










使用LeNet模型处理MNIST十分类数据集
本人目前研二,正在学习使用不同的模型来训练数据集,由于编程知识的匮乏,在师兄的指导下完成了LeNet模型来处理MNIST数据集,本篇博文是用来记录以进行后续学习,因我对代码掌握的不是很完善,有错误的地方还请各位大佬批评指正
1.创建LeNet模型
import torch
class LeNet(torch.nn.Module):
def __init__(self, input_channels, input_sample_points, classes):
super(LeNet, self).__init__()
self.input_channels = input_channels
self.input_sample_points = input_sample_points
self.features = torch.nn.Sequential(
torch.nn.Conv2d(input_channels, 20, kernel_size=5),
torch.nn.BatchNorm2d(20),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(20, 50, kernel_size=5),
torch.nn.BatchNorm2d(50),
torch.nn.MaxPool2d(2),
)
self.After_features_channels = 50
# 根据公式计算出通过所有的卷积层和池化层后输出的通道中样本点的数量
# self.After_features_sample_points = ((input_sample_points - 5 + 1) // 2 - 5 + 1) // 2
self.After_features_sample_points_x = ((self.input_sample_points[0]-4)//2-4) // 2
self.After_features_sample_points_y = ((self.input_sample_points[1]-4)//2-4) // 2
#断言,assert后面应该为True,条件成立则不进行任何操作,若不成立会抛出AssertionError错误,报错为参数内容“数据尺寸过小“
assert self.After_features_sample_points_x >0 or self.After_features_sample_points_x >0 , "数据尺寸过小"
self.classifier = torch.nn.Sequential(
torch.nn.Linear(self.After_features_channels * self.After_features_sample_points_x*self.After_features_sample_points_y, 1024),
torch.nn.LeakyReLU(0.02),
torch.nn.Linear(1024, classes),
torch.nn.LeakyReLU(0.02)
)
def forward(self, x):
# 检查输入样本维度是否有错误
assert x.size(1) == self.input_channels and x.size(2) == self.input_sample_points[0] and x.size(3) == self.input_sample_points[1],'输入数据维度错误,输入维度应为[Batch_size,{},{},{}],实际输入维度为{}'.format(self.input_channels, self.input_sample_points[0], self.input_sample_points[1],x.size())
x = self.features(x)#调用卷积模型
x = x.view(-1, self.After_features_channels * self.After_features_sample_points_x*self.After_features_sample_points_y)
x = self.classifier(x)#调用全连接层
return x
if __name__ == '__main__':
model = LeNet(input_channels=3, input_sample_points=[28,28], classes=2)
input = torch.randn(size=(1, 3, 28,28))#随机生成一个数据集用模型训练
output = model(input)
print(output.shape)
#torch.Size([1, 5])
2.创建随机生成的数据集以及标签进行模型训练
2.1 随机生成数据集
采用随机生成的数据集进行分类训练
import numpy as np
w,h = 28,28
# 随机生成第一类数据
class1 = np.ones(shape=(100,3,w,h))#用于创建指定形状的数组,并将数组中的元素初始化为1,这里生成了100个,通道数为3的wxh的全1矩阵
# 随机生成第二类数据
class2 = np.random.uniform(size=(100,3,w,h))#是一个均匀分布随机数生成函数,size指定了生成的随机数的数量和形状,生成了100个,通道数为3的wxh的随机数矩阵
#定义标签
label1 = np.zeros(shape=(100))#生成一个shape形状的全零数组,为一维数组,在第0维长度为100
label2 = np.ones(shape=(100))#生成一个shape形状的全1数组,为一维的,第0维长度为100
data = np.concatenate([class1,class2],axis=0)#将随机生成的两类数据沿着0轴方向进行拼接,axis=0代表沿着数组的垂直方向拼接
label = np.concatenate([label1,label2],axis=0)#同理,将标签进行拼接
print(zip(data,label))
dataset = np.array([i for i in zip(data,label)])
#zip()返回一个zip对象,其内部元素为元组;分别从data和label依次各取出一个元素组成元组,再将依次组成的元组组合成一个新的迭代器
#第一个i代表要放进dataset中
# 数据存储(若为二维及以下np数组,则可直接使用np.savetxt()方法进行保存,三维则用save
np.save('dataset',dataset)
