






 本文详细指导如何在Linux系统上安装Hadoop2.7.2,包括下载、JDK配置、环境变量设置、主机名/IP映射、XML文件修改以及YARN和HDFS配置,为Hadoop学习奠定基础。
本文详细指导如何在Linux系统上安装Hadoop2.7.2,包括下载、JDK配置、环境变量设置、主机名/IP映射、XML文件修改以及YARN和HDFS配置,为Hadoop学习奠定基础。
8.下面我们开始安装配置Hadoop
1)首先下载hadoop-2.7.2的jar包 并添加到我们的jtxy1的/root/目录下

2)yum install在线安装软件
-
yum install net-tools //支持ifconfig
-
yum install vim //支持vim
-
yum install glibc.i686 --java命令不好使

3)因为Hadoop是Java做的 所以我们需要jdk的支持 我们下载上传一下jdk到我们的jtxy1的/root/目录下

上传完成以后 我们开始安装jdk 首先解压
tar -zxvf jdk-8u144-linux-x64.tar.gz -C /usr/local/

-zxvf:z 解压 x 抽取 v 查看进度 -C 到xx目录下
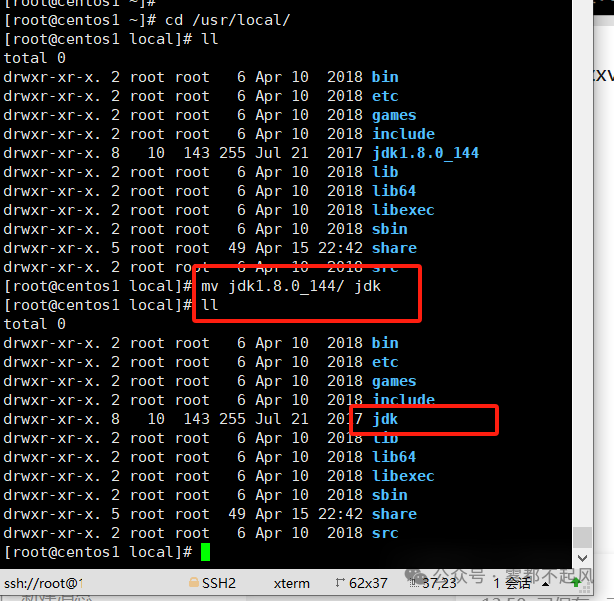
修改一下jdk的名字 方便后续操作
4)下面我们配置一下Java的环境变量
vim /etc/profile 按i 进入到INSERT状态下
添加以下两行代码 完成后点击Esc Shift+: 输入wq 保存并退出
export JAVA_HOME=/usr/local/jdkexport PATH=$PATH:$JAVA_HOME/bin
$:指的是取变量值 然后与后面输入的进行拼接

在shell编程中 我们可以定义一个变量 如v=33 那么 如果我们在它的前面加一个export 我们就可以在所有路径中访问它了
添加完以后 我们输入source /etc/profile 使里面的变量生效 生效以后 这个变量变成一个全局变量 我们就可以访问Java了

注意:我们在java下面 如果输入cd before 我们是进不去的 因为这样他会认为是进入java下面的目录 所以我们要加绝对路径 cd d:/before

5)下面我们安装Hadoop
a.配置主机名和ip地址映射
vim /etc/hosts

b.解压
tar -zxvf hadoop-2.7.2.tar.gz -C /usr/local/
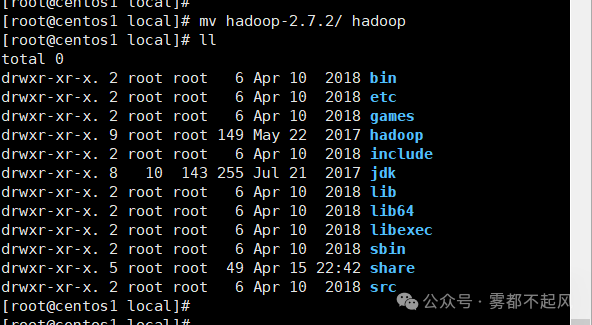
c.修改名字
mv hadoop-2.7.2 hadoop
d.进入到hadoop中 配置xml文件
cd /usr/local/hadoop/etc/hadoop/
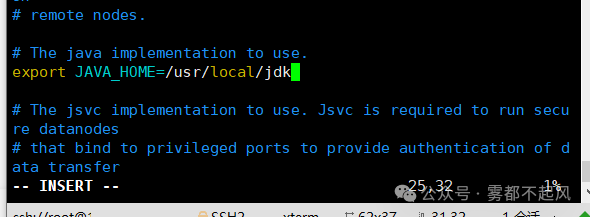
①首先 修改vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
②然后 修改vim core-site.xml
<property><name>fs.defaultFS</name><value>hdfs://centos1:9000</value></property><!-- 指定hadoop运行时产生文件的存储目录,最终分片的块数据 --><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value></property>

③然后 修改vim hdfs-site.xml
<property><name>fs.checkpoint.period</name><value>3000</value></property><!-- 指定HDFS副本的数量 (集群下,有多台机,可多份,目前就一台)--><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property>
④然后 修改vim mapred-site.xml
先修改一下名字 mv mapred-site.xml.template mapred-site.xml
<!-- 告诉hadoop 指定mr运行在yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
⑤最后 修改yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 yarn --><property><name>yarn.resourcemanager.hostname</name><value>centos1</value></property><!-- reducer获取数据的方式是shuffle方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
e.配置Hadoop环境变量
export HADOOP_HOME=/usr/local/hadoopexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
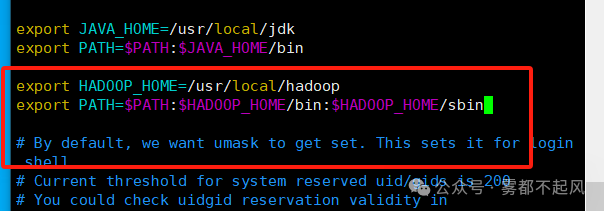
配置完成后 我们source /etc/profile 使变量生效一下

到这里 Hadoop的安装配置我们就完成啦 下面就可以开始Hadoop的学习了















 6152
6152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









