






继续研究一下大佬的RAG项目。开始我的碎碎念。
RAG可以分成两部分:一个是问答,一个是数据处理。
问答是人提问,然后查数据库,把查的东西用大模型组织成人话,回答人的提问。
数据处理是把当下知识库里的东西(不管是什么类型的数据),全弄成计算机话(代码能明白的格式)存到数据库,然后方便人提问的时候(也就是问答)给出可以回答的知识。
如果想让项目跑起来,必须把ES服务启动起来,该项目是用ES存的数据。
项目启动时,会先运行LoadStartup(在Springboot应用启动时),初始化向量存储(具体初始化向量存储用vectorstorage的initCollection()方法,指定名称和维度,向量维度是1024为了适配智谱AI)。总之就是自动初始化一个向量数据库的集合(Collection),用于存储后续的向量数据(如文本嵌入向量)。
我们看到LoadStartup类有一个注解@Component
所以@Service、@Repository等等这些注解,本质上都是@Component。只是根据层次有不同叫法。




这个collection是森马样子?回头再写吧。
首先,就是输入的问题。我们要存的知识不一定是什么类型,可能使txt,可能是word,甚至是pdf。那我们就需要把输入的东西先变成文本。
项目运行起来之前,点击运行下载好的es的bin文件夹下elasticsearch.bat,启动服务。
此时可以再终端看到可交互的shell命令行。这个应该是通过spring shell工具包实现的,项目的pom.xml文件里可以看到已经配置了shell的起步依赖。怎么用这个shell包呢?可以通过自己编写java类,自己做命令。前面说过把RAG分成两部分:问答,数据处理。使用add命令完成数据处理部分的工作,使用chat命令完成问答部分的工作。新建command文件夹来存放这两个类:add命令类,chat命令类。
通过 @ShellMethod 注解将 Java 方法暴露为 Shell 命令。
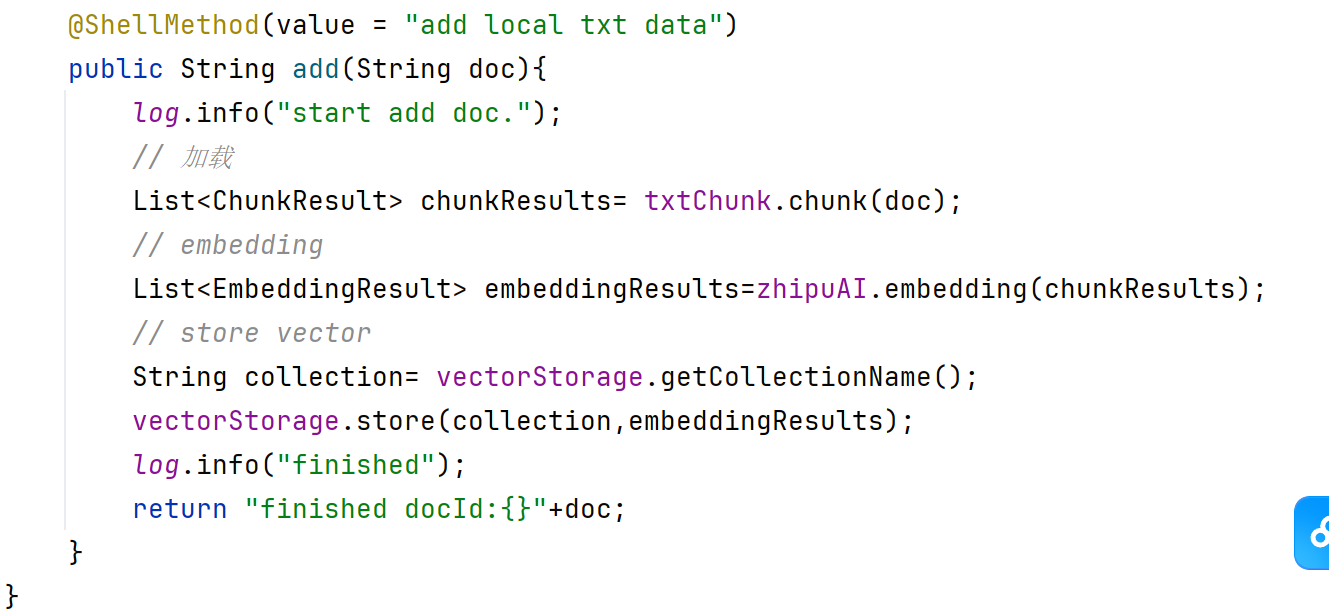
@ShellMethod(value = "add local txt data") // 声明这是一个Shell命令,描述为"add local txt data"
public String add(String doc) { // 定义命令方法,接收一个字符串参数doc(文件路径或文本内容)
log.info("start add doc."); // 打印日志:开始处理文档
// 1. 文本分块(Chunking)
List<ChunkResult> chunkResults = txtChunk.chunk(doc); // 调用分块工具,将文档拆分为多个文本块
// 2. 向量化(Embedding)
List<EmbeddingResult> embeddingResults = zhipuAI.embedding(chunkResults); // 使用智谱AI(或其他模型)将文本块转为向量
// 3. 向量存储
String collection = vectorStorage.getCollectionName(); // 获取向量数据库的集合名(类似表名)
vectorStorage.store(collection, embeddingResults); // 将向量存储到数据库中
log.info("finished"); // 打印日志:处理完成
return "finished docId:{}" + doc; // 返回处理结果(格式有误,应为String.format)
}数据处理的三步:文本分块、向量化、向量存储。最后返回结果。
这几步全调用方法,现在看是一个黑盒,知道输入输出和功能就行,后面再具体看黑盒里面的代码。
doc参数是文件内容还是文件路径搞不懂?试着输出了doc,发现是文件名。但是,根据文件名就能找着??
