






这段代码的目的是分析和优化Excel文件中的两列数据,以提高这两列数据之间的R²值(决定系数),这是一个衡量回归模型拟合优度的统计指标。具体来说,代码执行以下步骤:
-
读取数据:从指定的Excel文件路径读取数据,并提取出指定的两列(
x_col和y_col)。 -
计算初始R²值:使用
calculate_r2函数计算这两列数据的初始R²值,并打印出来。 -
迭代优化:如果初始R²值没有达到目标值(
target_r2),则开始迭代过程。在每次迭代中:- 使用线性回归模型(
LinearRegression)来拟合数据。 - 计算残差(实际值与预测值之间的差异)。
- 根据残差的标准差和设定的阈值(
threshold)来识别异常值。 - 删除异常值,并重新计算R²值。
- 重复上述步骤,直到R²值达到目标值或数据点数量不足以进行进一步的迭代。
- 使用线性回归模型(
-
绘制对比图:使用
plot_comparison函数绘制优化前后的数据对比图,以直观展示优化效果。 -
保存结果:将优化后的数据保存到一个新的Excel文件中,并打印出优化后的数据点数量和最终的R²值。
-
异常处理:如果在迭代过程中未能达到目标R²值,代码会给出警告,并提供一些建议,如减小阈值、检查数据中的系统性误差或降低目标R²值。
异常值的识别是通过计算残差(即实际值与预测值之间的差异)并使用标准差来实现的。具体步骤如下:
-
线性回归拟合:首先,使用线性回归模型对数据进行拟合,得到预测值。
-
计算残差:残差是实际值与预测值之间的差异,计算公式为:
残差=y−预测值残差
其中 y是实际值。
-
计算残差的标准差:使用NumPy的
np.std()函数计算残差的标准差,这个标准差用于衡量残差的分散程度。 -
识别异常值:根据设定的阈值(
threshold),标识残差绝对值超过该阈值倍数的点为异常值。具体判断条件为:∣残差∣>threshold×残差的标准差
这意味着,如果某个数据点的残差超过了标准差的
threshold倍数,则该点被视为异常值。
通过这种方法,代码能够动态识别并删除那些对模型拟合造成干扰的异常值,从而提高R²值,优化数据集的线性关系。
import pandas as pd
import numpy as np
from sklearn.metrics import r2_score
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
def analyze_and_optimize_r2(file_path, x_col, y_col, threshold=2, target_r2=0.995):
"""
分析两列数据的R²值,并通过删除异常值来优化R²
参数:
file_path: Excel文件路径
x_col: x轴列名
y_col: y轴列名(参考真值)
threshold: 残差阈值(标准差的倍数)
target_r2: 目标R²值,达到此值后停止迭代
返回:
优化后的数据框和最终的R²值
"""
# 读取数据
df = pd.read_excel(file_path)
print(f"原始数据点数量: {len(df)}")
# 提取需要的列
data = df[[x_col, y_col]].copy()
data = data.dropna() # 删除空值
# 计算初始R²
initial_r2 = calculate_r2(data[x_col], data[y_col])
print(f"初始R²值: {initial_r2:.6f}")
if initial_r2 >= target_r2:
print(f"R²值已经达到目标值 {target_r2},无需优化")
return data, initial_r2
# 开始迭代优化
iteration = 1
current_data = data.copy()
current_r2 = initial_r2
while current_r2 < target_r2 and len(current_data) > 2:
# 计算残差
model = LinearRegression()
X = current_data[x_col].values.reshape(-1, 1)
y = current_data[y_col].values
model.fit(X, y)
predictions = model.predict(X)
residuals = y - predictions
# 计算残差的标准差
residual_std = np.std(residuals)
# 标识异常值
outlier_mask = abs(residuals) > threshold * residual_std
if not any(outlier_mask):
print(f"没有发现新的异常值,迭代停止")
break
# 移除异常值
current_data = current_data[~outlier_mask]
# 重新计算R²
current_r2 = calculate_r2(current_data[x_col], current_data[y_col])
