






Spark基础
期待您的关注
☀小白的spark学习笔记 2024/6/3 08:30
目录
1.课程目标

2.Spark基于内存计算
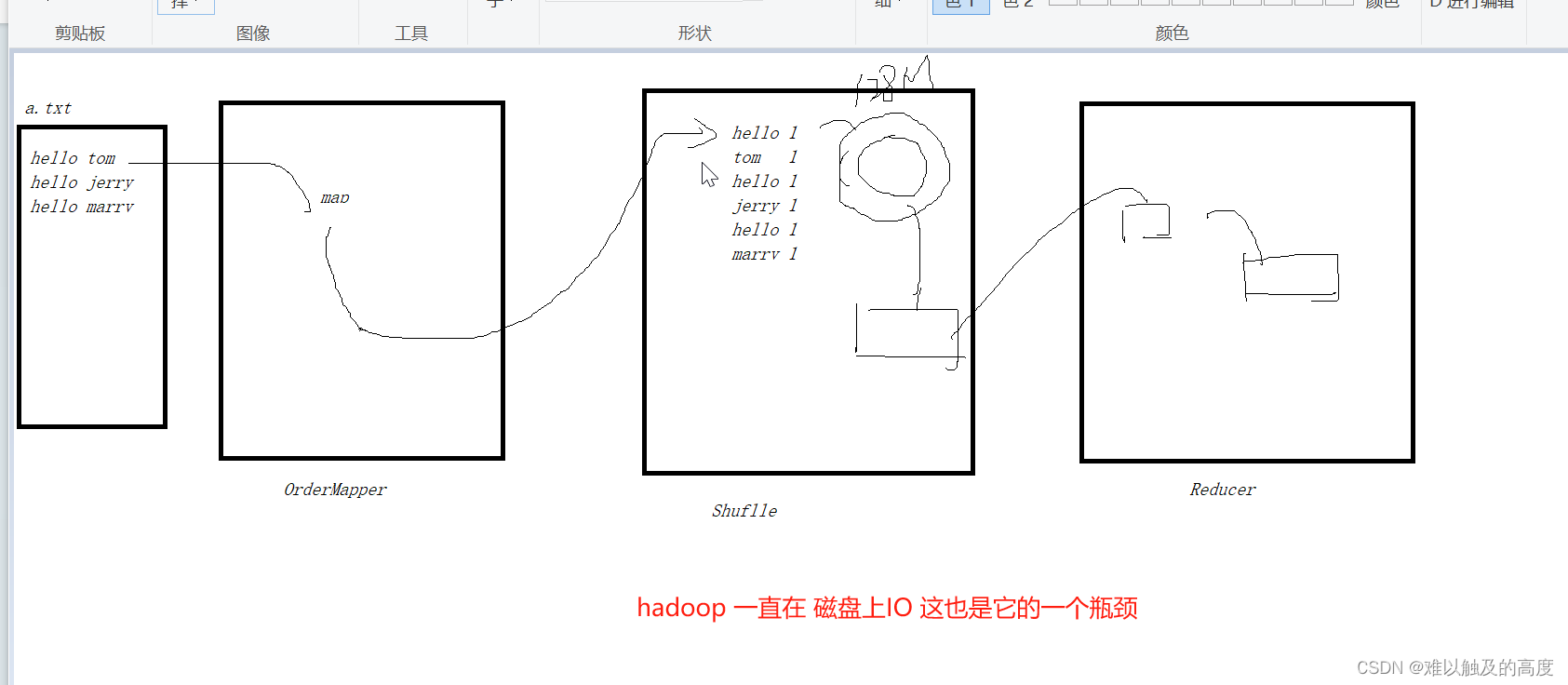
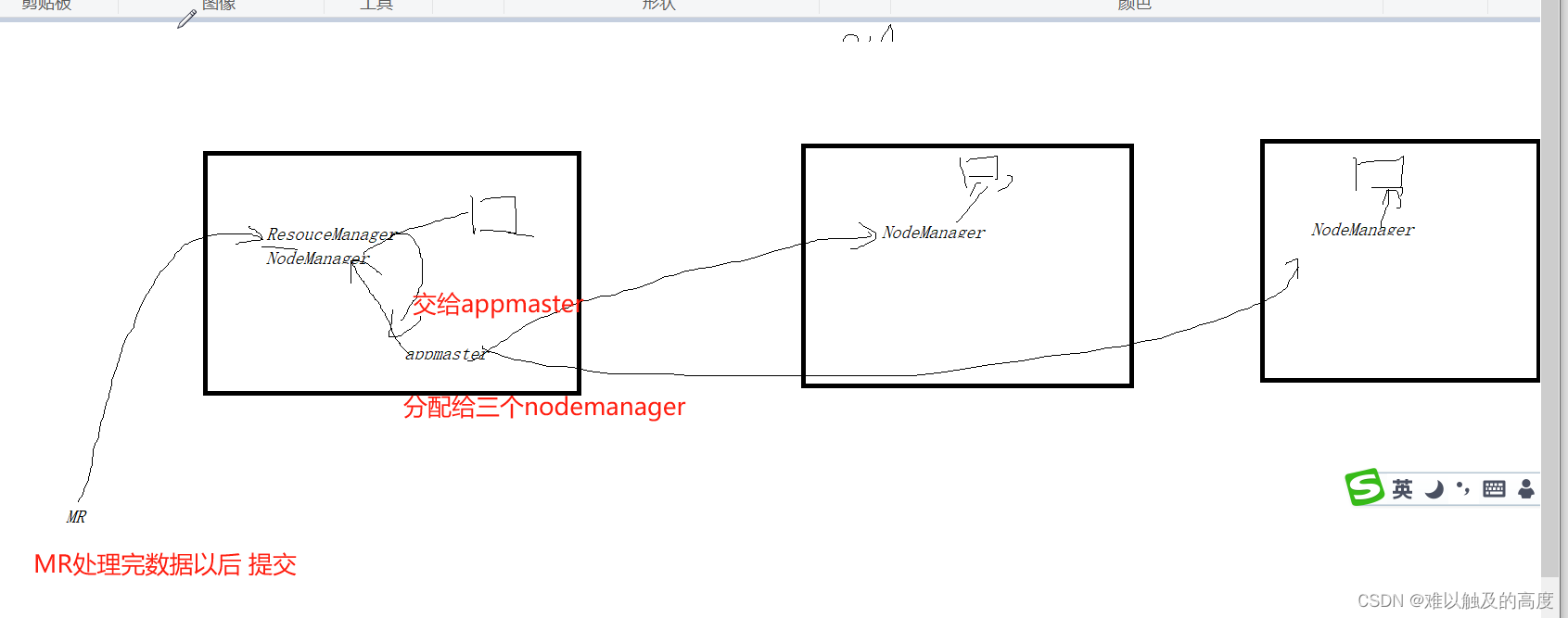
Hadoop的MapReduce
1.Mapper 产生KV对
2.Shuffle 洗牌 排序
3.Reduce 汇总
瓶颈:MapReduce 基于磁盘运算 速度较慢
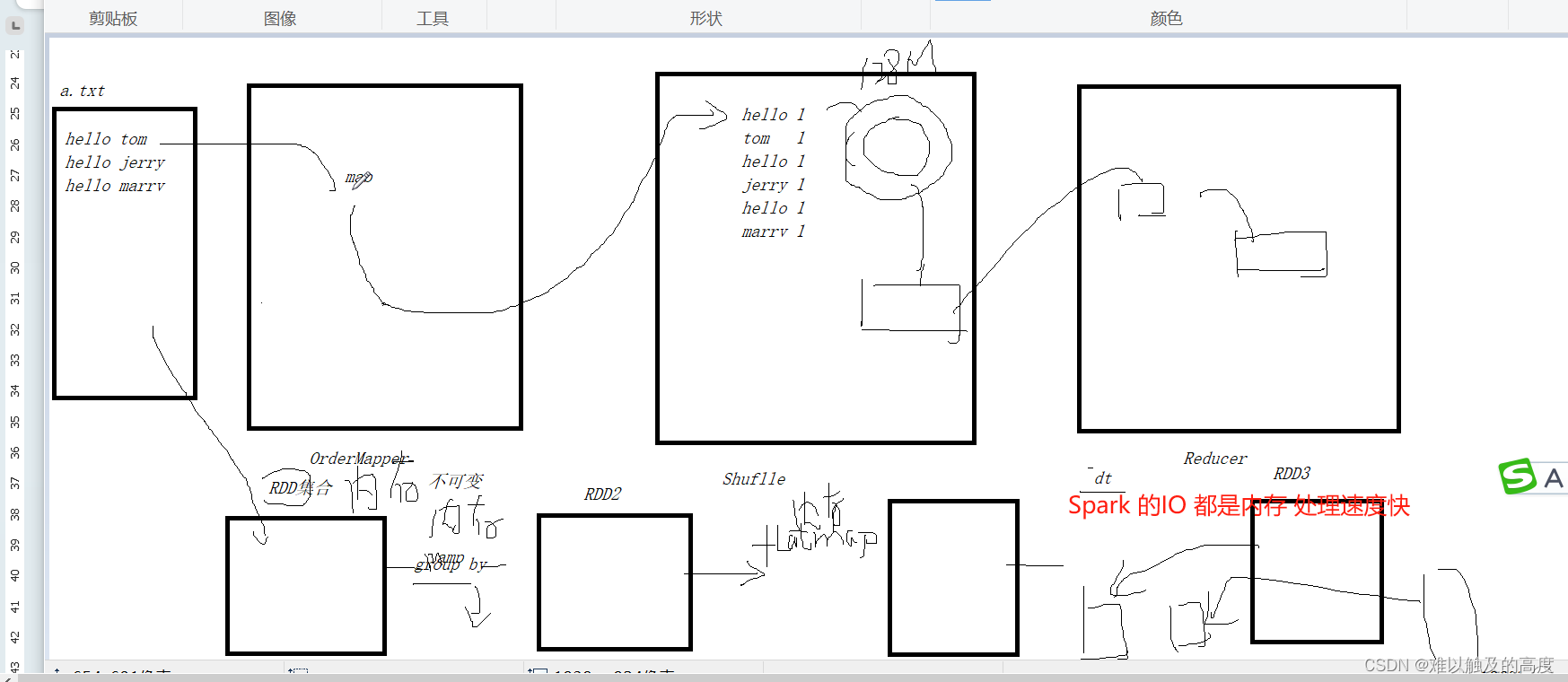
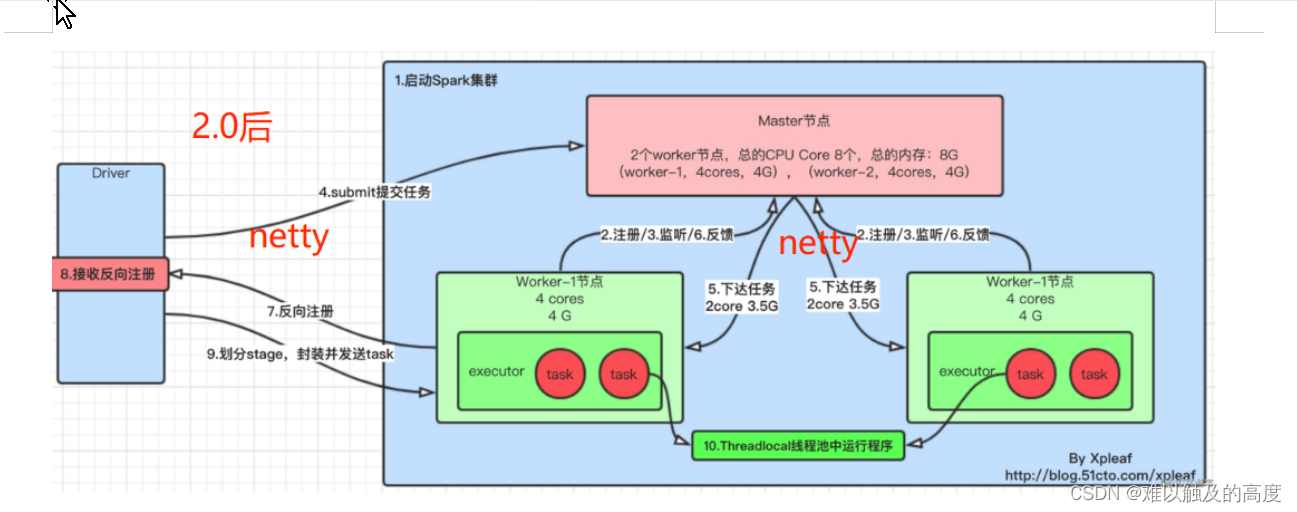
Spark 基于内存运算 速度快 易用 通用 兼容性好
3.Spark安装
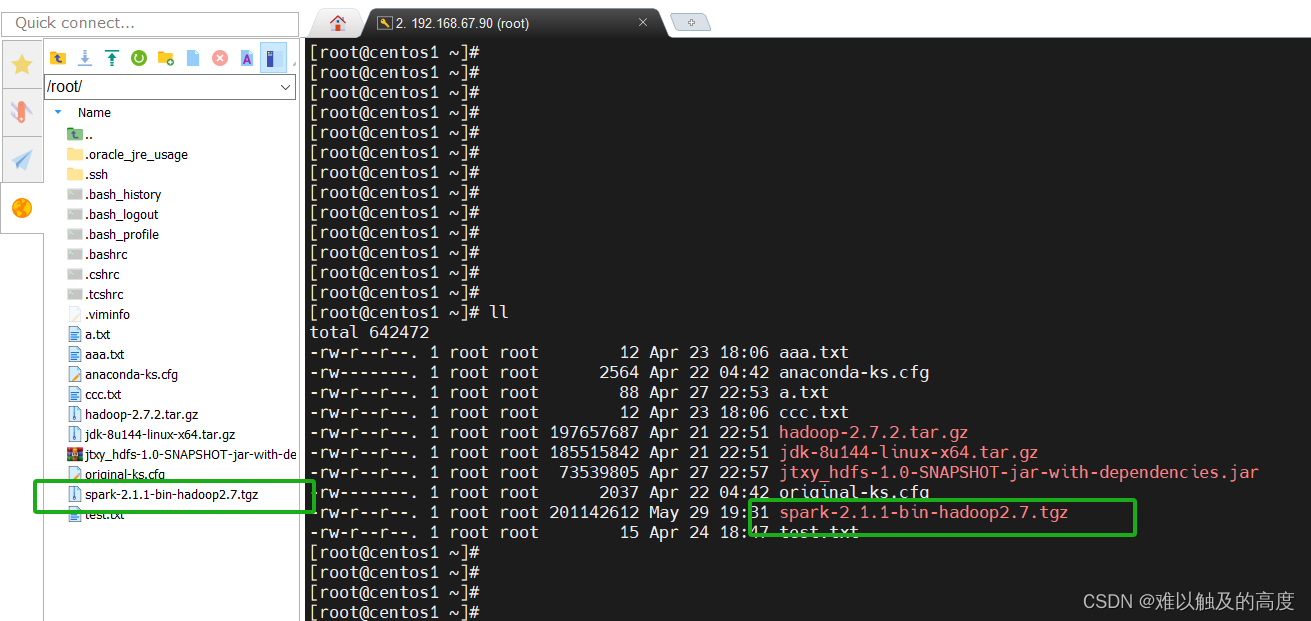
1)下载spark文件
文件(可以私信获取)打开我们之前创建的虚拟机 将其添加进去
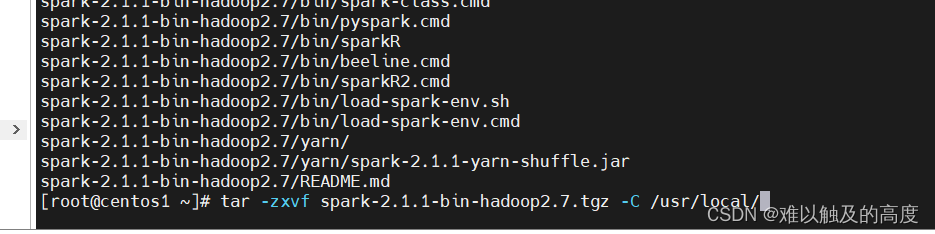