![]()
发现有一个默认路径/data,然后再默认路径/data下找doc文件名。找一下哪里设置的默认路径。
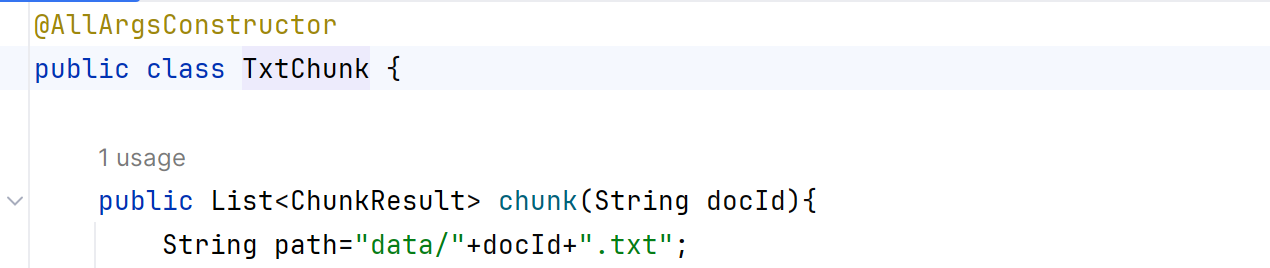
/data在chunk这里。
所以这个意思是,add 文件名。add这个方法就收到了参数doc文件名。然后进行文本分块(数据处理的具体代码放在/compoents文件夹),调用了chunk方法,然后根据默认路径+文件名+.txt,就得到一条完整的路径(相对路径)。
读取文件流classpathresource(path)


来回流转的数据,封装在对象中,而这些对象的代码都放在/domain文件夹里。
明天再写。
继续这个chunk。
然后为什么要chunk?小块文本比长文本更高效,节省计算资源。按照256个字符分割字符串。
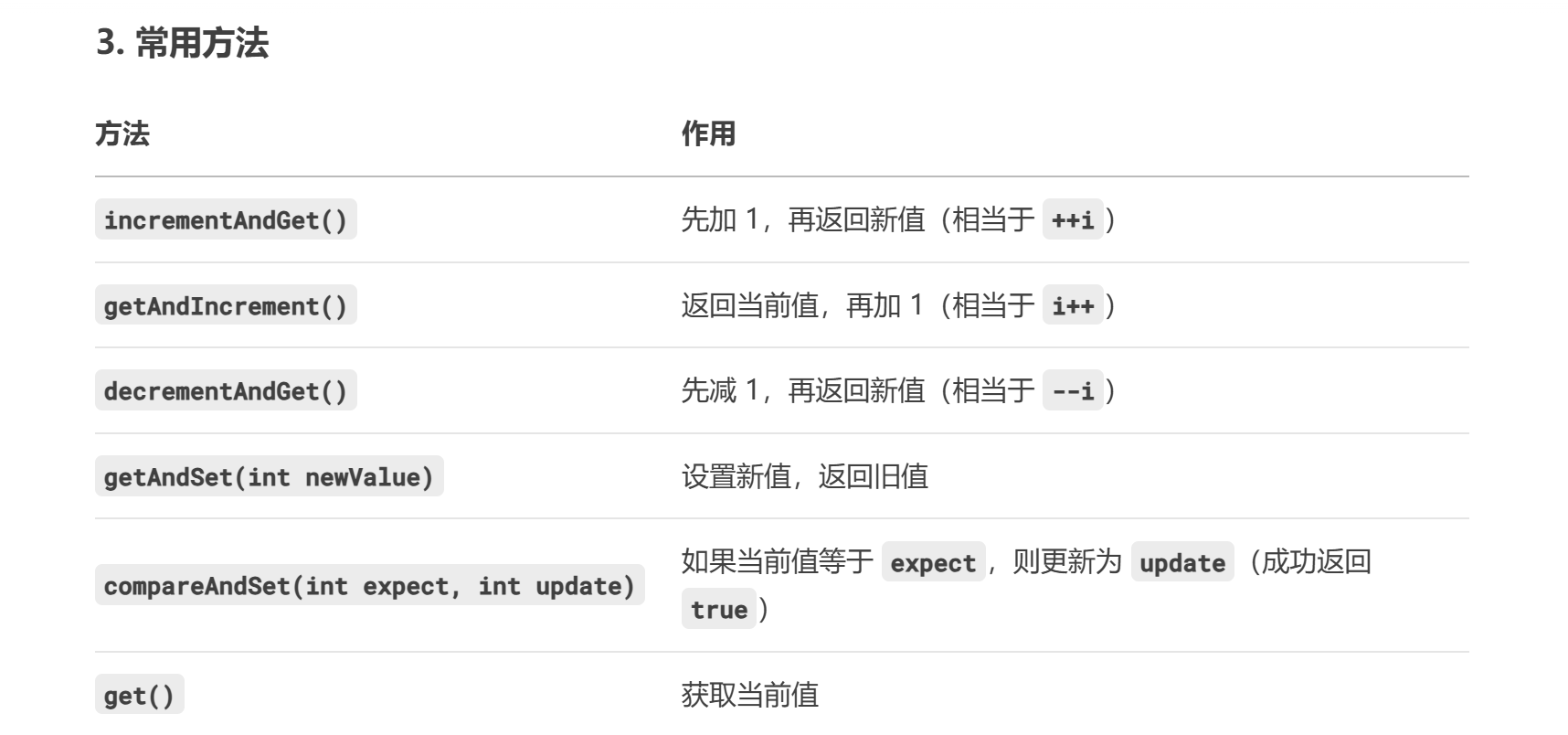
AtomicInteger是 Java 中一个线程安全的原子整数类,属于java.util.concurrent.atomic包。它的核心作用是提供原子操作(不可中断的单一操作),确保在多线程环境下对整数的操作(如递增、递减、赋值等)不会出现竞态条件(Race Condition)。
很明显,把每个chunk后的小块文本封装成一个chunkresult对象,然后返回这些对象构成的集合。
