for filename in os.listdir(dir):
if filename.startswith(name):
print(filename)
os.remove(dir + filename)
count += 1
dir = "person_face_detected/train/labels/"
for filename in os.listdir(dir):
if filename.startswith(name):
print(filename)
os.remove(dir + filename)
count += 1
# 清除val文件夹中该同事的image和label
dir = "person_face_detected/val/images/"
for filename in os.listdir(dir):
if filename.startswith(name):
print(filename)
os.remove(dir + filename)
count += 1
dir = "person_face_detected/val/labels/"
for filename in os.listdir(dir):
if filename.startswith(name):
print(filename)
os.remove(dir + filename)
count += 1
print(f"删除完毕,图片加标签总共{count}个文件")
代码【Yolov5篇】
采集完毕后,你的person_face_detected文件下有所有同事的训练集和测试集,请将此文件夹复制到Yolov5/data文件夹下,并为其写一个person_face_detected.yaml,文件格式请参考同目录下的其他yaml文件
以命令行方式打开yolov5文件夹
执行训练命令
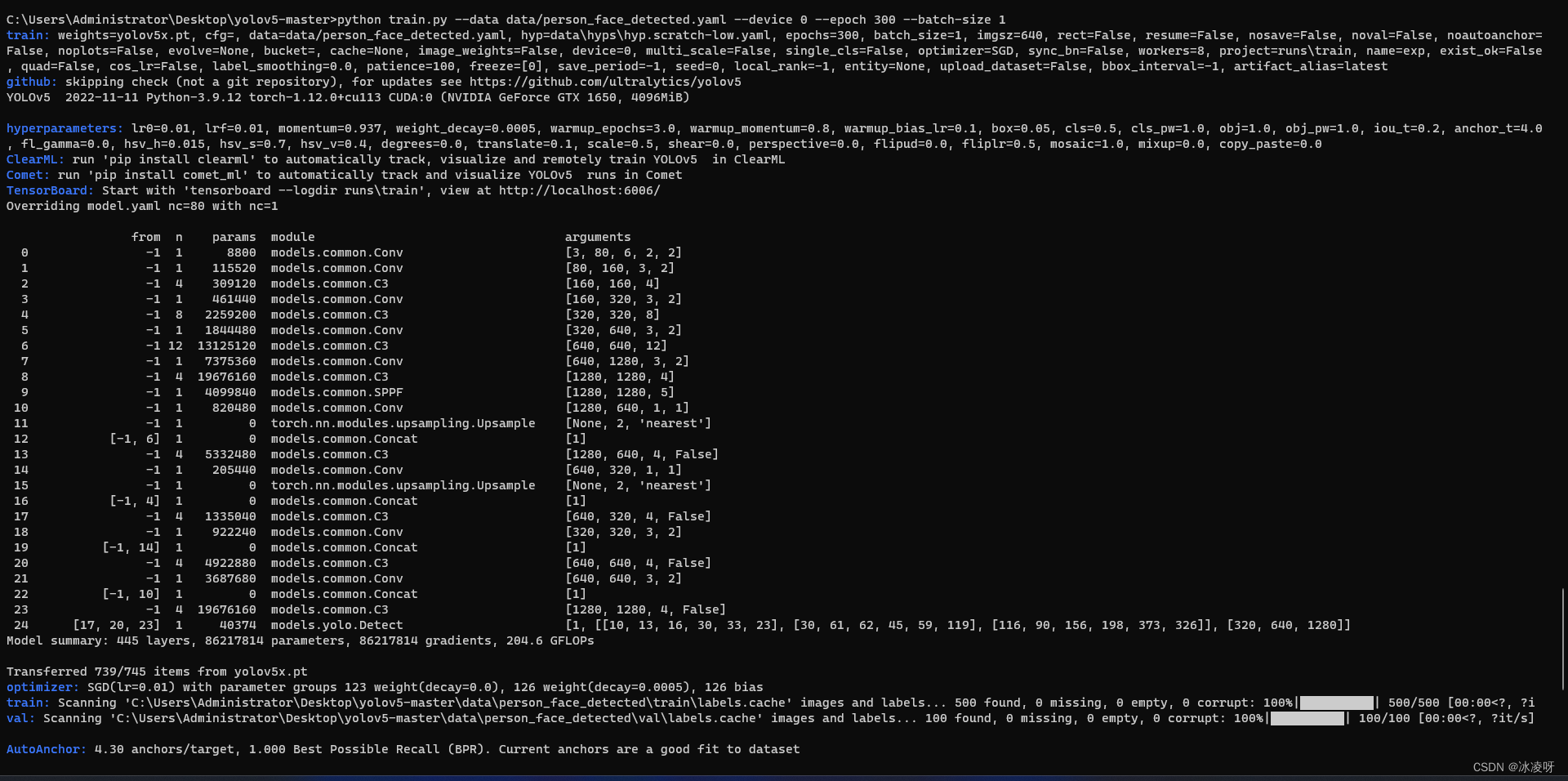
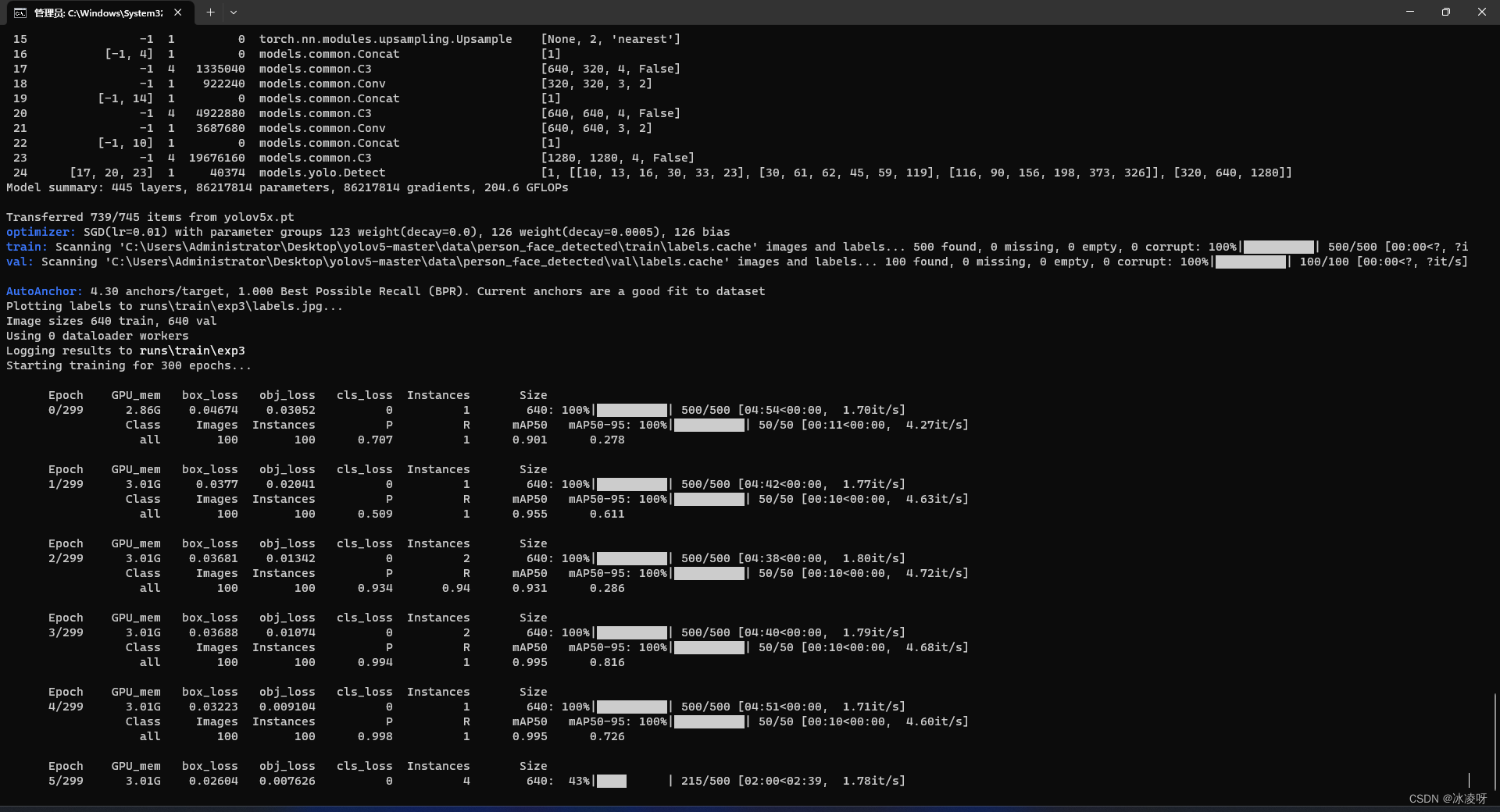
python train.py --data data/person_face_detected.yaml --epoch 300 --device 0 --batch-size 1如果没有任何异常,你应该可以看到如下界面
如果遇到异常,可以参考我之前发布的博文,希望能给大家带来一点帮助。















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









