






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
水质预测是一个重要的环境问题,可以通过基于注意力的双向 LSTM 和编码器-解码器模型来实现准确的水质预测。
首先,我们需要收集水质数据,包括水质指标(如溶解氧、氨氮、总磷等)和相关环境因素(如温度、pH值、降雨量等)。这些数据可以来自于实时监测站、传感器网络或者历史记录。
接下来,我们可以使用基于注意力的双向 LSTM 模型来对水质数据进行建模。双向 LSTM 可以捕捉时间序列数据中的长期依赖关系,并且通过正向和反向的信息传递来改善预测性能。注意力机制可以帮助模型关注对当前预测有重要影响的输入特征。
然后,我们可以使用编码器-解码器架构来进行水质预测。编码器将水质数据作为输入,并将其转换为一个中间表示。解码器将中间表示作为输入,并生成水质预测结果。编码器和解码器之间可以通过注意力机制进行信息传递,以帮助解码器生成准确的预测结果。
在训练模型时,我们可以使用历史水质数据进行监督学习。我们将水质数据序列划分为训练集和测试集,使用训练集来训练模型,并使用测试集来评估模型的预测性能。可以使用均方根误差(RMSE)或平均绝对误差(MAE)等指标来评估模型的准确性。
最后,我们可以使用训练好的模型来进行水质预测。将最新的水质数据输入模型,即可获得对未来水质状况的预测结果。
综上,基于注意力的双向 LSTM 和编码器-解码器模型可以提供准确的水质预测。通过合理选择模型架构、训练数据和评估指标,可以进一步提高模型的预测性能。
📚2 运行结果
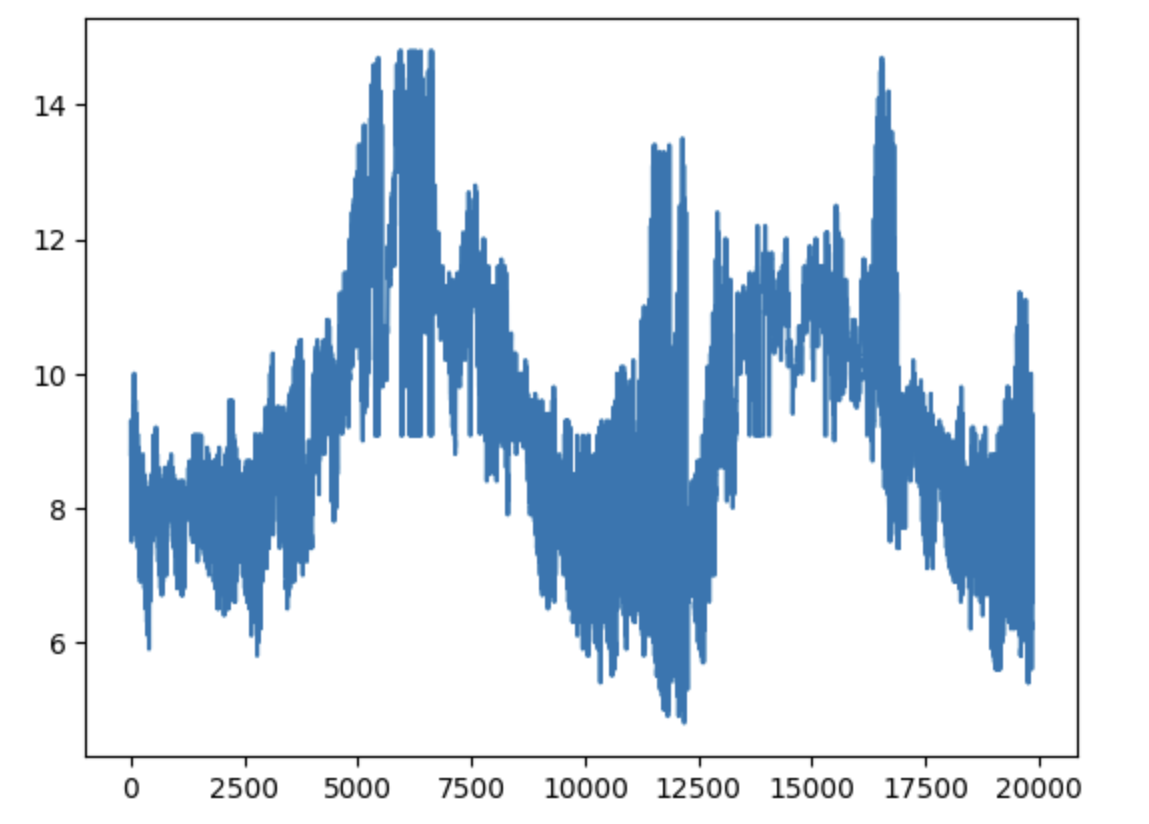
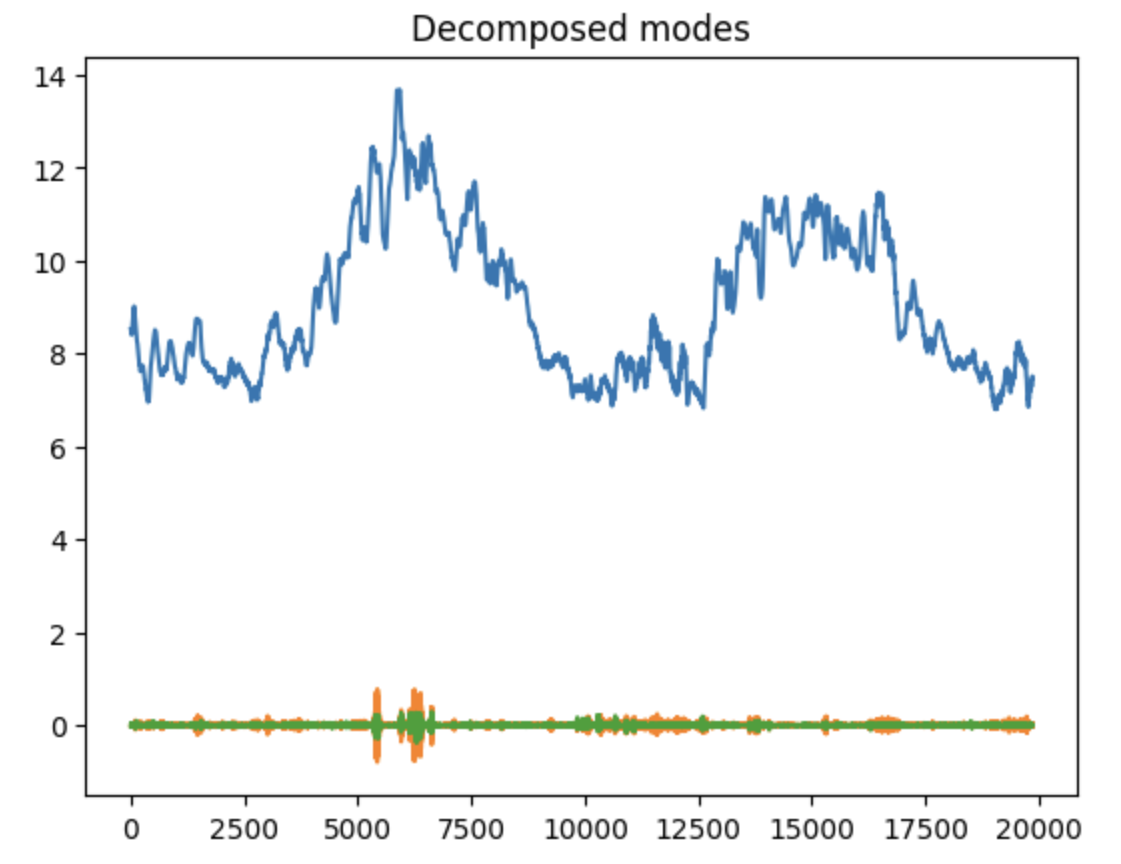
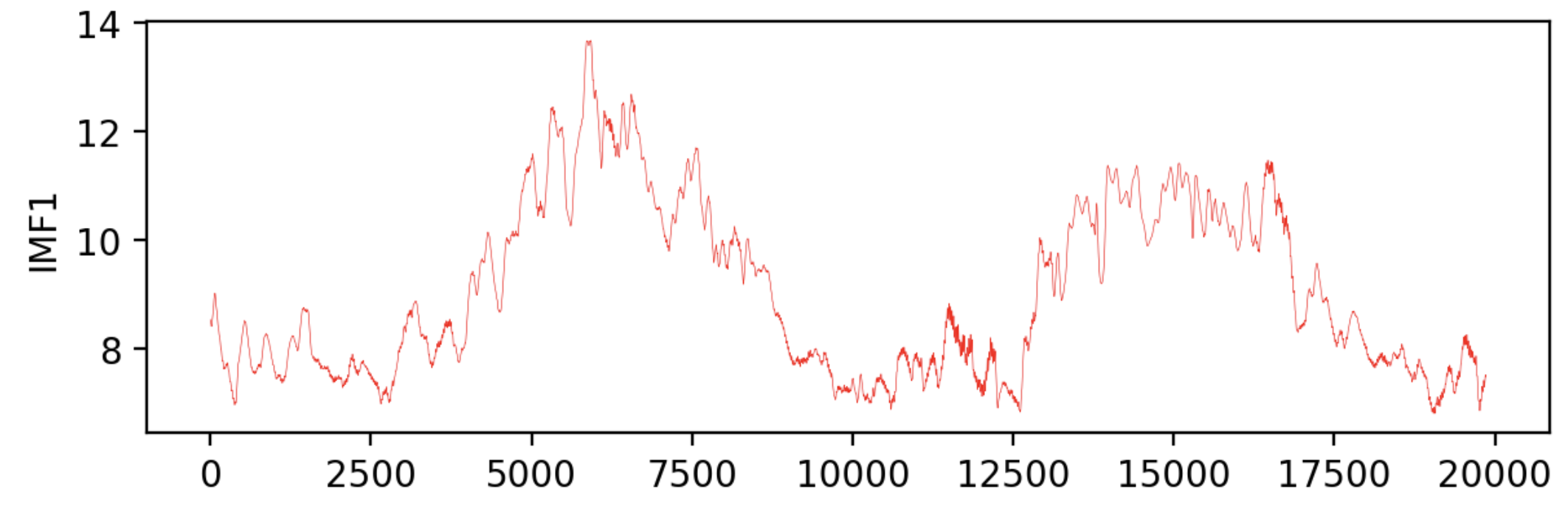

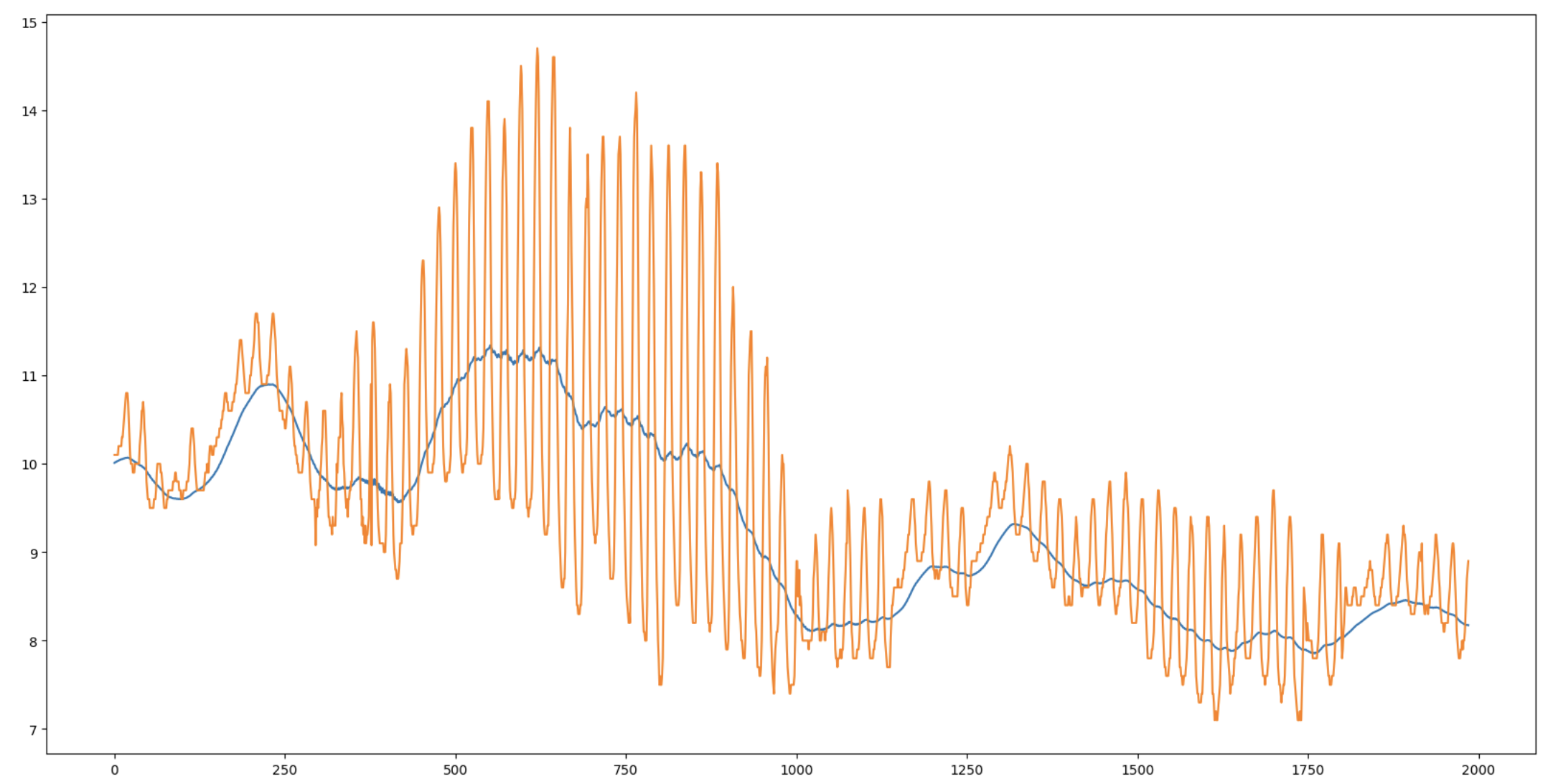
plt.figure(figsize=(20, 10))
plt.plot(preds)