2.2.使用随机生成的数据集进行分类训练
import numpy as np
import torch
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, Dataset
from torch.utils.data import random_split
from LeNet import LeNet
import copy
#载入数据集
data = np.load("dataset.npy",allow_pickle=True)
# 使用torch.utils.data.random_split()划分数据集
train_len = int(len(data) * 0.7)
test_len = int(len(data)) - train_len
train_dataset, test_dataset = random_split(dataset=data, lengths=[train_len, test_len])
# 数据库加载
class Dataset(Dataset):
def __init__(self, data):
self.len = len(data)
#torch.from_numpy把数组转换成张量,把里边每个data里面元组的第一项提取出来构成数组,作为特征
self.x_data = torch.from_numpy(np.array(list(map(lambda x: x[0], data)), dtype=np.float32))
self.y_data = torch.from_numpy(np.array(list(map(lambda x: x[-1], data)))).squeeze().long()
#把数据集data里面的最后一行提取出来构成数组,其中np.squeeze()函数可以删除数组形状中的单维度条目,即把shape中为1的维度去掉,但是对非单维的维度不起作用。
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
# 数据库dataloader
Train_dataset = Dataset(train_dataset)
Test_dataset = Dataset(test_dataset)
dataloader = DataLoader(Train_dataset, shuffle=True, batch_size=50)
testloader = DataLoader(Test_dataset, shuffle=True, batch_size=50)
# 训练设备选择GPU还是CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 模型初始化
model = LeNet(input_channels=3,input_sample_points=[28,28], classes=2)
#将模型加载到相应的设备中
model.to(device)
# 损失函数选择
criterion = torch.nn.CrossEntropyLoss()
criterion.to(device)
# 优化器选择
optimizer = torch.optim.Adam(model.parameters(), lr=0.000001)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.00001,momentum=0.9)
train_acc_list = []
test_acc_list = []
# 训练函数
def train(epoch):
model.train()
train_correct = 0
train_total = 0
for data in dataloader:
datavalue, datalabel = data
datavalue, datalabel = datavalue.to(device), datalabel.to(device)
datalabel_pred = model(datavalue)
loss = criterion(datalabel_pred, datalabel)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# probability, predicted = torch.max(datalabel_pred.data, dim=1)
probability, predicted = torch.max(datalabel_pred.data, dim=1)
train_total += datalabel_pred.size(0)#批量的数目
train_correct += (predicted == datalabel).sum().item()
if epoch % 10 == 0:
train_acc = round(100 * train_correct / train_total, 4)
train_acc_list.append(train_acc)
print('=' * 10, epoch // 10, '=' * 10)
print('loss:', loss.item())
print(f'训练集准确率:{train_acc}%')
test()
# 测试函数
def test():
model.eval()#评估模式,在评估模式下,batchNorm层,dropout层等用于优化训练而添加的网络层会被关闭,从而使得评估时不会发生偏移。
global Confusion_matrix
test_correct = 0
test_total = 0
# 混淆矩阵变量
#Confusion_matrix = np.zeros([2, 2])
with torch.no_grad():
for testdata in testloader:
testdatavalue, testdatalabel = testdata
testdatavalue, testdatalabel = testdatavalue.to(device), testdatalabel.to(device)
testdatalabel_pred = model(testdatavalue)
testprobability, testpredicted = torch.max(testdatalabel_pred.data, dim=1)#拿到的应该是一个矩阵,矩阵中有好多行,每一行里面有两个特征,沿着第一维度去找十个中最大值的下标,返回的是两个,一个是最大值,一个是最大值对应的下标
