






一、概要与相关工作
最近关于遥感目标检测的研究主要集中在改进定向边界框的表示上,但忽略了遥感场景中呈现的独特先验知识。这种先验知识是有用的,因为如果没有参考足够远的上下文,微小的遥感目标可能会被错误地检测出来,而且不同类型的目标所需的远距离上下文可能会有所不同。
在这篇论文中,我们考虑了这些先验知识,并提出了大型选择性核网络(LSKNet)。LSKNet可以动态调整其大的空间感受野,以更好地模拟遥感场景中各种目标的范围上下文。据我们所知,这是首次在遥感目标检测领域探索大型和选择性核机制。
简单来说,这篇文章的创新点主要在于它启用了上下文关系和先验知识,而不是单纯地做边缘检测和计算:
航空图像通常是从高空视角以高分辨率捕获的。特别是,航空图像中的大多数物体可能很小,仅凭外观难以识别。相反,这些物体的成功识别通常依赖于它们的上下文,因为周围的环境可以提供关于它们的形状、方向和其他特征的宝贵线索。
就比如面对一个看上去很小的东西,单凭外部轮廓分辨可能有困难,但结合航拍的背景(即该物体所在位置)可以推断出这个小物体是什么。
然后,最重要的两句话:
遥感图像中物体的准确检测通常需要广泛的情境信息
不同对象类型所需的各种上下文信息范围非常不同
说明:一个足球场,我不需要多少上下文背景,一眼就能看出来;但是其它的小物体,比如卡车,那就需要上下文,比如路面等。
准确检测物体所需的上下文信息量可能会根据检测对象的类型而显著不同。例如,足球场可能需要相对较少的额外上下文信息,因为独特的可辨识的球场边界线。相比之下,环形交叉口可能需要更大范围的上下文信息,以便区分花园和环形建筑。十字路口,特别是那些部分被树木遮挡的,通常需要一个非常大的感受野,因为交叉道路之间存在长距离依赖性。这是因为树木和其他障碍物的存在使得仅凭外观很难识别道路和十字路口本身。其他物体类别,如桥梁、车辆和船只,也可能需要不同尺度的感受野才能被准确检测和分类
解决方法就是LSKNet:
我们的方法涉及动态调整特征提取主干的接收场,以便更有效地处理被检测对象的多变宽广上下文。这通过一种空间选择性机制实现,该机制有效地加权处理一系列大深度卷积核处理的特征,然后将它们空间合并。这些核的权重是基于输入动态确定的,允许模型自适应地使用不同的大核,并根据需要调整每个空间目标的接收场。
文章还加入了大核网络和注意力选择:
大型核卷积在用更丰富的上下文调节卷积特征方面起着重要作用
注意力选择机制是一种简单有效的方法,用于增强各种任务的神经表示。通道注意力SE块[27]使用全局平均信息来重新加权特征通道,而空间注意力模块如GENet[26]、GCNet[3]和SGE[31]通过空间掩码增强了网络建模上下文信息的能力。CBAM[60]和BAM[48]结合了通道和空间注意力,以利用两者的优点。
除了通道/空间注意力机制外,核选择也是一种自适应且有效的技术,用于动态上下文建模。CondConv[66]和动态卷积[5]使用并行核来自适应地聚合来自多个卷积核的特征。SKNet[30]引入了具有不同卷积核的多个分支,并沿着通道维度选择性地组合它们。ResNeSt[77]扩展了SKNet的思想,将输入特征图分割成几个组。与SKNet类似,SCNet[34]使用分支注意力来捕获更丰富的信息,并使用空间注意力来提高定位能力。可变形卷积网络[80, 8]为卷积单元引入了灵活的核形状。
我们的方法与SKNet[30]最为相似,然而,两种方法之间存在两个关键区别。首先,我们提出的选择机制明确依赖于通过分解得到的一系列大核,这与大多数现有的基于注意力的方法不同。其次,我们的方法在空间维度上自适应地聚合信息,而不是像SKNet那样在通道维度上使用。这种设计对于遥感任务来说更为直观和有效,因为通道级选择无法模拟图像空间中不同目标的空间变化。详细的结构比较列在图3中。
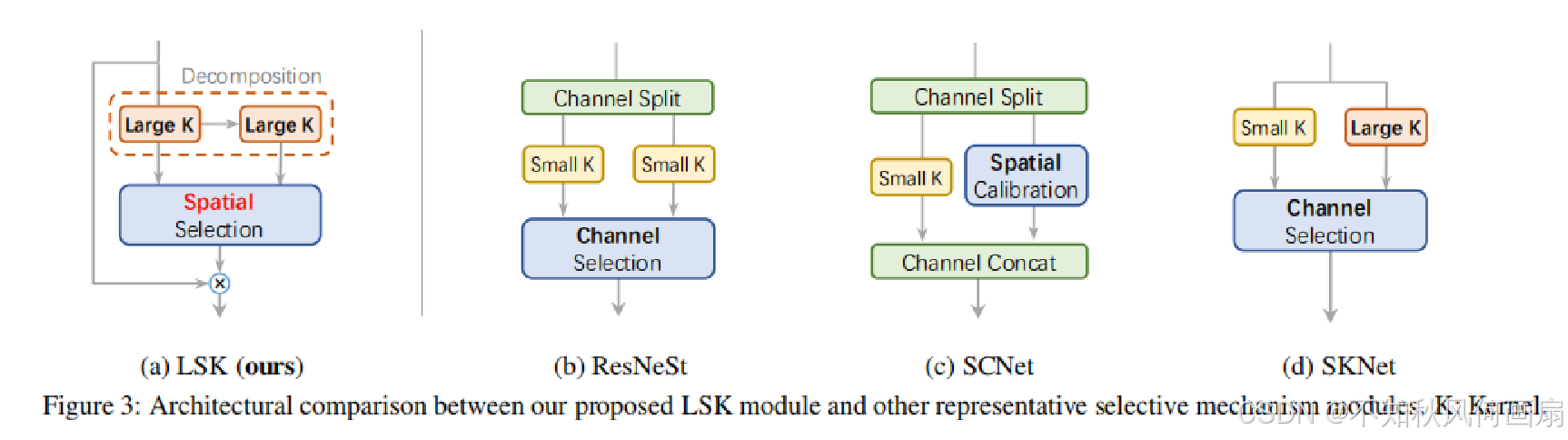
二、方法和整体结构
整体架构是基于最近流行的结构[37, 58, 17, 25, 74](详见补充材料(SM))构建的,具有重复的构建块。 本文中使用的LSKNet不同变体的详细配置列在表1中。每个LSKNet块由两个残差子块组成:大型核选择(LK选择)子块和前馈网络(FFN)子块。核心的LSK模块(图4)嵌入在LK选择子块中。它由一系列大型核卷积和一个空间核选择机制组成,稍后将详细阐述。
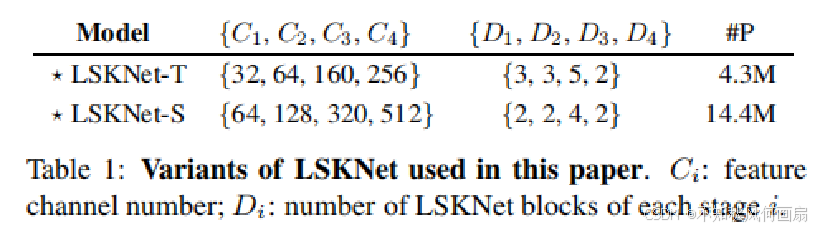
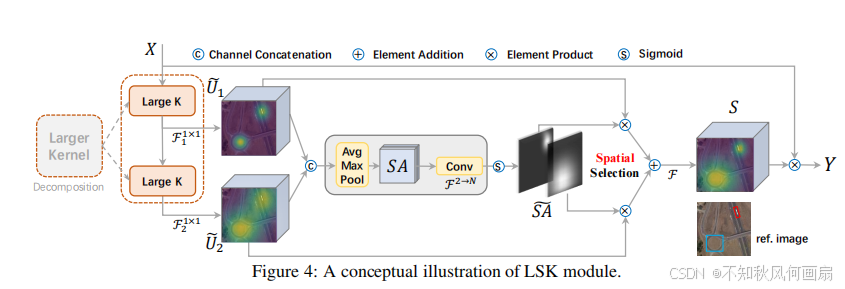
三、代码
大家看到了图4和图8,这就是整体的样子,结合代码更好理解:
import torch
import torch.nn as nn
