







概述
使用DataFrame处理时间序列数据时,你可以轻松地进行时间戳的转换和格式化。Pandas提供了丰富的函数和方法来处理日期和时间,如pd.to_datetime()用于将字符串转换为日期时间对象,.dt访问器用于访问日期时间的各个部分,以及strftime()方法用于将日期时间对象格式化为字符串。这些功能使得在DataFrame中处理时间序列数据变得简单而直观。
此外,DataFrame还支持基于时间的索引操作,如between_time()和at_time()。这些方法允许你根据特定的时间范围或时间点来筛选数据,从而快速提取出感兴趣的时间段内的数据。这对于时间序列分析、数据可视化以及预测建模等任务非常有用。
总之,DataFrame的时间序列是数据分析中不可或缺的一部分。通过利用Pandas库的功能,你可以轻松地处理、分析和可视化时间序列数据,从而发现数据中的模式和趋势,为决策提供有力支持。
一、pandas的日期类型
Pandas中的日期类型主要是datetime64,这是一个固定宽度的数据类型,用于表示日期和时间。datetime64类型允许存储从1677年到2262年之间的日期和时间,以纳秒为时间单位。
(一)datetime64类型的特点
固定宽度:datetime64类型在内存中占用固定数量的字节,这有助于高效地存储和处理时间序列数据。
纳秒精度:datetime64类型使用纳秒作为时间单位,因此可以表示非常精确的时间戳。
时间范围:如前所述,datetime64可以表示从1677年到2262年之间的日期和时间。
时区感知:Pandas支持时区感知的datetime64类型,这对于处理跨越不同时区的数据非常有用。
(二) 时间序列的创建
你可以使用pd.to_datetime()函数将字符串、整数、浮点数或其他数据类型转换为datetime64类型。这个函数非常灵活,可以处理多种格式的日期和时间字符串。
1.从字符串创建datetime64类型
import pandas as pd
# 从字符串创建datetime64类型
date_string = '2023-10-23'
date = pd.to_datetime(date_string)
print(date)
运行结果:

2. 整数(Unix时间戳)创建datetime64类型
# 从整数(Unix时间戳)创建datetime64类型
timestamp = 1697606400 # 示例:2023-10-23 00:00:00的Unix时间戳
dt_from_timestamp = pd.to_datetime(timestamp, unit='s')
print(dt_from_timestamp)
运行结果:

3.导入数据时直接转换
使用parse_dates参数直接把需要转换的列转化为datetime64
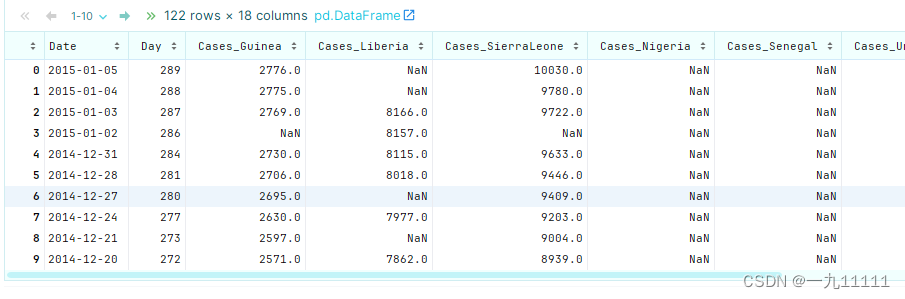
ebola = pd.read_csv('/export/data/pandas_data/country_timeseries.csv', parse_dates=['Date'])
