






前缀微调(Prefix tuning)最初被 (Xiang Lisa Li, 2021)提出用于微调文本生成任务。类似提示词的原理,适当的上下文可以引导语言模型生成特定的词,而无需更改其参数。例如,如果希望LM生成一个词(例如,群众),可以在上下文中添加其常见的搭配(例如,人民),语言模型将对所需的词分配更高的概率。将这种直觉扩展到生成单个词或句子以外,我们希望找到一个上下文,可以引导语言模型解决自然语言生成(NLG)任务。寻找这样合适的上下文存在理论上的可能,但在计算上具有很大的挑战性。
为此, (Xiang Lisa Li, 2021)提出了一种为特定任务添加连续的向量序列的方法。如下图所示,它在每一层transformer的自注意力模块中的key、value向量前添加一个向量序列,再通过后向传播来求解。后来,经过一系列实验发现,直接求解这个前缀向量对学习率和参数的初始化非常敏感,导致微调的性能不稳定。因此,论文原作者又对训练过程进行了改进,训练时加入了一个多层感知网络(MLP),如图中虚线框中部分所示,推理时可以删除这个多层感知网络,只保留其输出值。
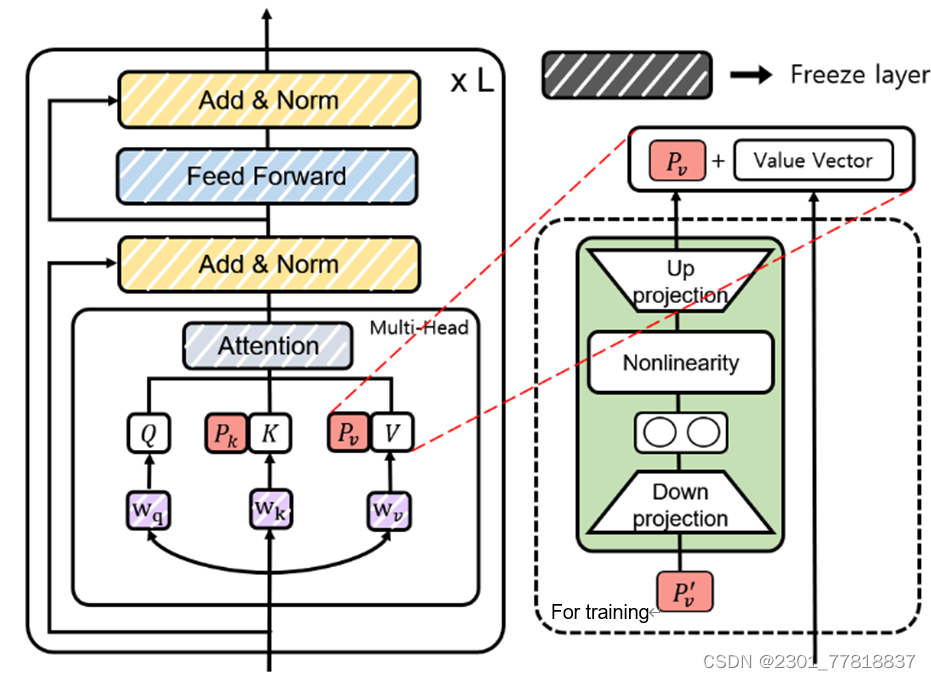
通过对比实验发现,前缀微调在使用更少的参数的情况下(0.1%的参数),得到了与全量微调和适配器微调(3%的参数)相当的效果;在大部分实验中,模型性能要强于传统的迁移学习方法(仅微调顶部的两层)和同等参数量的适配器微调(0.1%的参数)。
前缀微调使用开源的Adapters包(https://github.com/adapter-hub/adapters)来实现,通过PrefixTuningConfig来进行配置即可。整体流程和适配器微调(Adapter tuning)相同,只是把BnConfig换成了PrefixTuningConfig,再次不做赘述,主要介绍下PrefixTuningConfig类,它有以下参数:
- flat:是否需要加入多层感知网络来训练前缀参数。如果是False,则是需要;如果是True,则直接训练。
- encoder_prefix:如果是True,只在encoder里加入前缀参数。
- cross_prefix:如果是True,只在交叉注意力里加入前缀参数。
- prefix_length:设置前缀的长度。
下面是一个代码示例。如果flat为False进行训练,在保存模型时需要调用eject_prefix_tuning方法,传入之前训练用的名称,这样会把训练时用的多层感知网络删除,从而节省存储空间,之后推理时也能使用更少的参数,更快推理。
from adapters import PrefixTuningConfig
# 配置前缀参数
adapter_name = "trouble_shooting"
config = PrefixTuningConfig(flat=False, encoder_prefix=True, prefix_length=12)
model.add_adapter(adapter_name, config=config)
… … … …
# 训练前缀参数
model.train_adapter(adapter_name)
… … … …
# 删除训练用的多层感知网络
model.eject_prefix_tuning(adapter_name)
参考文献:
Xiang Lisa Li, P. L. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation.
Yunho Mo, J. Y. (2023). Parameter-Efficient Fine-Tuning Method for Task-Oriented. Mathematics.














 2874
2874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