from torch.nn.modules.utils import _pair as to_2tuple
from mmcv.cnn.utils.weight_init import (constant_init, normal_init,
trunc_normal_init)
from ..builder import ROTATED_BACKBONES
from mmcv.runner import BaseModule
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
import math
from functools import partial
import warnings
from mmcv.cnn import build_norm_layer
"""
Mlp 是一个多层感知机(MLP)模块,通常用于在深度学习模型中引入非线性变换。它包含以下组件:
全连接层 (fc1): 使用一个 1x1 的卷积层将输入特征映射到隐藏特征空间。
深度可分离卷积层 (dwconv): 使用深度可分离卷积进行特征提取。
激活函数 (act): 使用指定的激活函数(默认是 GELU)。
第二个全连接层 (fc2): 再次使用一个 1x1 的卷积层将隐藏特征映射回输出特征空间。
Dropout 层: 用于防止过拟合。
参数:
in_features: 输入特征的数量。
hidden_features: 隐藏层特征的数量。如果未指定,则默认为 in_features。
out_features: 输出特征的数量。如果未指定,则默认为 in_features。
act_layer: 激活函数层,默认为 nn.GELU。
drop: Dropout 概率,默认为 0。
"""
#图8的下半部分
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1) #第一个全连接层
self.dwconv = DWConv(hidden_features) #深度可分离卷积层
self.act = act_layer() #激活函数
self.fc2 = nn.Conv2d(hidden_features, out_features, 1) #第二个全连接层
self.drop = nn.Dropout(drop) #dropout层
def forward(self, x):
x = self.fc1(x)
x = self.dwconv(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
"""
LSKblock 是一个局部自注意力块(Local Self-Attention Block),通常用于捕捉局部特征和长距离依赖关系。它包含以下组件:
初始卷积层 (conv0): 使用一个 5x5 的卷积层,步幅为 1,填充为 2,组数等于通道数,以实现局部特征提取。
空间卷积层 (conv_spatial): 使用一个 7x7 的卷积层,步幅为 1,填充为 9,组数等于通道数,膨胀率为 3,以捕捉更大范围的特征。
降维卷积层 (conv1 和 conv2): 分别将特征维度减半。
聚合和压缩卷积层 (conv_squeeze): 使用一个 7x7 的卷积层,步幅为 1,填充为 3,将特征聚合并压缩成两个通道。
最终卷积层 (conv): 将特征恢复到原始维度。
注意力机制: 通过计算平均池化和最大池化的特征图,然后应用 Sigmoid 函数来生成注意力权重,最后对输入特征进行加权。
输入: 一个四维张量 x,形状为 [batch_size, channels, height, width]。
输出: 经过注意力机制处理后的张量,形状与输入相同
"""
#图4,重点结构
class LSKblock(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim) #局部注意力
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3) #空间注意力
self.conv1 = nn.Conv2d(dim, dim//2, 1) #通道注意力,输入通道数整除减半
self.conv2 = nn.Conv2d(dim, dim//2, 1) #通道注意力
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3) #压缩通道注意力的特征图。输入通道数为2,输出通道数也为2,卷积核大小为7x7,填充为3