ebola
运行结果:
(三)datetime64作为索引
将datetime64类型的列设为索引列
# 将Date类设为索引列
ebola.set_index('Date')
运行结果
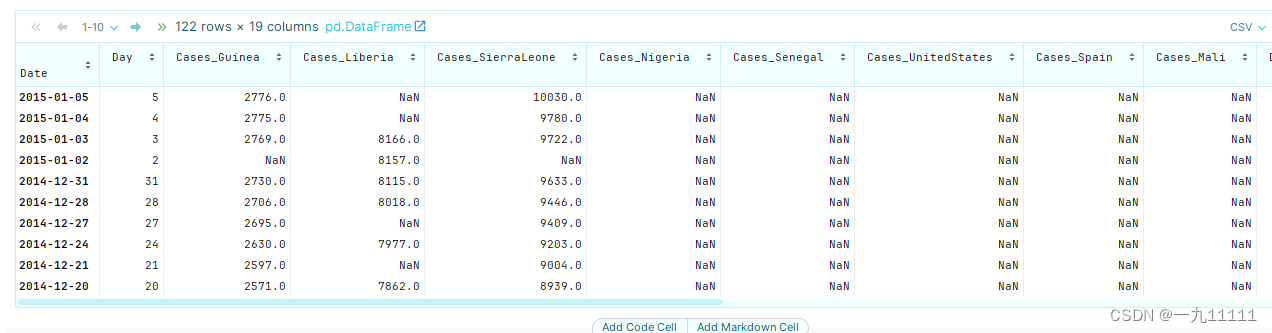
获取2014年12月的数据
二、运用时间序列索引获取数据
导入数据:
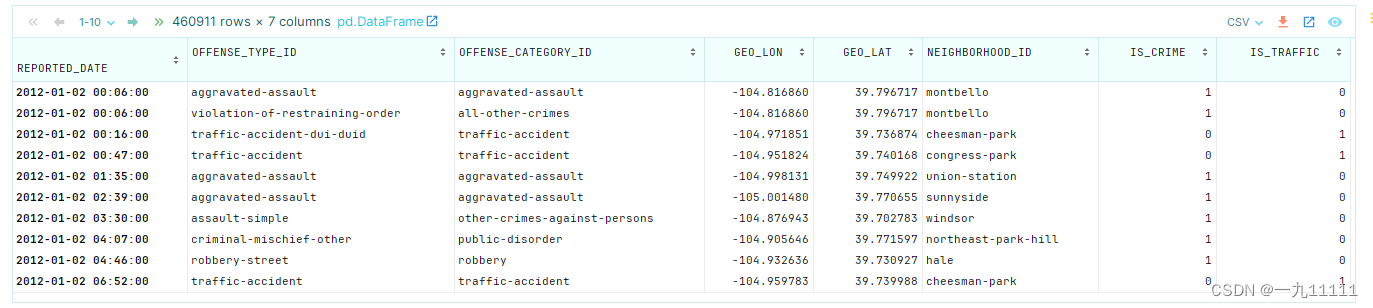
crime = pd.read_csv('/export/data/pandas_data/crime.csv',parse_dates=['REPORTED_DATE'],index_col='REPORTED_DATE')
crime =crime.sort_index()
crime
运行结果:
利用时间索引,你可以像处理普通索引一样对数据进行切片。
1.选择特定日期的数据
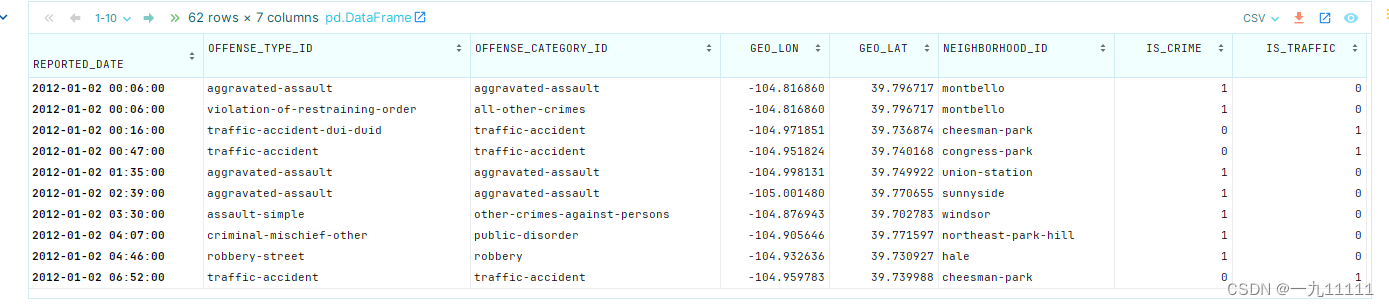
# 提取2012年1月2日的数据
crime['2012-01-02']
运行结果:
# 提取2012年1月的数据
crime['2012-01']
运行结果:
2. 切片选择时间范围
# 提取2012年1月-2月的数据的数据
crime['2012-01':'2012-02'] # 新版已停用
crime.loc['2012-01':'2012-02'] # 标准写法
运行结果:
注意:
运用时间序列获取数据的时候,先对时间序列排序在切片运行效率会提高很多
3. between_time(),at_time()
between_time() 和 at_time() 是两个用于根据时间筛选DataFrame中特定时间段的便捷方法,它们特别适用于那些索引为日期时间类型(DatetimeIndex)的DataFrame。这两个方法允许你基于时间进行快速筛选,无需复杂的布尔索引或查询。
between_time()
between_time() 方法用于选择指定开始时间和结束时间之间的所有行。
- 用法:
DataFrame.between_time(start_time, end_time, include_start=True, include_end=True, tz=None)
-
参数:
- start_time:字符串,表示开始时间,格式为 ‘HH:MM’ 或 ‘HH:MM:SS’。
- end_time:字符串,表示结束时间,格式同样为 ‘HH:MM’ 或 ‘HH:MM:SS’。
- include_start:布尔值,默认为 True,表示是否包含开始时间。
- include_end:布尔值,默认为 True,表示是否包含结束时间。
- tz:时区字符串或 None,用于指定时区。如果DataFrame的索引已经有时区信息,这个参数可以用来覆盖它。
import pandas as pd