plt.plot(true)
plt.show()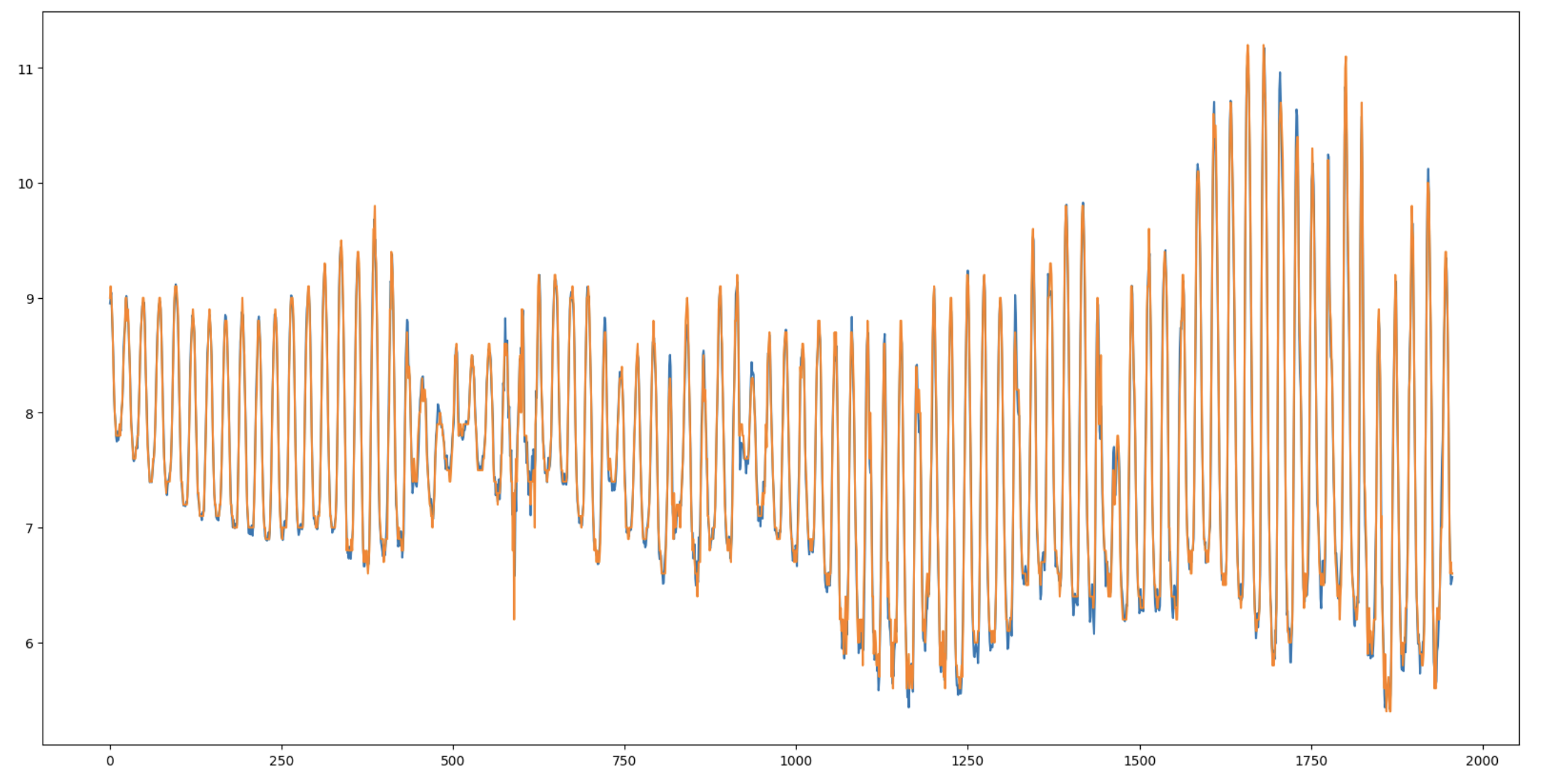
plt.figure(figsize=(20, 10))
plt.plot(val_loss)
plt.plot(train_loss)
plt.show()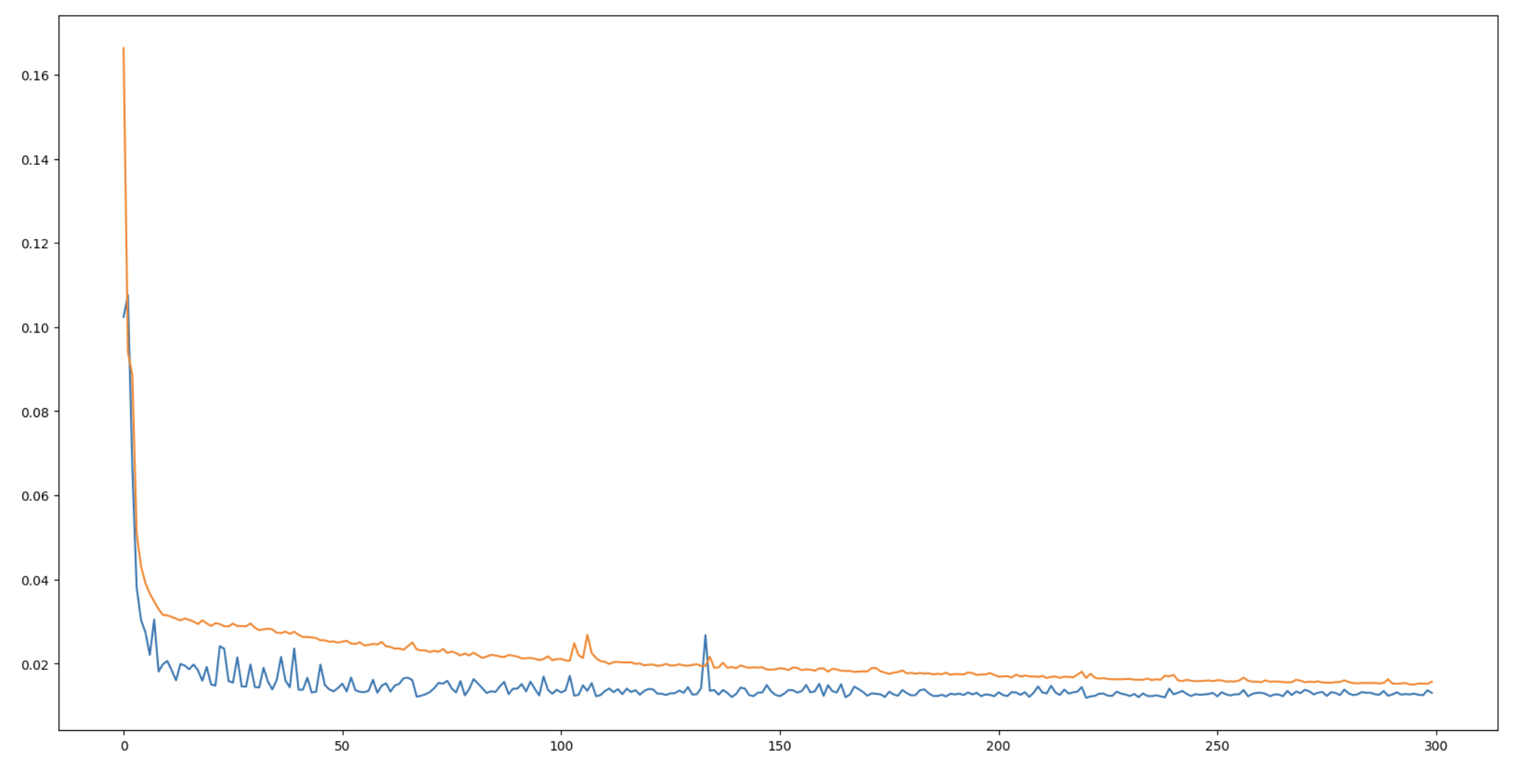
部分代码:
alpha = 14000 # moderate bandwidth constraint
tau = 0. # noise-tolerance (no strict fidelity enforcement)
K = 3 # 3 modes
DC = 0 # no DC part imposed
init = 1 # initialize omegas uniformly
tol = 1e-7
"""
alpha、tau、K、DC、init、tol 六个输入参数的无严格要求;
alpha 带宽限制 经验取值为 抽样点长度 1.5-2.0 倍;