self.conv = nn.Conv2d(dim//2, dim, 1) #用于将通道注意力的特征图恢复到原始维度,输入通道数为dim//2,输出通道数为dim
def forward(self, x):
attn1 = self.conv0(x) #使用一个深度可分离卷积(卷积核大小为5x5,填充为2)来提取局部特征
attn2 = self.conv_spatial(attn1) #使用另一个深度可分离卷积(卷积核大小为7x7,填充为9,膨胀率为3)来进一步提取空间特征
# 分别使用两个1x1卷积将局部特征映射到不同的通道空间
attn1 = self.conv1(attn1)
attn2 = self.conv2(attn2)
#特征聚合和激活
attn = torch.cat([attn1, attn2], dim=1) #将两个特征图在通道维度上进行拼接(5)
avg_attn = torch.mean(attn, dim=1, keepdim=True) #计算拼接后特征图的平均值(6)
max_attn, _ = torch.max(attn, dim=1, keepdim=True) #计算拼接后特征图的最大值(6)
agg = torch.cat([avg_attn, max_attn], dim=1) #将平均和最大值特征图在通道维度上拼接(7)
sig = self.conv_squeeze(agg).sigmoid() #使用一个1x1卷积(卷积核大小为7x7,填充为3)来压缩特征图,并通过Sigmoid函数激活,得到注意力权重 sig(8)
#应用注意力
attn = attn1 * sig[:,0,:,:].unsqueeze(1) + attn2 * sig[:,1,:,:].unsqueeze(1) #根据计算出的注意力权重 sig 对 attn1 和 attn2 进行加权求和,得到最终的注意力特征图 attn(9)
attn = self.conv(attn) #使用一个1x1卷积将注意力特征图恢复到原始维度
return x * attn #将输入特征图 x 与注意力特征图 attn 逐元素相乘,得到最终输出
"""
Attention 模块是一个注意力机制,它通过以下步骤处理输入特征:
投影层 (proj_1): 使用一个 1x1 的卷积层将输入特征映射到隐藏特征空间。
激活函数 (activation): 使用指定的激活函数(默认是 GELU)。
空间门控单元 (spatial_gating_unit): 使用 LSKblock 进行局部自注意力计算。
第二个投影层 (proj_2): 再次使用一个 1x1 的卷积层将隐藏特征映射回输出特征空间。
残差连接: 将输入特征与经过注意力机制处理后的特征相加,形成残差连接。
"""
#图8的上半部分
class Attention(nn.Module):
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)#这是一个二维卷积层,使用 1x1 的卷积核。作用是对输入张量进行线性变换,改变其通道数或特征维度。输入和输出的形状相同,但通道数可能被改变。
self.activation = nn.GELU() #引入非线性,学习复杂特征
self.spatial_gating_unit = LSKblock(d_model) #自定义的空间门控单元(LSKblock),用于捕捉局部和全局信息,注意力机制
self.proj_2 = nn.Conv2d(d_model, d_model, 1) #二维卷积层,对经过空间门控单元处理后的张量进行进一步的线性变换
def forward(self, x):
shorcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x + shorcut #残差连接,保留原始信息,促进稳定性
return x #经过一系列卷积、激活函数、空间门控单元(Spatial Gating Unit)处理后的张量,形状与输入相同
"""
Block 模块结合了归一化、注意力机制和多层感知机(MLP),并应用了残差连接和层缩放技术。它包含以下组件:
归一化层 (norm1 和 norm2): 对输入特征进行归一化处理。如果提供了 norm_cfg,则使用自定义的归一化层;否则,使用默认的批量归一化层。
注意力机制 (attn): 使用 Attention 模块处理特征。
DropPath: 如果 drop_path 大于 0,则应用 DropPath 正则化;否则,不应用任何操作。
多层感知机 (mlp): 使用 Mlp 模块处理特征。
