






软件安装
从北京数字绿土科技有限公司官方网站下载最新版 LiDAR360 软件,软件安装和激活请参考用户手册。
新手用户在软件的七天免费试用期内,完全有时间掌握基础操作并处理点云数据。
第一章 数据加载及其预处理
1 数据导入
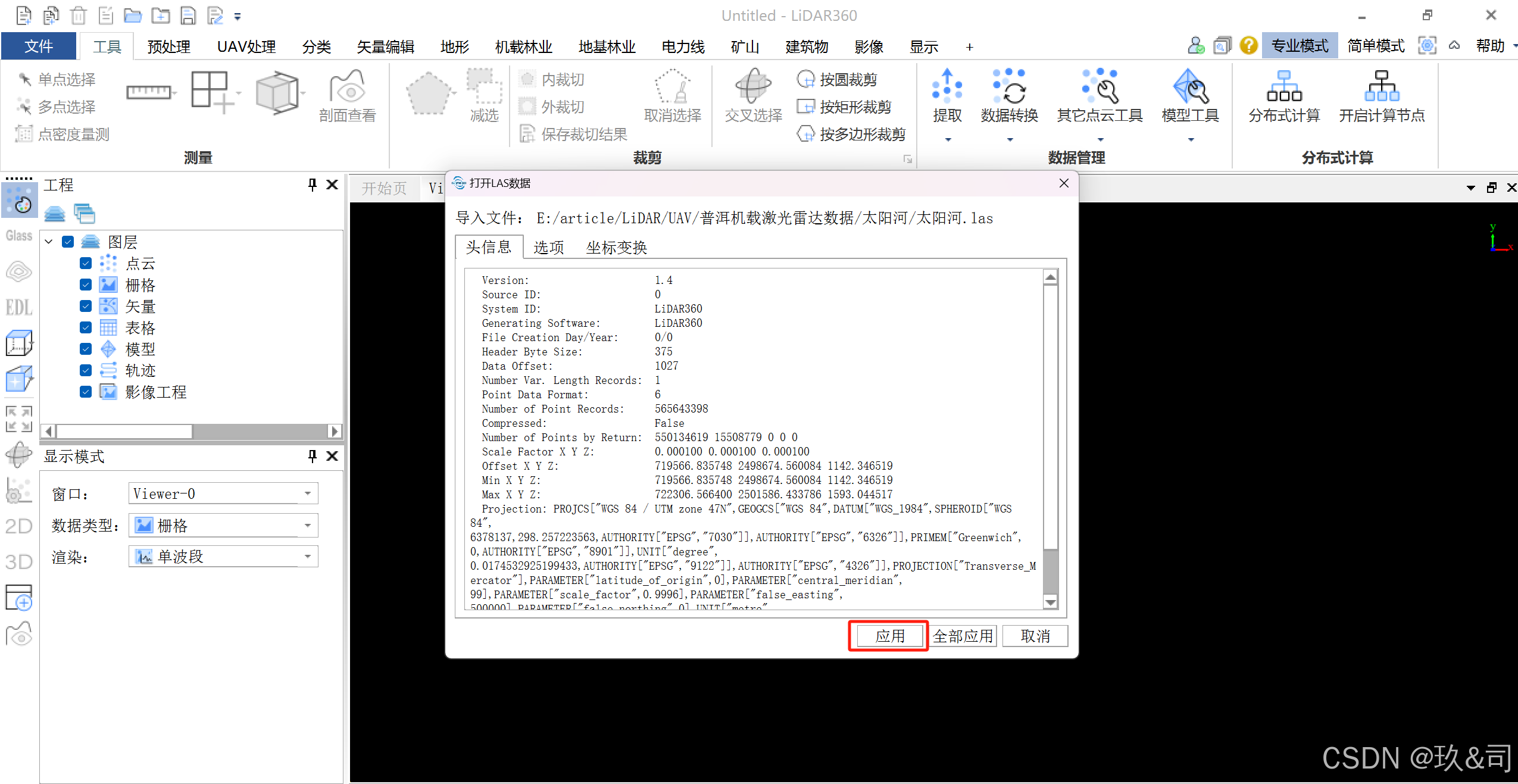
1.1 导入单个点云数据的方法为:文件 > 数据 > 加载数据,然后选择 LiDAR360 支持的点云文件格式点击确定;也可以直接将一个或多个点 云数据直接拖入到软件界面上,软件将自动加载点云数据。
拖放完毕后将会弹出下图所示的界面,此时直接单击应用即可。之 后会在相应文件夹下生成 LiData 文件,该文件将会自动加载到软件中, 之后对该点云进行的任何操作都不会影响原始的 las 文件。