然后调用智谱AI的embedding方法。可以看到传进去的参数是chunkresult对象的集合,返回的是embeddingresult的集合。具体看embedding方法里的代码:观察集合是否为空,空的话返回空集合;非空返回embedding后的集合(这里就有一个embedding方法了)。我们具体看这个embedding方法,上一个embedding返回的是集合,这个里面embedding方法返回的单个向量化后的结果。方法的重载,参数不同。说不明白,具体看代码就懂了。
/**
* 批量
* @param chunkResults 批量文本
* @return 向量
*/
public List<EmbeddingResult> embedding(List<ChunkResult> chunkResults){
log.info("start embedding,size:{}",CollectionUtil.size(chunkResults));
if (CollectionUtil.isEmpty(chunkResults)){
return new ArrayList<>();
}
List<EmbeddingResult> embeddingResults=new ArrayList<>();
for (ChunkResult chunkResult:chunkResults){
embeddingResults.add(this.embedding(chunkResult));
}
return embeddingResults;
}
public EmbeddingResult embedding(ChunkResult chunkResult){
String apiKey= this.getApiKey();
//log.info("zp-key:{}",apiKey);
OkHttpClient.Builder builder = new OkHttpClient.Builder()
.connectTimeout(20000, TimeUnit.MILLISECONDS)
.readTimeout(20000, TimeUnit.MILLISECONDS)
.writeTimeout(20000, TimeUnit.MILLISECONDS)
.addInterceptor(new ZhipuHeaderInterceptor(apiKey));
OkHttpClient okHttpClient = builder.build();
EmbeddingResult embedRequest=new EmbeddingResult();
embedRequest.setPrompt(chunkResult.getContent());
embedRequest.setRequestId(Objects.toString(chunkResult.getChunkId()));
// 智谱embedding
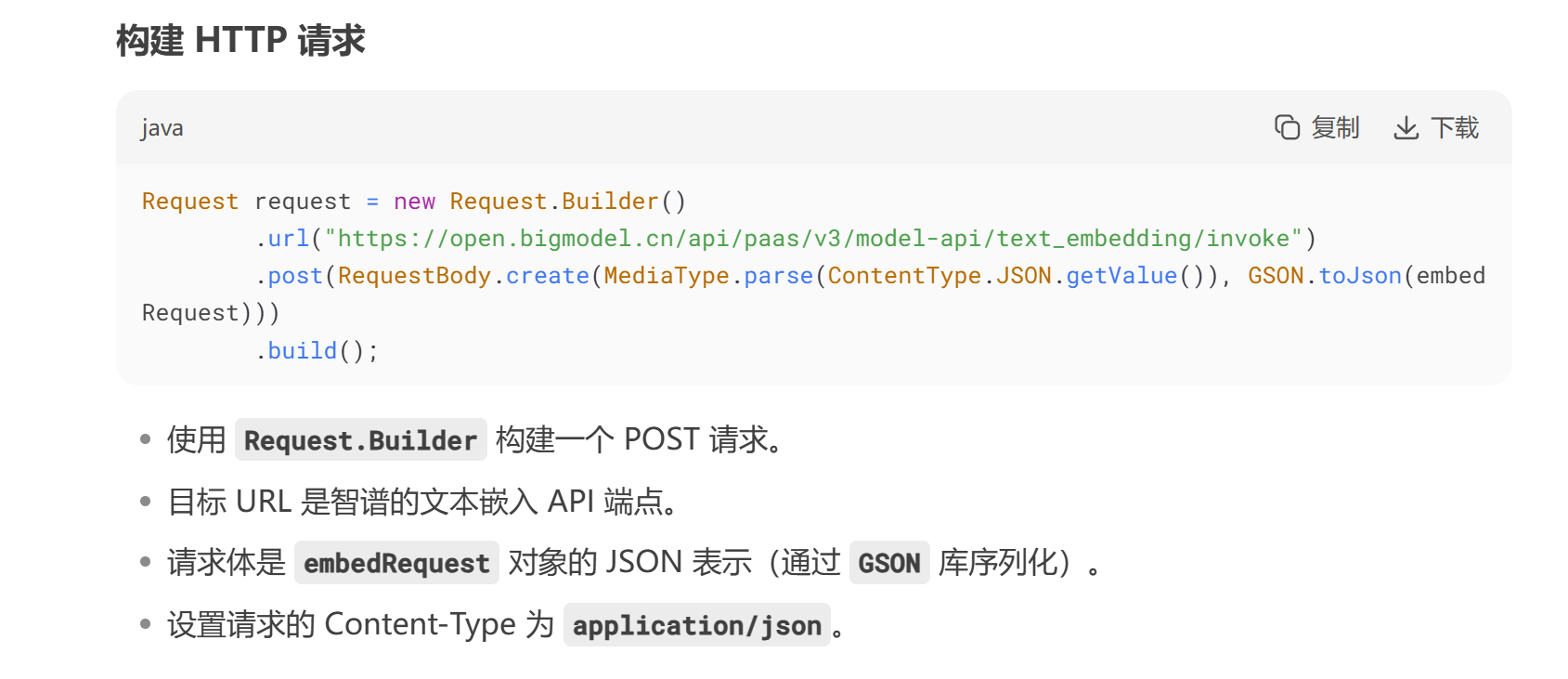
Request request = new Request.Builder()
.url("https://open.bigmodel.cn/api/paas/v3/model-api/text_embedding/invoke")