# 创建一个示例DataFrame,索引为日期时间
dates = pd.date_range('2023-01-01', periods=10, freq='H') # 每小时一个数据点
data = {'value': range(10)}
df = pd.DataFrame(data, index=dates)
# 筛选早上8点到9点之间的数据
between_8_and_9 = df.between_time('8:00', '9:00')
print(between_8_and_9)
运行结果:

at_time()
at_time() 方法用于选择指定时间的所有行。
- 用法:
DataFrame.at_time(time, tz=None)
-
参数:
- time:字符串,表示要筛选的时间,格式为 ‘HH:MM’ 或 ‘HH:MM:SS’。
- tz:时区字符串或 None,与 between_time() 中的 tz 参数相同。
仍然使用上面的DataFrame,并且筛选出早上8点的所有行:
# 筛选早上8点的数据
at_8 = df.at_time('8:00')
print(at_8)
运行结果:

这两个方法都返回一个新的DataFrame,其中只包含满足时间条件的行。它们对于处理时间序列数据,特别是那些需要基于特定时间窗口进行筛选的数据集时,非常有用。
三、重采样时间序列数据
resample() 函数
resample()是用于时间序列数据重采样的强大工具。它允许将时间序列数据从一个频率转换为另一个频率,并通过聚合函数(如求和、均值、最大值等)来减少数据的粒度。这个函数通常应用于 Pandas 的 DataFrame 或 Series 对象,这些对象有一个 DatetimeIndex。
1. 常用的时间规则
- ‘D’ 或 ‘B’:每日频率,‘D’ 包括周末,‘B’ 仅包括工作日(周一至周五)。
- ‘H’:每小时频率。
- ‘T’ 或 ‘min’:每分钟频率。
- ‘S’:每秒频率。
- ‘M’:月末频率,即每个日历月末。
- ‘SM’:每月的开始,即每个月的第一天。
- ‘BM’:每个业务月(工作日)的月末。
- ‘BMS’:每个业务月(工作日)的开始。
- ‘Q’:季度末频率,即每个日历季度的末尾。
- ‘BQ’:每个业务季度的末尾。
- ‘QS’:每个季度的开始。
- ‘BQS’:每个业务季度的开始。
- ‘A’ 或 ‘Y’:年末频率,即每年的最后一个日历日。
- ‘AS’ 或 ‘YS’:每年的开始。
- ‘BA’ 或 ‘BY’:每个业务年的末尾。
- ‘BAS’ 或 ‘BYS’:每个业务年的开始。
- ‘W-MON’:每周一频率。你可以使用 ‘W-TUE’、‘W-WED’、‘W-THU’、‘W-FRI’、‘W-SAT’ 或 ‘W-SUN’ 来指定每周的任意一天。
- ‘W’:每周频率,默认从周日开始,但可以通过 offset 参数进行更改。
- 自定义偏移量:你还可以创建自定义的日期偏移量,例如 pd.offsets.MonthEnd(3) 表示每个月的第三个日历日的末尾。