2.数据的预处理
2.1去噪
点击 机载林业 > 去噪,使用默认参数设置,点击确定。
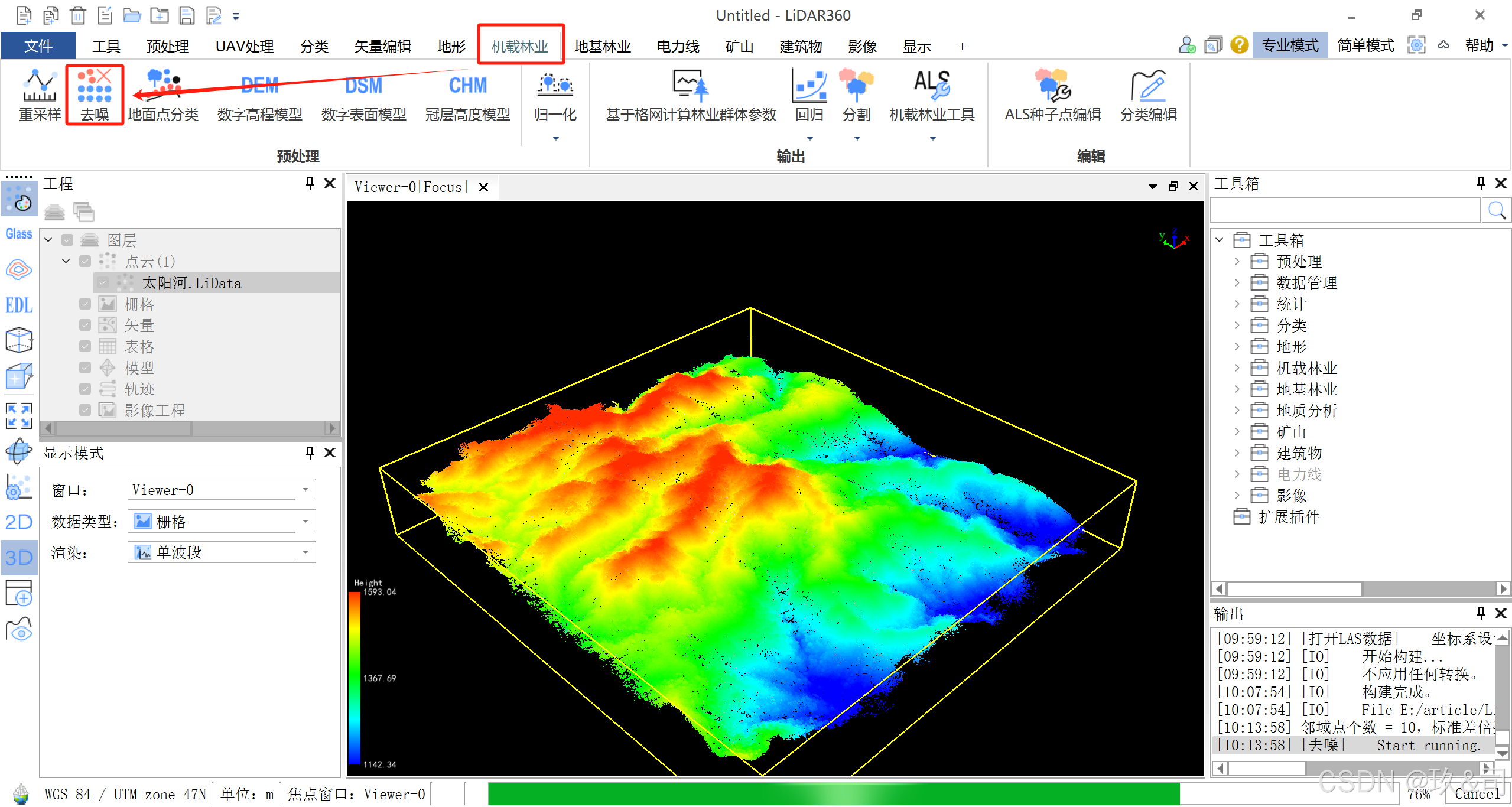
PS:这里不选择重采样的原因是,本数据之前已经预处理过,点云数据具有代表性
重采样的主要作用是减少点云数据中不必要的点数,以降低其他处理功能的计算负担。重采样可以通过不同的方法进行,包括设置最小点间距、采样率或使用Octree(八叉树)细分级别来控制保留的点数。重采样的目的是在一个较大的数据集中创建一个更小但更具代表性的点云,以便于更高效的数据处理和分析。重采样功能在数据管理模块中,可以通过点击“数据管理 > 点云工具 > 重采样”来访问。
