






项目概述
关于遥感目标检测的研究主要集中在改进定向边界框的表示上,但忽略了遥感场景中呈现的独特先验知识。这种先验知识是有用的,因为如果没有参考足够远的上下文,微小的遥感目标可能会被错误地检测出来,而且不同类型的目标所需的远距离上下文可能会有所不同。在这篇论文中,我们考虑了这些先验知识,并提出了大型选择性核网络(LSKNet)。LSKNet可以动态调整其大的空间感受野,以更好地模拟遥感场景中各种目标的范围上下文。据我们所知,这是首次在遥感目标检测领域探索大型和选择性核机制。LSKNet无需任何额外功能,就在标准基准测试上设立了新的最先进的分数,即HRSC2016(98.46% mAP)、DOTA-v1.0(81.85% mAP)和FAIR1M-v1.0(47.87% mAP)。基于类似的技术,我们在2022年粤港澳大湾区国际算法竞赛中排名第二。
上述材料摘取自论文【1】Y. Li, Q. Hou, Z. Zheng, et al., Large Selective Kernel Network for Remote Sensing Object Detection, ICCV, 2023.
由此,我们可以明白这篇论文的意义:它突破了传统的边缘检测识别遥感图像的窠臼,把上下文条件加入到了训练当中。
下面是我实现推理部分(注意,只有推理)的过程和环境配置,大概算是比较详细的教程了,但请务必注意,我不清楚屏幕前的同学你是什么时候看到的这篇文章,自己配置的时候要跟着我的思路,借鉴我的代码,综合自己的情况,具体问题具体分析。
在技术迭代如此之快的情况下,我们不能把实验的成功率赌在奇奇怪怪的兼容性和落后的项目文档上!
整体架构
打开项目(GitHub - zcablii/LSKNet: (IJCV2024 & ICCV2023) LSKNet: A Foundation Lightweight Backbone for Remote Sensinghttps://github.com/zcablii/Large-Selective-Kernel-NetworkGitHub - zcablii/LSKNet: (IJCV2024 & ICCV2023) LSKNet: A Foundation Lightweight Backbone for Remote Sensing),我们可以发现它的结构如下:
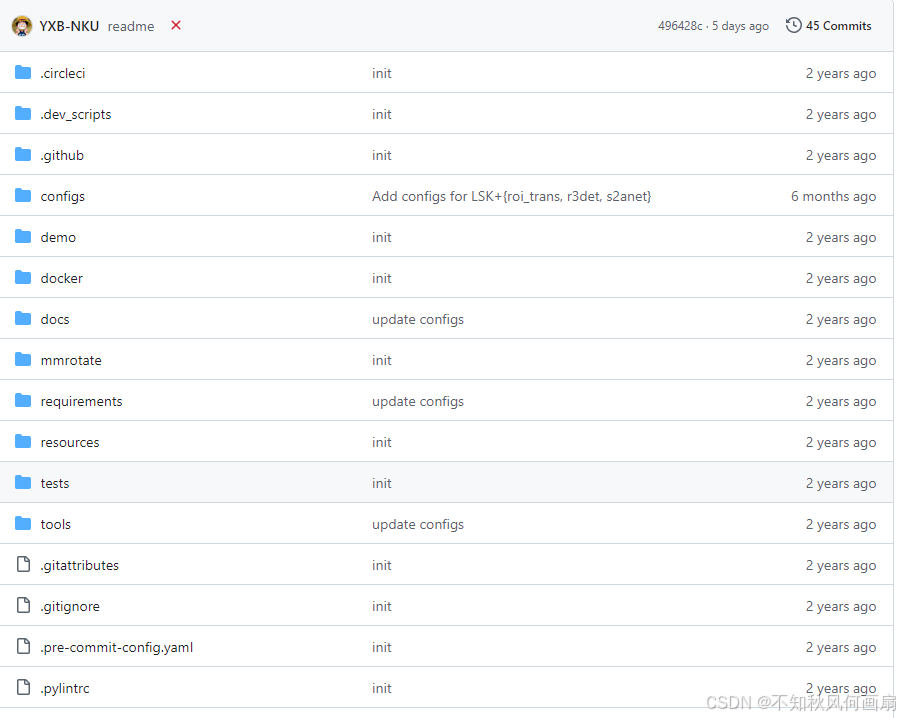
我们要知道几个重要文件:
- 框架所在地:mmrotate\models\backbones\lsknet.py
- 三个配置文件所在地:configs\_base_\datasets\dotav1.py、configs\_base_\schedules\schedule_1x.py、configs\_base_\default_runtime.py
- 运行推理的文件:tools\test.py
- 教会使用者如何运用上述文件配置的所有.md文件:从最外层的.md开始阅读。提示:.md文件不可以全信,因为现在的技术迭代很快,直接运行会出现很多错误。
配置环境
首先,我们需要知道你所在的电脑环境是什么样的。做过机器学习的同学都知道,除非本地电脑性能特别好,否则建议上网租一个云服务器。本文以AutoDL为例子,租的服务器环境如下:

当然,外部的服务器长成什么样子无所谓,因为八成跑不起来,所以我建立一个虚拟环境openmmlab2:
conda create --name openmmlab2 python=3.9 -y # 建立虚拟环境
source activate openmmlab2 #进入虚拟环境,退出后仍可重新进入如果成功进入,那么下一个命令行的开头不再是(base),而是(openmmlab2)。
在这个情况下,虚拟环境里是应该什么也没有的,但是有个地方一定要注意:
项目非常依赖CUDA和Pytorch,因此他们两个的版本一定要对应,不能冲突,否则无法下载后续mmcv包,导致项目无法运行。
那么我们要怎么检查呢?