print(testprobability)
test_total += testdatalabel_pred.size(0)
test_correct += (testpredicted == testdatalabel).sum().item()
#混淆矩阵加载
# for i, j in zip(testdatalabel, testpredicted):
# Confusion_matrix[i][j] += 1
test_acc = round(100 * test_correct / test_total, 4)
test_acc_list.append(test_acc)
print(f'测试集准确率:{(test_acc)}%')
bestmodel = None
bestepoch = None
bestacc = 0
for epoch in range(1, 201):
# for epoch in range(1, 21):
train(epoch)
#找出测试集的最佳轮次以及最佳准确率
if epoch % 10 == 0:
if test_acc_list[epoch % 10 - 1] > bestacc:
bestacc = test_acc_list[epoch % 10 - 1]#迭代找出测试集最大的准确率,覆盖之前的bastacc
bestepoch = epoch
bestmodel = copy.deepcopy(model)#模型保存
print("最佳轮次为:{},最佳准确率为:{}".format(bestepoch, bestacc))
torch.save(bestmodel,"best.pth")#存储到best.pth文件中
torch.save(model,"last.pth")
plt.plot(np.array(range(20))*10,train_acc_list)
plt.plot(np.array(range(20))*10,test_acc_list)
plt.legend(['train','test'])#对视图中的不同数据进行标注
plt.xlabel('epoch')
plt.ylabel('Accuracy')
plt.show()
结果图为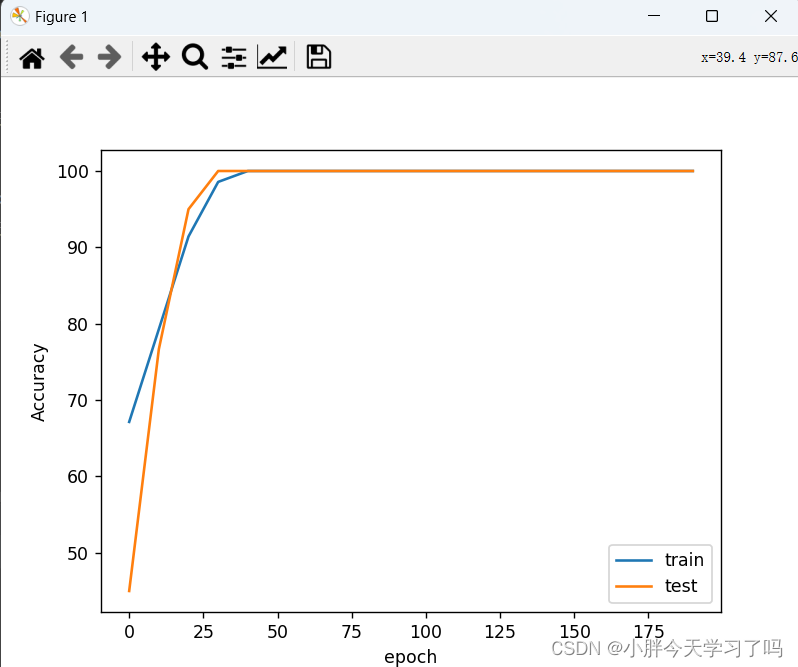
2.3读取生成数据训练模型
import torch
import numpy as np
#读取随机生成的dataset数据集,如果要显示出内容,一定要加上.item(),表示取内容
dataset = np.load("dataset.npy",allow_pickle=True)
packge = dataset[0]
index = 110#取dataset中索引为110的数据进行测试,并将其改成(B,C,H,W)形式
data = torch.Tensor(dataset[index][0]).view(1,3,28,28)
label = dataset[index][1]
model = torch.load('best.pth').to("cpu")
model.eval() # 评估模式,在评估模式下,batchNorm层,dropout层等用于优化训练而添加的网络层会被关闭,从而使得评估时不会发生偏移
output = model(data)
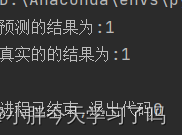
print(f"预测的结果为:{torch.argmax(output).item()}")#只想要最终的标签,对其概率不关心,就可以直接用torch.argmax()返回tensor数据最大值的索引
print(f"真实的的结果为:{int(label)}")
结果为
3.使用MNIST数据集进行模型训练
3.1读取数据集
import torchvision
from torchvision import transforms
trainDataset = torchvision.datasets.MNIST( # torchvision可以实现数据集的训练集和测试集的下载
root="./data", # 下载数据,并且存放在data文件夹中
train=True, # train用于指定在数据集下载完成后需要载入哪部分数据,如果设置为True,则说明载入的是该数据集的训练集部分;如果设置为False,则说明载入的是该数据集的测试集部分。
transform=transforms.ToTensor(), # 数据的标准化等操作都在transforms中,此处是转换成张量
download=True # 下载过程中如果中断,或者下载完成之后再次运行,则会出现报错
)
testDataset = torchvision.datasets.MNIST(
root="./data",
train=False,
transform=transforms.ToTensor(),
download=True
)
3.2训练MNIST数据集
#加载数据集
dataloader = DataLoader(train_dataset, shuffle=True, batch_size=500)
testloader = DataLoader(test_dataset, shuffle=True, batch_size=500)
# 训练设备选择GPU还是CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 模型初始化
model = LeNet(input_channels=1,input_sample_points=[28,28], classes=10)
model.to(device)
# 损失函数选择
criterion = torch.nn.CrossEntropyLoss()
criterion.to(device)
# 优化器选择
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.00001,momentum=0.9)
train_acc_list = []
test_acc_list = []
# 训练函数
def train(epoch):
model.train()
train_correct = 0
train_total = 0
for data in dataloader:
datavalue, datalabel = data