去噪则专注于移除点云数据中的噪声点,这些噪声点可能是由于测量误差、反射异常或其他干扰因素产生的。去噪功能通过统计分析方法识别并去除这些异常点,从而提高数据的质量。去噪处理后,点云数据更加干净,为后续的分析和建模提供更准确的数据基础。去噪功能同样位于数据管理模块,可以通过点击“数据管理 > 点云工具 > 去噪”来访问。
总结来说,重采样主要是为了减少数据量并提高处理效率,而去噪则是为了提高数据的准确性和质量。两者都是点云数据处理中不可或缺的步骤。
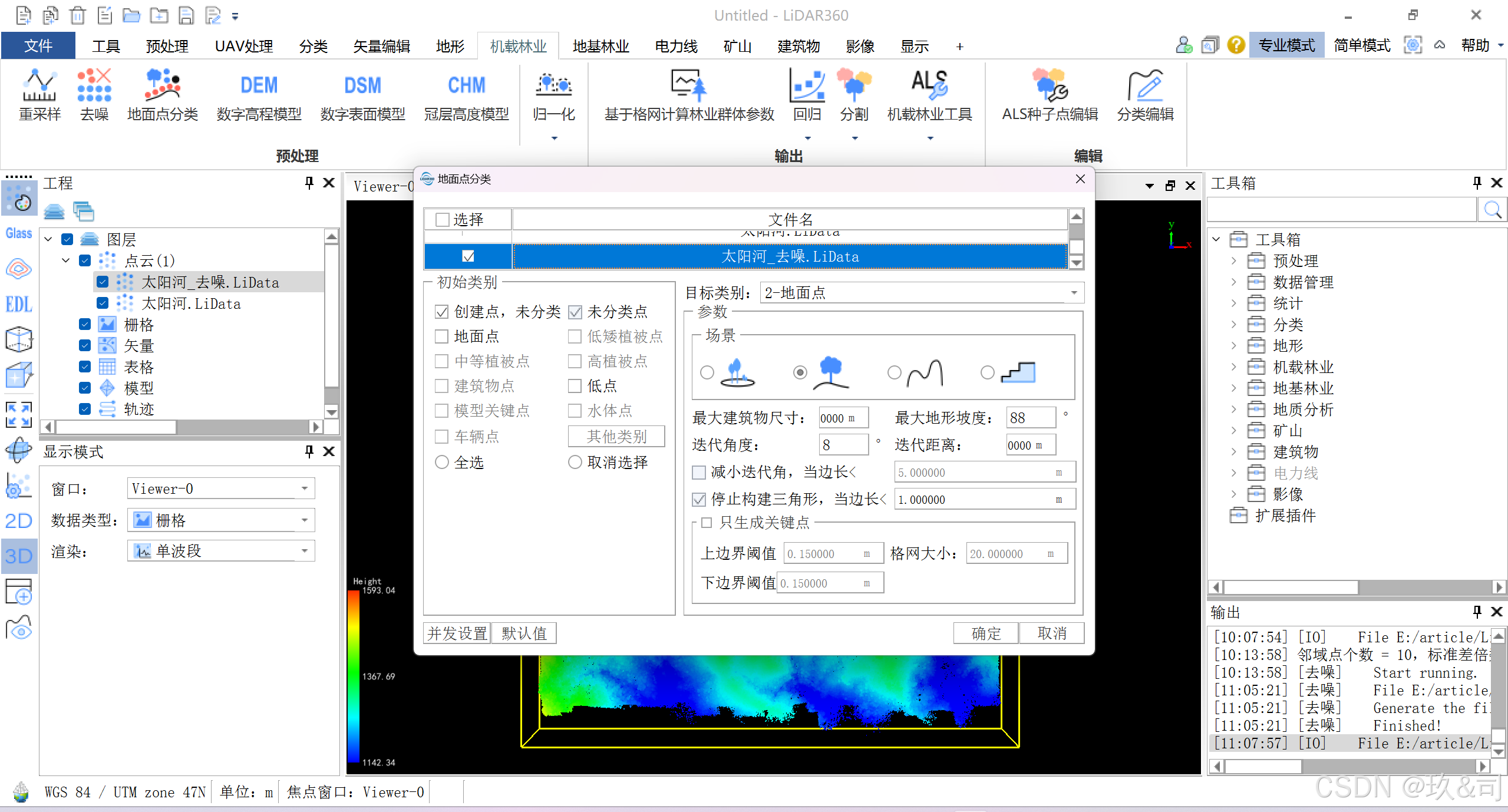
2.2点面点分类
点击 机载林业 > 地面点分类,使用默认参数设置,点击确定。

2.3生成 DEM
点击机载林业> 数字高程模型,使用默认参数设置,点击确定。
