






1、内存管理概述
文件在FreeRTOS/source/portable/MemMang下,它也是放在portable目录下,表示你可以提供自己的函数,源码中默认提供了五个文件,对应内存管理的五种方法
| 文件 | 优点 | 缺点 |
| heap_1.c | 分配简单,时间确定 | 只分配,不回收 |
| heap_2.c | 动态分配,最佳匹配 | 碎片化,时间不定 |
| heap_3.c | 调用标准库函数 | 速度慢,时间不定 |
| heap_4.c | 相邻空间内存可合并 | 可解决碎片化问题,时间不定 |
| heap_5.c | 在heap_4的基础上支持分隔的内存块 | 包含4缺点的基础上代码量增大 |
对于heap_3他是调用了C库的malloc和free等、对于heap_4他是基于heap_2的基础上实现的
2、堆的概念
很多人把堆栈相提并论,其实堆栈是完全没有联系,栈的作用我们前面已经讲过,那么堆的作用是什么,堆就是一块或者多块内存,我们可以从中申请一小块内存来使用,使用后释放掉这一小块内存,简单的说堆就是一些空闲内存,我们可以
1、使用malloc函数从中申请,获取一小块内存
2、使用free函数释放这一小块内存
3、这些malloc和free函数就是用来管理这些内存的
3、malloc、free函数可以有其他名称,例如FreeRTOS中的pvProtMalloc和vPortFree
3、堆的内存来源
一开始,堆是一堆空闲内存,怎么得到这些空闲内存,在启动文件中定义了申请一块堆的大小,设定为可读可写,使用space命令就可以申请一块堆来使用

而在FreeRTOS中,他定义了一个全局数组,定义了一个这么大的数组,那他的内存空间肯定也是这个数组定义的大小,刚开始这个数组没人使用,就可以把他当成一个堆来使用

