







这一篇博客主要是对一些刚学完Python爬虫中request库的小伙伴的一个简单的爬虫实战,希望对大家有用。
1 访问图片网站
对于图片网站的选取,我们选取网站https://pic.netbian.com/4kdongman/,网页如下图所示。
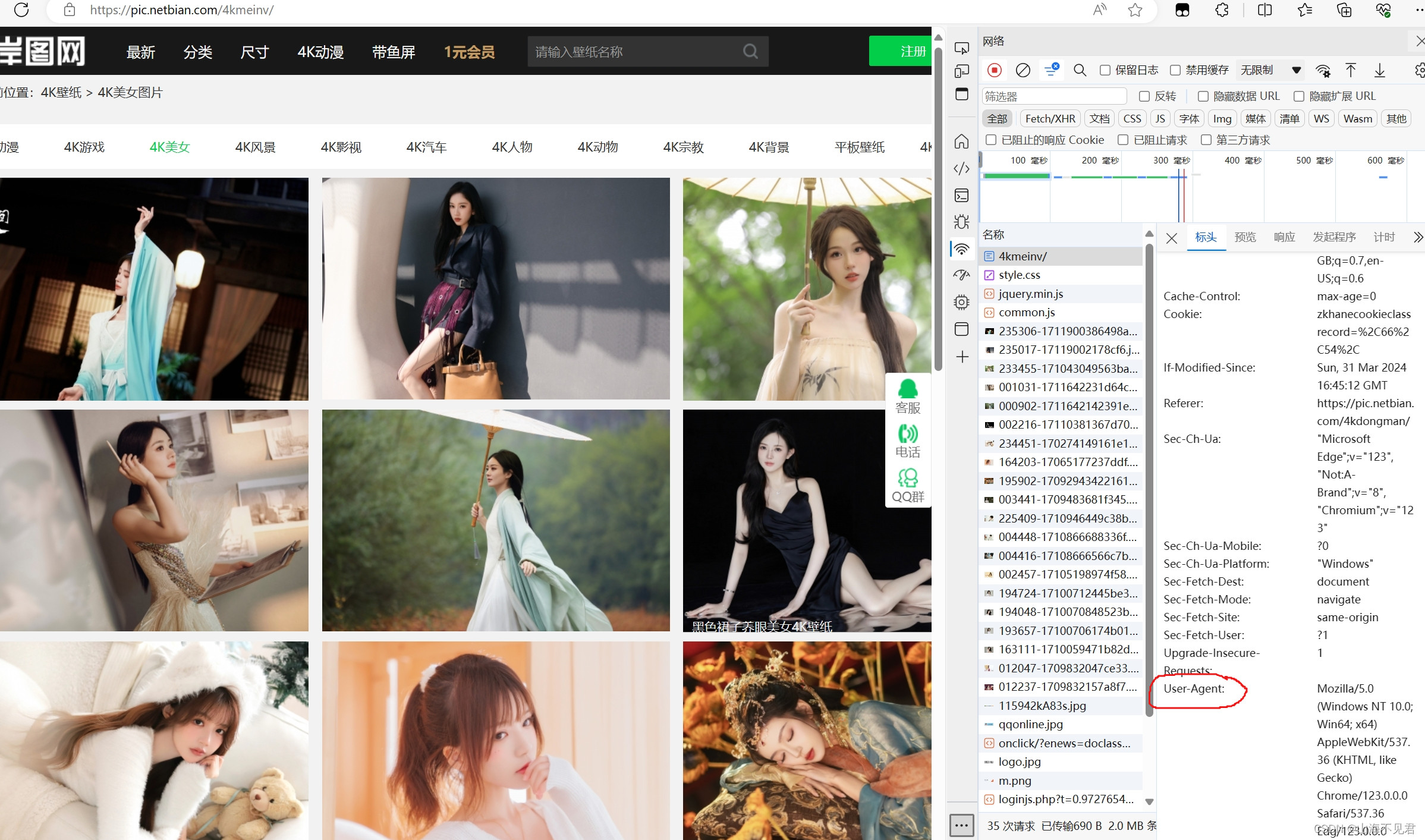
 通过对网页的抓包,找到自己的UA。
通过对网页的抓包,找到自己的UA。
 代码的编写如下,如果成功运行,则成功访问其网站。
代码的编写如下,如果成功运行,则成功访问其网站。
if __name__ == '__main__':
headers = {
"User-Agent": '......'