.post(RequestBody.create(MediaType.parse(ContentType.JSON.getValue()), GSON.toJson(embedRequest)))
.build();
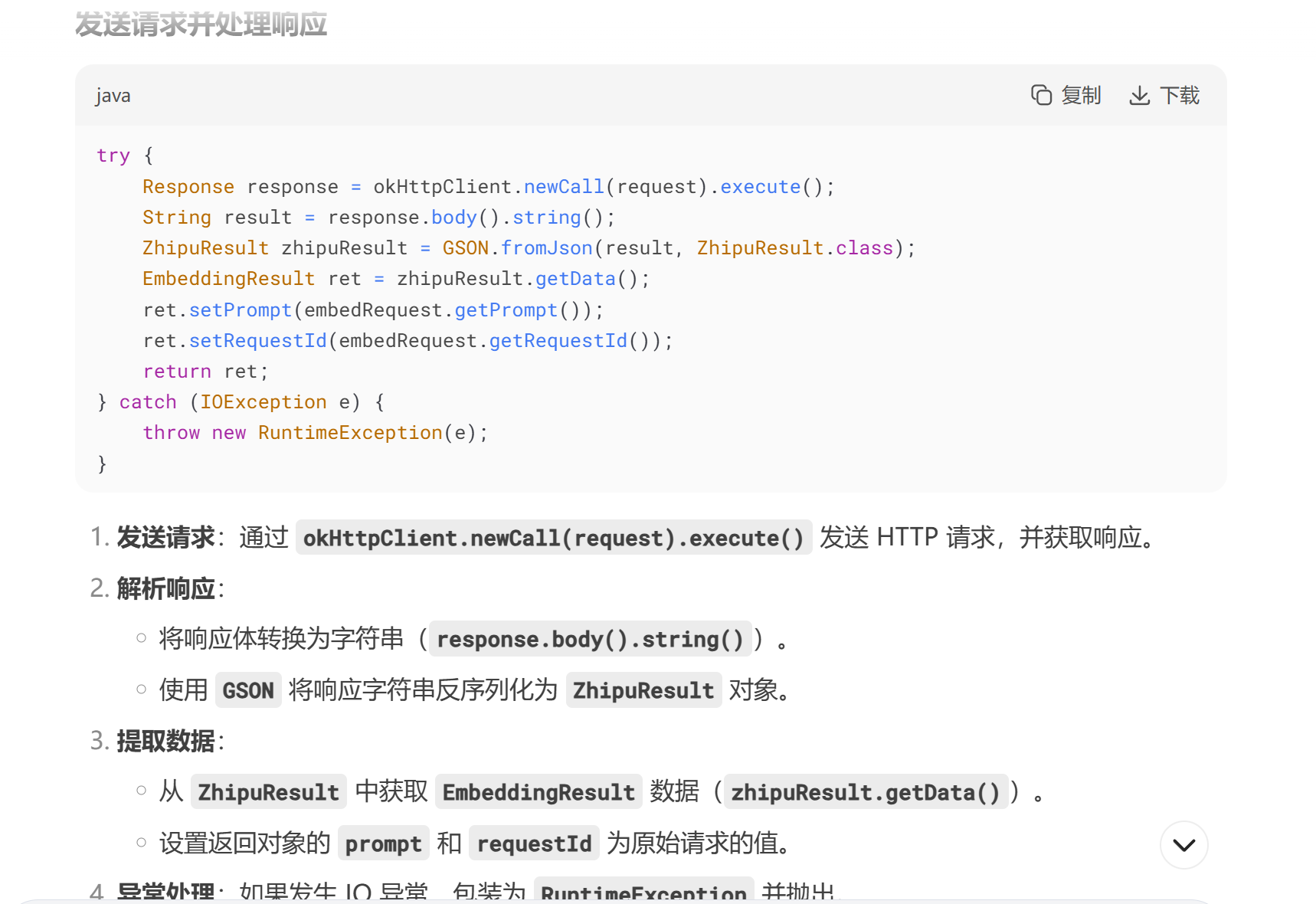
try {
Response response= okHttpClient.newCall(request).execute();
String result=response.body().string();
ZhipuResult zhipuResult= GSON.fromJson(result, ZhipuResult.class);
EmbeddingResult ret= zhipuResult.getData();
ret.setPrompt(embedRequest.getPrompt());
ret.setRequestId(embedRequest.getRequestId());
return ret;
} catch (IOException e) {
throw new RuntimeException(e);
}
}前面embedding方法只是封装成集合,就不看了。后面的embedding才是真正的向量化,重头戏。(但是人家的API咱直接用就行,embedding具体回头再看吧)
直接用的智谱的API,我们直接给参就好了。