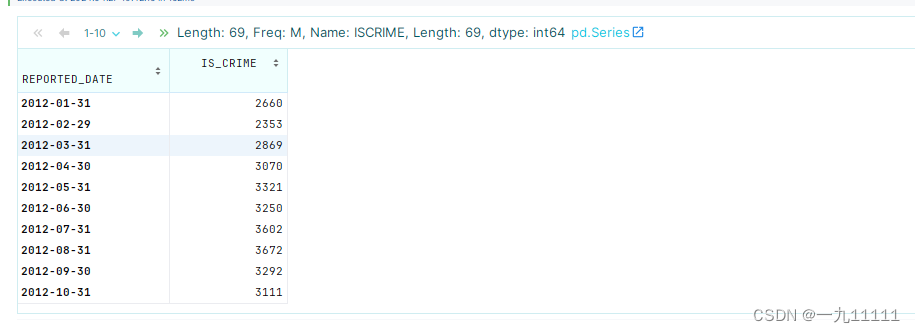
2.将日数据重采样为月数据
# 求每个月犯罪的总数
crime.resample('M')['IS_CRIME'].sum()
运行结果:
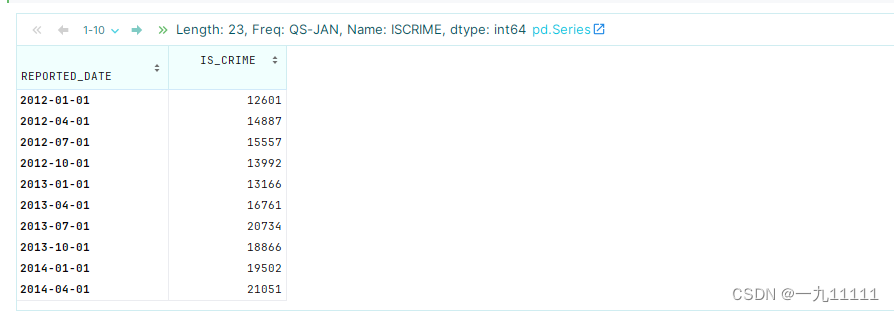
3. resample后面可以接apply函数,传入自定义函数
# 计数自定义函数
def my_count(x):
return x.count()
# 求每个季度犯罪的总数
crime.resample('QS')['IS_CRIME'].apply(my_count)
运行结果:
4. 注意事项:
- resample() 函数默认不对数据进行任何聚合,它只是改变了数据的索引频率。为了实际进行聚合操作,你需要链式调用一个聚合函数,如 mean(), sum(), max(), min() 等,或者使用 agg() 函数来指定多个聚合操作。
- 如果你的 DataFrame 有一个非时间戳的索引,你需要首先将其设置为时间戳索引,才能使用 resample() 函数。这可以通过 set_index() 方法来实现,如上面的示例所示。
- 在使用 resample() 时,确保你的数据已经按时间顺序排序,因为重采样操作依赖于数据的顺序。如果数据未排序,你可以使用 sort_index() 方法先对数据进行排序。
四、移动窗口操作
rolling() 方法
rolling() 方法用于在 DataFrame 或 Series 对象上执行滚动(或窗口)操作。滚动操作允许你对时间序列数据或其他连续数据执行一系列计算,这些计算是在一个固定大小的窗口上进行的,窗口会沿着数据移动。这对于计算诸如滚动平均值、滚动标准差、滚动最大值等统计量非常有用。
1.在单列上执行滚动操作
# 创建一个示例 DataFrame
data = {
'date': pd.date_range(start='2023-01-01', periods=10),
'price': [100, 101, 105, 104, 107, 106, 108, 110, 112, 111] ,
'price2': [110, 121, 135, 144, 157, 166, 178, 180, 192, 110]
}
df = pd.DataFrame(data)
df.set_index('date', inplace=True)
# 计算五天的滚动平均值
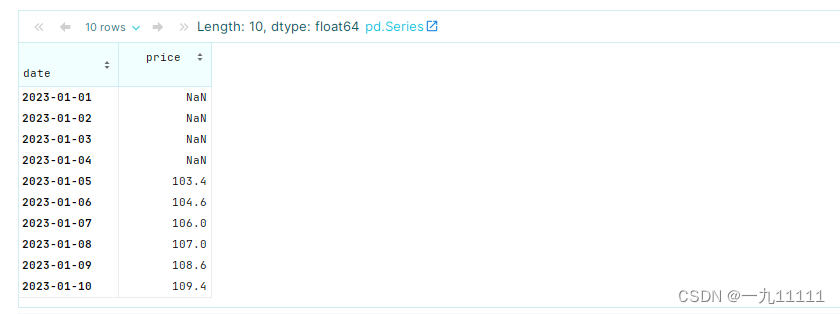
rolling_mean = df['price'].rolling(window=5).mean()
rolling_mean
2. 在多个列上执行滚动操作
如果你的 DataFrame 有多个列,并且你想要对多列都执行滚动操作, rolling() 后指定多列。
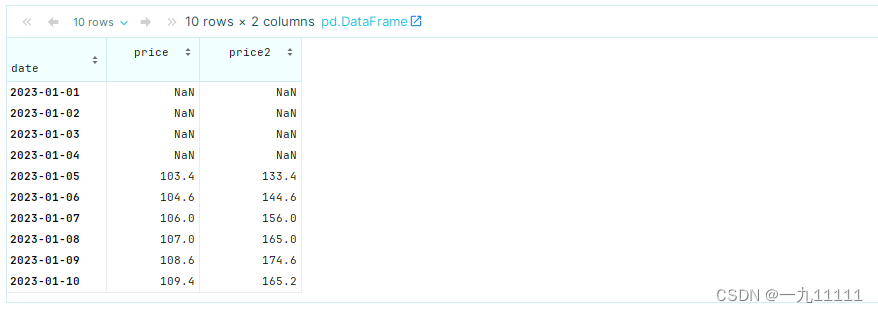