}
url = 'https://pic.netbian.com/4kdongman/'
re = requests.get(url=url, headers=headers)
re = re.text2 利用xpath对图片进行抓取操作
这里我们采用xpath对图片进行操作,如果想用正则表达式和bs4的小伙伴也可以自己尝试一下,评论区交流自己的代码哟!
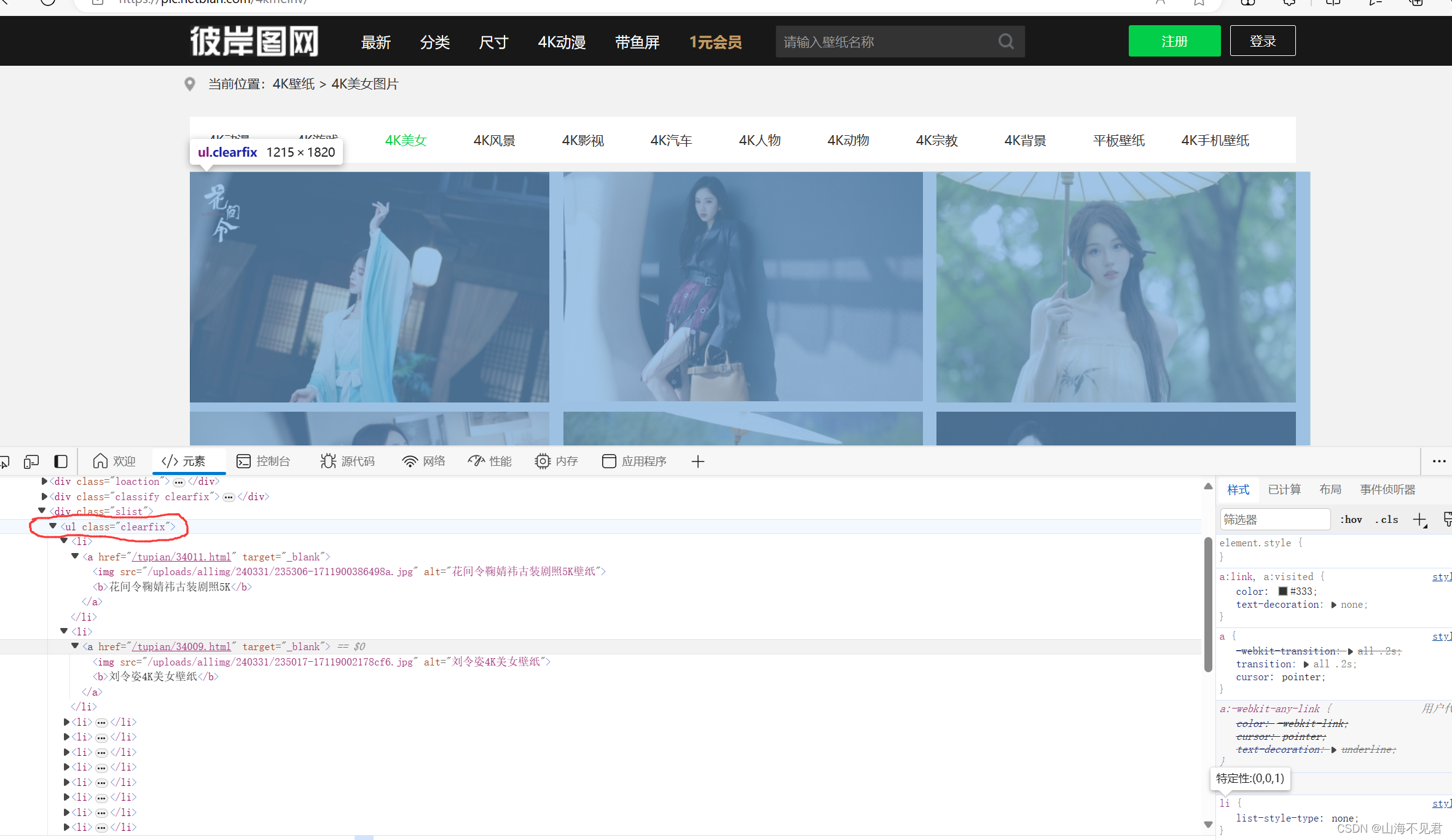
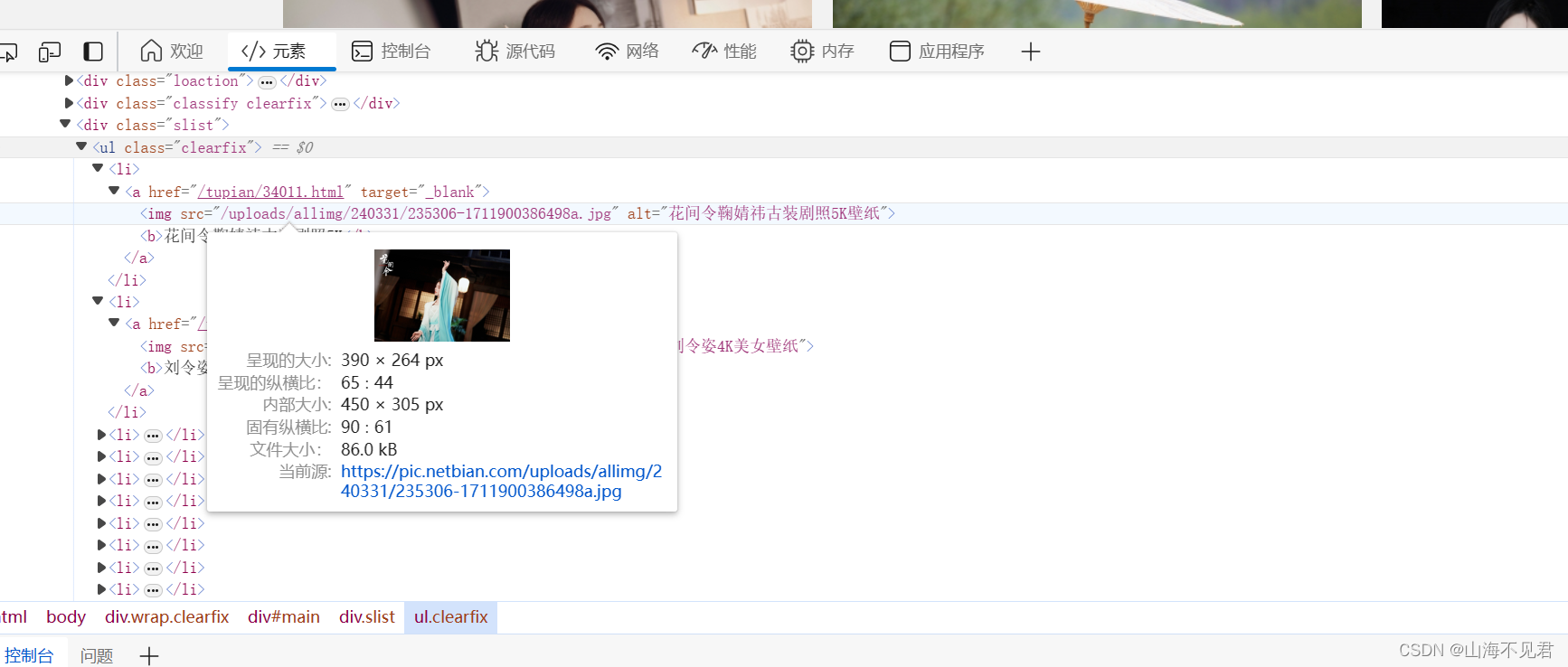
我们首先右击一张图片,点击检查,图片的位置就会自己出来。

然后我们找到所有图片都保存在中的li下面
然后我们右击ul标签,点击复制,可以发现里面有复制xpath路径,直接选择就行。
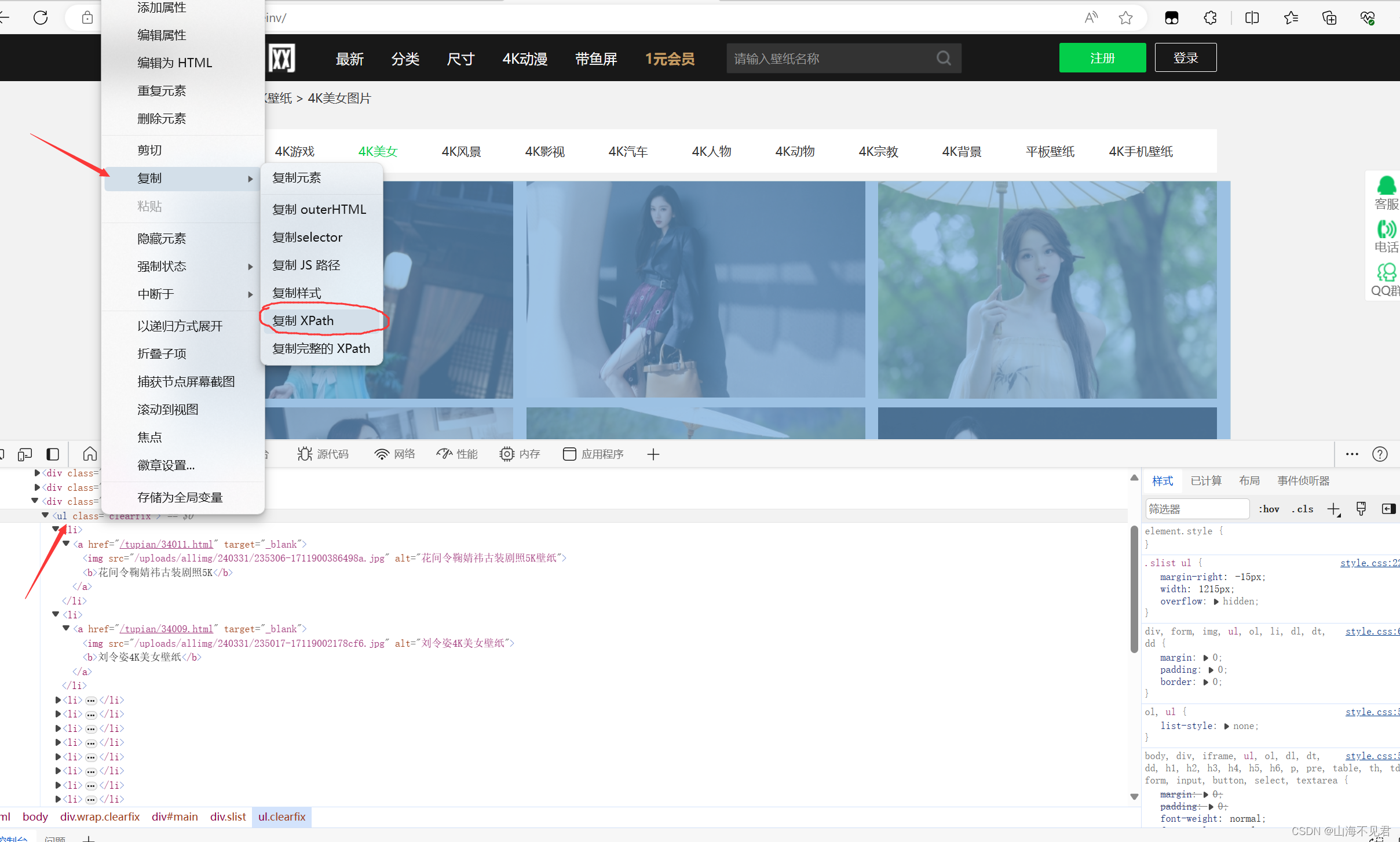
