






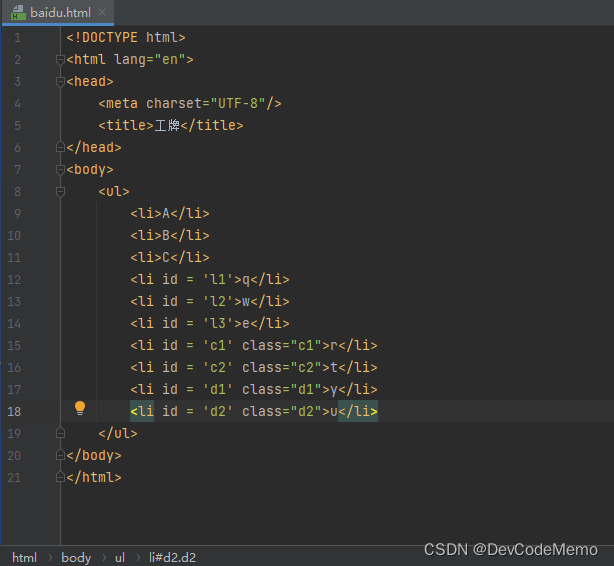
html示例
基本使用
#导入包
#pip install lxml
from lxml import etree
# xpath解析
# 1.本地文件 etree.parse
# 2.服务器响应的数据 etree.HTML()
tree = etree.parse('baidu.html')
# 获取所有的ul下的li标签
l1 = tree.xpath('//ul/li')
print(l1)
print(len(l1))
# 获取所有带有id的标签内容"/text()"
l2 = tree.xpath('//ul/li[@id]/text()')
print(l2)
print(len(l2))
# 获取id=l1的标签内容,id要带引号
l3 = tree.xpath('//ul/li[@id ="l1"]/text()')
print(l3)
# 获取id = c1的li标签的class属性值
l4 = tree.xpath('//ul/li[@id="c1"]/@class')
print(l4)
# 获取id中带有l的内容
l5 = tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(l5)
#获取class中带有d的内容
l6 = tree.xpath('//ul/li[contains(@class,"d")]/text()')
print(l6)
# 获取id为l开头的标签内容
l7 = tree.xpath('//ul/li[starts-with(@id,"l")]/text()')
print(l7)
# 获取id=c1且class=c1的标签内容
l8 = tree.xpath('//ul/li[@id="c1" and @class="c1"]/text()')
print(l8)













 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