2)解压Spark
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /usr/local/
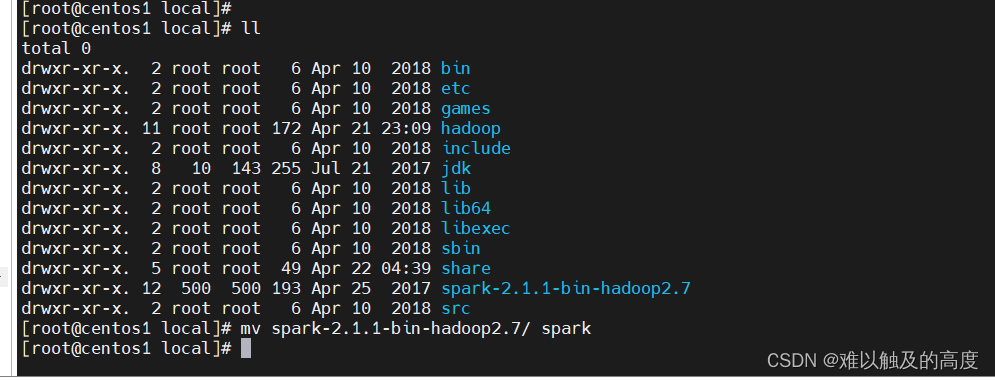
cd /usr/local
mv spark-2.1.1-bin-hadoop2.7 spark
3)修改配置文件
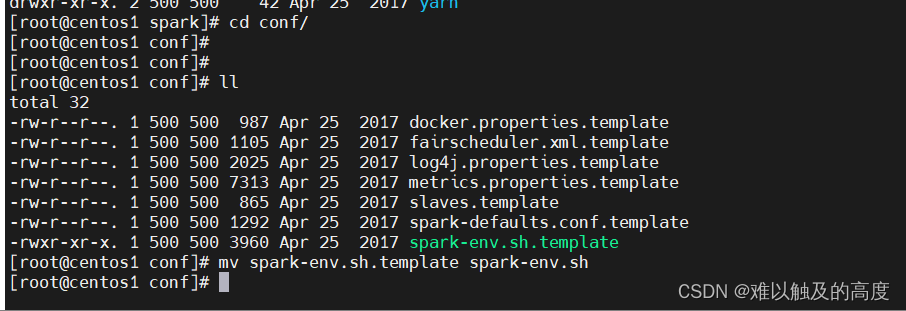
cd /usr/local/spark/conf/
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
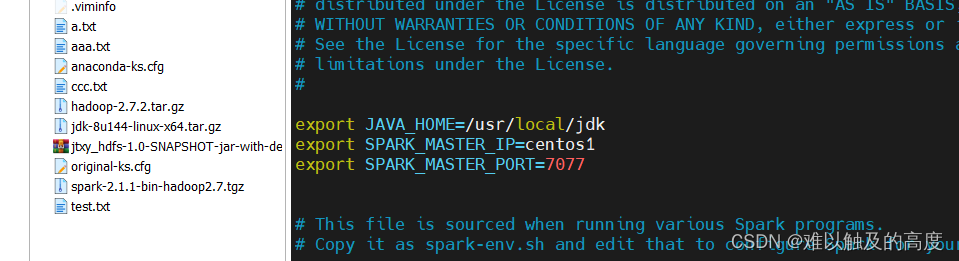
添加
export JAVA_HOME=/usr/local/jdk
export SPARK_MASTER_IP=contos1
export SPARK_MASTER_PORT=7077
mv slaves.template slaves