先获取密钥。//咱们写好的getapikey方法,而它里面是调用了LLmProperties里面的东西。(回头再看吧,反正肯定这个注解指定有点东西//绑定前缀“llm”开头的配置,然后再yaml配置文件里定义属性)👇
使用 OkHttpClient.Builder 构建一个 HTTP 客户端,配置了连接、读取和写入的超时时间(均为 20 秒)。
添加了一个自定义拦截器 ZhipuHeaderInterceptor,用于在请求头中添加 API 密钥等认证信息。
创建一个
EmbeddingResult对象作为请求体。设置
prompt为输入文本块的内容(chunkResult.getContent())。设置
requestId为文本块的 ID(chunkResult.getChunkId()),转换为字符串。EmbeddingResult embedRequest=new EmbeddingResult(); embedRequest.setPrompt(chunkResult.getContent()); embedRequest.setRequestId(Objects.toString(chunkResult.getChunkId()));
我们在这里用到了一个拦截器。回头再仔细看。
Lombok 注解:简化代码。比如@AllArgsConstructor注解,就是默认全参构造。
具体见:Lombok-CSDN博客

向量化返回的结果👇是地址。。。
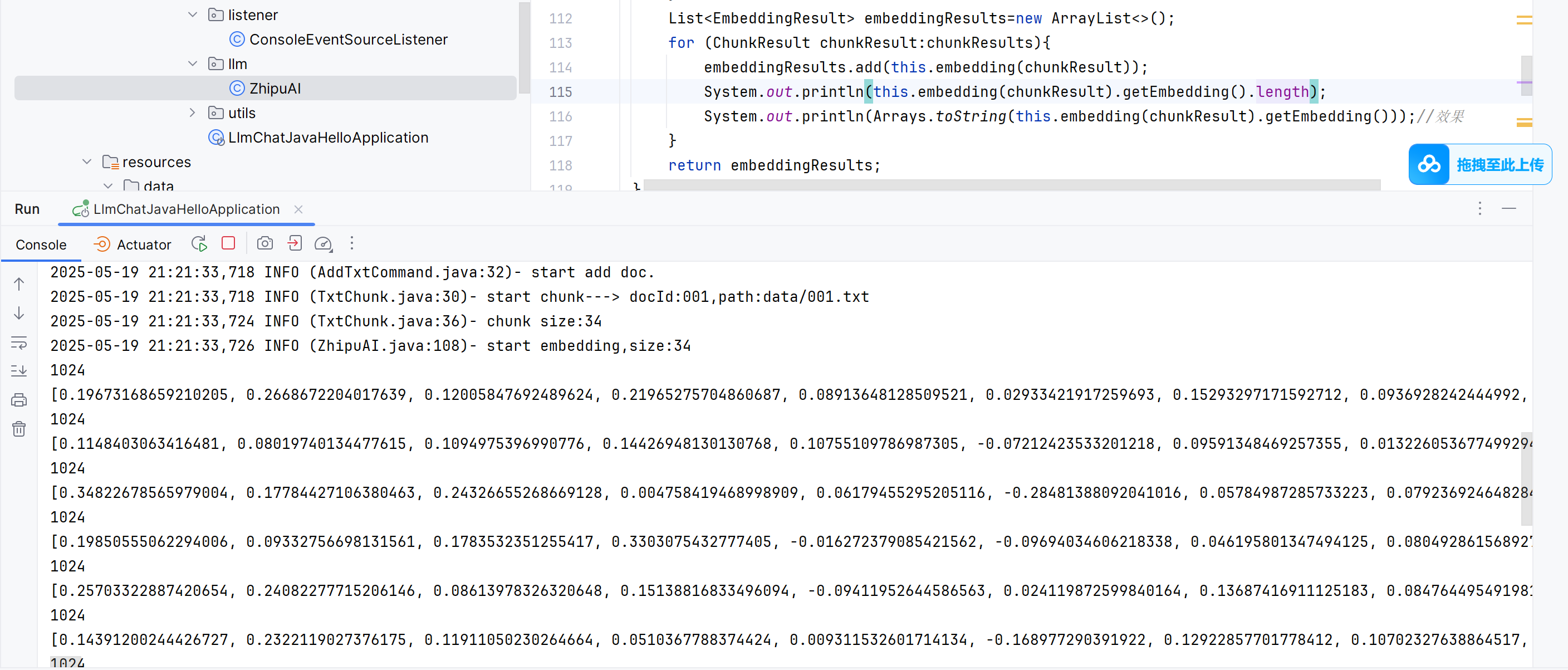