print(f"迭代 {iteration}: 删除了 {sum(outlier_mask)} 个点, 新的R²值: {current_r2:.6f}")
iteration += 1
# 绘制优化前后的对比图
plot_comparison(data, current_data, x_col, y_col)
# 保存结果
output_path = file_path.replace('.xlsx', '_optimized.xlsx')
current_data.to_excel(output_path, index=False)
print(f"\n优化后的数据已保存至: {output_path}")
print(f"优化后的数据点数量: {len(current_data)}")
print(f"最终R²值: {current_r2:.6f}")
# 如果未达到目标R²值,给出提示
if current_r2 < target_r2:
print(f"\n警告:未能达到目标R²值 {target_r2}。")
print("建议:")
print("1. 尝试减小threshold值")
print("2. 检查数据中是否存在系统性误差")
print("3. 考虑降低目标R²值")
return current_data, current_r2
def calculate_r2(x, y):
"""计算R²值"""
return r2_score(y, x)
def plot_comparison(original_data, optimized_data, x_col, y_col):
"""绘制优化前后的对比散点图"""
plt.figure(figsize=(12, 5))
# 绘制优化前的数据
plt.subplot(121)
plt.scatter(original_data[x_col], original_data[y_col], alpha=0.5)
plt.plot([original_data[y_col].min(), original_data[y_col].max()],
[original_data[y_col].min(), original_data[y_col].max()],
'r--')
plt.title('优化前')
plt.xlabel(x_col)
plt.ylabel(y_col)
# 绘制优化后的数据
plt.subplot(122)
plt.scatter(optimized_data[x_col], optimized_data[y_col], alpha=0.5)
plt.plot([optimized_data[y_col].min(), optimized_data[y_col].max()],
[optimized_data[y_col].min(), optimized_data[y_col].max()],
'r--')
plt.title('优化后')
plt.xlabel(x_col)
plt.ylabel(y_col)
plt.tight_layout()
plt.show()
# 运行代码
if __name__ == "__main__":
file_path = r"你的数据路径(Excel表)"
x_col = "Height" #预测数据
y_col = "样地一_" #实测数据
try:
optimized_data, final_r2 = analyze_and_optimize_r2(
file_path,
x_col,
y_col,
threshold=2, # 可以调整此值来控制异常值判定的严格程度
target_r2=0.995 # 设置目标R²值为0.995
)
except Exception as e:
print(f"错误: {str(e)}")数据优化前后散点图对比
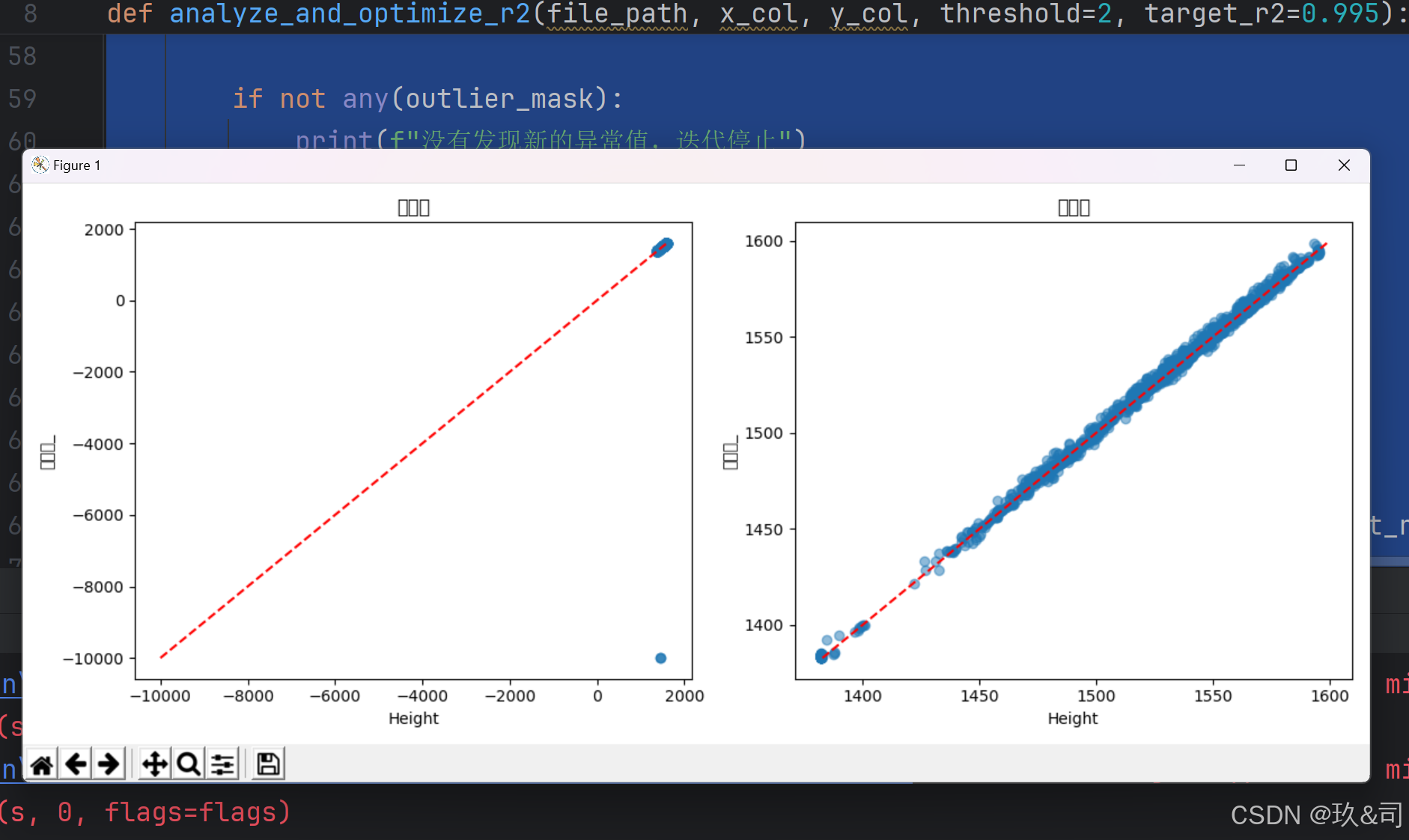
-------------------------------------------------------2024年12月27日更-------------------------------------------------
使用Z得分的方法区清洗数据
Z分数(Z-score),也称为标准分数(standard score),是一个表示元素值与平均值之间差异的度量,通常以标准差为单位。它描述了一个数据点与平均值的距离,用标准差的倍数来表示。Z分数的计算公式如下:
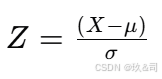
其中:
- XX 是数据点的值。
- μμ 是数据集的平均值(mean)。
- σσ 是数据集的标准差(standard deviation)。
Z分数的主要作用包括:
-
标准化数据:将数据转换为一个通用的尺度,使得不同数据集或不同量表的数据可以进行比较。
-
识别异常值:在统计学中,Z分数可以用来识别异常值。通常,如果一个数据点的Z分数大于+3或小于-3(这个阈值可以根据具体应用调整),则可能被认为是异常值。
-
理解数据分布:Z分数可以帮助我们理解数据的分布情况,比如数据点是集中在平均值附近,还是分散在平均值周围。
-
进行统计测试:在进行某些统计测试时,Z分数是一个重要的计算步骤,比如Z检验。
