








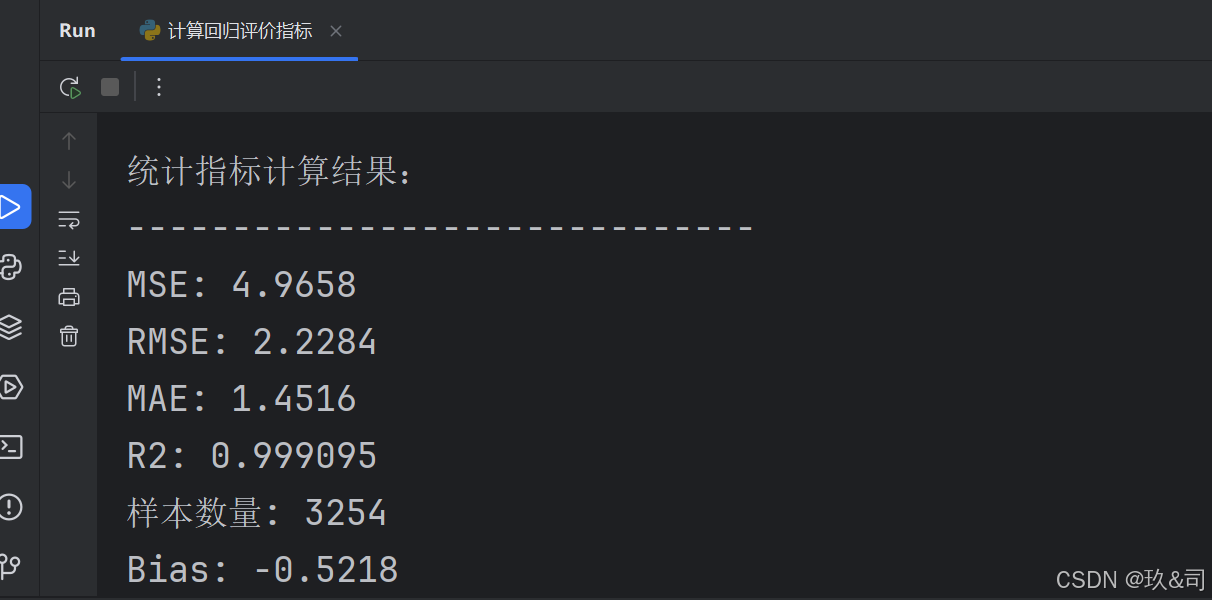
这段代码定义了一个名为 calculate_metrics 的函数,其目的是从给定的Excel文件中读取数据,并计算预测值与实际值之间的几种统计指标。这些指标包括均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、决定系数(R²)和偏差(Bias)。函数将这些指标的计算结果存储在一个字典中,并打印出来。
代码的执行流程如下:
- 读取Excel文件中的数据。
- 从数据中提取预测值和实际值。
- 计算样本数量。
- 分别计算MSE、RMSE、MAE、R²和Bias。
- 将计算结果存储在字典中,并打印出来。
- 如果在执行过程中发生错误,打印错误信息并返回None。
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
def calculate_metrics(file_path):
"""
计算预测值与实际值之间的各种统计指标
参数:
file_path: Excel文件路径
返回:
dict: 包含各种统计指标的字典
"""
try:
# 读取Excel文件
df = pd.read_excel(file_path)
# 获取预测值和实际值
y_pred = df['预测值'].values # 替换
y_true = df['实际值'].values # 替换
# 计算样本数量
n_samples = len(y_true)
# 计算MSE(均方误差)
mse = mean_squared_error(y_true, y_pred)
# 计算RMSE(均方根误差)
rmse = np.sqrt(mse)
# 计算MAE(平均绝对误差)
mae = mean_absolute_error(y_true, y_pred)
# 计算R2(决定系数)
r2 = r2_score(y_true, y_pred)
# 计算Bias(偏差)
bias = np.mean(y_pred - y_true)
# 将结果存储在字典中
metrics = {
'MSE': mse,
'RMSE': rmse,
'MAE': mae,
'R2': r2,
'样本数量': n_samples,
'Bias': bias
}
# 打印结果
print("\n统计指标计算结果:")
print("-" * 30)
for metric, value in metrics.items():
if metric in ['MSE', 'RMSE', 'MAE', 'Bias']:
print(f"{metric}: {value:.4f}")
elif metric == 'R2':
print(f"{metric}: {value:.6f}")
else:
print(f"{metric}: {value}")
return metrics
except Exception as e:
print(f"发生错误:{str(e)}")
return None
# 使用示例
file_path = r"文件路径"
metrics = calculate_metrics(file_path)计算结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