vim slaves
修改为 centos1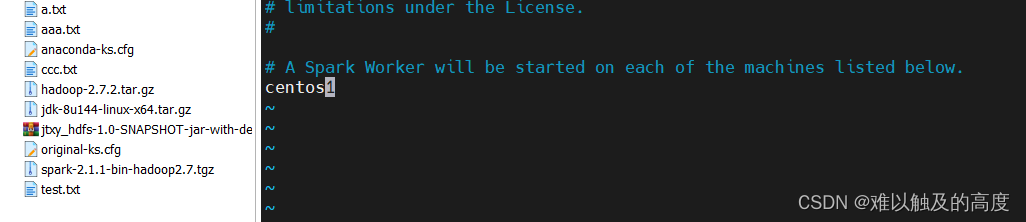
5)配置环境变量
vim /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile
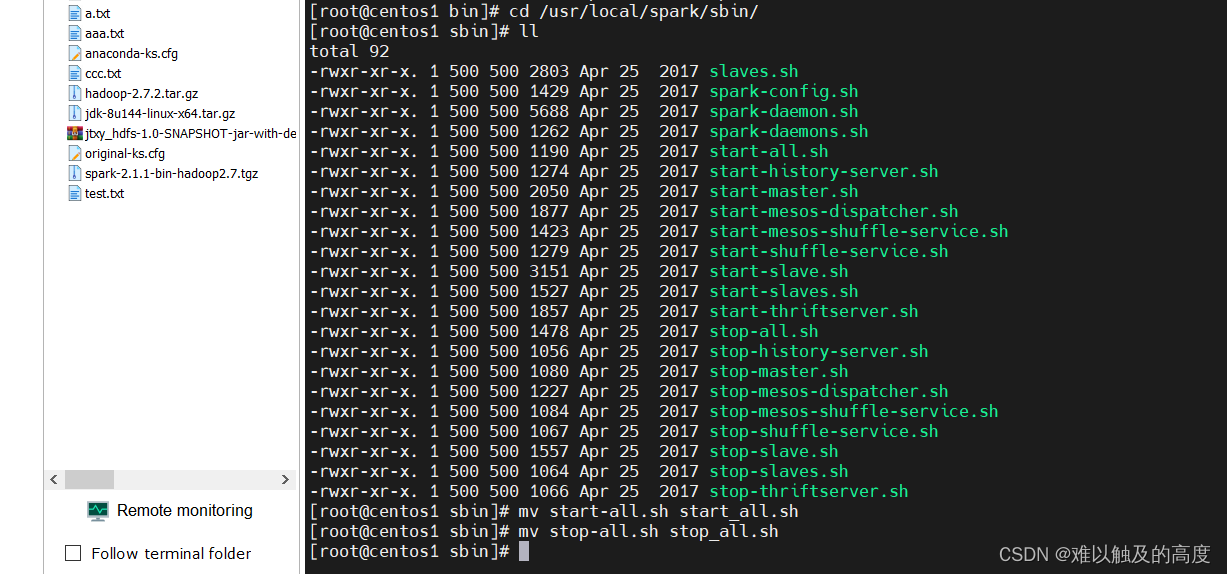
5)修改启动命令
cd /usr/local/spark/sbin/
ll
mv start-all.sh start_all.sh
mv stop-all.sh stop_all.sh
4.Spark工作原理
回顾一下Hadoop工作原理
Spark工作原理
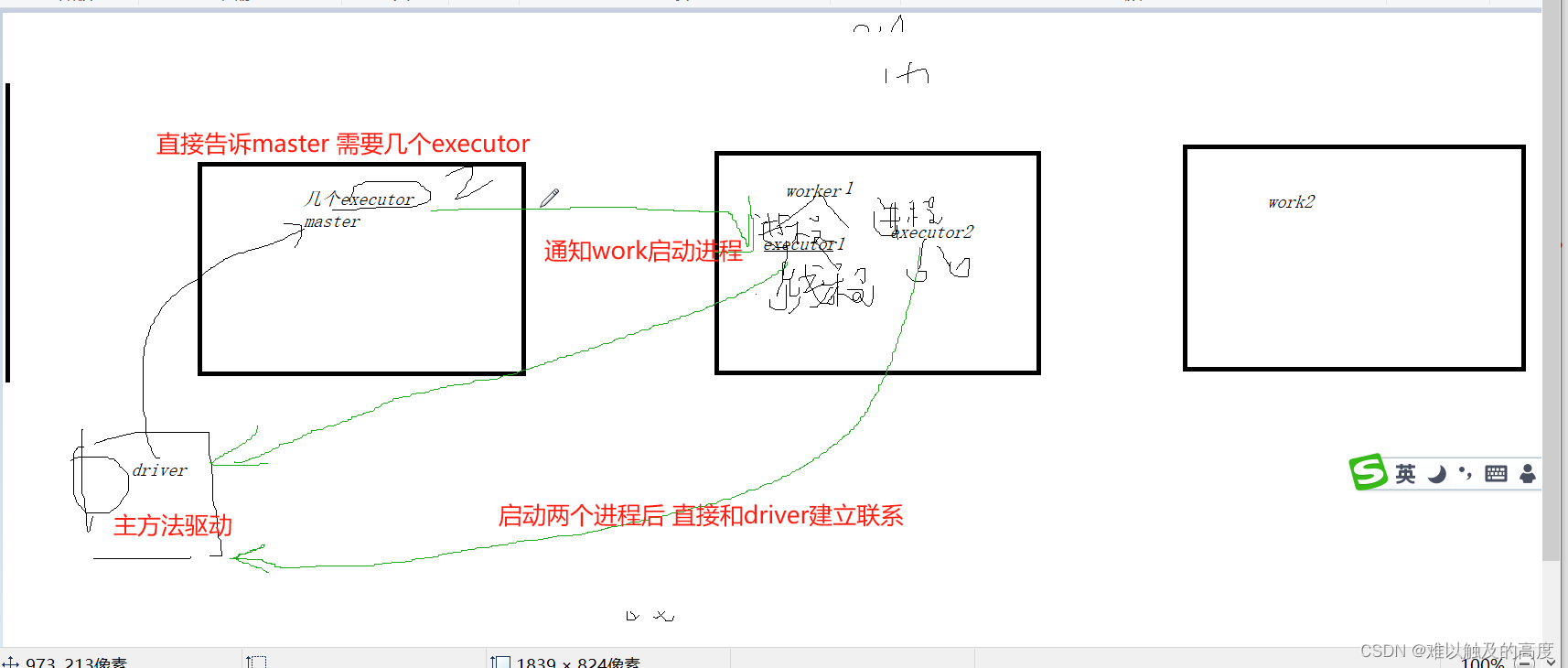
5.启动Spark
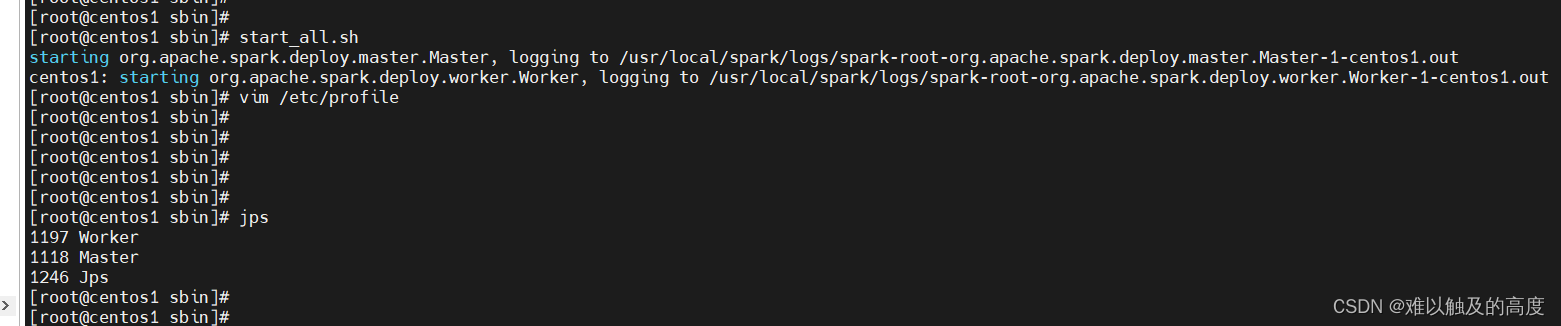
1)启动
start_all.sh
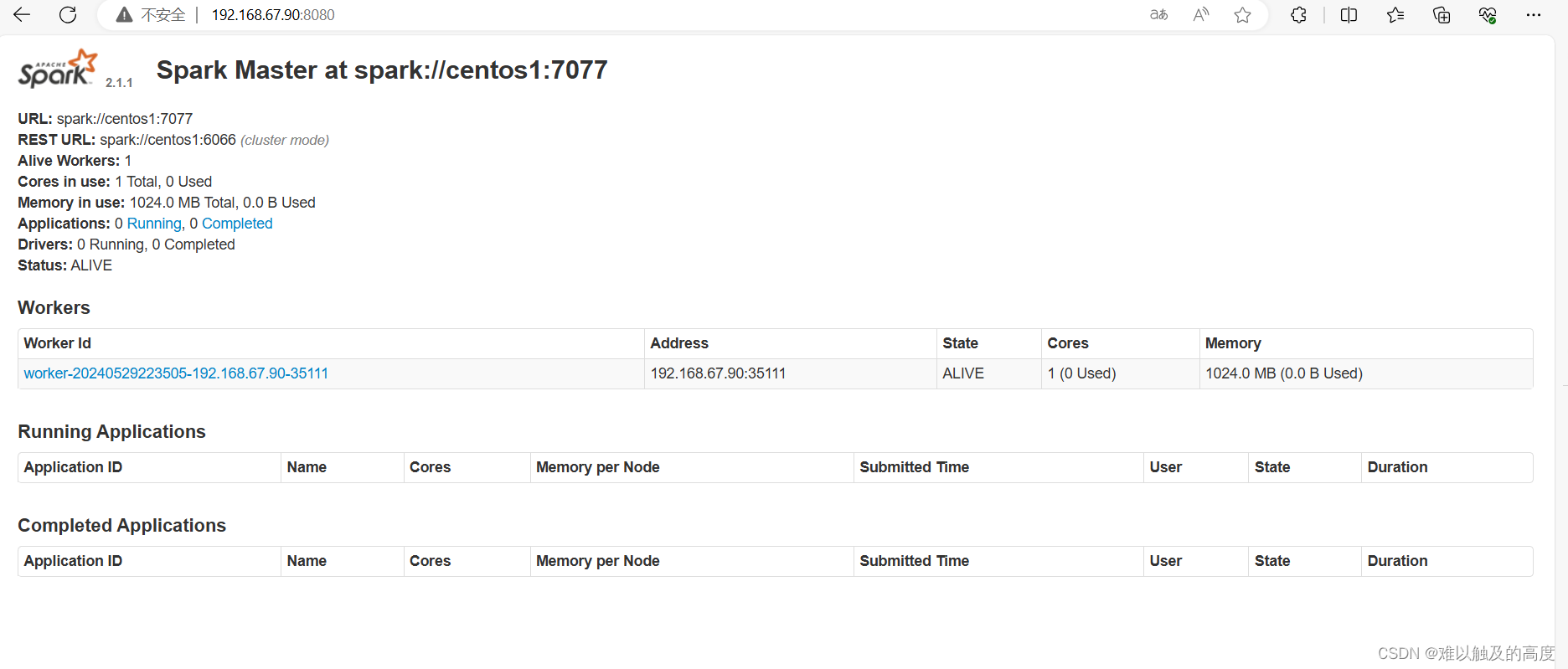
2)Spark界面
