






来源:书生浦语大模型全链路开源体系训练营培训课程学习笔记
刚开始学习很多地方不懂,不建议详细观看,建议前往以下地址:
https://arxiv.org/pdf/2403.17297.pdf
时间和能力有限,理解不到位,待后续学习会不断补充完善此文章内容!!!
一、学习笔记
大模型由专用模型发展到了通用模型。
internLM2是书生浦语最新的开源通用大模型,为用户提供了不同体量的模型大小。
1.internLL2的介绍:
1.1采用了新一代数据清洗技术:
采用了多维度数据价值评估 、高质量语料驱动的数据富集、有针对性的数据补齐等手段,使得训练更加高效。

1.2.主要亮点:
超长的上下文理解能力、综合性能的全面提升、优秀的对话和创作体验、工具调用能力的整体升级、突出的数理能力和实用的数据分析功能。

1.3.从模型到应用
我们可以根据以下流程来选择适合自己的大模型,书生浦语为我们提供了不同量级的模型:
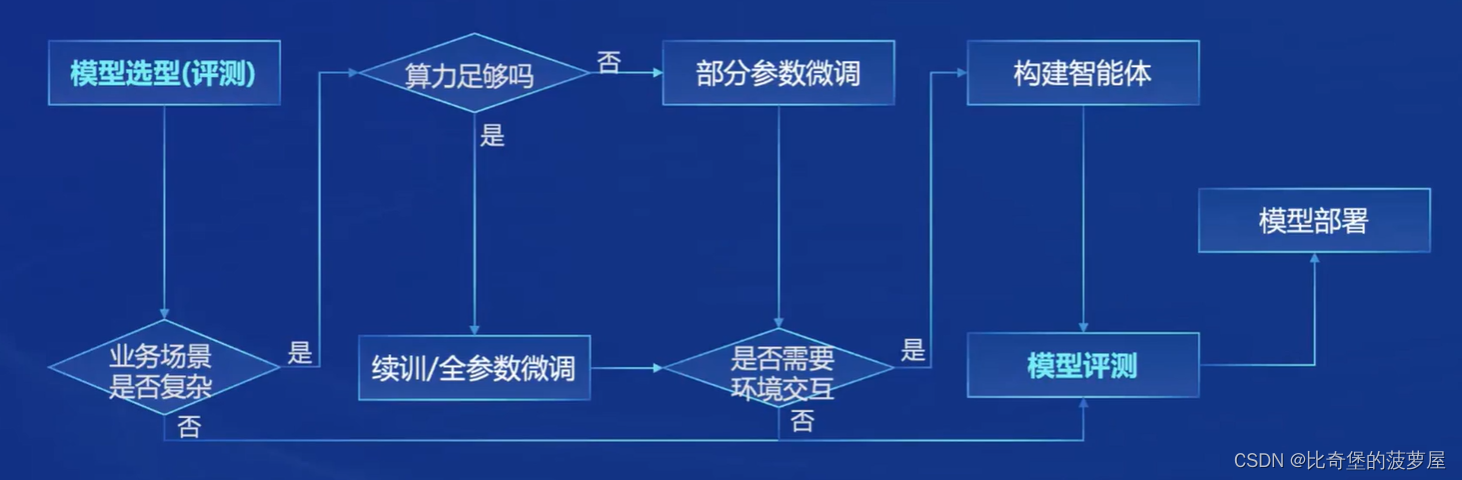
书生浦语是全链路开源的,各部分开源内容如下图所述:

2.全链路开源体系具体介绍:
获取地址:https://opendatalab.org.cn/
2.1.高质量语料数据:

书生万卷CC总数据量400GB,拥有时间跨度长、来源丰富、安全密度高等优点。
2.2预训练:

2.3微调:
增量续训和有监督微调俩种方式。
增量续训是使用书籍、文章、代码等来让基座模型学习到一些新知识,如某个垂直领域的知识。
有监督微调是使用高质量的对话和问答数据,让模型学会理解各种指令进行对话,或者注入少量领域知识。
开放了高效的微调框架XTuner
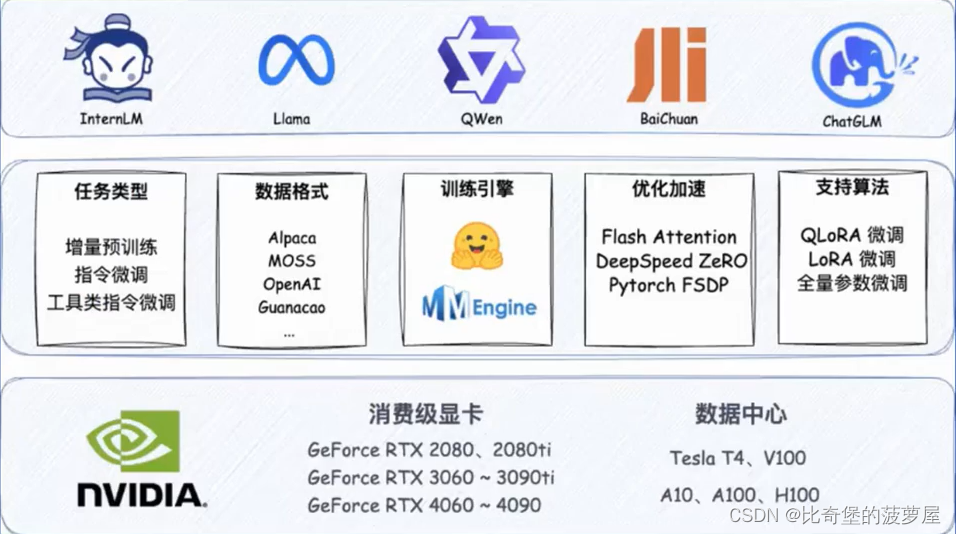
2.4评测
开放了OpenCompass2.0思南大模型评测体系
包括:
CompassKit:大模型评测全栈工具链
CompassHub:高质量评测基准社区
OpenCompass助力大模型产业发展和学术研究,广泛应用于头部大模型企业和科研机构