然后在路径后面添加li,表示我们要获取ul下面所有的li图片信息,代码实现如下。
tree = etree.HTML(re)
x = tree.xpath('//*[@id="main"]/div[3]/ul/li')
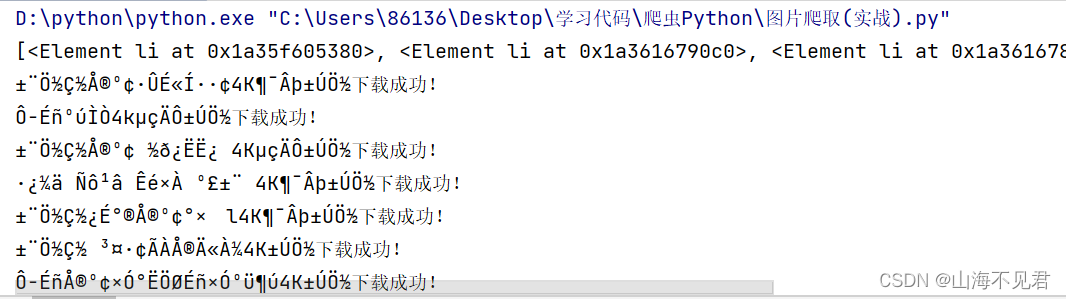
print(x)如果输出结果如下所示,那就代表你已经成功抓取图片信息了!