# 对 DataFrame 中的每一列计算五天的滚动平均值
rolling_df = df.rolling(window=5)[['price','price2']].mean()
rolling_df
运行结果:
2.对不同列使用不同的聚合函数
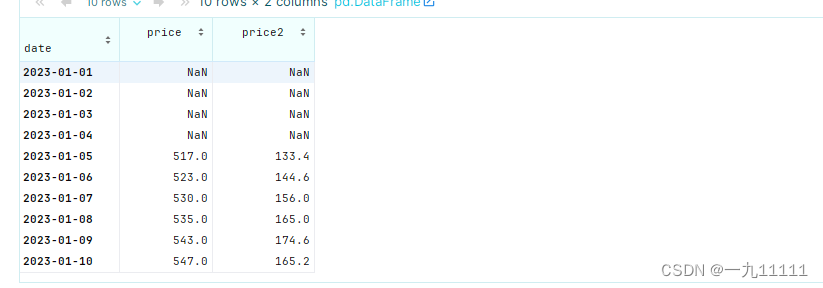
同分组聚合一样使用agg函数,进行对不同的列进行不同的操作
rolling_df = df.rolling(window=5)[['price','price2']].agg({'price': 'sum', 'price2': 'mean'})
rolling_df
运行结果:
3. 应用自定义函数
还可以使用 apply() 方法与 rolling() 结合来应用自定义函数。
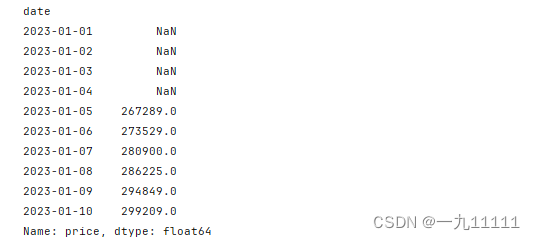
# 自定义函数来计算滚动窗口中的值之和的平方
def custom_func(series):
return (series.sum()) ** 2
# 应用自定义函数到滚动窗口
rolling_custom = df['price'].rolling(window=5).apply(custom_func)
print(rolling_custom)
运行结果:
4. 注意事项:
- rolling() 方法默认不会改变原始数据,而是返回一个新的 DataFrame 或 Series 对象,其中包含了滚动操作的结果。
- window 参数指定了滚动窗口的大小。它必须是一个整数,表示窗口中包含的元素的数量。
- 滚动操作会忽略窗口大小小于窗口中元素数量的部分,因此在结果的开头,你会看到一些 NaN 值,这些值表示没有足够的数据来计算滚动统计量。
- 你可以通过链式调用其他方法(如 dropna())来删除这些 NaN 值。
五、时间差异计算
1. diff()函数
方法在 Pandas 中是一个非常实用的函数,用于计算序列中相邻元素之间的差异。这个方法在处理时间序列数据、金融数据以及其他需要计算相邻元素差值的场景中非常有用。
- diff() 方法的基本格式:
对于 DataFrame:DataFrame.diff(periods=1, axis=0, fill_value=None)
对于 Series:Series.diff(periods=1) - 参数说明:
- periods:指定要计算差值的时期数,可以是正数或负数,默认为1。正数表示后一个元素减去前一个元素,负数则表示前一个元素减去后一个元素。
- axis:对于 DataFrame,此参数指定计算差值的轴向。如果为0或者’index’,则上下移动;如果为1或者’columns’,则左右移动。默认值为0,即沿着行方向(索引)进行计算。
- fill_value:用于指定缺失值填充值。如果原数据中存在缺失值(NaN),可以用此参数指定的值进行填充,然后再进行差值计算。
2.diff()函数在时间序列上的使用
diff() 函数在 Pandas 中用于计算时间序列数据中相邻观测值之间的差异。对于时间序列数据,这通常意味着计算连续时间点之间值的变化。这种变化可能代表增长率、速度、加速度或其他任何需要测量连续时间点之间变化量的指标。