以地面点分类后的数据作为输入。分辨率大小根据自己的实验要求更改。
这里详细解释一下三种插值方法
-
反距离权重插值(Inverse Distance Weighting, IDW): 这种方法依据地理学第一定律,通过附近点计算栅格单元的值,并根据点到栅格单元中心点的距离来确定加权平均值。用户需要设置权重值,权重是采样点到像素中心距离的幂值,控制采样点高程对像素中心的影响程度。此外,可以设置可变半径或固定半径来定义各个栅格像元值插值的输入点。(想象一下,你在一个陌生的城市,想要找到最近的咖啡馆。你可能会向周围的人询问,而那些离你近的人提供的信息会比离你远的人更有影响力。IDW就是这样工作的,它认为距离我们越近的点,对我们想要预测的位置的影响越大。所以,如果你想要计算一个点的高程,你会看它周围的点,最近的点会有更大的权重。)
-
克里金插值(Kriging): 克里金插值法计算优化的协方差,并使用高斯过程插值栅格值。这种方法同样可以使用可变半径或固定半径来定义各个栅格像元值插值的输入点。克里金插值是一种地统计学方法,它模型化了空间变量的变异性,并提供了误差估计。(克里金插值更像是一个有经验的向导,它不仅考虑了距离,还考虑了地形的模式和趋势。比如,你知道山脉通常是连续的,河流通常遵循特定的流向。克里金插值会利用这些模式来预测未知点的高程,就像向导会根据地形特征带你找到目的地一样。)
-
不规则三角网插值(Triangulated Irregular Network, TIN): TIN插值方法从最近的邻近点组成的多个三角形共同形成的表面上提取栅格单元值。