4、heap_1代码分析
对于 heap_1.c 他只实现了malloc函数,并没有实现free函数,在代码中就是上面提到的那种方式来定义堆的大小,宏定义大小为17k,当然我们也可以自己调整他的大小
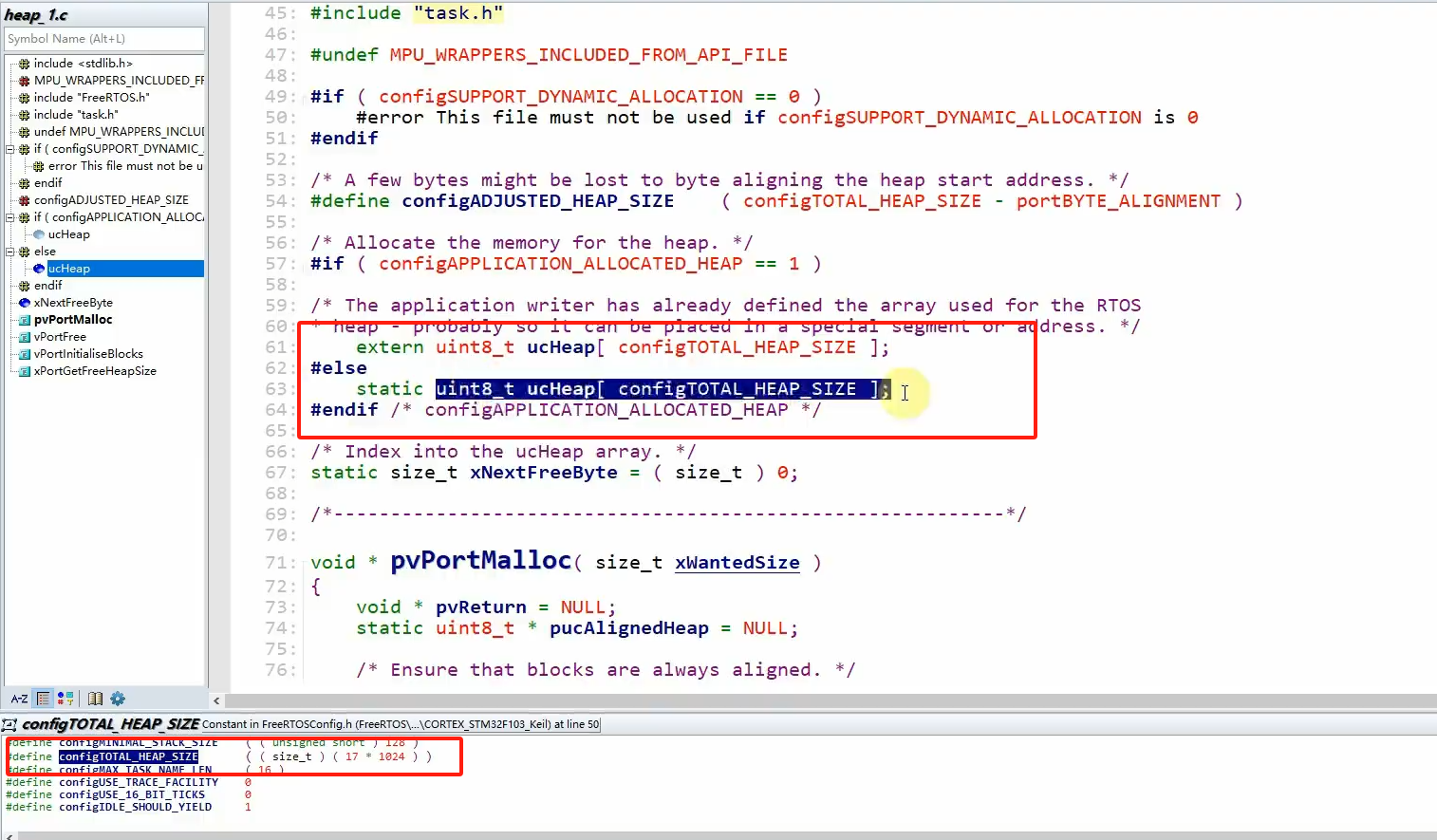
最开始是起始状态,里头存在两个变量,一个是起始位置变量,一个是偏移地址变量,起始位置指向的地址加上偏移变量的地址就是这块内存的首地址,分配内存的函数传入的参数就是本次需要分配内存的大小xWantedSize,下次需要分配内存的首地址就变成了偏移值(已经分配的内存大小)+起始位置地址,这个起始位置变量需要进行内存对齐,他不一定指向数组的首地址,需要程序算法来修正
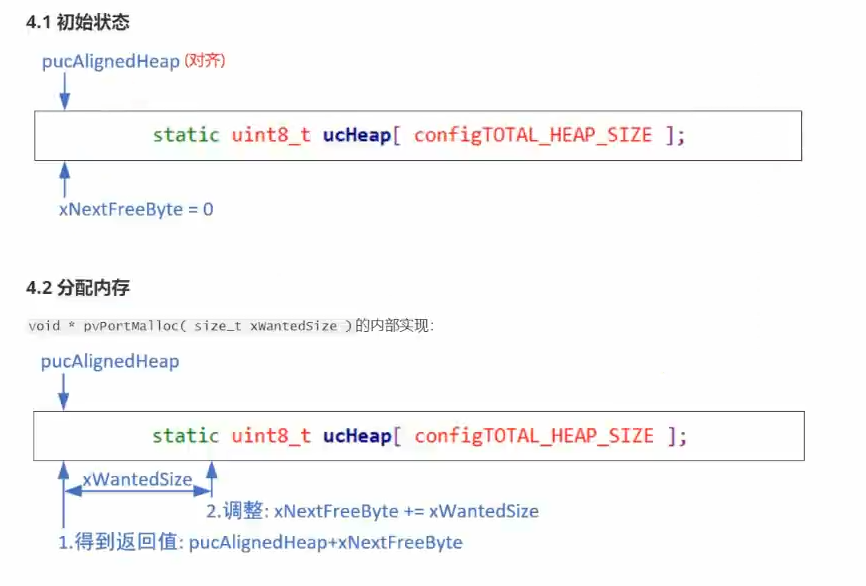
接下来我们看看具体的代码实现,首先根据流程来看上来肯定是需要初始化一下,也就是我们前面提到的内存需要对齐,为什么内存需要对齐呢,因为数组首地址是随机的,万一指向一个0x20000001这样的地址,我需要分配个int类型的指针,多出来一个字节有的芯片就接收不了这样的基地址他就会报错,所以需要往后查找到符合分配内存的地址用来对齐,在代码的开头定义了这个起始位置的变量,他是一个空指针,需要进初始化算法计算他需要指向什么样的内存
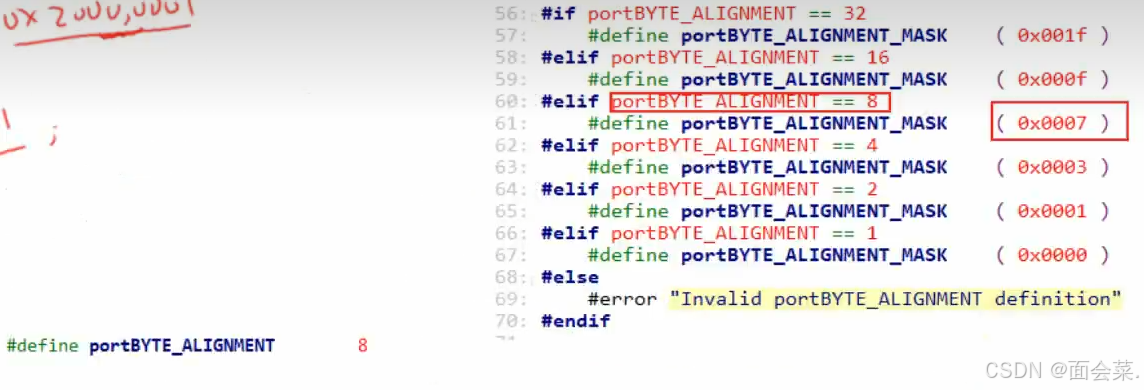
下面是具体的算法以及宏定义取的数值,下面这个算法怎么算的呢,假如说我数组起始地址是0x20000001,那么取数组的第八位地址就是0x20000009,与上取反的宏定义数值0x0007取反之后就是0x0b11110000,最后得出的结果就是0x20000008就得到了这个八字节对齐的地址,具体的算法可以自己拆解出来看看,主要是知道这个堆分配需要内存对齐即可