192.168.67.90:8080
6.第一个Spark程序
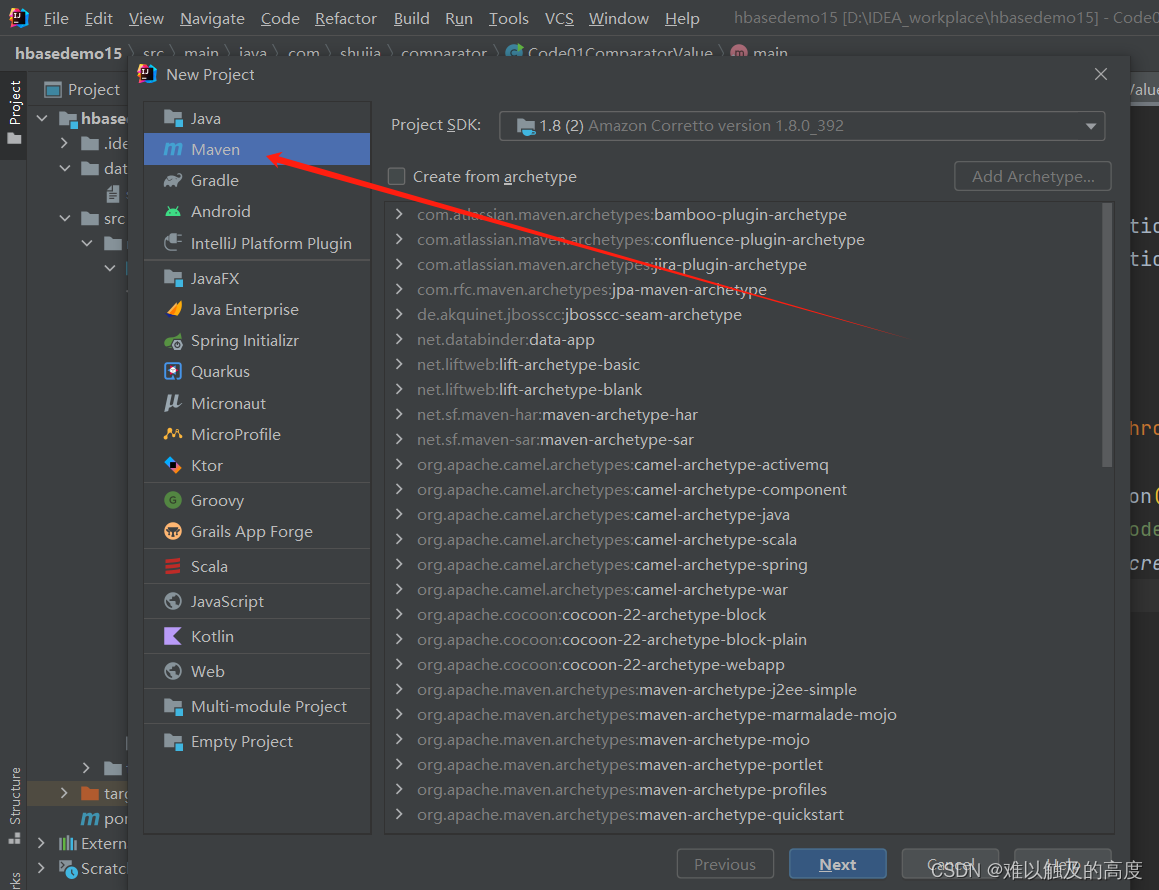
1)准备
maven:下载jar包的 根据groupId artifactId version就可以确定一个工程
首先 我们创建一个maven项目
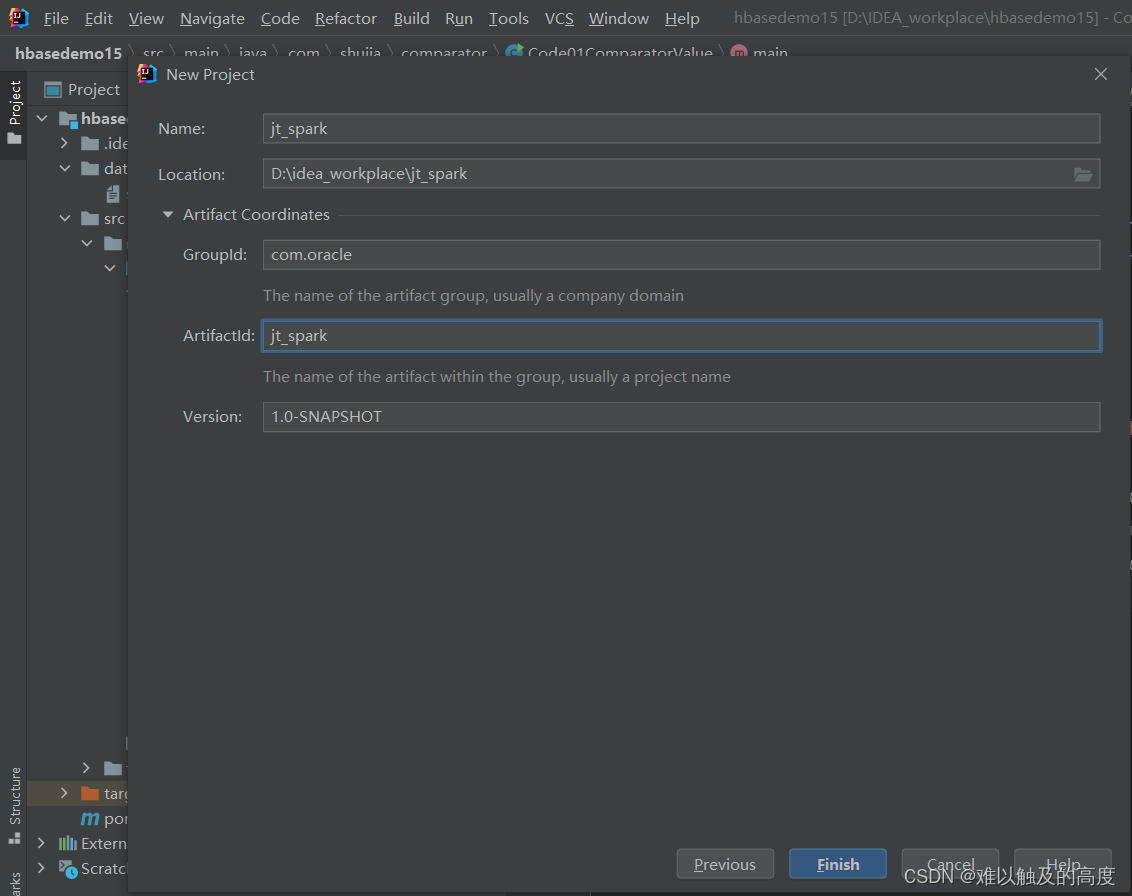
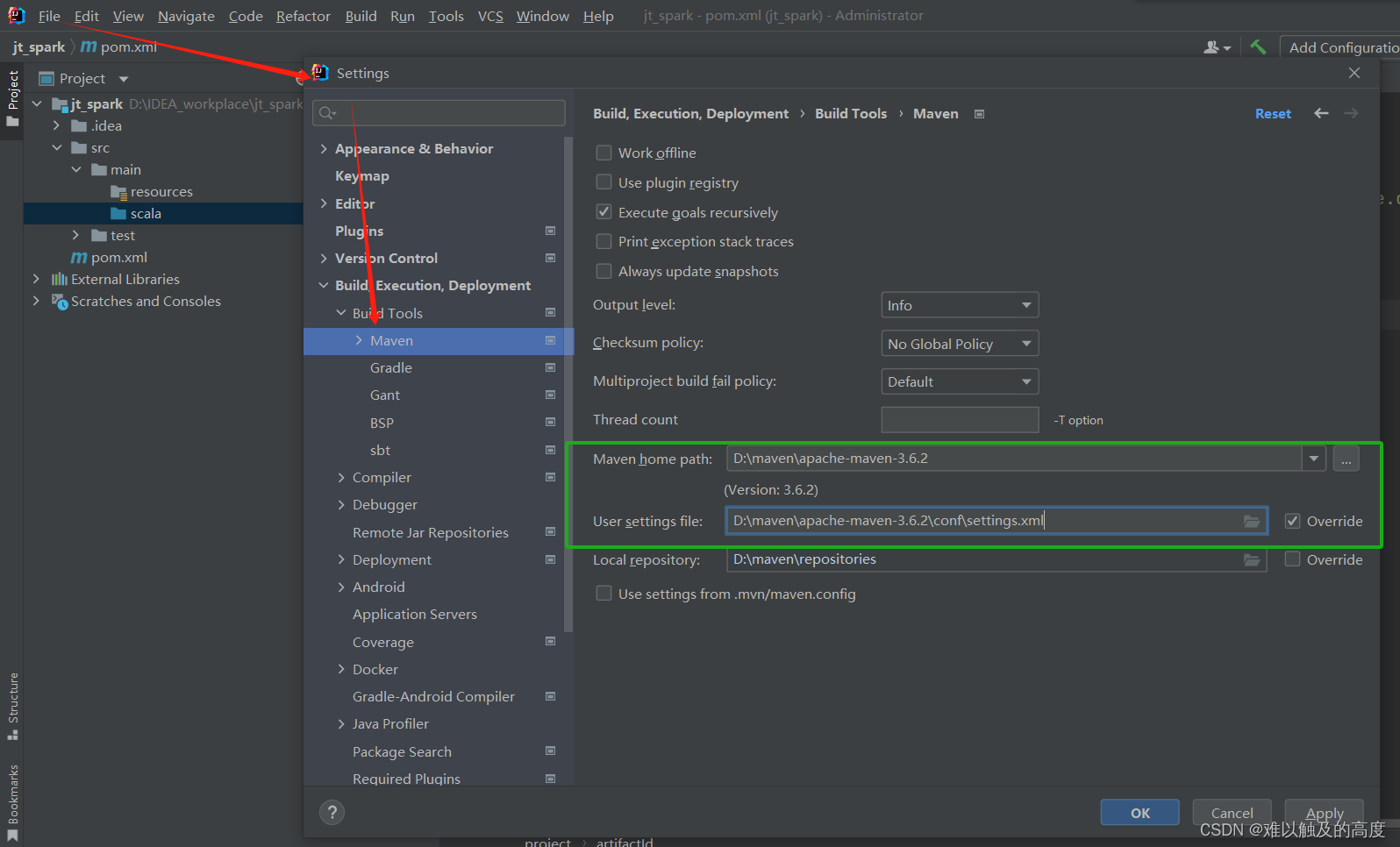
然后 我们配置一下maven 让我们的IDEA知道它的存在
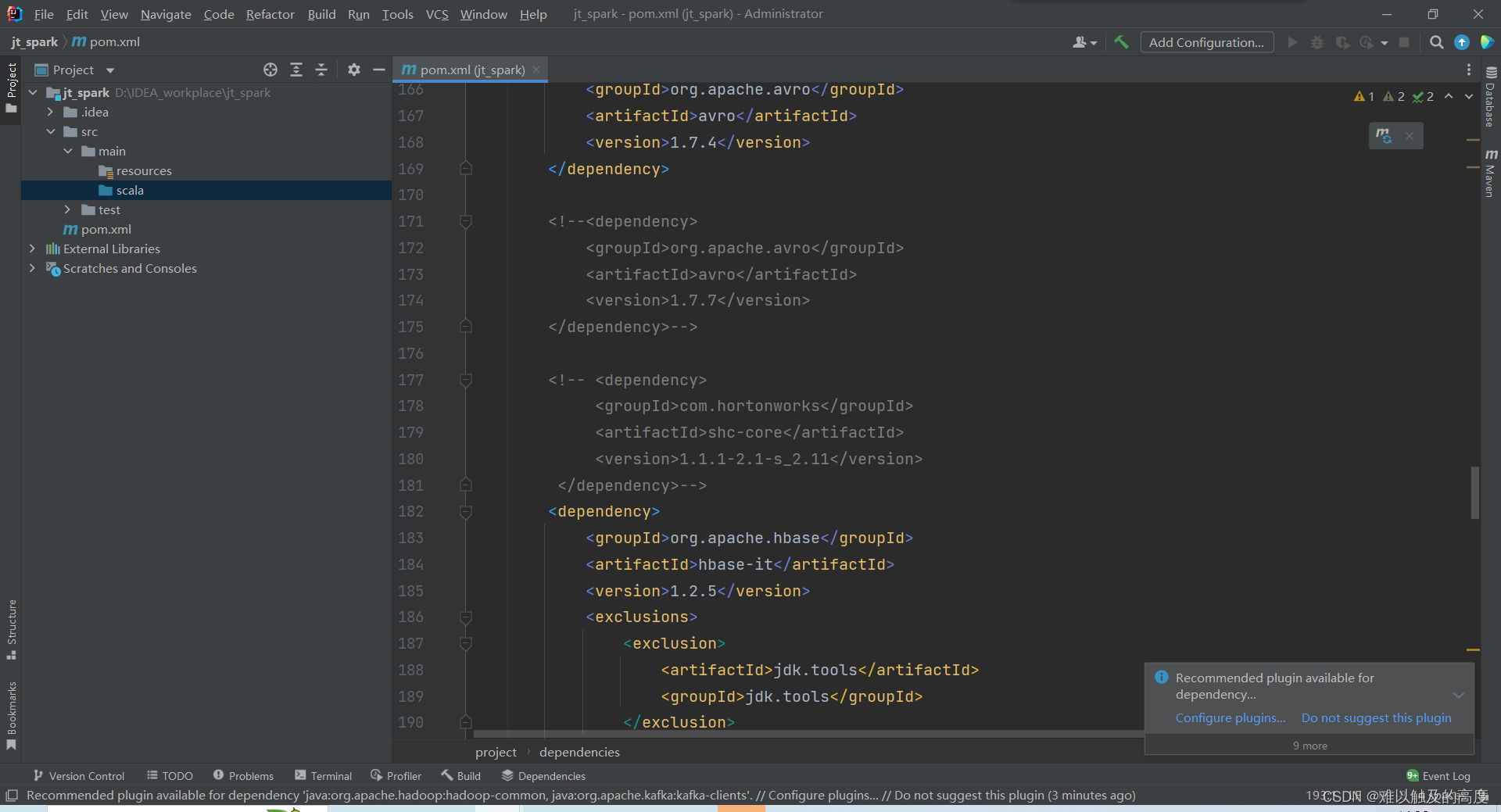
修改pom文件 将依赖复制进去 刷新一下
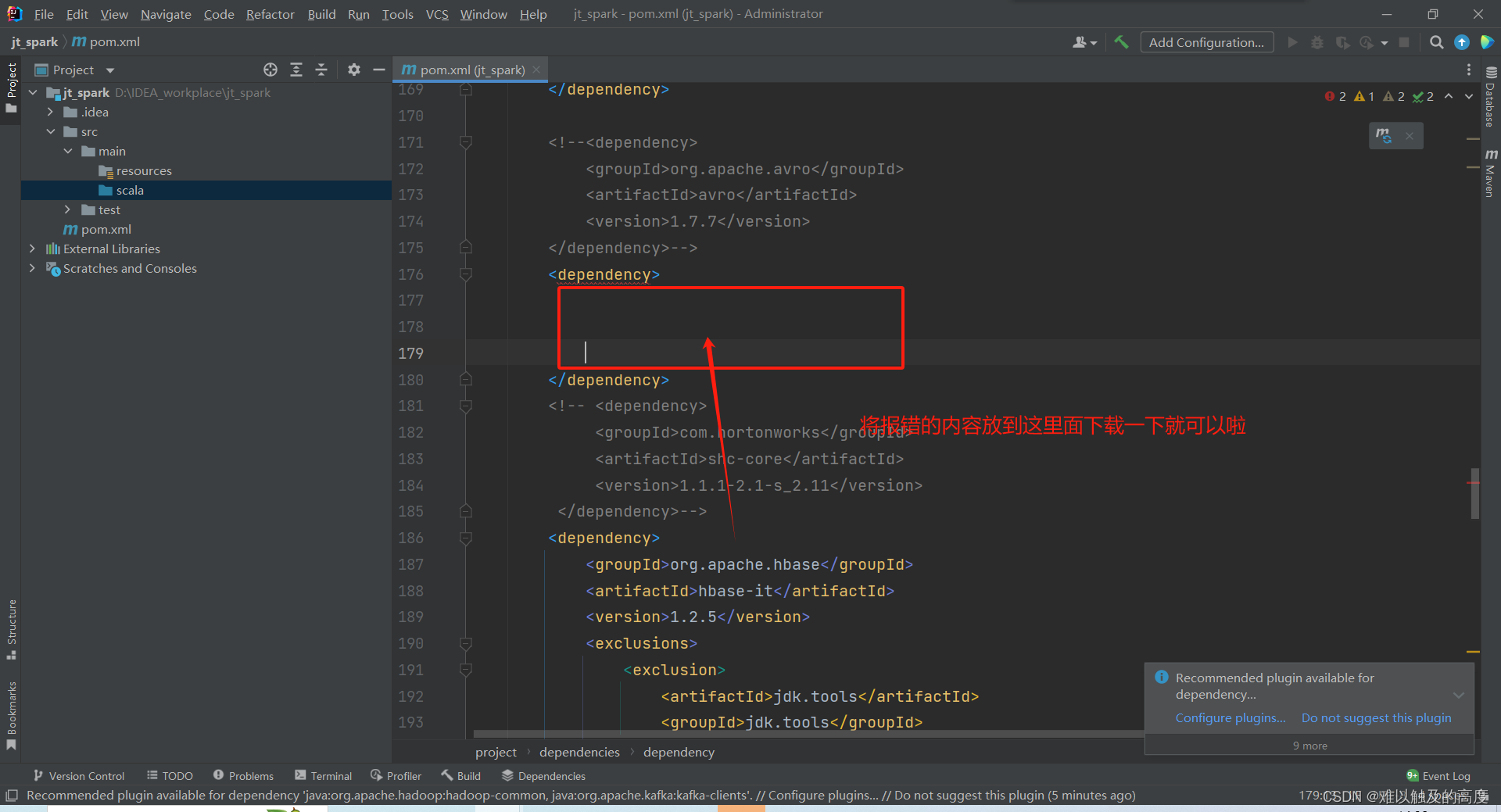
注意:我们在重新加载依赖的时候可能部分依赖会出现错误 那么 我们可以去下载一下 就可以解决这个问题了
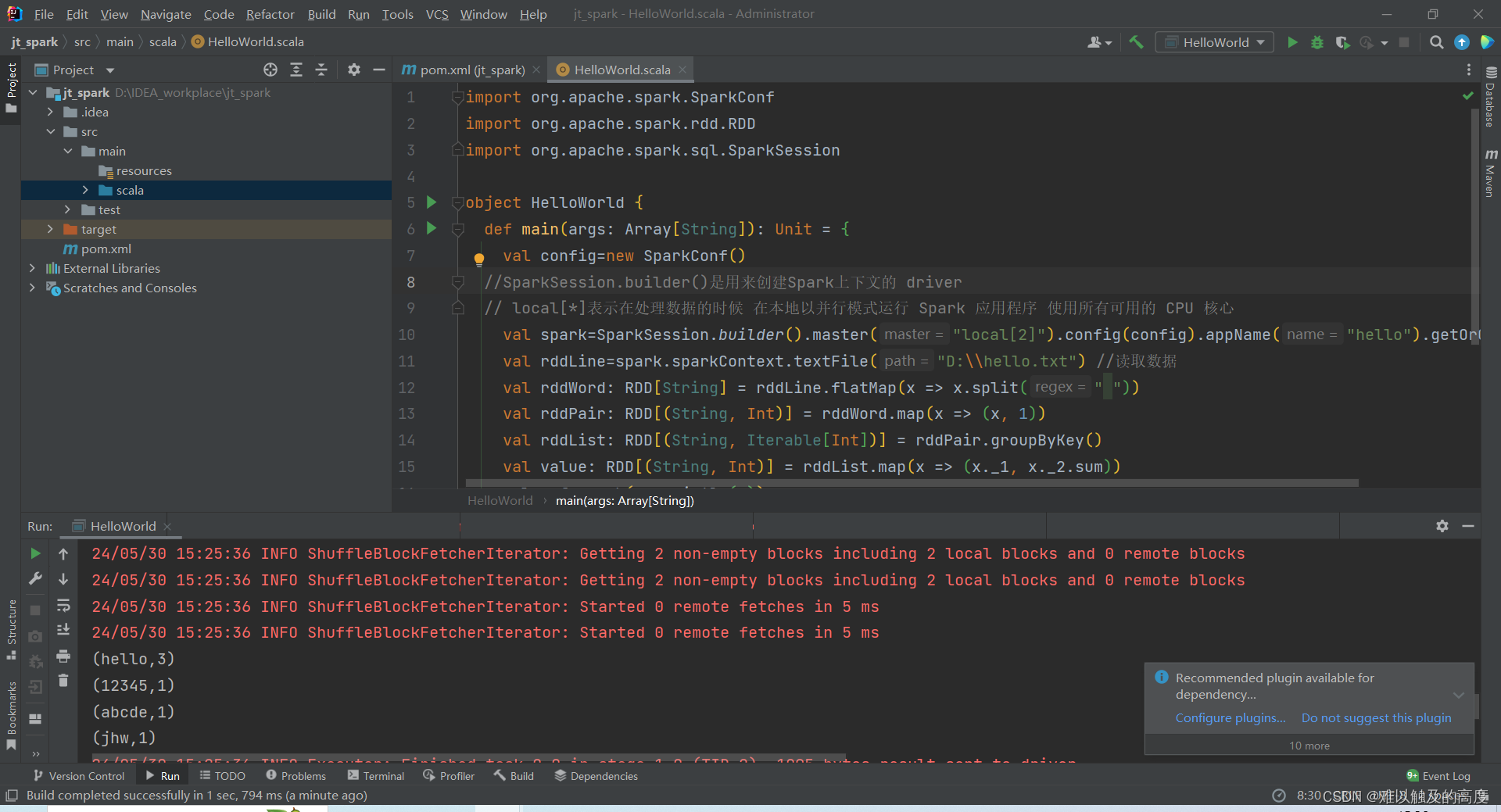
2)第一个程序