nvcc --version # 检查CUDA版本
pip list # 查询一系列安装的包
如果两个都没有,那就先安装CUDA,然后安装与他版本兼容的Pytorch,皆大欢喜。
具体判断方式为:如果安装的是cuda10.2和Pytorch1.6.0,则如下访问
https://download.openmmlab.com/mmcv/dist/cu102/torch1.6.0/index.html
如果界面类似于下图,那么二者兼容,可以下载:

反之,如果cuda或者Pytorch版本过高,则会出现下图的结果,代表二者不兼容:
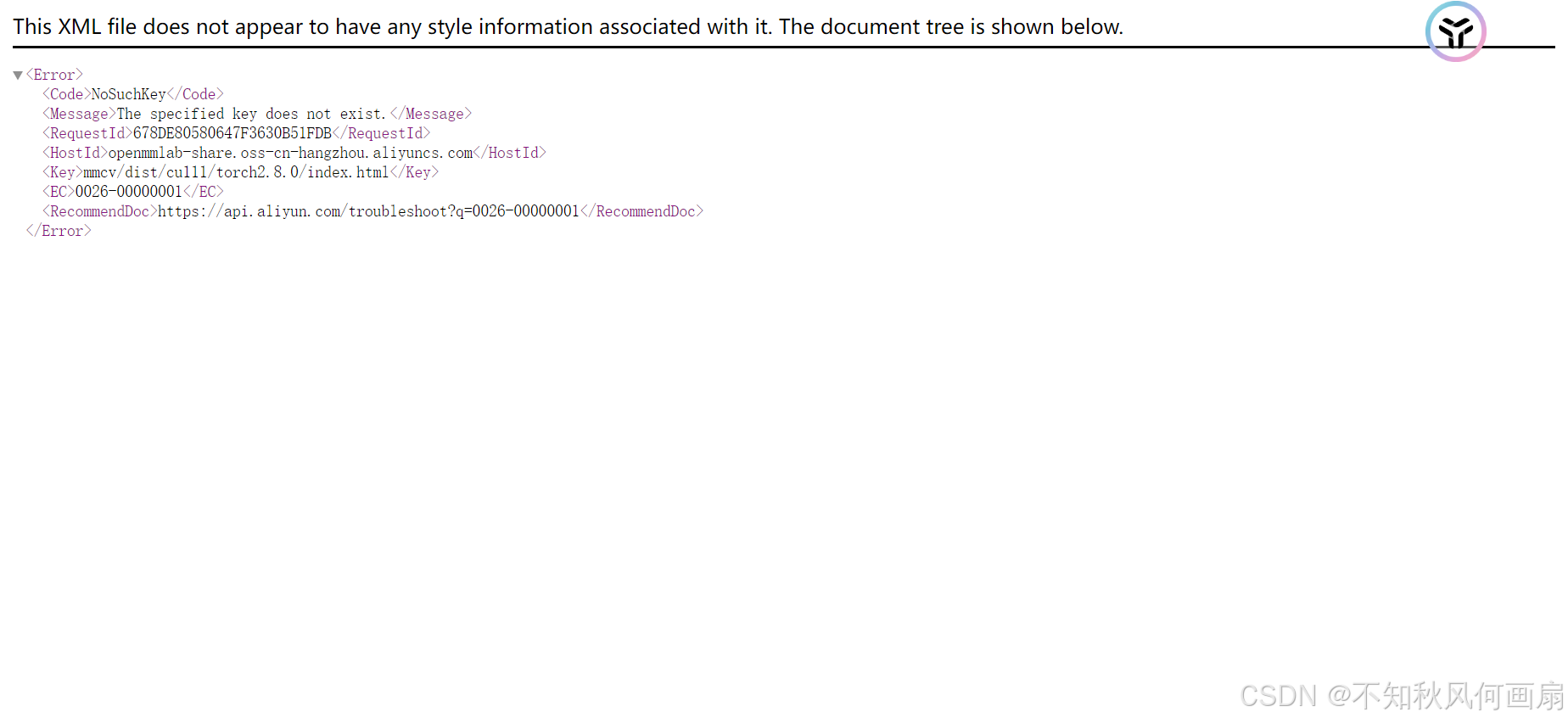
我用了cuda11.1(云服务器自带,如果没有请自己安装)和torch1.9.0(为了配合cuda)。具体什么版本并不重要,重要的是二者要兼容。
# 如果不确定是否兼容,那么就去代码里的网址查查
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html有时,系统会说类似“找不到Pytorch”的问题,我们可以运行如下代码配置:
conda config --add channels pytorch
conda config --set channel_priority strict接着,普通的安装:
pip install -U openmim然后,安装cuda和Pytorch支持的mmcv,注意改动网址里的二者版本:
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
再然后,普通安装:
pip install mmdet好了,库安装基本结束,下面让我们把项目导入数据盘(请一定注意,很多云服务器默认进入是系统盘)。