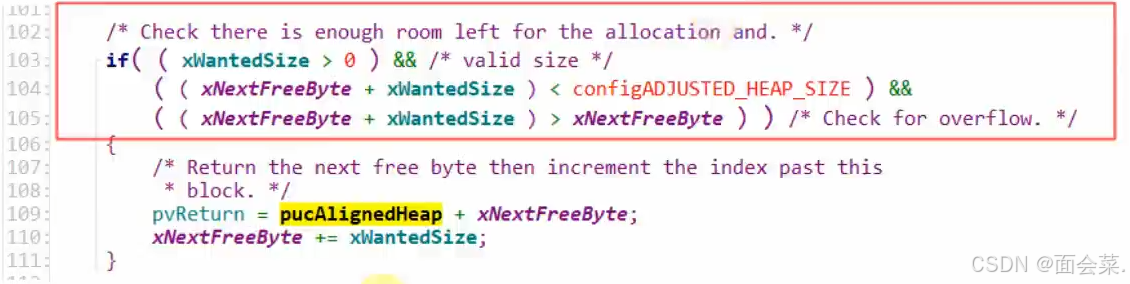
初始化之后就需要分配堆的空间了,我们接下来往下看代码,上面这些条件判断我们先不管,他主要是判断你分配的空间是否太大了,如果太大就会返回失败,他这个返回值pvReturn就是我们上面流程图中提到的分配地址,由对齐地址+偏移值得到,下次分配我就知道从哪开始分配了,然后我们的偏移值就必须累加我们已经分配的字节大小,在分配堆空间的时候,RTOS开启了禁止任务调度,将所有任务挂起了,目的就是为了防止我正在分配堆,还没有分配完,又有人调用我这个函数从而打乱堆的分配
为啥说这个heap_1他有碎片呢,假如说我分配80字节,那么正好对齐我直接八字节遍历就可以读取所有的信息,那么我分配100字节呢,八字节对齐我是分配96字节给他还是104字节给他,肯定是分配104字节,能把所有信息全部包含在内,那么我就多出4字节空余空间分配给他了,这部分内存只能被浪费掉,这就是以空间换时间,如果不想产生碎片那么一个字节一个字节读效率会非常差,到这基本上heap_1的主旨思想都分享完了,接下来我们看看heap_2和1有什么不同
5、heap_2代码分析
heap_2和heap_1最大的区别就是heap_2实现了free回收内存的函数,为什么heap_1不行呢,因为他无法记录我每次分配的堆空间有多大,例如说我分配100字节的内存,函数自动字节对齐给我多分配了四个字节,根本无法记录本次分配堆空间的大小,所以无法实现free函数
那么heap_2是如何实现记录堆的长度呢,他在heap_1的基础上,新增了一个头部储存信息的功能,头部是一个结构体,结构体组成一个链表来管理堆空间的大小,例如我要分配80字节的长度,其实分配的实际内存是80字节+一个头部,但是返回值返回的是头部结尾,也就是80字节开头的地方,最后我要释放内存只需要查看头部里的信息就知道需要释放多少的内存了