层缩放参数 (layer_scale_1 和 layer_scale_2): 初始化为一个小值,并在训练过程中学习。
残差连接: 将输入特征与经过注意力机制和 MLP 处理后的特征相加,形成残差连接(差连接通过引入跳跃连接(或称为捷径),将输入直接添加到输出上,使得每一层都可以直接学习到输入的变化。这种结构允许网络在深层的同时保留重要的信息,避免了信息丢失)
dim: 输入特征的维度。
mlp_ratio: MLP 中隐藏层的维度与输入维度的比例,默认为 4。
drop: MLP 中的 dropout 概率。
drop_path: Stochastic depth 的概率,即随机丢弃路径的概率。
act_layer: 激活函数,默认是 nn.GELU。
norm_cfg: 归一化配置,如果提供则使用自定义的归一化层,否则使用 nn.BatchNorm2d
"""
#图8,连接mlp和attention
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0.,drop_path=0., act_layer=nn.GELU, norm_cfg=None):
super().__init__()
if norm_cfg: #根据 norm_cfg 设置归一化层
self.norm1 = build_norm_layer(norm_cfg, dim)[1]
self.norm2 = build_norm_layer(norm_cfg, dim)[1]
else:
self.norm1 = nn.BatchNorm2d(dim)
self.norm2 = nn.BatchNorm2d(dim)
self.attn = Attention(dim) #初始化注意力模块 self.attn
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() #初始化 DropPath 模块 self.drop_path
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) #计算 MLP 的隐藏层维度并初始化 MLP 模块 self.mlp
layer_scale_init_value = 1e-2
self.layer_scale_1 = nn.Parameter( #初始化两个可学习参数 self.layer_scale_1 和 self.layer_scale_2,用于缩放注意力和 MLP 的输出
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x): #输入: x,形状为 (batch_size, channels, height, width)
#通过第一个归一化层 self.norm1 对输入进行归一化,然后通过注意力模块 self.attn 处理,结果乘以 self.layer_scale_1 并添加到原始输入 x(残差连接)
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.attn(self.norm1(x)))
#通过第二个归一化层 self.norm2 对输入进行归一化,然后通过 MLP 模块 self.mlp 处理,结果乘以 self.layer_scale_2 并添加到步骤1的结果(另一个残差连接)
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
return x #经过注意力机制和多层感知机(MLP)处理后的张量
"""
将图像转换为嵌入向量,将输入图像分割成多个小块(patch),然后将这些小块映射到高维空间中
"""
class OverlapPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=7, stride=4, in_chans=3, embed_dim=768, norm_cfg=None):
super().__init__()
patch_size = to_2tuple(patch_size)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
if norm_cfg:
self.norm = build_norm_layer(norm_cfg, embed_dim)[1]
else:
self.norm = nn.BatchNorm2d(embed_dim)
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = self.norm(x)