- 计算日变化量
假设你有一个包含每日股票价格的时间序列 DataFrame,你想要计算每日价格变化。
import pandas as pd
import numpy as np
# 创建一个包含日期和价格的示例 DataFrame
dates = pd.date_range(start='2023-01-01', periods=5)
prices = [100, 102, 105, 103, 106]
df = pd.DataFrame({'date': dates, 'price': prices})
df.set_index('date', inplace=True)
# 计算每日价格变化
daily_changes = df['price'].diff()
daily_changes
运行结果:
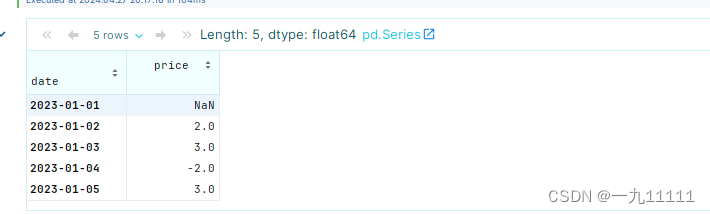
输出会显示每日价格与前一天价格的差异。
- 计算周变化量
如果你想计算每周的变化量,你可以通过调整 periods 参数来实现。
# 计算每周价格变化(假设数据是每日的,并且每周有7天)
weekly_changes = df['price'].diff(periods=7)
# 注意:这将只在有足够的数据点来计算7天差异时返回非NaN值
weekly_changes
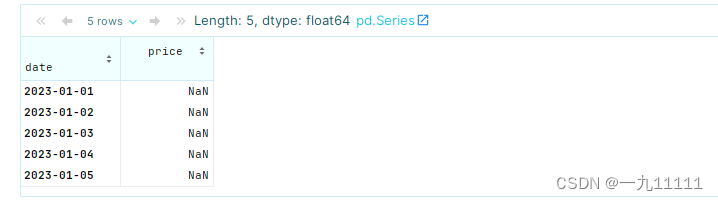
- 处理缺失值
如果时间序列中存在缺失值,diff() 函数将在缺失值的位置返回 NaN。你可以使用 fill_value 参数来填充这些缺失值,然后再进行差分计算。
# 假设价格数据中有缺失值
prices_with_nan = [100, np.nan, 105, 103, 106]
df_with_nan = pd.DataFrame({'date': dates, 'price': prices_with_nan})
df_with_nan.set_index('date', inplace=True)
# 使用前一个有效值填充缺失值,并计算差异
filled_changes = df_with_nan['price'].fillna(method='ffill').diff()
print(filled_changes)
运行结果:
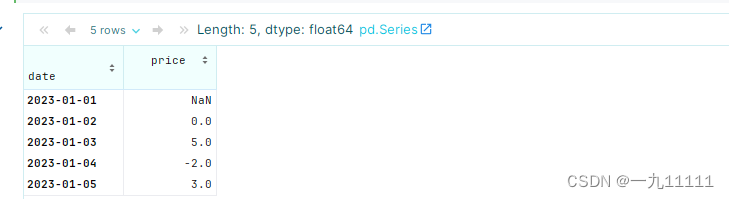
在这个例子中,fillna(method=‘ffill’) 使用前一个有效值填充了缺失值。然后,diff() 函数计算了填充后序列的差异。
- 注意事项
diff() 方法的工作原理可以简单理解为两个步骤:首先,通过 shift() 方法将数据序列进行移动;然后,将移动后的数据与原数据进行相减,得到相邻元素之间的差异。
需要注意的是,diff() 方法返回的是一个与原数据形状相同的新序列,其中包含了相邻元素的差值。由于计算差值时涉及到了元素的移动,因此在结果序列的开头或结尾部分,可能会因为没有足够的相邻元素而导致出现 NaN 值。