datavalue, datalabel = datavalue.to(device), datalabel.to(device)
datalabel_pred = model(datavalue)
loss = criterion(datalabel_pred, datalabel)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# probability, predicted = torch.max(datalabel_pred.data, dim=1)
probability, predicted = torch.max(datalabel_pred.data, dim=1)
train_total += datalabel_pred.size(0)
train_correct += (predicted == datalabel).sum().item()
if epoch % 10 == 0:
train_acc = round(100 * train_correct / train_total, 4)
train_acc_list.append(train_acc)
print('=' * 10, epoch // 10, '=' * 10)
print('loss:', loss.item())
print(f'训练集准确率:{train_acc}%')
test()
# 测试函数
def test():
model.eval()
global Confusion_matrix
test_correct = 0
test_total = 0
# 混淆矩阵变量
# Confusion_matrix = np.zeros([2, 2])
with torch.no_grad():
for testdata in testloader:
testdatavalue, testdatalabel = testdata
testdatavalue, testdatalabel = testdatavalue.to(device), testdatalabel.to(device)
testdatalabel_pred = model(testdatavalue)
testprobability, testpredicted = torch.max(testdatalabel_pred.data, dim=1)
test_total += testdatalabel_pred.size(0)
test_correct += (testpredicted == testdatalabel).sum().item()
# 混淆矩阵加载
# for i, j in zip(testdatalabel, testpredicted):
# Confusion_matrix[i][j] += 1
test_acc = round(100 * test_correct / test_total, 4)
test_acc_list.append(test_acc)
print(f'测试集准确率:{(test_acc)}%')
bestmodel = None
bestepoch = None
bestacc = 0
for epoch in range(1, 201):
# for epoch in range(1, 21):
train(epoch)
if epoch % 10 == 0:
if test_acc_list[epoch % 10 - 1] > bestacc:
bestacc = test_acc_list[epoch % 10 - 1]
bestepoch = epoch
bestmodel = copy.deepcopy(model)
print("最佳轮次为:{},最佳准确率为:{}".format(bestepoch, bestacc))
torch.save(bestmodel,"MINISTbest.pth")
torch.save(model,"MINISTlast.pth")
plt.plot(np.array(range(20))*10,train_acc_list)
plt.plot(np.array(range(20))*10,test_acc_list)
plt.legend(['train','test'])
plt.xlabel('epoch')
plt.ylabel('Accuracy')
plt.show()
3.3读取手写数字
自己写下几个数字,拍照重命名之后上传粘贴到该模型所处文件下,尝试进行读取手写的数字,看能否进行准确识别
#将图片处理成同数据集一样的图片
import cv2
#读入图像
img = cv2.imread("p4.jpg")
#二值化,是将图片呈现出明显的只有黑或白的
_,img = cv2.threshold(img,100,255,cv2.THRESH_BINARY)#进行阈值二值化操作,大于阈值100的用255表示,小于的用0表示
# Rectangular kernel使用了opencv库中的形态学操作函数,对二值化图像进行了开运算操作
#使用cv2.getStructuringElement函数创建了一个矩形结构元素(矩形卷积核,其中所有元素均为1),大小为(150,150)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (150, 150))
#腐蚀操作,在卷积核中,若同时出现像素值255和0的像素点,则0替换255,(即当卷积核框住的部分既有黑又有白时,把白变成黑)前提是输入图像必须是二值的
img = cv2.erode(img, kernel, iterations=1)
img = cv2.bitwise_not(img)#进行取反操作(弄这一步的话是白底黑字,取反之后变成黑底白字,因为数据集中都是黑底白字,所以将其变为一样的)
img = cv2.resize(img,(28,28))#图像的缩放,将图像尺寸改为28x28(同数据集内的尺寸大小相同)
img = cv2.GaussianBlur(img, (9, 9), 0)#高斯模糊,可以生成模糊图片,第一个参数是原图像,第二个参数是高斯矩阵,要注意长和宽都必须为正奇数,第三个参数是标准差,如果写0,则函数会自行计算。
#高斯矩阵的尺寸越大,标准差越大,处理过的图像模糊程度越大
cv2.imshow("img",img)
cv2.waitKey()
#waitkey控制着imshow的持续时间,当imshow之后不跟waitkey时,相当于没有给imshow提供时间展示图像,所以只有一个空窗口一闪而过。添加了waitkey后,哪怕仅仅是cv2.waitkey(1),我们也能截取到一帧的图像。所以cv2.imshow后边是必须要跟cv2.waitkey的。