return x, H, W
@ROTATED_BACKBONES.register_module()
class LSKNet(BaseModule):
"""
类定义和初始化
img_size: 输入图像的大小,默认为224x224。
in_chans: 输入图像的通道数,默认为3(RGB图像)。
embed_dims: 每个阶段的嵌入维度列表。
mlp_ratios: 每个阶段的MLP层扩展比例。
drop_rate: Dropout率。
drop_path_rate: Stochastic Depth的路径丢弃率。
norm_layer: 归一化层,默认使用LayerNorm。
depths: 每个阶段的块数量。
num_stages: 总阶段数。
pretrained: 预训练模型的路径或名称。
init_cfg: 初始化配置。
norm_cfg: 归一化配置。
"""
def __init__(self, img_size=224, in_chans=3, embed_dims=[64, 128, 256, 512],
mlp_ratios=[8, 8, 4, 4], drop_rate=0., drop_path_rate=0., norm_layer=partial(nn.LayerNorm, eps=1e-6),
depths=[3, 4, 6, 3], num_stages=4,
pretrained=None,
init_cfg=None,
norm_cfg=None):
super().__init__(init_cfg=init_cfg)
#初始化过程
"""
确保 init_cfg 和 pretrained 不能同时设置。
如果 pretrained 是字符串类型,则发出警告并转换为 init_cfg。
初始化深度和阶段数。
根据 drop_path_rate 计算每一层丢弃的概率。
"""
assert not (init_cfg and pretrained), \
'init_cfg and pretrained cannot be set at the same time'
if isinstance(pretrained, str):
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
elif pretrained is not None:
raise TypeError('pretrained must be a str or None')
self.depths = depths
self.num_stages = num_stages
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
#构建网络结构
"""
循环创建每个阶段的 OverlapPatchEmbed(特征向量)、Block 和 norm_layer。
使用 setattr 动态地将它们添加到模块中。
"""
for i in range(num_stages):
patch_embed = OverlapPatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=7 if i == 0 else 3,
stride=4 if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i], norm_cfg=norm_cfg)
block = nn.ModuleList([Block(
dim=embed_dims[i], mlp_ratio=mlp_ratios[i], drop=drop_rate, drop_path=dpr[cur + j],norm_cfg=norm_cfg)
for j in range(depths[i])])
norm = norm_layer(embed_dims[i])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
#权重初始化
"""
根据 init_cfg 进行权重初始化,如果没有指定 init_cfg,则手动初始化各层权重。
"""
def init_weights(self):
print('init cfg', self.init_cfg)
if self.init_cfg is None:
for m in self.modules():
if isinstance(m, nn.Linear):
trunc_normal_init(m, std=.02, bias=0.)