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object HelloWorld {
def main(args: Array[String]): Unit = {
val config=new SparkConf()
//SparkSession.builder()是用来创建Spark上下文的 driver
// local[*]表示在处理数据的时候 在本地以并行模式运行 Spark 应用程序 使用所有可用的 CPU 核心
val spark=SparkSession.builder().master("local[*]").config(config).appName("hello").getOrCreate()
val rddLine=spark.sparkContext.textFile("D:\\hello.txt") //读取数据
val rddWord: RDD[String] = rddLine.flatMap(x => x.split(" "))
val rddPair: RDD[(String, Int)] = rddWord.map(x => (x, 1))
val value = rddPair.reduceByKey((x, y) => x + y) //优化
// val rddList: RDD[(String, Iterable[Int])] = rddPair.groupByKey()
// val value: RDD[(String, Int)] = rddList.map(x => (x._1, x._2.sum))
value.foreach(x=>println(x))
}
}
3)练习
求每个用户的总金额
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object SalSum {
def main(args: Array[String]): Unit = {
val config=new SparkConf()
val spark=SparkSession.builder().master("local[*]").config(config).appName("salSum").getOrCreate()
val rddLine: RDD[String] = spark.sparkContext.textFile("D:\\sal.txt")
val rddWord: RDD[(String, Int)] = rddLine.map(x => {
val ord = x.split(",")
(ord(0), ord(2).toInt) //类型转换
})
val value = rddWord.reduceByKey((x, y) => x + y)
value.foreach(x=>println(x))
}
}
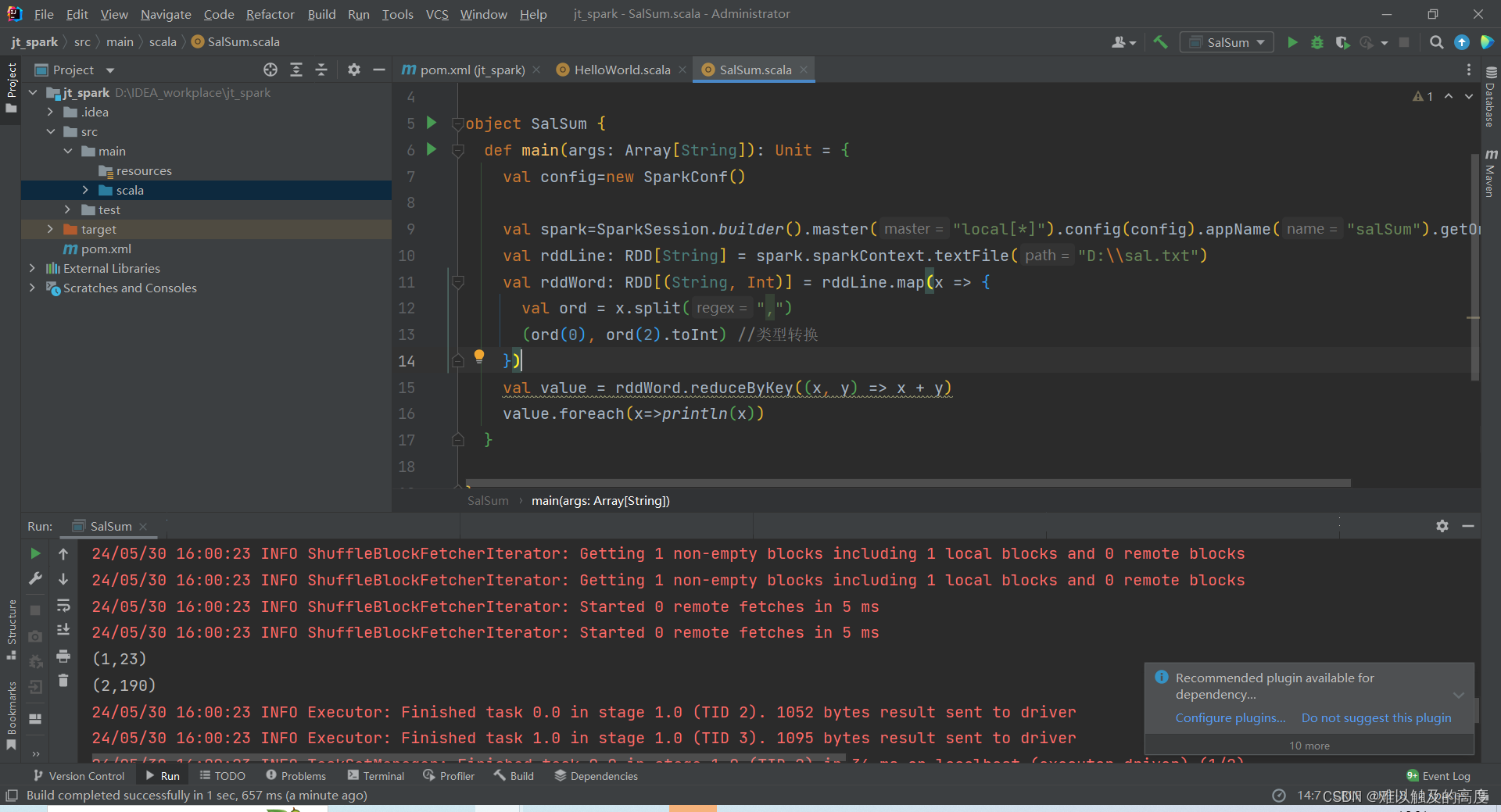
注意:数据类型的转换
7.打包到集群上运行
首先 我们点击Build 并打包一下
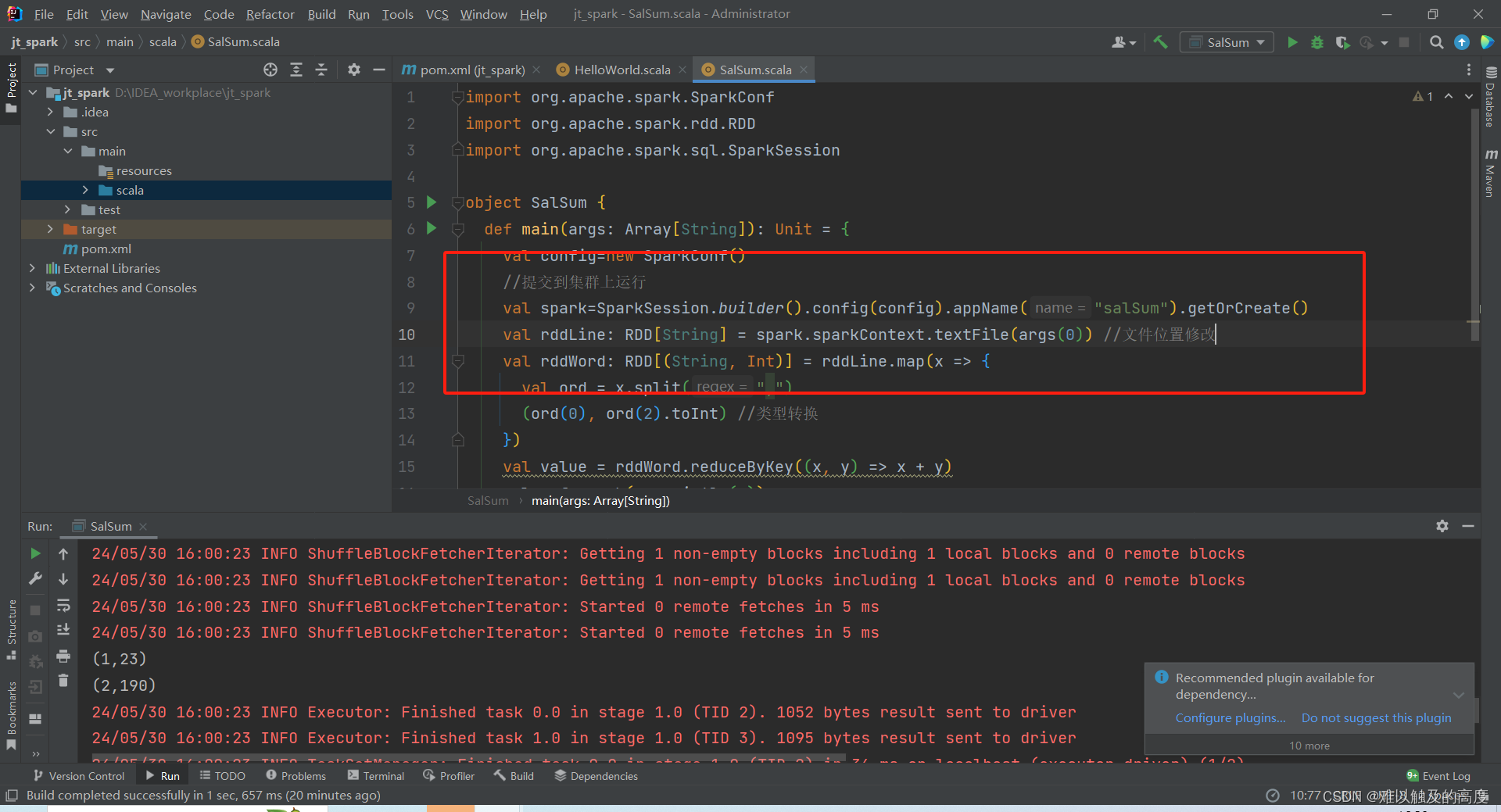
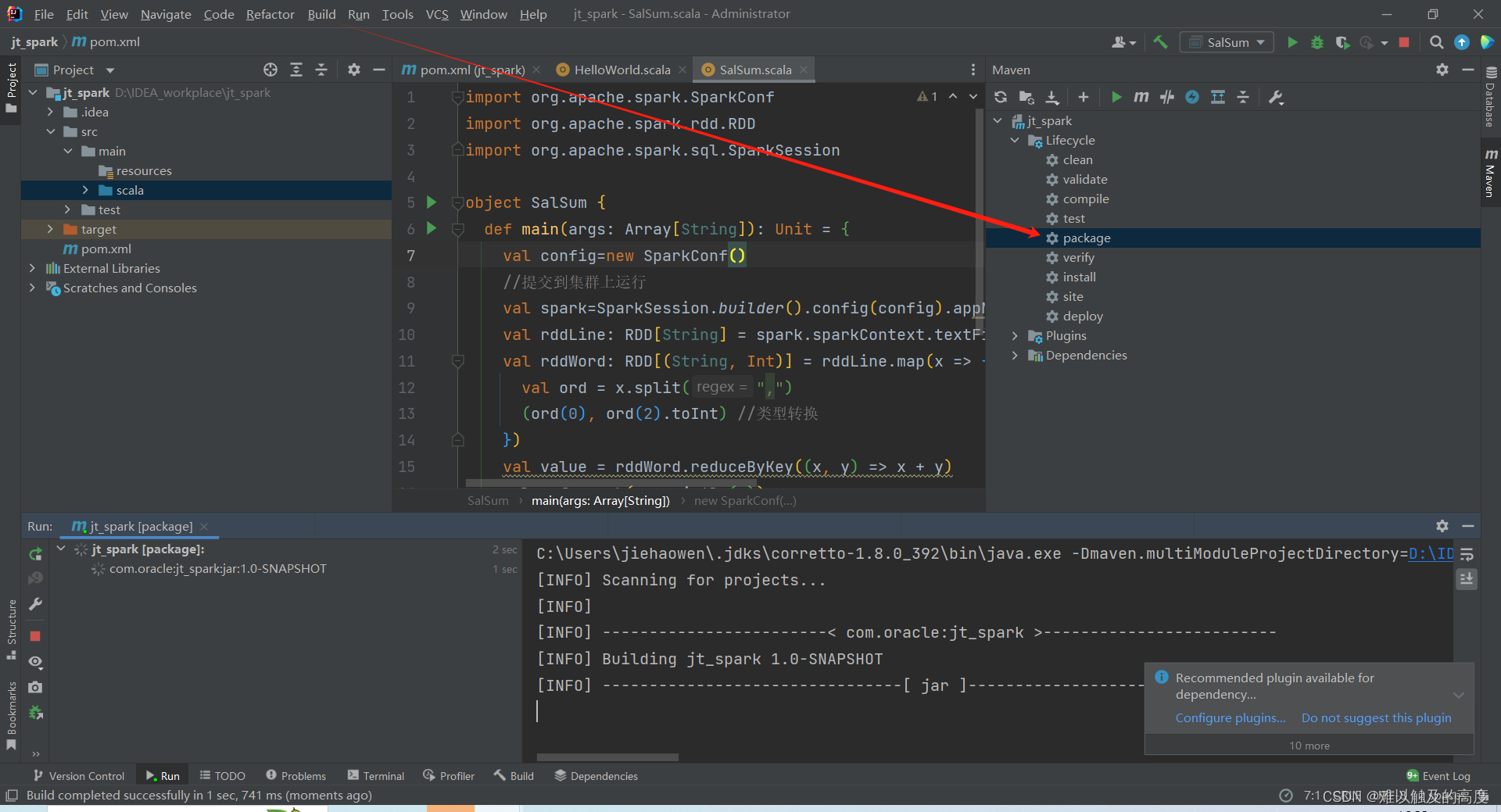