LiDAR360支持两种构网方式:狄洛尼(Delaunay)三角网和无凹坑TIN。狄洛尼三角网使用传统的逐点插入法构建,所有点云全部参与构网。无凹坑TIN剔除高程异常的点云,可以生成不带有明显尖峰的三角网。用户可以设置临界边长和插入缓冲区来控制三角网的构建。(想象你有一个由橡皮筋连接的点阵,这些点就是你知道高程的具体位置。当你从这些点拉伸橡皮筋,它们会形成一个不规则的三角网。TIN插值就是基于这些三角面来估算未知点的高程。这种方法很适合模拟自然地形,因为它可以捕捉到像山谷和山脊这样的复杂特征。)
这些插值方法各有优势,选择哪种方法取决于数据的特性和用户的具体需求。例如,IDW方法计算简单,适用于各种地形条件,而克里金插值则提供了更为精确的估计,特别是在数据点分布不均匀的情况下。TIN方法则适用于生成较为复杂的地形表面,能够更好地表示地形的细微变化。在实际应用中,用户可能需要根据点云数据的密度、地形的复杂程度以及对精度的要求来选择最合适的插值方法。
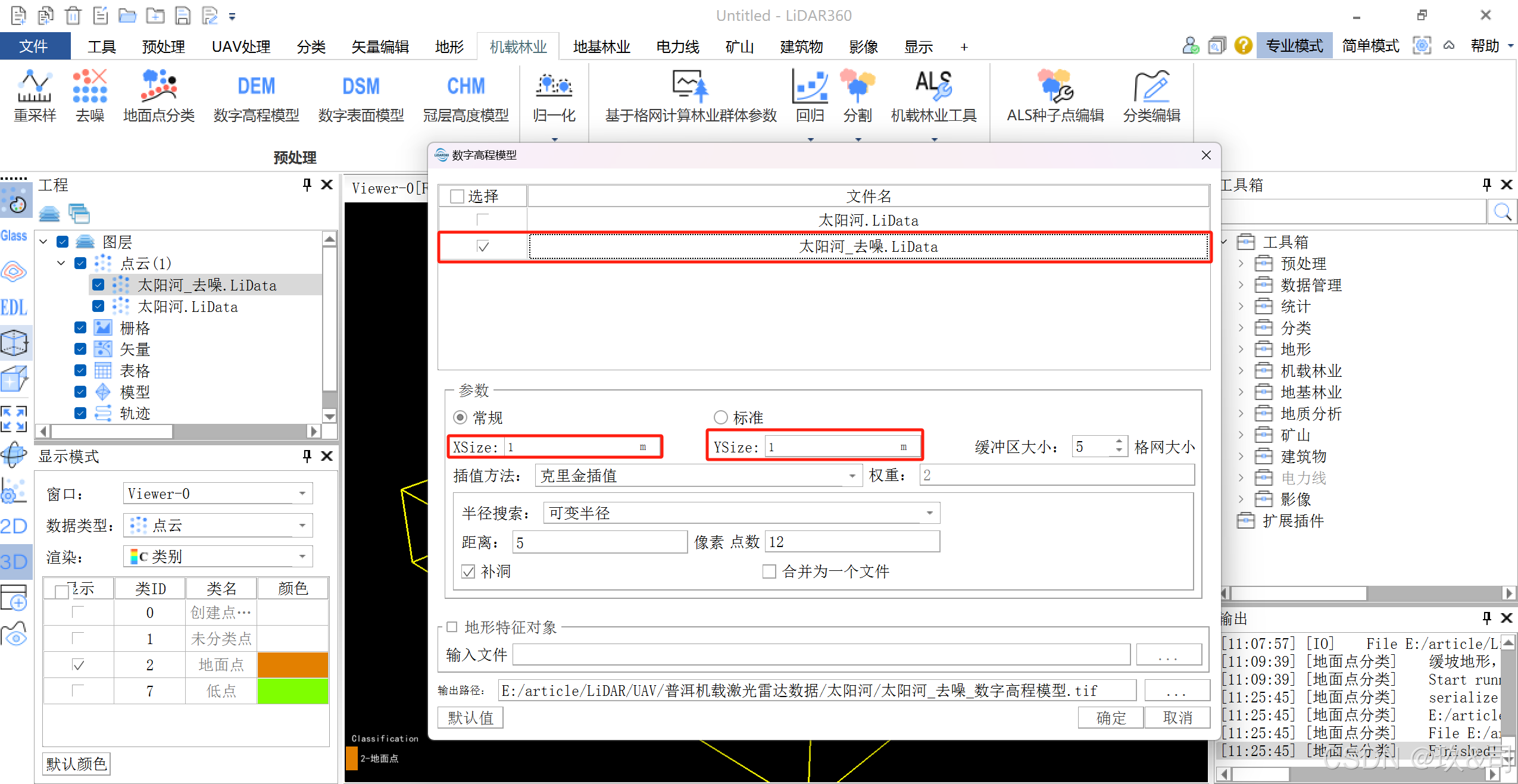

这是DEM结果,本研究使用的是第三种插值方法,因为本研究区地形起伏较大,并且点云数据过于稀疏

第二章 生成CHM
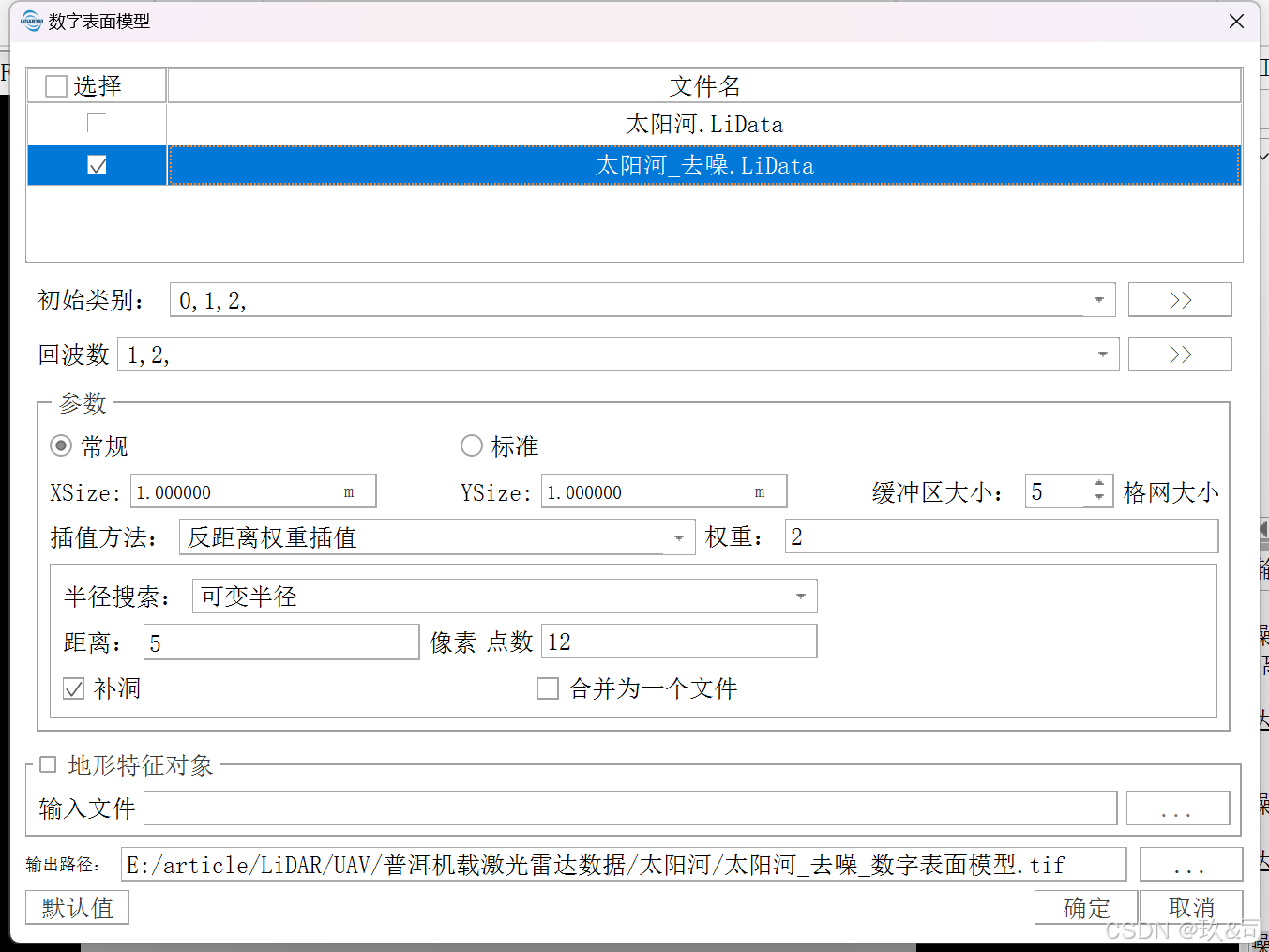
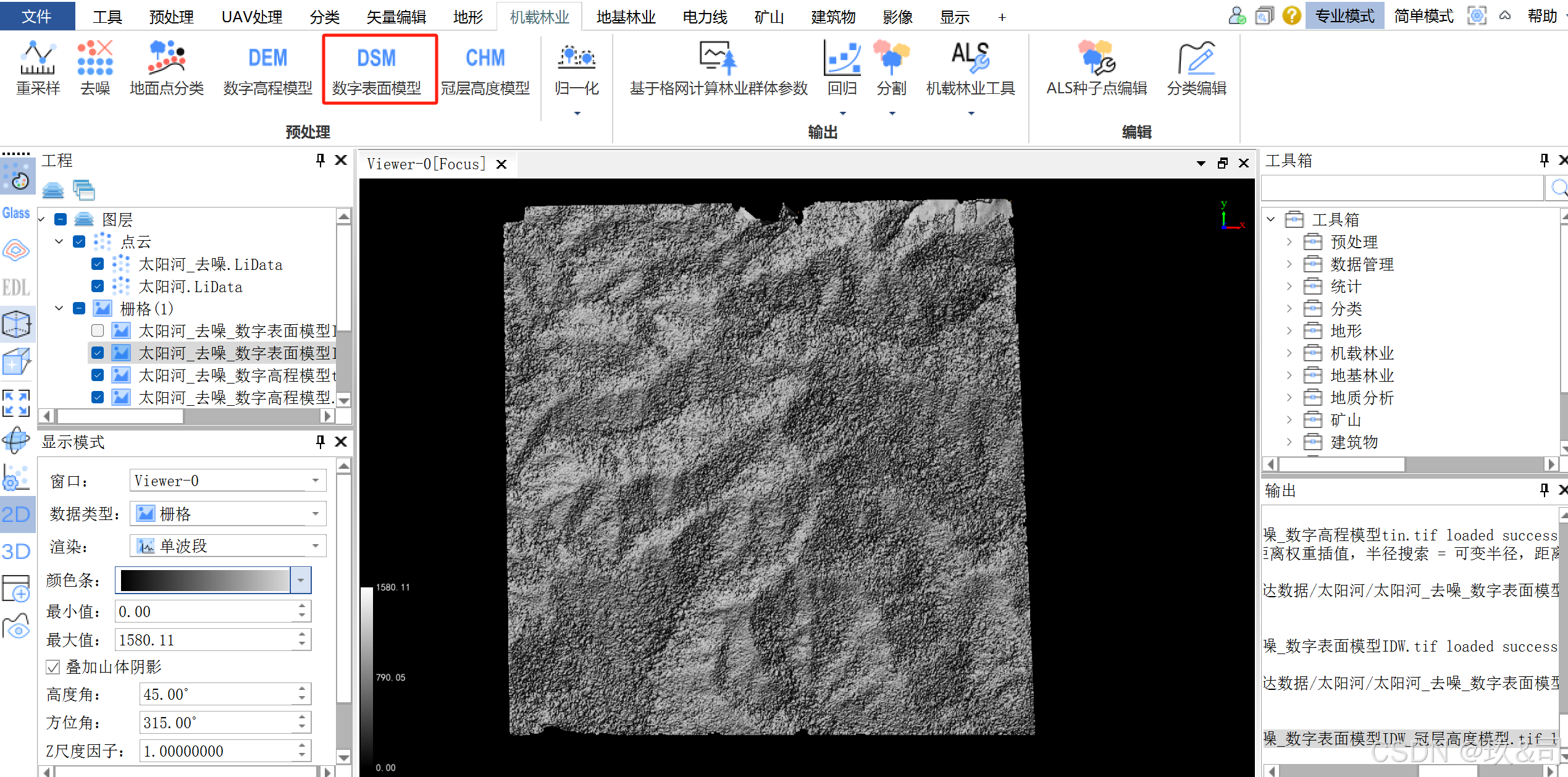
2.1生成DSM