数组变成字符串打印出来👇变成这样的向量了。
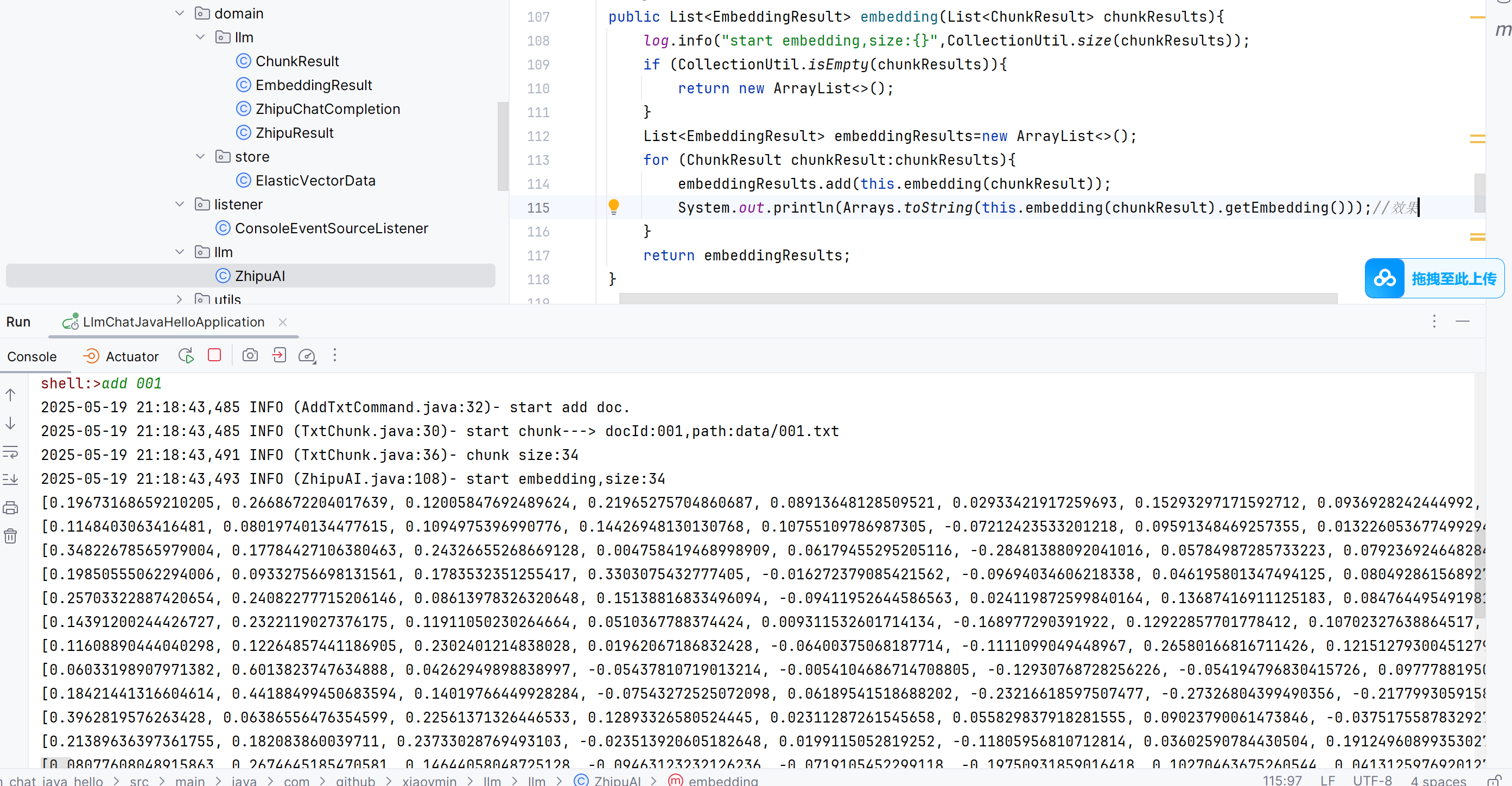
理论上每个数组大小为1024,事实上也是。具体向量怎么算的,回头看。
接下来把这些向量存起来。存在哪?怎么存?可以看到这回用到了vectorStorage,调用了它的store,参数是collectionName(下面讲//可以get得到)和embedding后的向量。(最开始我们说该项目是用ES存的)
可以看到initCollection方法的两个参数,一个是名字(固定前缀+时间),另一个是维度。传进去这俩参数,会返回一个布尔值(T or F)。initCollection在这里被调用的(可以看到维度1024)。


initCollection如果因不存在自动创建,确保提前开启ES服务。


说实话,我还是没明白。进去一个1024,返回一个map集合,这个map有什么用,为什么要叫root,回来再看。
继续写啦。
然后是store方法,很明显是把向量化的数据集合遍历一个个存进es里。
然后还有个retrieval方法,但是现在数据处理这里好像暂时没有用。那我们继续回到add这里看。
emmm,add到这里就结束了。数据处理的三部分(文本分块、向量化、向量存储)就这样完成了。
然后我们开始问答,还是通过shell命令,此时不是add命令了,而是用到chat命令。找到chat的代码,从头开始看。