elif isinstance(m, nn.LayerNorm):
constant_init(m, val=1.0, bias=0.)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[
1] * m.out_channels
fan_out //= m.groups
normal_init(
m, mean=0, std=math.sqrt(2.0 / fan_out), bias=0)
else:
super(LSKNet, self).init_weights()
#冻结补丁嵌入层
def freeze_patch_emb(self):
self.patch_embed1.requires_grad = False
#忽略权重衰减的参数,返回不需要权重衰减的参数名集合
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed1', 'pos_embed2', 'pos_embed3', 'pos_embed4', 'cls_token'} # has pos_embed may be better
#获取分类器,返回分类头
def get_classifier(self):
return self.head
#重置分类器
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
#前向传播特征提取
"""
提取输入图像的特征,通过多个阶段的补丁嵌入和块处理。
最后返回所有阶段的特征图。
"""
def forward_features(self, x):
B = x.shape[0]
outs = []
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x)
for blk in block:
x = blk(x)
x = x.flatten(2).transpose(1, 2)
x = norm(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
return outs
#前向传播
"""
调用 forward_features 提取特征,并返回结果。注释掉的部分可以用于添加分类头。
"""
def forward(self, x):
x = self.forward_features(x)
# x = self.head(x)
return x
#深度可分离卷积(Depthwise Convolution)模块 DWConv
"""
DWConv: 这是一个继承自 nn.Module 的自定义卷积模块。
init: 初始化方法中定义了一个深度可分离卷积层 self.dwconv。参数说明:
dim: 输入和输出通道数,默认为768。
groups=dim: 将卷积分组数设置为输入通道数,使其成为深度可分离卷积。
forward: 前向传播方法,将输入 x 通过深度可分离卷积层,然后返回结果。
"""
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
"""
dim: 输入和输出通道数。
3: 卷积核的大小为 3x3。
1: 步幅(stride)为 1。
1: 填充(padding)为 1,使得输出大小与输入大小相同。
bias=True: 使用偏置项。
groups=dim: 将卷积分组数设置为输入通道数,这实际上是实现深度可分离卷积的关键。
"""
def forward(self, x):
x = self.dwconv(x)
return x
"""
_conv_filter: 这个函数用于转换模型的权重,特别是将手动分块和线性投影的权重转换为卷积层的权重。
参数:
state_dict: 包含模型权重的字典。
patch_size: 分块的大小,默认为16。
功能:
遍历 state_dict 中的每个键值对。
如果键中包含 'patch_embed.proj.weight',则将对应的权重重新调整形状,从 (C, H*W) 变为 (C, 3, patch_size, patch_size)。
将处理后的权重存入新的字典 out_dict 中。
返回: 处理后的权重字典 out_dict。
"""
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict

















 1660
1660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