点击机载林业 > 数字表面模型,分辨率设置为 1米(根据自己的实验需求进行设置),插值方式选择 IDW,其 他参数采用默认设置,点击确定。
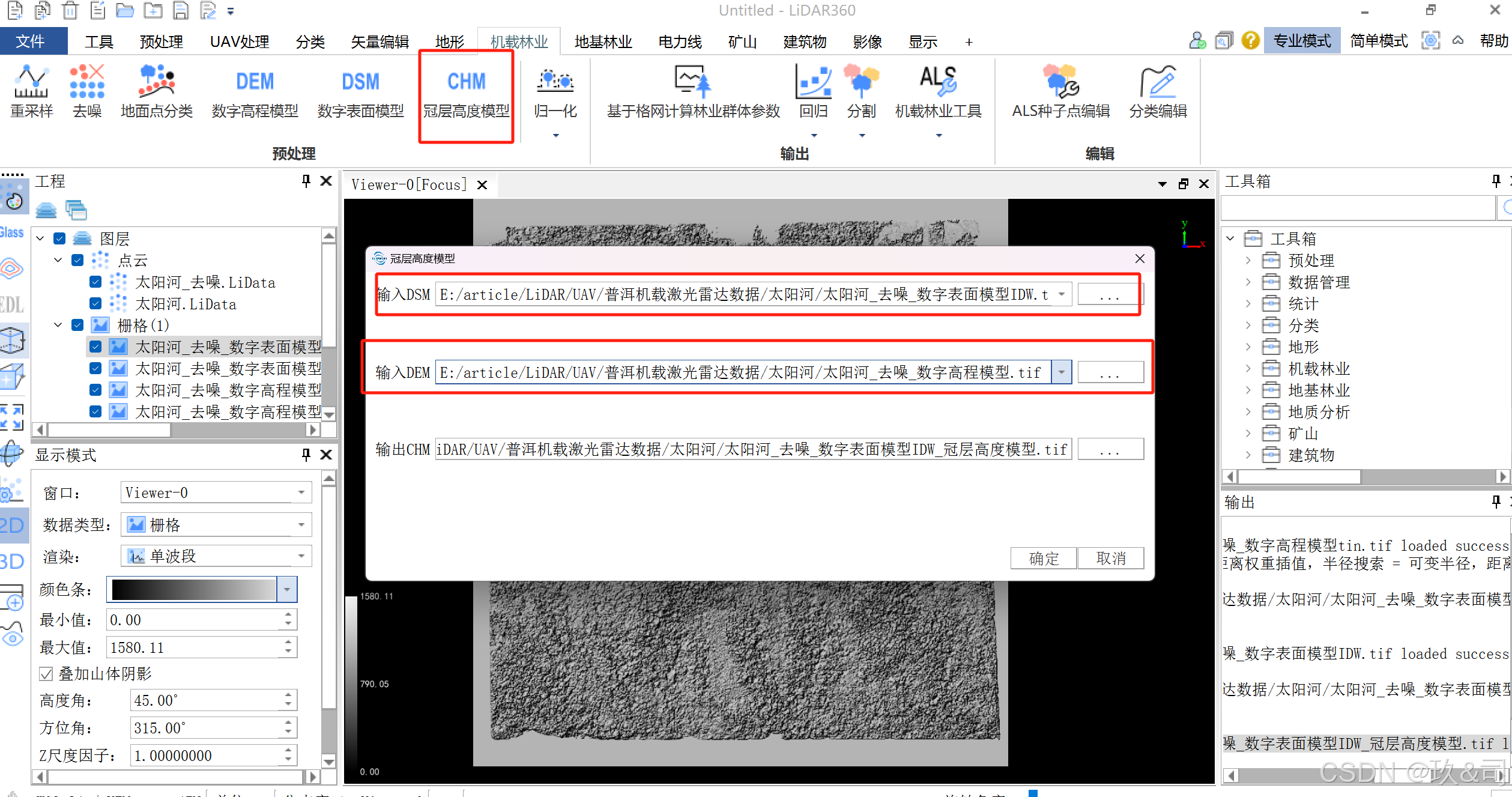
2.2 生成CHM
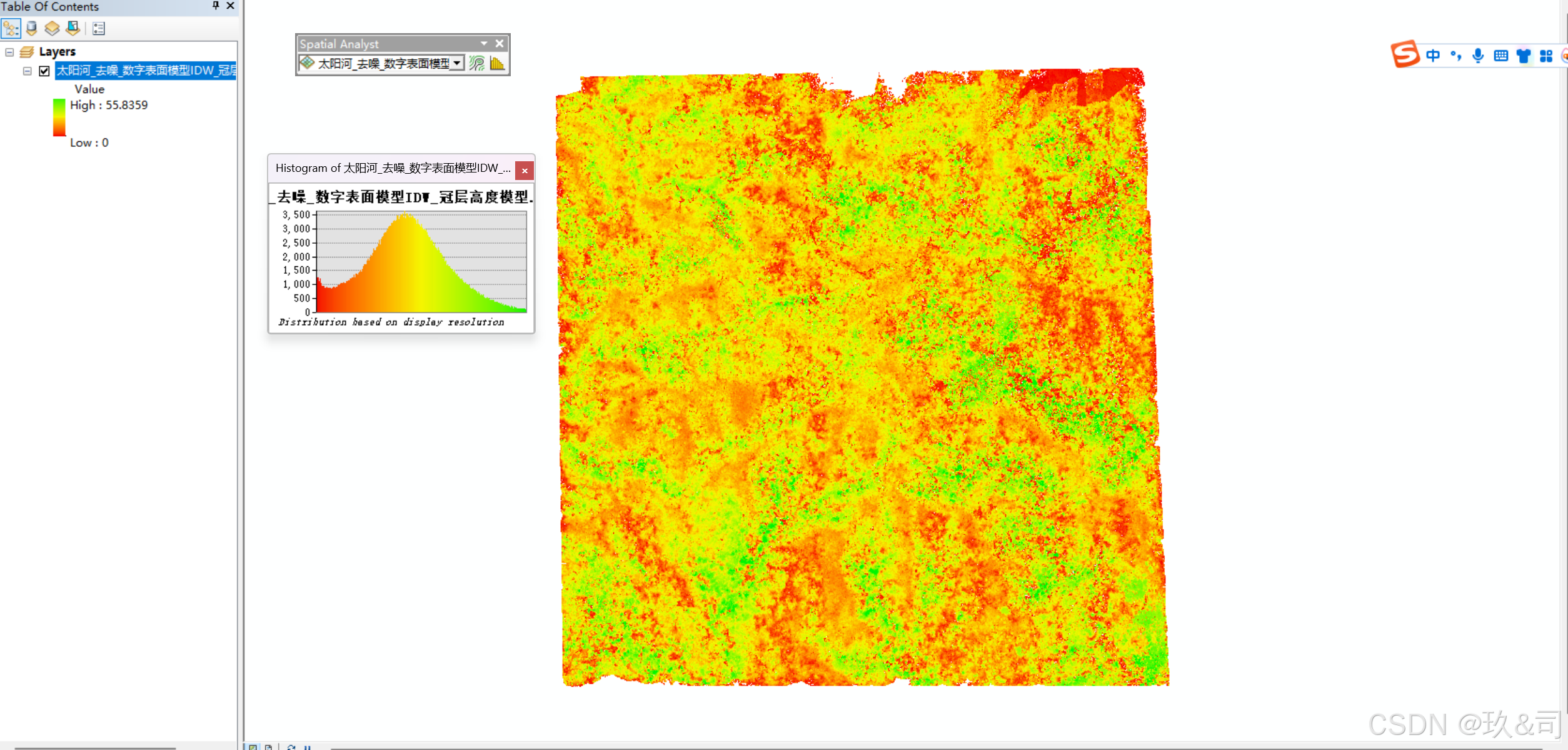
2.4导入ARCgis
当数据被导入ArcGIS并进行分析时,如果它们呈现出标准的正态分布,这通常表明数据集是准确无误的。这种分布形状说明数据点紧密围绕平均值聚集,且极端值较少,这是我们期待从精确测量中得到的结果


















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