向add里面只有一个add方法一样,chat这里也只有一个chat方法。输入是你的问题(字符串类型),返回的是StrUtil.EMPTY,应该调用大模型出来的人话。chat方法里面逻辑:StrUtil.isBlank(问题)判断问题是否为空,用到了糊涂包里的东西。问题为空,提示你必须输一个问题。
然后我们看到注释里写,1.问题句子转向量。2.向量召回。
很明显:
1.我们把句子里的东西也变成向量了,就像我们之前把add那些txt文本变成向量一样。

看到新建了一个分块,设了其content属性为那个问题(一般问题不会很长,一个分块肯定就能装下了),其chunkid是随机生成。我看看之前数据处理的chunkid怎么来的,欸好像是自增。
然后还是调用embedding方法,传入刚刚的chunk,目的是把分块向量化,这里的embedding和之前那个单个的embedding(不是批量embedding)一样,(因为就一个块,用不上批量)。
最后返回结果。这个结果应该是个向量数组。不过太奇怪了,之前embedding返回的对象那么全,这次怎么只返回了这个对象的embedding属性。。。
2.向量召回之前没写过。先定义Map类型的params集合,这个key全是“query_vector”告诉我们是问题向量,value是问题句子得到的向量化的一个数组,(好像知道为什么这次只返回了这个对象的embedding属性),然后计算cos值+1。

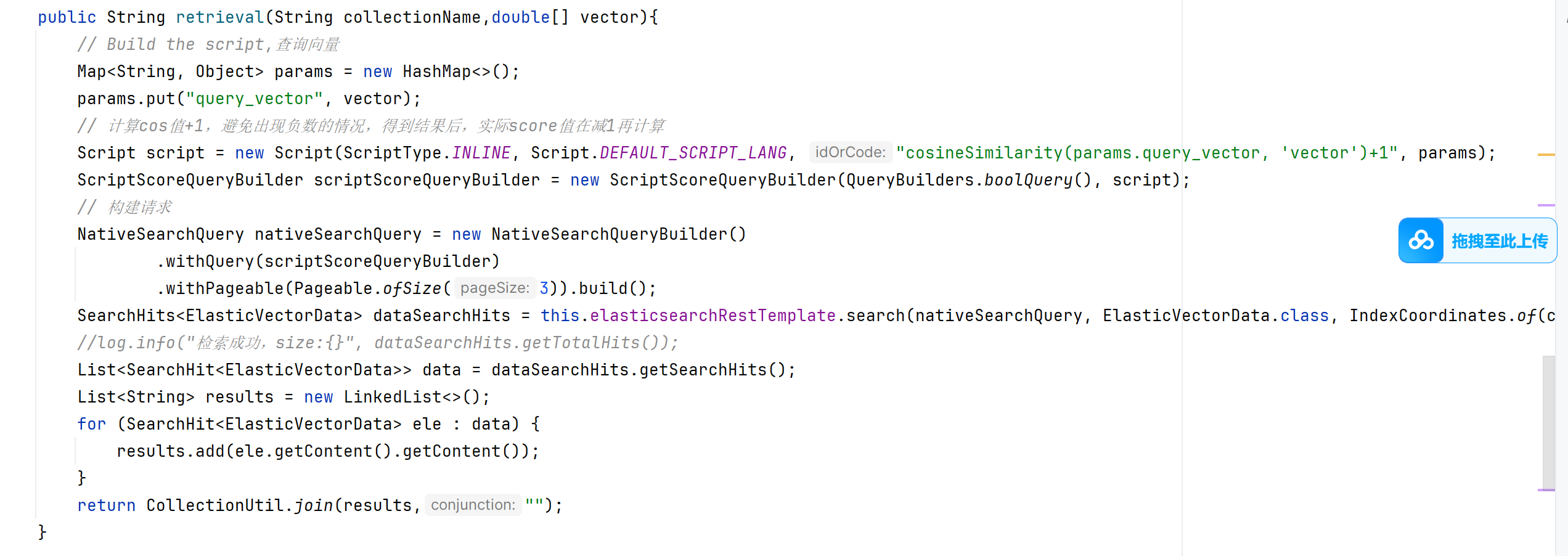

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









