






LinkedList简介
ArrayList和LinkedList都实现Collection接口,区别在于ArrayList基于数组实现,而LinkedList基于链表实现,由于数组是由连续的存储空间组成,其注定了ArrayList在查找方面的优势,但在执行插入删除等操作时,插入点/删除点之后的元素需要依次位移来填补空缺,其性能必将受到一定的影响,而链表这种数据结构正好解决了这个问题,在LinkedList中,使用大量的Node节点来存储数据,每个节点中item用于存储内容,next用于记录下一个节点,prev则用于记录上一个节点,从而以“链”的方式来存储数据,在执行插入等操作时,只需修改对应节点的指向即可,大大减少内存消耗提升了性能,接下来让我们来具体了解一下LinkedList的实现过程。
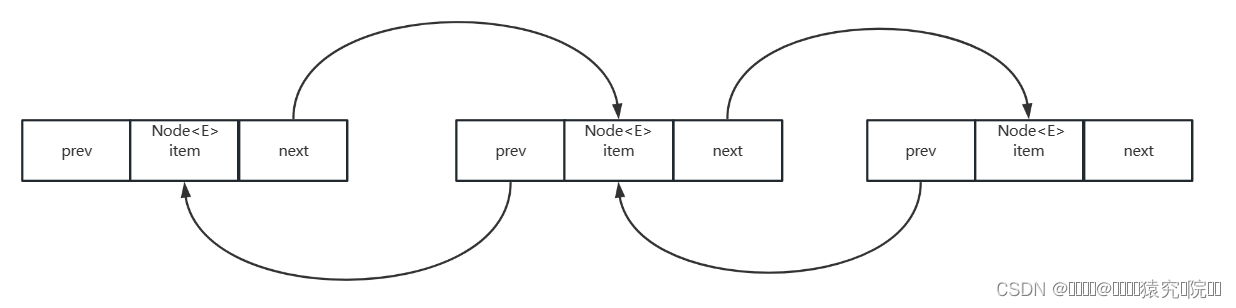
一 、LinkedList的整体结构
LinkedList由一个记录LinkedList容量的int类型的全局变量size,一个Node类型记录头节点first和一个Node类型记录尾节点的last组成。
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
其中Node为一个静态内部类,如代码所示,它由item记录节点数据,由prev记录上一节点 ,next记录下一节点,从而形成链式结构,使春初的数据有序化。
二、LinkedList的构造方法
LinkedList只有两个构造方法,区别于ArrayList,由于LinkedList基于链表实现,不同于ArrayList基于数组实现,数组在被创建时容量是固定的,当所需容量超过当前容量需要进行扩容操作,而链表则不需要关心容量问题。故链表没有指定初始化容量的构造方法。
(1)无参构造
public LinkedList() {
}不同于ArrayList,ArrayList由于基于数组实现,在无参构造中需要对elementData数组进行初始化操作,而在LinkedList中则无需初始化工作。
(2)传入一个Collection实现类的构造方法
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}其调用了自己的无参构造,再将传入的实现类调用addAll方法将其存入链表。
三、LinkedList的增删改查功能实现
(1)LinkedList实现插入元素
1、add方法
public boolean add(E e) {
linkLast(e);
return true;
}
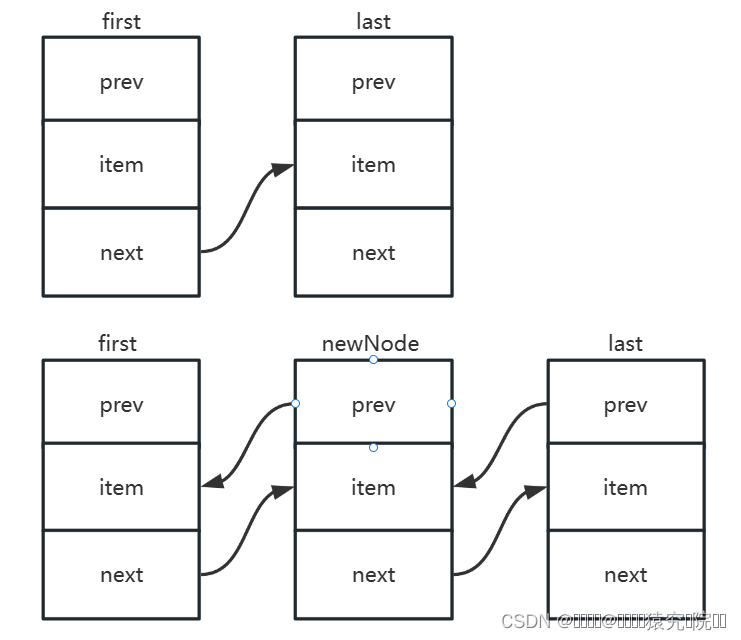
由源码我们可知add方法调用了linkLast方法,实现了元素从尾部插入,linkLast的实现如下图所示。
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}源码中先将原来的尾节点暂存在l中,定义newNode为一个prev为l,item为插入元素,next为空的新节点。由于采用的为尾插法,所以此时全局变量所记录的last指向newNode,对之前保存的l进行判断,如果l=null则链表中还未存入元素,故使first指向定义的新节点newNode,若不为空,则链表中已经存在元素,则使原尾节点的next指向新的尾节点newNode。
2、 addAll方法
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
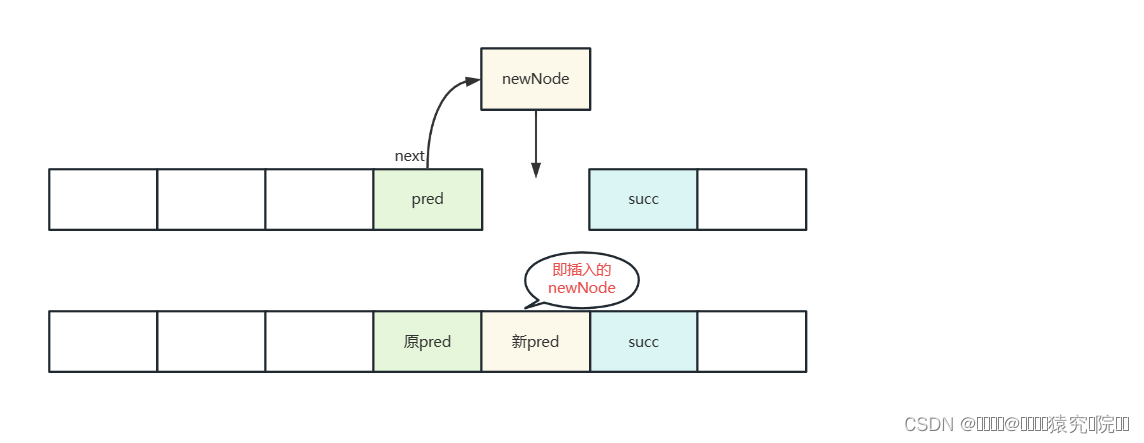