#没有输入代表默认为0
(1)ret, dst = cv2.thresh(src, thresh, maxval, type)
参数说明, src表示输入的图片, thresh表示阈值, maxval表示最大值, type表示阈值的类型
(2) type的类型
1.cv2.THRESH_BINARY 表示阈值的二值化操作,大于阈值使用maxval表示,小于阈值使用0表示
2. cv2.THRESH_BINARY_INV 表示阈值的二值化翻转操作,大于阈值的使用0表示,小于阈值的使用最大值表示
3. cv2.THRESH_TRUNC 表示进行截断操作,大于阈值的使用阈值表示,小于阈值的不变
4. cv2.THRESH_TOZERO 表示进行化零操作,大于阈值的不变,小于阈值的使用0表示
5. cv2.THRESH_TOZERO_INV 表示进行化零操作的翻转,大于阈值的使用0表示,小于阈值的不变
手写数字6,原图为
运行图片为
形态学操作借鉴下面这位博主写的文章,感觉写的挺全面
形态学处理
在这里对字体的膨化操作是用的腐蚀来实现的,因为腐蚀和膨化都是相对于高亮部分来说,程序在用腐蚀操作时此时是白底黑字,腐蚀使白底部分缩小,之后又进行的取反操作将其变为黑底白字,然后再调整图片大小,进行显示图片。
按理说也可以对图片先取反,变成黑底白字,之后进行膨化操作,调整图片大小,但是按照这种情况跑出来的图片不是理想的模样,不知道原因出在什么地方。。。。
3.4手写数字识别程序
import torch
import numpy as np
import torchvision
import cv2
#模型加载
model = torch.load("MINISTbest.pth").to("cpu")
# trainDataset = torchvision.datasets.MNIST( # torchvision可以实现数据集的训练集和测试集的下载
# root="./data", # 下载数据,并且存放在data文件夹中
# train=True, # train用于指定在数据集下载完成后需要载入哪部分数据,如果设置为True,则说明载入的是该数据集的训练集部分;如果设置为False,则说明载入的是该数据集的测试集部分。
# # transform=transforms.ToTensor(), # 数据的标准化等操作都在transforms中,此处是转换
# download=True # 下载过程中如果中断,或者下载完成之后再次运行,则会出现报错
# )
# print(trainDataset.data.size())
# picture = torch.randn((1,1,28,28))
# # 读取数据集种的图片
# index = 150
# img = trainDataset.data[index].numpy()
# picture = trainDataset.data[index].to(torch.float32).view(-1,1,28,28)
# label = trainDataset.targets[index]
#
# model.eval()
# result = model(picture)
#
# result = (result - torch.min(result)) / (torch.max(result) -torch.min(result))
# import torch.nn.functional as F
# probabilities = F.softmax(result, dim=1)
# print(probabilities*100,'%\t',torch.argmax(result).item())
# cv2.imshow(f"{torch.argmax(result).item()}",img)
# cv2.waitKey()
# 读取手写图片
# img = cv2.imread("p1.jpg", 0)
# img = cv2.imread("p2.jpg", 0)
#img = cv2.imread("p3.jpg", 0)
img = cv2.imread("p4.jpg", 0)
# 二值化图片
_,img = cv2.threshold(img,50,255,cv2.THRESH_BINARY)
# 通过膨化加粗字体(此时是白底黑字,对于白底黑字的话来说腐蚀就是字体膨化)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (151, 151))
img = cv2.erode(img, kernel, iterations=1)
# 黑白取反
img = cv2.bitwise_not(img)
# 改变图片尺寸
img = cv2.resize(img,(28,28))
# 改变输入数据维度
img = torch.Tensor(img).view(1,1,28,28)
# 设置模型为测试模式
model.eval()
# 输入模型测试结果
result = model(img)
# 打印输出结果
print(result)
# 数据归一化,让输入数据经过softmax之后可以得到概率值
result = (result - torch.min(result)) / (torch.max(result) -torch.min(result))
# 导入softmax函数
import torch.nn.functional as F
# 计算概率
probabilities = F.softmax(result, dim=1)
# 打印概率值和预测标签
print(probabilities*100,'%\t',torch.argmax(result).item())
cv2.imshow(f"{torch.argmax(result).item()}",img.numpy().reshape(28,28))
cv2.waitKey()
其中所用到的数据归一化方法为min-max标准化,具体内容参照下面这位博主所写
数据归一化方法
结果运行为下图这种:

这里预测的结果不太准确,原因可能是由于训练速度太慢,我没有训练完LeNet模型,就进行了测试。
小结
到这里这个项目算是训练完成了,还是有很多的东西去学习,继续努力。















 2328
2328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