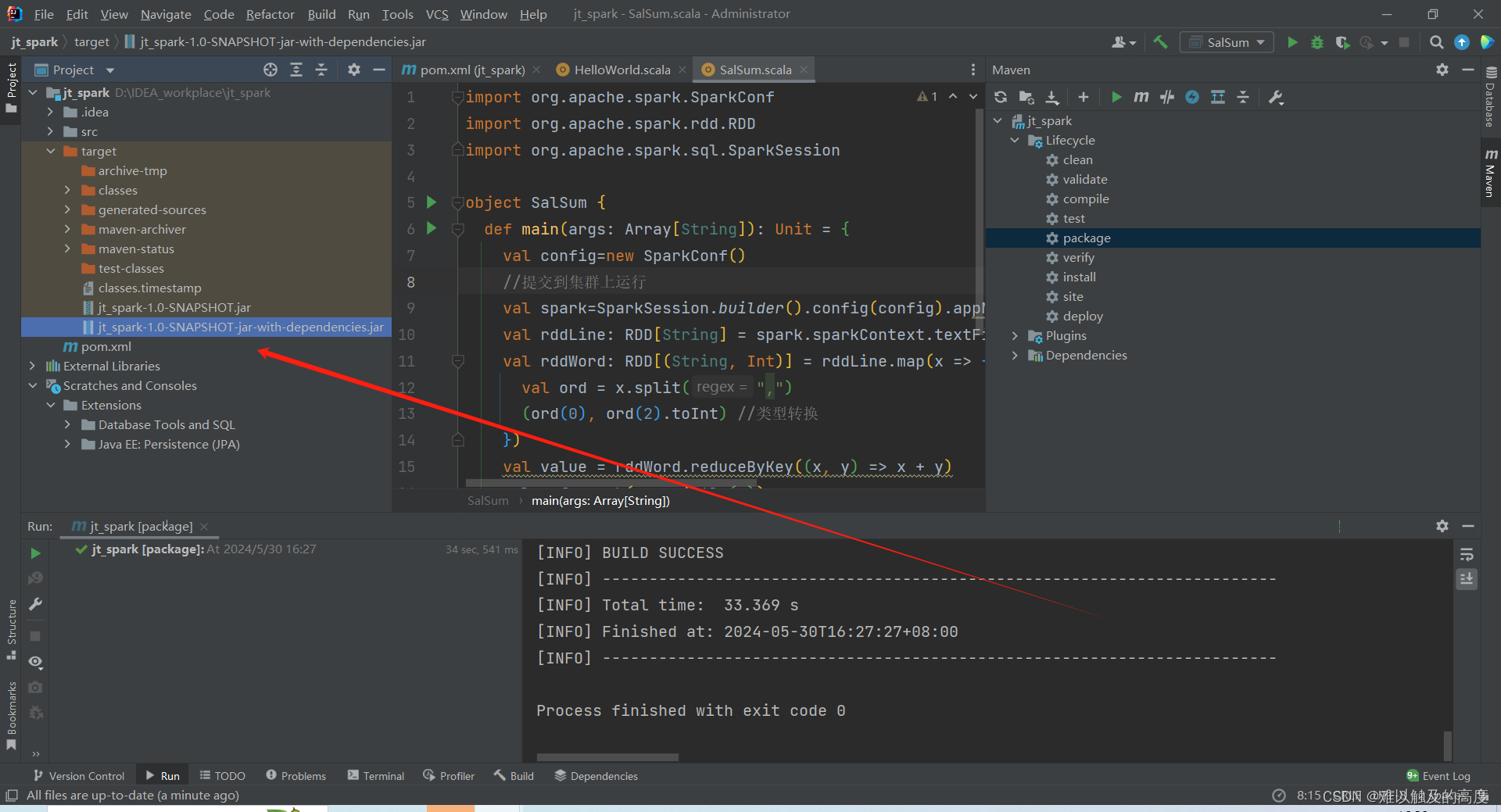
然后 我们把打好的jar包添加到/root/目录下 输入代码 创建一个文本 输入带豆点的文本内容
spark-submit --class SalSum --master spark://centos1:7077 --executor-memory 500M --total-executor-cores 2 jt_spark-1.0-SNAPSHOT-jar-with-dependencies.jar /root/words.txt

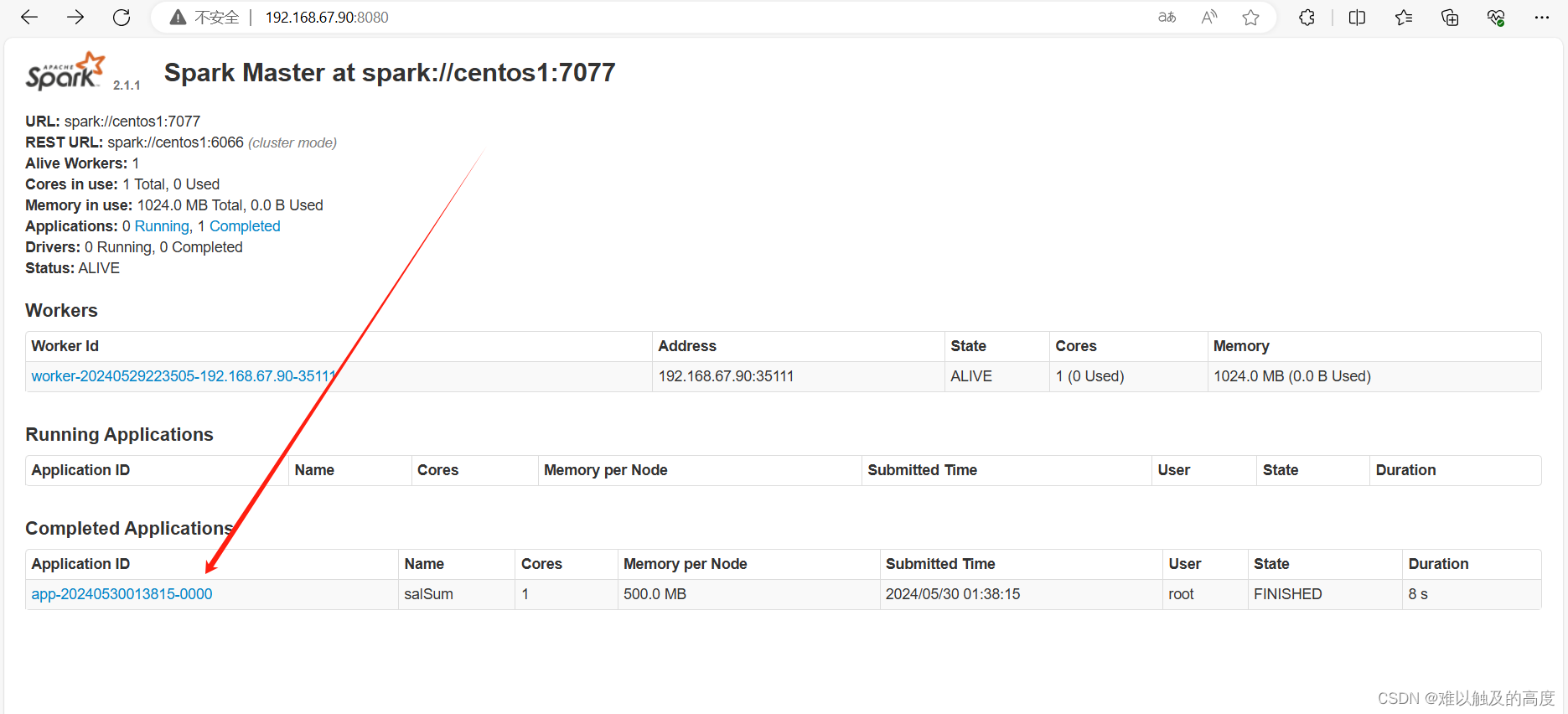
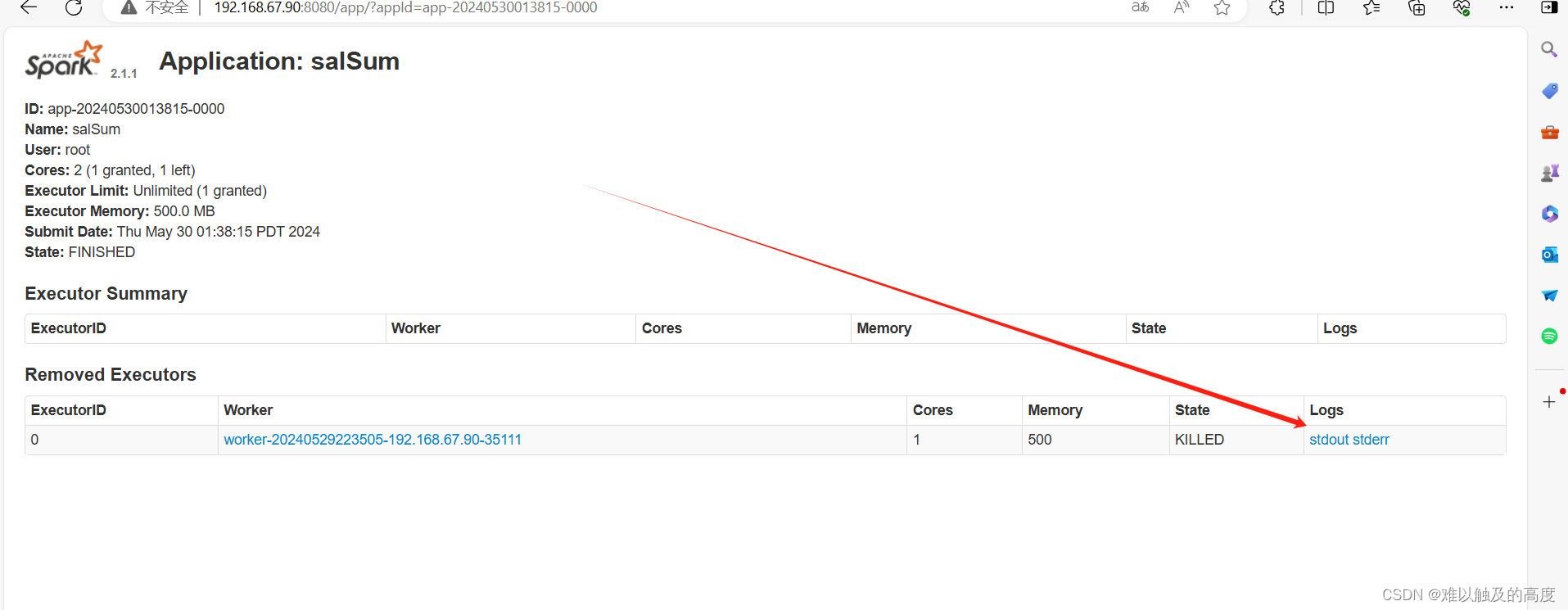
可以看到结果
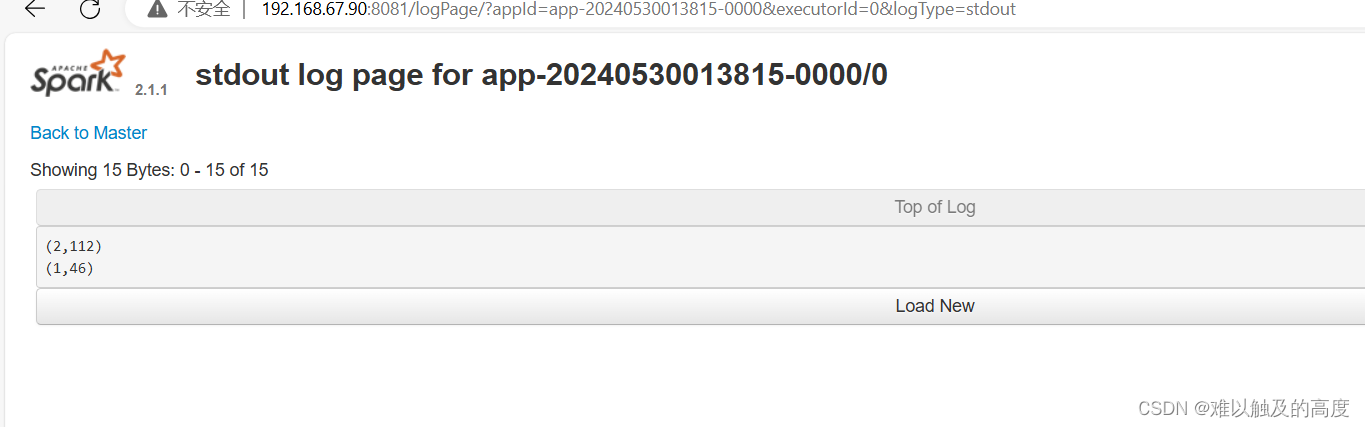















 1646
1646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