2.5部署
LMDeploy提供大模型在GPU上部署的全流程解决方案,包括模型轻量化、推理和服务。


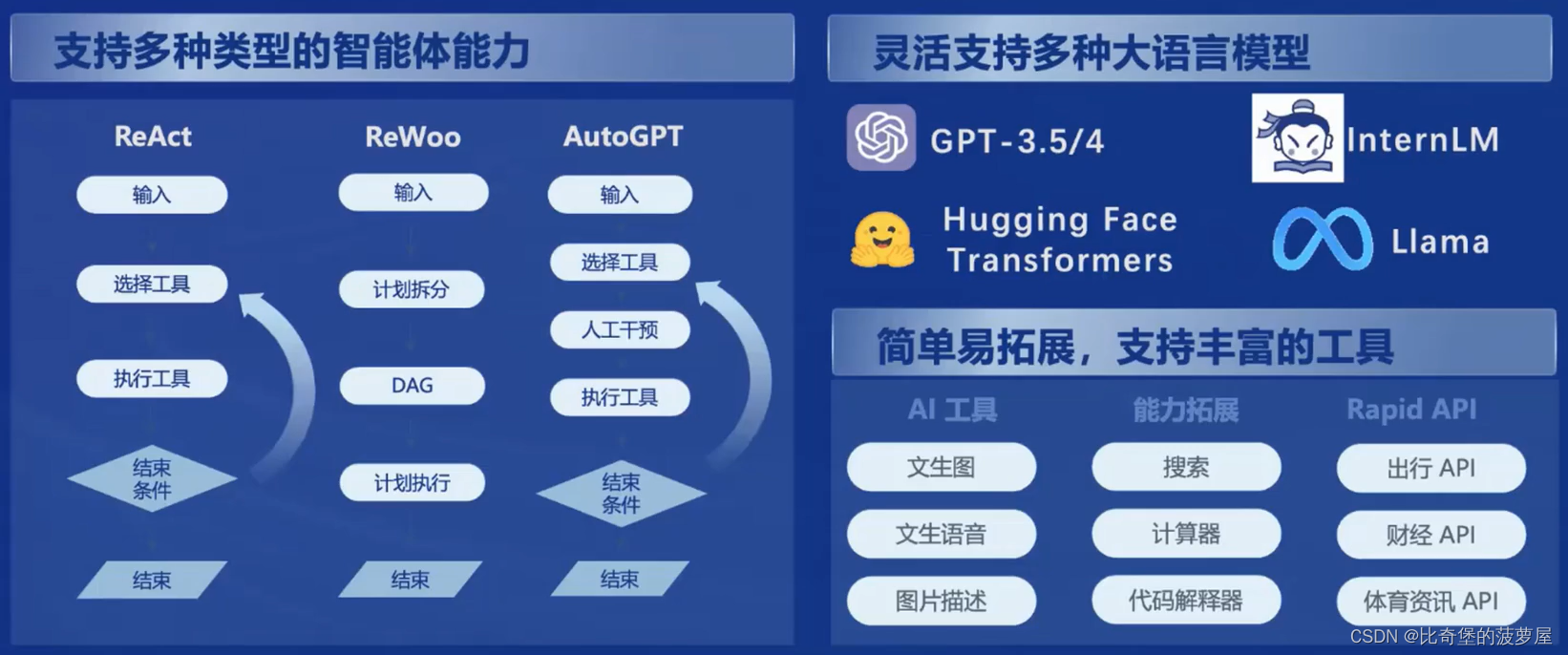
2.6智能体

二、internLM2技术报告
1.摘要:
本文介绍了InternLM 2,这是一个开源的LLM,通过创新的预训练和优化技术,在6个维度和30个基准的综合评估,长上下文建模和开放式主观评估方面优于其前辈。InternLM 2的预训练过程非常详细,强调了各种数据类型的准备,包括文本,代码和长上下文数据。InternLM 2有效地捕获长期依赖关系,最初在4k token上训练,然后在预训练和微调阶段推进到32 k token,在200 k“Needle-in-a-Haystack”测试中表现出出色的性能。InternLM 2使用监督微调(SFT)和一种新的基于人类反馈的条件在线强化学习(COOL RLHF)策略进一步调整,该策略解决了人类偏好和奖励黑客的冲突。通过在不同的训练阶段和模型大小发布InternLM 2模型,为社区提供了对模型演变的见解。
2.介绍:
本报告介绍了一个开源的LLM。
大型语言模型(LLM)的开发包括几个主要阶段:
2.1预训练
预训练主要基于利用大量的自然文本语料库,积累数万亿的令牌。这一阶段的目的是为LLM配备广泛的知识库和基本技能。数据的质量被认为是预训练过程中最关键的因素。
如何有效地扩展LLM的上下文长度是当前的热门研究课题。InternLM2首先采用了Group Query Attention(GQA)来在推断长序列时实现更小的内存占用。在预训练阶段,首先用4k上下文文本训练InternLM 2,然后将训练语料库转换为高质量的32k文本进行进一步训练。完成后,通过位置编码外推(LocalLLaMA,2023),InternLM 2在200k上下文中的“干草堆中的针”测试中取得了值得称赞的性能。
2.2监督微调(SFT)
选择有条件的奖励模型来协调不同但可能相互冲突的偏好,在长时间的上下文预训练之后,利用监督微调(SFT)和来自人类反馈的强化学习(RLHF)来确保模型很好地遵守人类指令并与人类价值观保持一致。
2.3来自人类反馈的强化学习(RLHF)
选择有条件的奖励模型来协调不同但可能相互冲突的偏好,在长时间的上下文预训练之后,利用监督微调(SFT)和来自人类反馈的强化学习(RLHF)来确保模型很好地遵守人类指令并与人类价值观保持一致。
3.准备工作
介绍了在预训练、SFT和RLHF中使用的训练框架InternEvo。
3.1internEvo
internEvo一个高效和轻量级的预训练框架,用于模型训练。这个框架使我们能够在数千个GPU上扩展模型训练。这是通过数据、张量、序列和管道并行。为了进一步增强GPU内存效率,InternEvo结合了各种零冗余优化器(ZeRO)策略,显著减少了培训所需的内存占用。

