






P-tuning (Xiao Liu, 2021)和提示词微调方法思想相似,都是通过对虚拟提示词进行编码的得到一个向量加在输入里的连续提示词方法。但是P-tuning与提示词微调有一个显著的不同,提示词微调只把额外的向量加在了输入向量的前面,而P-tuning可以在输入向量的前面和后面都加入额外的提示词向量,这增加了微调的能力。
除此以外,P-tuning还提出了新的Prompt encoder,用来建模虚拟提示词的词嵌入函数f(Pi)=hi,并尝试用长短期记忆网络(LSTM)或多层感知器(MLP)来实现Prompt encoder。
(Xiao Liu, 2021)实验发现P-tuning使得GPT这类生成式模型在NLU任务中性能有大幅提升。
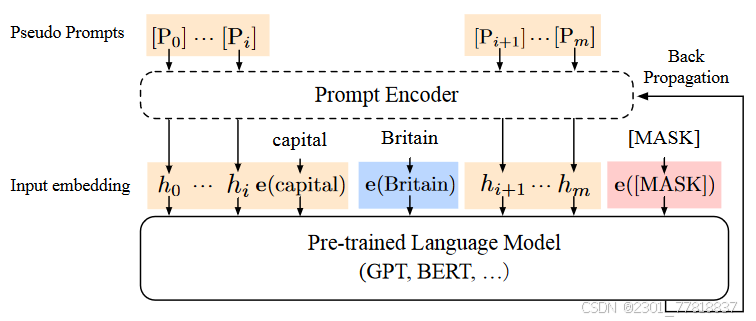
图 1 P-tuning原理示意图
P-tuning可以使用HuggingFace的peft包来实现。使用下面的命令来安装peft包。之后将以peft包来实现P-tuning的过程。
$ pip install peft
首先要载入基础模型和分词器的,下面是一段示例代码,用于载入bert模型用于文本分类任务。
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_path = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(
model_path, num_labels=3
)然后是微调的设置部分,这里使用peft包提供的PromptEncoderConfig类和get_peft_model函数来创建PromptEncoder和增强基础模型。下面是一段示例代码。
from peft import PromptEncoderConfig, get_peft_model
# 创建PromptEncoder的配置
peft_config = PromptEncoderConfig(task_type="SEQ_CLS",
num_virtual_tokens=10, encoder_hidden_size=128)
# 创建PromptEncoder来增强基础模型
model = get_peft_model(model, peft_config)PromptEncoderConfig类主要有以下参数:
-
- Task_type:任务类型,如SEQ_CLS文本分类,SEQ_2_SEQ_LM文本生成。
- encoder_reparameterization_type:使用的重新参数化的类型,MLP或LSTM。
- encoder_hidden_size:prompt encoder的隐藏层的参数量。
- encoder_num_layers:prompt encoder的隐藏层的层数。
- encoder_dropout:prompt encoder中会加入一个dropout层,这个参数设置dropout的概率。
最后,设置训练参数,并启动训练过程。训练参数参考适配器微调(Adapter tuning)-CSDN博客。
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
do_eval=False,
learning_rate=1e-3,
num_train_epochs=10,
per_device_train_batch_size=16,
output_dir="D:\\LLM\\BERT\\bert-trouble-shooting-ptuning-001",
weight_decay=0.01,
save_strategy="epoch",
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer
)
trainer.train()推理时需要先使用AutoModelForSequenceClassification加载基础模型,再使用peft包的PeftModel类加载prompt encoder。下面是一段示例代码。
from peft import PeftModel
# 加载训练好的prompt encoder
model = PeftModel.from_pretrained(model, "D:\\LLM\\BERT\\bert-trouble-shooting-ptuning-001\\")参考文献:
Xiao Liu, K. J. (2022). P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. Proceedings of the 60th Annual Meeting of the Association of Computational Linguistics.
Xiao Liu, Y. Z. (2021). GPT Understands, Too.

















 2842
2842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









