







这里是对sklearn库里的机器学习支持向量机分类器SVC的实战文章,大家如果对其原理感兴趣的话可以自行搜索,这里我将会带你零基础学会使用sklearn库里面的SVC,这里只是一个很简单的模型实战,如果写的不好也请多多指教。
1 数据的确定与划分
这里我就直接用sklearn里自带的鸢尾花数据集来进行实战,因为这里的数据集是完整无缺失的,所以就不进行数据预处理了,首先我们导入鸢尾花数据集。
from sklearn.datasets import load_iris
data=load_iris()
X=data.data
Y=data.target对数据进行划分,我们采用sklearn自带的划分数据集,对数据进行37划分,其中70%作为训练集,30%作为测试集,同时将数据随机数固定,确保每次划分的数据集一样。
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.3,random_state=420)2 模型的选参与调优
到这里我们就开始对模型进行选参和调优了,首先在sklearn的SVC中,你要选择的参数就是核函数,这里不懂的想要了解一下的可以自行上网去搜索,对于核函数的选择我们在kernel中进行操作的,下面请看代码。
from sklearn.svm import SVC
Kernel = ["linear","poly","rbf","sigmoid"]
scorel=[]
for k in Kernel:
clf = SVC(kernel=k).fit(Xtrain,Ytrain)
scorel.append(clf.score(Xtest,Ytest))
best_kernel=Kernel[scorel.index(max(scorel))]
best_kernel通过上面的代码我们初步确定了参数kernel的值,同时不同的核函数他所对应的参数也有所不同,具体如下图所示。

不同参数的调参步骤基本上都是一致的,这里我们拿rbf为例来进行调参,同时为了更加直观的表现出训练的过程,我们将其绘制出来,同时参数cache_size表示模型训练时的内存大小,大家可以根据自己电脑的配置来修改,单位为MB。
import numpy as np
import matplotlib.pyplot as plt
mc = []
gamma_range = np.logspace(-10, 1, 50)
for i in gamma_range:
clf = SVC(kernel="rbf",gamma = i,cache_size=2000).fit(Xtrain,Ytrain)
mc.append(clf.score(Xtest,Ytest))
print(max(mc), gamma_range[mc.index(max(mc))])
plt.plot(gamma_range,mc)
plt.show()训练过程如下图所示,如果你训练完后发现图像依旧呈现上升趋势的话那就增大范围在进行训练。
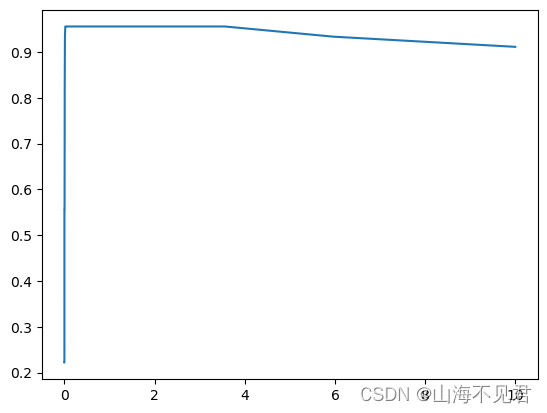
最后我们来对本文中最后一个参数C来进行调优,它代表了错误项的惩罚参数,用于控制模型的复杂度与对训练数据拟合程度之间的权衡,我们可以通过对C的调优来优化模型。
q = []
C_range = np.linspace(0.01,30,50)
for i in C_range:
clf = SVC(kernel="rbf",C=i,gamma = gamma_range[mc.index(max(mc))],cache_size=20000).fit(Xtrain,Ytrain)
q.append(clf.score(Xtest,Ytest))
print(max(q), C_range[q.index(max(q))])
plt.plot(C_range,q)
plt.show()训练过程如下图所示。
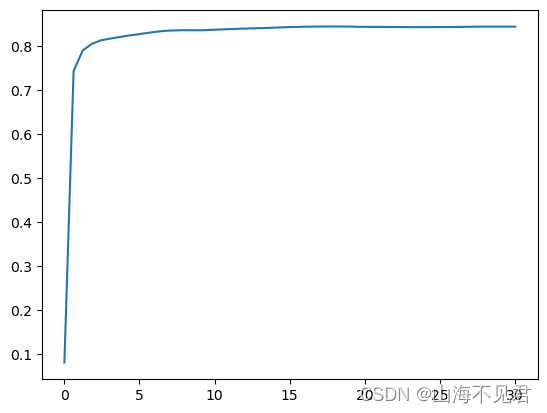
3 总结
到这里一个简单的SVC模型实战就结束了,希望对大家有所帮助,如果有错误也希望大家提出来,我们共同进步。
4 代码汇总
from sklearn.datasets import load_iris
from sklearn.svm import SVC
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
data=load_iris()
X=data.data
Y=data.target
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.3,random_state=420)
Kernel = ["linear","poly","rbf","sigmoid"]
scorel=[]
for k in Kernel:
clf = SVC(kernel=k).fit(Xtrain,Ytrain)
scorel.append(clf.score(Xtrain,Ytrain))
best_kernel=Kernel[scorel.index(max(scorel))]
mc = []
gamma_range = np.logspace(-10, 1, 50)
for i in gamma_range:
clf = SVC(kernel="rbf",gamma = i,cache_size=2000).fit(Xtrain,Ytrain)
mc.append(clf.score(Xtrain,Ytrain))
print(max(mc), gamma_range[mc.index(max(mc))])
plt.plot(gamma_range,mc)
plt.show()
q = []
C_range = np.linspace(0.01,30,50)
for i in C_range:
clf = SVC(kernel="rbf",C=i,gamma = gamma_range[mc.index(max(mc))],cache_size=20000).fit(Xtrain,Ytrain)
q.append(clf.score(Xtrain,Ytrain))
print(max(q), C_range[q.index(max(q))])
plt.plot(C_range,q)
plt.show()














 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