上图为使用InternEvo培训InternLM-7 B的FLOPs模型利用率(MFU)。使用不同GPU数量的4096个令牌的序列长度对训练性能进行基准测试,并使用不同序列长度的128个GPU对训练性能进行基准测试。
3.2model structure
Transformer由于其出色的并行化能力而被主要用作过去的大型语言模型(LLM)的主干,该并行化能力充分利用了GPU的能力。LLaMA通过替换LayerNorm与RMSNorm,并将激活函数设置为SwiGLU,从而提高了训练效率和性能。
自从LLaMA,社区积极参与增强围绕LLaMA架构构建的生态系统。这包括高效推理(lla,2023)和算子优化(Dao,2023)等方面的进步。为了确保我们的模型,InternLM 2与这个完善的生态系统以及其他著名的LLM,本文选择坚持LLaMA的结构设计原则。
为了提高效率,整合了Wk、Wq和Wv矩阵,这使得预训练阶段的训练加速超过5%。此外,为了更好地支持各种张量并行(tp)转换,重新配置了矩阵布局。不是以简单的方式堆叠Wk、Wq和Wv矩阵,而是对每个头的Wk、Wq和Wv采用交织方法,如下图所示。这种设计修改通过沿着它们的最后一个维度拆分或连接矩阵来促进张量并行大小的调整,从而增强了模型在不同分布式计算环境中的灵活性。InternLM 2旨在推断32 K上下文之外的内容,InternLM2系列模型都选择分组查询注意力(GQA),因此它可以在高速和低GPU内存中使用非常长的上下文进行推断。

4.预训练
4.1预训练数据
LLM的预培训受到数据的严重影响,这带来了多方面的挑战。它包括处理敏感数据,涵盖全面的知识,并平衡效率和质量。在本节中,文章将描述用于准备一般领域文本数据、编程语言相关数据和长文本数据的数据处理管道。
4.2预训练设置
介绍了标记化和预训练超参数

使用GPT-4的标记化方法,因为它在压缩大量文本内容方面具有出色的效率。主要参考是cl 100 k vocabulary 4,它主要包括英语和编程语言token,总共100,256个条目,少量包含不到3000个中文token。为了优化InternLM在处理中文文本时的压缩率,同时保持整体词汇量在100000以下,我们从cl 100 k词汇表中仔细选择了前60004个标记,并将它们与32,397个中文标记集成在一起。此外,我们还包括了147个备用标记来完成选择,最终达到了与256的倍数一致的词汇量,从而促进了有效的训练。
4.3预训练阶段
用于预训练1.8B、7B和20B模型的令牌总数从2.0T到2.6T不等,预训练过程由三个不同的阶段组成。在第一阶段,我们使用长度不超过4k的预训练语料库。在第二阶段,我们包括50%的长度不超过32k的预训练语料库。在第三阶段,我们利用特定功能的增强数据。在每个阶段,我们混合了英文、中文和代码的数据。
5.微调
预培训阶段赋予LLM解决各种任务所需的基础能力和知识。我们进一步微调LLM,以充分挖掘它们的能力,并引导LLM成为有用且无害的AI助手。这一步通常被称为“对齐”,通常包含两个阶段:
监督微调(SFT)和来自人类反馈的强化学习(RLHF)。
在SFT过程中,我们通过高质量的指令数据对模型进行微调,以遵循不同的人类指令。然后,我们提出了条件在线RLHF,它应用了一种新的条件奖励模型,可以协调不同种类的人类偏好(例如,多步推理的准确性,有用性,无害性),并进行三轮在线RLHF,以减少奖励黑客。在对齐阶段,我们通过利用SFT和RLHF 4.3期间的长上下文预训练数据来保持LLM的长上下文能力。我们还介绍了我们的做法,提高LLM 4.4的工具利用能力。
有条件奖励模型是一个创新的解决方案,固有的挑战,在以前的偏好建模RLHF方法。与通常依赖于多个偏好模型来解决不同领域的偏好冲突的传统方法不同,条件奖励模型结合了针对不同类型偏好的不同系统提示,以有效地在单一奖励模型中对各种偏好进行建模。