git clone https://github.com/zcablii/Large-Selective-Kernel-Network.git注意,很多云服务器无法访问github,固然我们可以大力出奇迹,下载zip到本地之后再上传,但我有一个更好的办法:GitHub 文件加速代理 - 快速访问 GitHub 文件可以把国外的网址变成国内的映像,从而完成克隆操作,比如:
https://gh-proxy.com/github.com/zcablii/Large-Selective-Kernel-Network
最后,进入到目录里再安装剩余的包:
cd Large-Selective-Kernel-Network # 进入项目目录
pip install -v -e . # 据说一定要有,不知原因,但请务必执行
pip install -r requirements.txt # 这是项目中配置的依赖,在安装过程中会报错,请看下一小节
pip install timm # 普通的安装技术细节
关于requirements.txt,它堪称是罪恶之源,它主要有两个问题:
- 我前文说过,现在的技术更新迭代很快,很多版本不向下兼容,而本项目的依赖没有把版本锁定死,因此执行安装的时候不会报错,但是实际上在正式执行的过程中可能会出现这种现象:
A module that was compiled using NumPy 1.x cannot be run inNumPy 2.0.2 as it may crash. To support both 1.x and 2.xversions of NumPy, modules must be compiled with NumPy 2.0.Some module may need to rebuild instead e.g. with 'pybind11>=2.12'怎么解决呢?最简单的办法,把numpy卸载了,然后装一个新的。
# numpy不合适就用这个 pip uninstall numpy pip install numpy==1.24 - 在上文我也提到过,有些、或者说大部分云服务器访问不了github,对此,我还是提出了那个找国内镜像的做法:
我们找到requirements.txt里记载的文件位置:
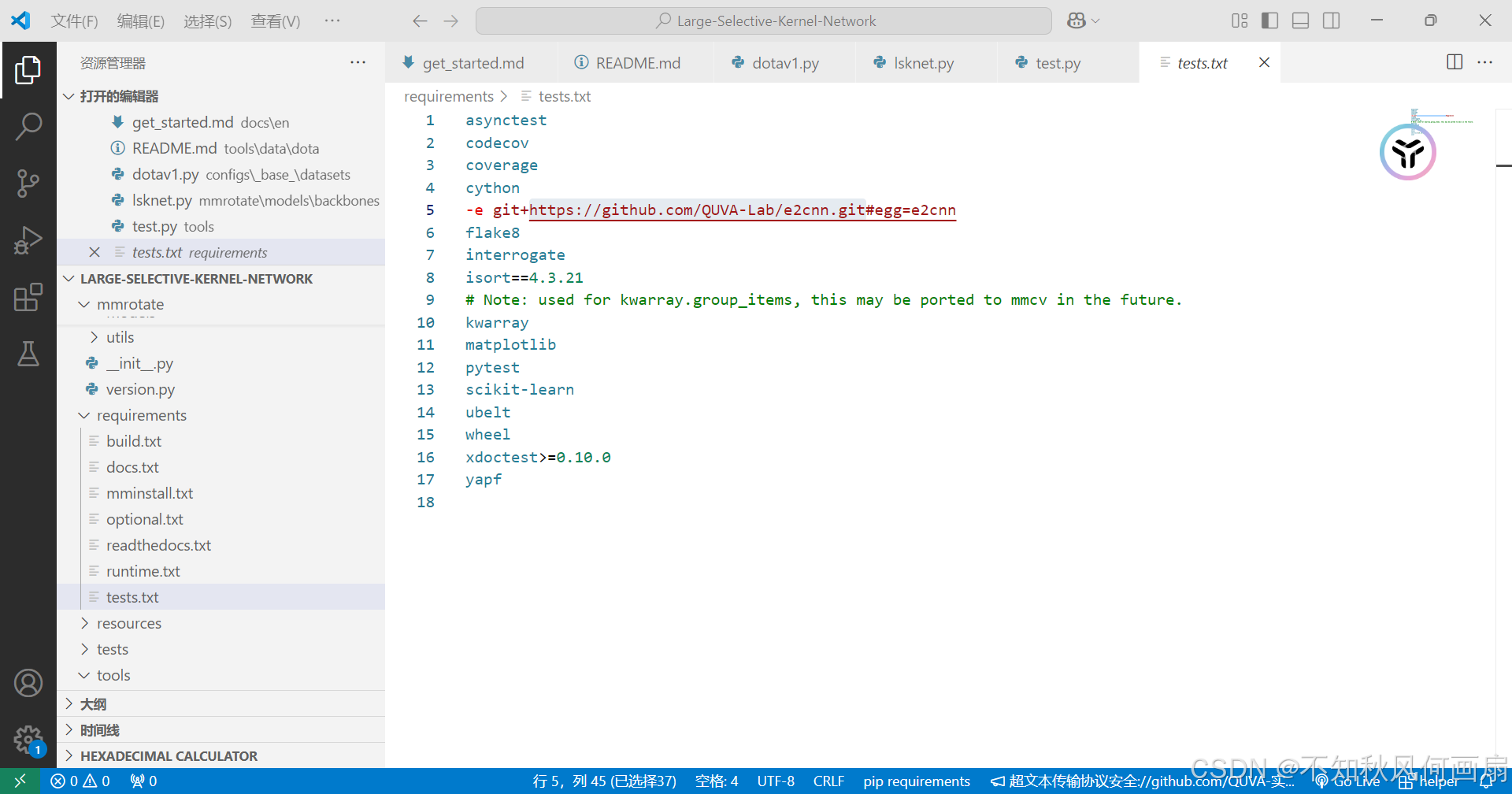
我用鼠标选中的部分转换成国内镜像https://gh-proxy.com/github.com/QUVA-Lab/e2cnn.git就可以了。注意,涉及到github的文件不止一个。
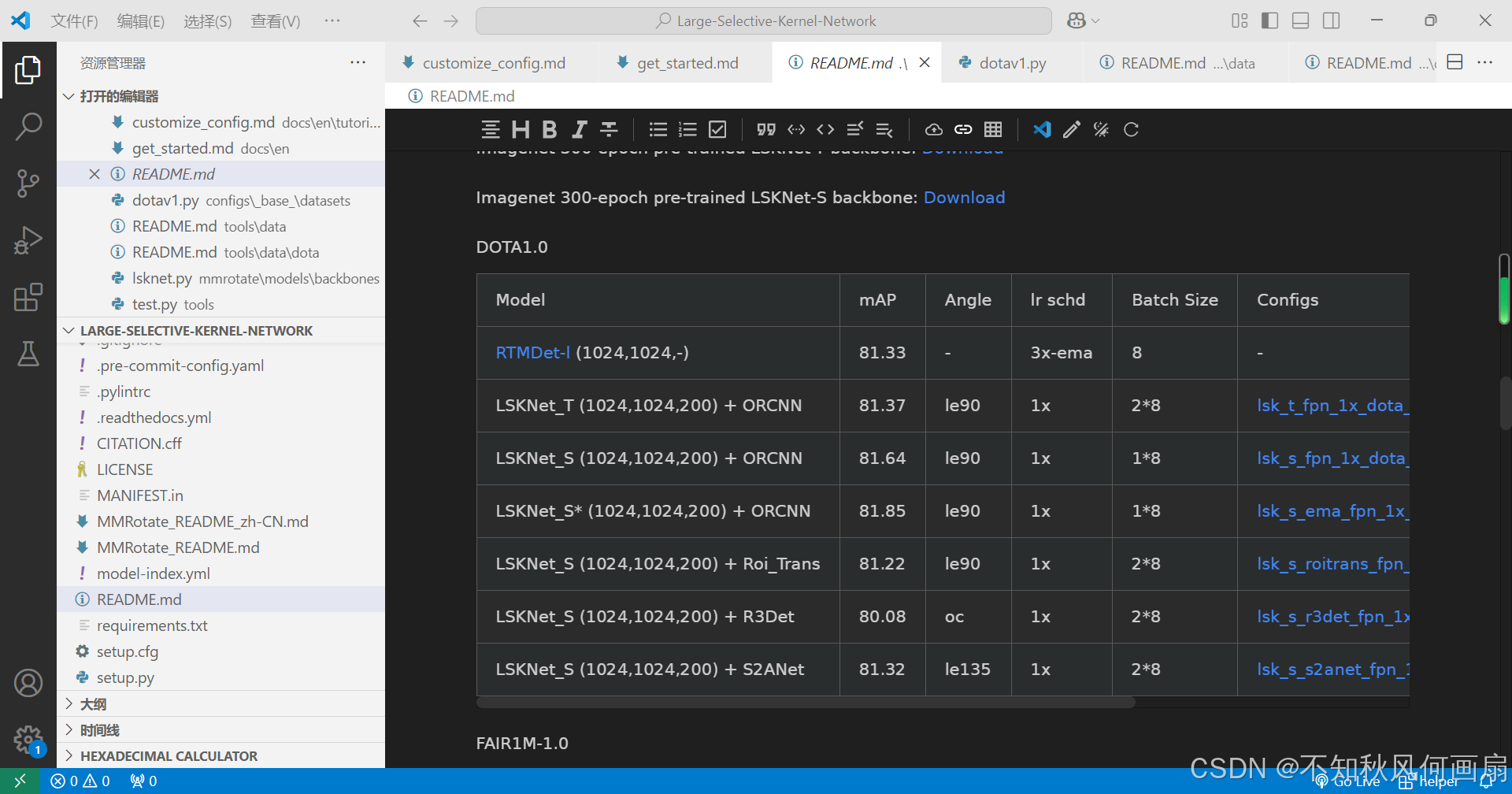
关于推理,很多朋友可能会问,没有训练可以有推理吗?答案是可以,只不过需要下载权重。在这个表格里的.pth文件就是权重文件,点击后面的model就可以下载,下载之后把文件放在指定路径下(后文的执行推理会提到)。
注意,在这里选择了哪个模型,下文的代码对应的配置路径也得改成相应的模型的配置文件!
关于数据集,也可以在项目中的DOTA找到,但要注意的是,下载来的是数据集的网站,而非真正的数据集。真正的数据集是一个百度网盘或者google里的文件夹装着的压缩包,非常大。上传很费时间。
此外,还需要更改configs\_base_\datasets\dotav1.py的data_root目录指向数据集的根节点和指向数据集中test的目录,用相对路径。
在运行前,务必根据自己的目录和我的注释执行以下split:
# --img-dir后的目录是test数据集所在,--ann-dirs之后的目录指向标注的txt集合,这里默认为none。这是ms_test.json和img_split.py的规定
#ms代表多尺度,ss代表单尺度,可以选择不同json文件
python tools/data/dota/split/img_split.py --base-json tools/data/dota/split/split_configs/ms_test.json --img-dir ../dataset/dota/test/images最后,根据自己的目录和我的注释运行:
# checkpoints/lsk_s_fpn_1x_dota_le90_20230116-99749191.pth是下载的权值文件所在的路径
# configs/lsknet/lsk_s_fpn_1x_dota_le90.py是对应的模型
# --show-dir是要显示东西放在那个目录下
python ./tools/test.py configs/lsknet/lsk_s_fpn_1x_dota_le90.py checkpoints/lsk_s_fpn_1x_dota_le90_20230116-99749191.pth --format-only --eval-options submission_dir=work_dirs/Task1_results --show-dir work_dirs/vis_ms小结
总之,我这篇文章向大家阐明了环境的配置和推理的完成,在最后我强调两点:
1.请所有执行操作在虚拟环境中,./Large-Selective-Kernel-Network下完成
2.请注意改动命令行中的参数,如果虚拟环境配置错误,可以参考以下代码删除环境
conda remove --name openmmlab2 --all # 删除环境3.如果一次运行不成功或者中途中断,他会创建一个文件,之后存储的时候会说“该文件已存在”,参考以下代码慎重删除:
#我写的是我的路径,这里写自己的,别乱删
rm -rf /root/autodl-tmp/Large-Selective-Kernel-Network/data/split_ss_dota/test
rm -rf /root/autodl-tmp/Large-Selective-Kernel-Network/work_dirsPS:桀桀,想不到吧,我的帖子还在更新!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