六、时间戳转换和格式化
1. 将字符串转换为日期时间对象
使用pd.to_datetime()函数将其转换为Pandas的日期时间对象。
import pandas as pd
# 假设df是一个DataFrame,其中'date_str'列包含日期时间字符串
df = pd.DataFrame({
'date_str': ['2023-01-01 12:00:00', '2023-01-02 14:30:00']
})
# 将字符串转换为日期时间对象
df['date_time'] = pd.to_datetime(df['date_str'])
print(df)
运行结果:

2. 格式化日期时间对象
- 使用.dt访问器来访问日期时间的各个部分
# 访问日期时间的各个部分
df['year'] = df['date_time'].dt.year
df['month'] = df['date_time'].dt.month
df['day'] = df['date_time'].dt.day
df['hour'] = df['date_time'].dt.hour
df['minute'] = df['date_time'].dt.minute
df['second'] = df['date_time'].dt.second
df
运行结果:

- 使用strftime()方法来格式化日期时间为字符串。
# 格式化日期时间为字符串
df['formatted_date'] = df['date_time'].dt.strftime('%Y-%m-%d %H:%M:%S')
df['formatted_date']
运行结果:

4. 时区转换
如果你的日期时间数据包含时区信息,并且你需要进行时区转换,你可以使用tz_convert()方法。
# 假设你的日期时间数据是UTC时区的
df['utc_time'] = pd.to_datetime(df['date_str']).dt.tz_localize('UTC')
# 转换为另一个时区,比如纽约时区(America/New_York)
df['ny_time'] = df['utc_time'].dt.tz_convert('America/New_York')
5.注意事项:
- 确保你的日期时间字符串格式与pd.to_datetime()函数能够解析的格式相匹配。如果格式不匹配,你可能需要指定format参数来告诉Pandas如何解析日期时间字符串。
- 在处理时区时,确保你的环境中安装了pytz库,因为Pandas使用pytz来处理时区信息。
- 当格式化日期时间为字符串时,strftime()方法中的格式字符串应该遵循Python的日期时间格式化规则。
下篇内容
matplotlib入门














 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