我们根据源码逐步解析,checkPositionIndex的内部实现原理很简单,就是对插入的下标index进行判断,如果index<0或index>size则抛出IndexOutOfBoundsException异常,我们就不对其进行详细的代码展示了。可以看到,方法内部首先将传入的Collection实现类转化为一个Object数组,如果这个数组为空则证明传入的实现类为一个空集合,直接返回false。接下来对index进行判断,若index等于size则证明是将元素集合插入链表尾部,不等则是插入链表中间。定义pred,succ分别来记录两个关键节点——pred记录插入区间的前一个节点,succ记录插入区间的后一个节点,如图所示:
然后对插入元素进行遍历, 记录当前元素newNode,如果pred=null则链表为空,使头节点指向newNode,如果不为空,则使记录的pred的next指向newNode,当前的newNode成为新的pred
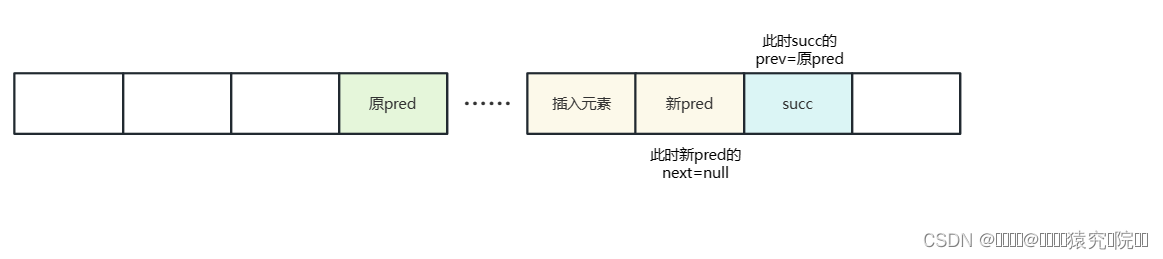
经过遍历每个元素重复此过程则完成插入,但如果插入元素组是在链表中间插入,即succ不等于空,还需改变pred的next指向和succ指向。将pred.next=succ,succ.prev=pred。至此我们就完成了集合按指定下标的插入操作。
(2)LinkedList实现删除元素
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}指定元素删除我们通过源码可知指定元素删除我们需要先传入一个元素对象,然后for循环通过寻找下一个的方式那item进行对比,找到元素调用unlink方法进行删除,(由源码可以看出LinkedList可以存储null)让我们来详细了解一下unlink方法到底是如何实现的。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
该方法需要传入一个Node对象, 先对该对象的next,prev,item分别进行记录,如果prev为null,则证明该Node对象为头节点,只需要使first指向其next即将first指向传入节点的下一个节点即可。如果prev不为null则只需要让他的上一个节点的next指向他的下一个节点即可,如果next为null则传入节点为尾节点,只需让last指向传入节点的上一个节点即可,如果next不为空,则需要将传入节点的后一个节点的prev指向传入节点的前一个。最后抹除传入节点的item数据,使链表容量减一,最终完成了元素的删除。


(3)LinkedList实现查询和更改元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}查询操作首先要对传入的下标进行一个范围是否有效的检查,此方法与我们上文介绍的checkPositionIndex方法功能实现类似。确定index为有效下标值后调用node对其进行查找,在node方法中也是使用链表的next和prev对其进行逐一查找,在node方法中运用了折半查找的思想,提高了查找的效率。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
更改和查询在上述篇幅均有一定介绍,其内容与上述大同小异,就不在此赘述。
总结
LinkeList在集合框架中扮演着多种角色,它既是List的实现类也是Deque的实现类,关于它源码的学习还有很多巧妙的知识,但由于篇幅有限,今天我们就先介绍到这里。在此我们总结一下今天所学的知。:
我们了解了LinkedList是由链表实现的集合框架,它内部维护了Node类型的first和last用于记录链表的头节点和尾节点,使用静态内部类Node来实现链表功能,其中prev记录前一节点,next记录后一节点,item用于保存数据,在对LinkedList存储的数据进行操作时,只需改变Node节点的prev、next的指向即可,由此提升了对数据写的性能。

















 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