import pandas as pd
import numpy as np
from sklearn.metrics import r2_score
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from scipy import stats
def analyze_and_optimize_r2(file_path, x_col, y_col, threshold=3, target_r2=0.995):
"""
使用改进的异常值检测方法分析数据的R²值
参数:
file_path: Excel文件路径
x_col: x轴列名
y_col: y轴列名(参考真值)
threshold: z分数阈值
target_r2: 目标R²值
"""
df = pd.read_excel(file_path)
print(f"原始数据点数量: {len(df)}")
data = df[[x_col, y_col]].copy()
data = data.dropna()
initial_r2 = calculate_r2(data[x_col], data[y_col])
print(f"初始R²值: {initial_r2:.6f}")
# 计算相对误差
relative_error = abs(data[x_col] - data[y_col]) / data[y_col] * 100
# 使用Z分数检测异常值
z_scores = np.abs(stats.zscore(relative_error))
outlier_mask = z_scores < threshold
# 移除异常值
cleaned_data = data[outlier_mask].copy()
# 计算最终R²值
final_r2 = calculate_r2(cleaned_data[x_col], cleaned_data[y_col])
# 输出结果
print(f"移除的数据点数量: {len(data) - len(cleaned_data)}")
print(f"保留的数据点数量: {len(cleaned_data)}")
print(f"最终R²值: {final_r2:.6f}")
# 保存结果
output_path = file_path.replace('.xlsx', '_cleaned.xlsx')
cleaned_data.to_excel(output_path, index=False)
print(f"\n清理后的数据已保存至: {output_path}")
# 绘图
plot_comparison(data, cleaned_data, x_col, y_col)
return cleaned_data, final_r2
def calculate_r2(x, y):
"""计算R²值"""
return r2_score(y, x)
def plot_comparison(original_data, cleaned_data, x_col, y_col):
"""绘制清理前后的对比散点图"""
plt.figure(figsize=(12, 5))
plt.subplot(121)
plt.scatter(original_data[x_col], original_data[y_col], alpha=0.5)
plt.plot([original_data[y_col].min(), original_data[y_col].max()],
[original_data[y_col].min(), original_data[y_col].max()],
'r--')
plt.title('清理前')
plt.xlabel(x_col)
plt.ylabel(y_col)
plt.subplot(122)
plt.scatter(cleaned_data[x_col], cleaned_data[y_col], alpha=0.5)
plt.plot([cleaned_data[y_col].min(), cleaned_data[y_col].max()],
[cleaned_data[y_col].min(), cleaned_data[y_col].max()],
'r--')
plt.title('清理后')
plt.xlabel(x_col)
plt.ylabel(y_col)
plt.tight_layout()
plt.show()
if __name__ == "__main__":
file_path = r"文件路径"
x_col = "Height"
y_col = "ALS"
try:
cleaned_data, final_r2 = analyze_and_optimize_r2(
file_path,
x_col,
y_col,
threshold=3,
target_r2=0.995
)
except Exception as e:
print(f"错误: {str(e)}")

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