tau 噪声容限 ;
K 分解模态(IMF)个数;
DC 合成信号若无常量,取值为 0;若含常量,则其取值为 1;
init 初始化 w 值,当初始化为 1 时,均匀分布产生的随机数;
tol 控制误差大小常量,决定精度与迭代次数
"""
u, u_hat, omega = VMD(f.values, alpha, tau, K, DC, init, tol)
plt.figure()
plt.plot(u.T)
plt.title('Decomposed modes')
fig1 = plt.figure()
plt.plot(f.values)
fig1.suptitle('Original input signal and its components')alpha = 14000 # moderate bandwidth constraint
tau = 0. # noise-tolerance (no strict fidelity enforcement)
K = 3 # 3 modes
DC = 0 # no DC part imposed
init = 1 # initialize omegas uniformly
tol = 1e-7
"""
alpha、tau、K、DC、init、tol 六个输入参数的无严格要求;
alpha 带宽限制 经验取值为 抽样点长度 1.5-2.0 倍;
tau 噪声容限 ;
K 分解模态(IMF)个数;
DC 合成信号若无常量,取值为 0;若含常量,则其取值为 1;
init 初始化 w 值,当初始化为 1 时,均匀分布产生的随机数;
tol 控制误差大小常量,决定精度与迭代次数
"""
u, u_hat, omega = VMD(f.values, alpha, tau, K, DC, init, tol)
plt.figure()
plt.plot(u.T)
plt.title('Decomposed modes')
fig1 = plt.figure()
plt.plot(f.values)
fig1.suptitle('Original input signal and its components')
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]商艳红,张静.基于局部化双向LSTM和状态转移约束的养殖水质分类预测[J].渔业现代化, 2019.DOI:CNKI:SUN:HDXY.0.2019-02-005.
[2]商艳红,张静.基于局部化双向LSTM和状态转移约束的养殖水质分类预测[J].渔业现代化, 2019, 46(2):7.DOI:10.3969/j.issn.1007-9580.2019.02.005.
[3]白雯睿,杨毅强,李强.引入小波分解的Seq2Seq水质多步预测模型研究[J].现代电子技术, 2022(017):045.















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









