




【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。

几乎没有数据科学项目能够免于数据清洗。数据清洗是准备数据的初始步骤,其核心目的是保留数据中相关且有用的信息,无论是为了后续分析,还是作为人工智能或机器学习模型的输入。常见的数据清洗操作包括统一或转换数据类型、处理缺失值、剔除因错误测量产生的噪声值以及去重。
正如你所料,数据越复杂,清洗过程就越繁琐、耗时,尤其是在手动操作时。
本文将介绍如何利用Pandas库的功能,实现数据清洗流程的自动化。
使用Pandas清洗数据:常用函数
利用Pandas自动化数据清洗,本质上是将多个数据清洗函数按顺序组合,封装为可复用的清洗管道。在此之前,先介绍一些常用函数。下文假设有一个Python变量df,其包含一个Pandas DataFrame对象的数据集。
- 填充缺失值:使用
df.fillna()可以将缺失值替换为默认值,或通过df.dropna()删除包含缺失值的行或列。 - 删除重复数据:
df.drop_duplicates()可快速删除重复条目(行),可根据单个属性或整行进行去重。 - 字符串处理:Pandas提供方法统一字符串格式。例如,将
'column'列的值全部转换为小写可使用df['column'].str.lower(),去除前后空格可用df['column'].str.strip()。 - 日期和时间处理:
pd.to_datetime(df['column'])可将包含日期时间信息(如dd/mm/yyyy格式)的字符串列转换为Python datetime对象,方便进一步操作。 - 列重命名:使用
df.rename(columns={old_name: new_name})可以批量重命名列,例如为不同地区或项目的数据集添加前缀或后缀,便于识别。
综合应用:自动化数据清洗管道
下面将上述方法整合成一个可复用的数据清洗管道,适用于新数据批次。假设有一个包含个人交易记录的小数据集,包含三列:姓名(name)、购买日期(date)和消费金额(value)。
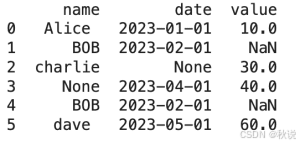
这个数据集已存储在Pandas DataFrame对象df中。
为了创建一个简单且可封装的清洗管道,可以定义一个自定义类DataCleaner,为每个清洗步骤编写方法:
class DataCleaner:
def __init__(self):
pass
def fill_missing_values(self, df):
# 前向填充 + 后向填充
return df.fillna(method='ffill').fillna(method='bfill')
def drop_missing_values(self, df):
return df.dropna()
def remove_duplicates(self, df):
return df.drop_duplicates()
def clean_strings(self, df, column):
df[column] = df[column].str.strip().str.lower()
return df
def convert_to_datetime(self, df, column):
df[column] = pd.to_datetime(df[column])
return df
def rename_columns(self, df, columns_dict):
return df.rename(columns=columns_dict)
说明:
fill_missing_values中的ffill和bfill策略分别为前向填充和后向填充,确保所有缺失值都得到处理。
接着,定义类中“核心”方法,将所有清洗步骤整合为一个完整管道。注意操作顺序应根据具体数据情况确定:
def clean_data(self, df):
df = self.fill_missing_values(df)
df = self.drop_missing_values(df)
df = self.remove_duplicates(df)
df = self.clean_strings(df, 'name')
df = self.convert_to_datetime(df, 'date')
df = self.rename_columns(df, {'name': 'full_name'})
return df
最后,使用该类一次性执行整个清洗流程,并查看结果:
cleaner = DataCleaner()
cleaned_df = cleaner.clean_data(df)
print("\nCleaned DataFrame:")
print(cleaned_df)
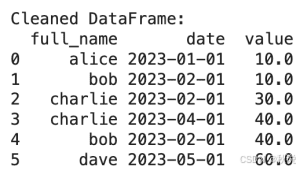
经过这套封装管道处理后,原始DataFrame被整理得更加整洁和统一。
这种封装管道的设计能够简化后续新数据批次的清洗操作,提高效率,同时保证处理过程的一致性和可复用性。


















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