接下来我们就开始对li里的图片信息进行处理,我们可以知道图片保留在img标签下的src中,图片名在alt中,我们对x进行遍历,取出里面的li,然后访问图片所在的url,利用xpath取出图片地址和图片名。
因为我们要保存图片,所以这里我们用二进制进行保存,代码如下。
for k in x:
x1 = 'https://pic.netbian.com/' + k.xpath('.//img/@src')[0]
x2 = k.xpath('./a/img/@alt')[0]
re_x = requests.get(url=x1, headers=headers).content3 图片的保存
到现在为止,我们的抓取操作已经完成了,现在我们开始对抓取到的图片进行保存,我们现在本路径下利用os创建文件夹。
os.mkdir('美女照片')然后对每一张图片都保存在这个文件夹下面,代码如下。
name = '美女照片/' + x2
with open(name, 'wb') as fp:
fp.write(re_x)
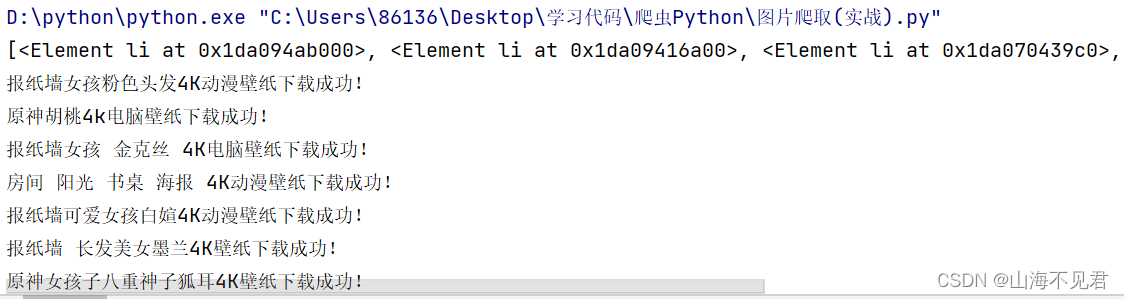
print(x2 + '下载成功!')这里我们表示如果下载成功,则输出成功信息。
有些小伙伴会发现自己的电脑怎么输出乱码呀,这里,欧的电脑也是乱码,那我们在最开始的位置将网站用gdk保存就可以解决问题了。
if __name__ == '__main__':
os.mkdir('美女照片')
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
url = 'https://pic.netbian.com/4kdongman/'
re = requests.get(url=url, headers=headers)
re.encoding = 'gbk'
re = re.text然后我们再开始运行代码,记得运行前把之前的文件夹删除了,不然会报错的哟。
好了,到目前为止Python爬虫之图片爬取已经完美结束了,如果大家有问题可以在评论区里交流。
4 完整代码
完整代码也给大家奉上了,希望大家收藏起来,默默开卷!
import os
import requests
from lxml import etree
if __name__ == '__main__':
os.mkdir('美女照片')
headers = {
"User-Agent": '......'
}
url = 'https://pic.netbian.com/4kdongman/'
re = requests.get(url=url, headers=headers)
re.encoding = 'gbk'
re = re.text
tree = etree.HTML(re)
x = tree.xpath('//*[@id="main"]/div[3]/ul/li')
print(x)
for k in x:
x1 = 'https://pic.netbian.com/' + k.xpath('.//img/@src')[0]
x2 = k.xpath('./a/img/@alt')[0]
re_x = requests.get(url=x1, headers=headers).content
name = '美女照片/' + x2
with open(name, 'wb') as fp:
fp.write(re_x)
print(x2 + '下载成功!')














 5676
5676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