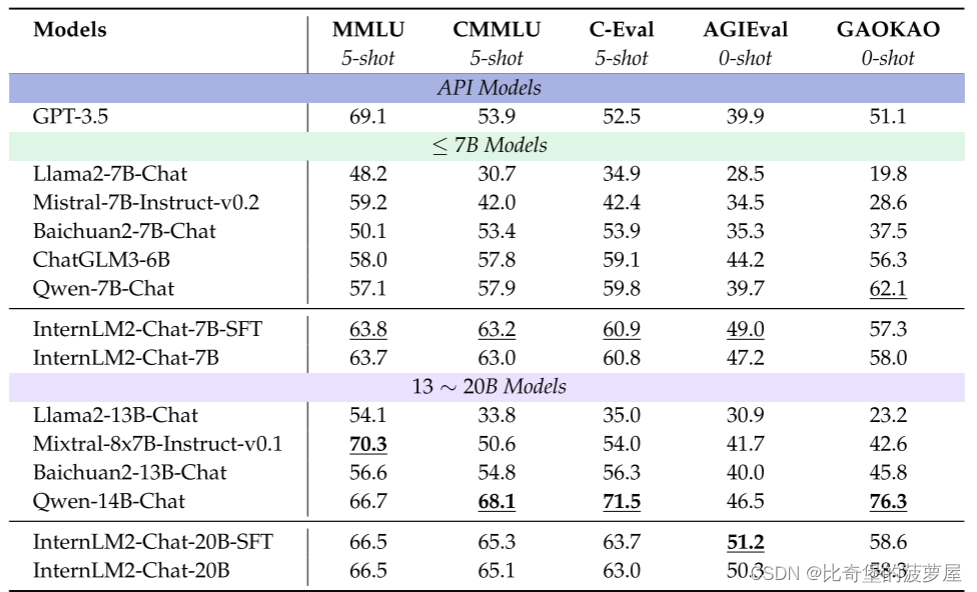
6.结果评价分析
在本节中,文章将对语言模型在各个领域和任务中的性能进行全面的评估和分析。评价分为两大类:
(a)下游任务
(B)协调一致
对于每个类别,我们进一步将评估分解为特定的子任务,以详细了解模型的优点和缺点。最后讨论了语言模型中的数据污染及其对模型性能和可靠性的影响。除非另有明确规定,否则所有评估均使用OpenCompass。

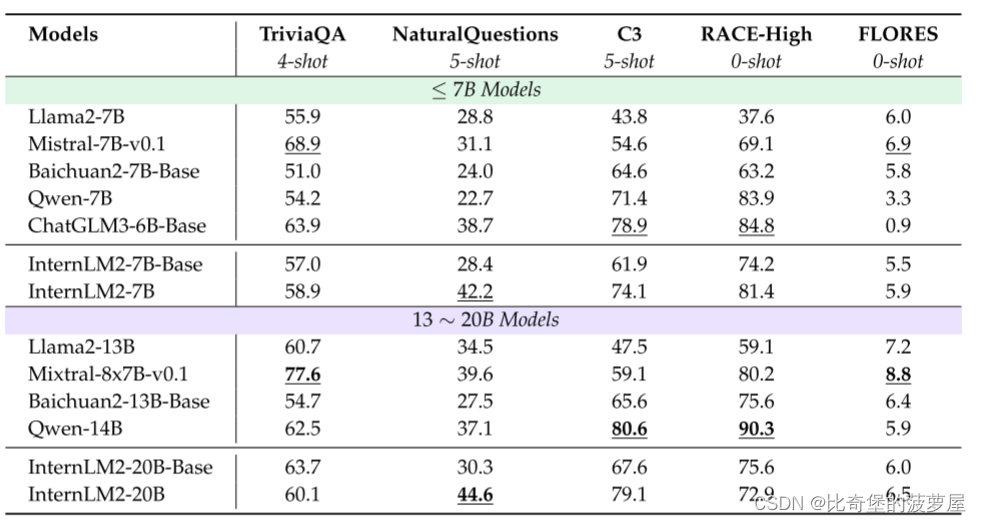




7.总结
在本报告中,我们介绍了InternLM2大型语言模型,该模型在主观和客观评估中表现出卓越的性能。InternLM2已经在超过2T的高质量预训练语料库上进行了训练,覆盖了1.8B、7B和20B的模型大小,适用于各种场景。为了更好地支持长上下文,InternLM2采用GQA来降低推理成本,并在多达32k的上下文上进行了额外的训练。除了开源模型本身,我们还提供了训练过程中各个阶段的检查点,方便未来的研究。除了开源模型之外,我们还详细描述了我们如何训练InternLM 2,包括训练框架,预训练文本数据,预训练代码数据,预训练长文本数据和对齐数据。此外,为了解决RLHF过程中遇到的偏好冲突,我们提出了有条件的在线RLHF,以协调各种偏好。这些信息可以提供有关如何准备预训练数据以及如何更有效地训练更大模型的见解。















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