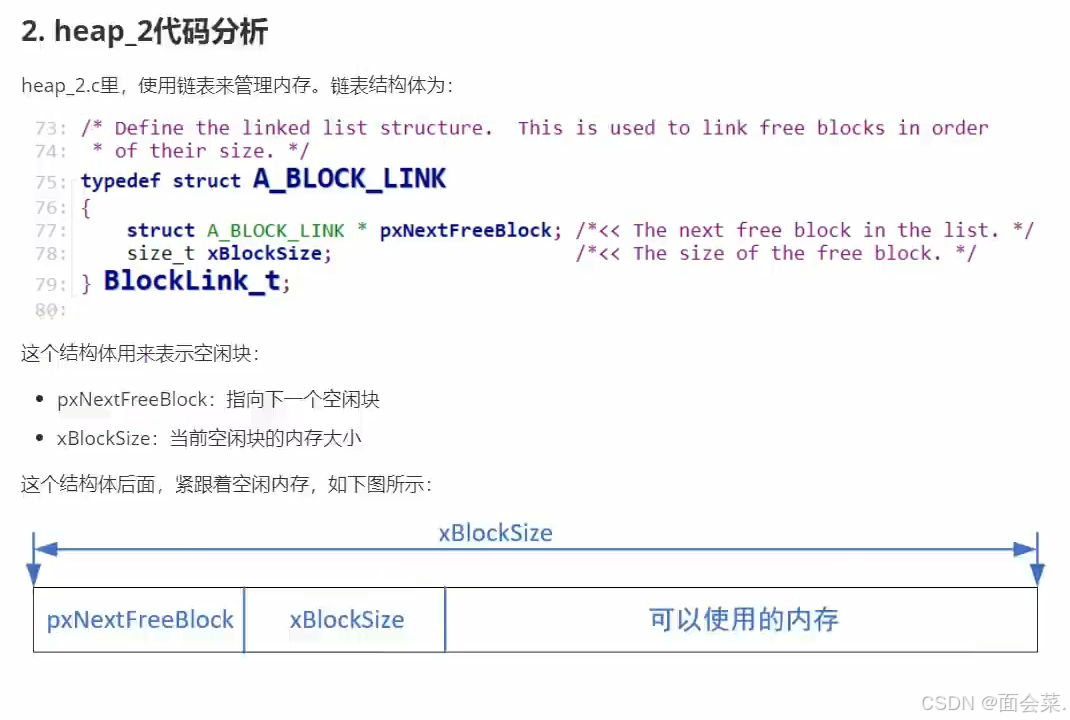
这个是一个单链表,链表头指向结构体的首地址,结构体里头的指针再指向下一个空闲的内存块,最后指向链表尾部,其中的xBlockSize是对应整个分配内存的字节大小,例如说我要用100字节,8字节对齐,那么就需要分配104个字节,加上头部的8字节就是112字节,存入xBlockSize里

那么他是怎么分配内存的呢,假如说我现在需要分配112字节的内存,我就通过遍历链表来查询是否有符合我要求大小的空闲内存块,如果我符合条件,我就把这个空闲的块从链表删除,这个空闲出来的块怎么处理呢,例如说我需要分配112,但是这个空闲的块有17k那么大,我根本用不了这么多,这个时候就需要拆分这个块
把这个空闲的块拆出来一个我需要的大小,这就是新的block1,此时里头的xBlockSize就等于我需要分配的大小,剩下的块将成为一个新的块block2,把这个新的block2放入链表中,等待新的内存申请
那我们分配讲完了,释放内存是怎么释放的呢,我们申请内存的时候会得到一个返回值,根据这个返回值我们往前移动八个字节就能找到结构体的头部地址,头部结构体存储着内存大小的信息,通过这个信息就可以释放掉我申请的这部分内存,然后我们把他插入链表中就可以继续遍历链表重复使用了,但是这时候又会产生碎片的问题,我当初链表中只有一块最大的内存,如今我链表中有一大一小两块内存了,他们无法合并成一大块内存了
对于heap_2,因为他的局限性,导致他的使用场景只能是频繁申请释放固定大小的内存的场景,对于heap_4把这个问题补全了
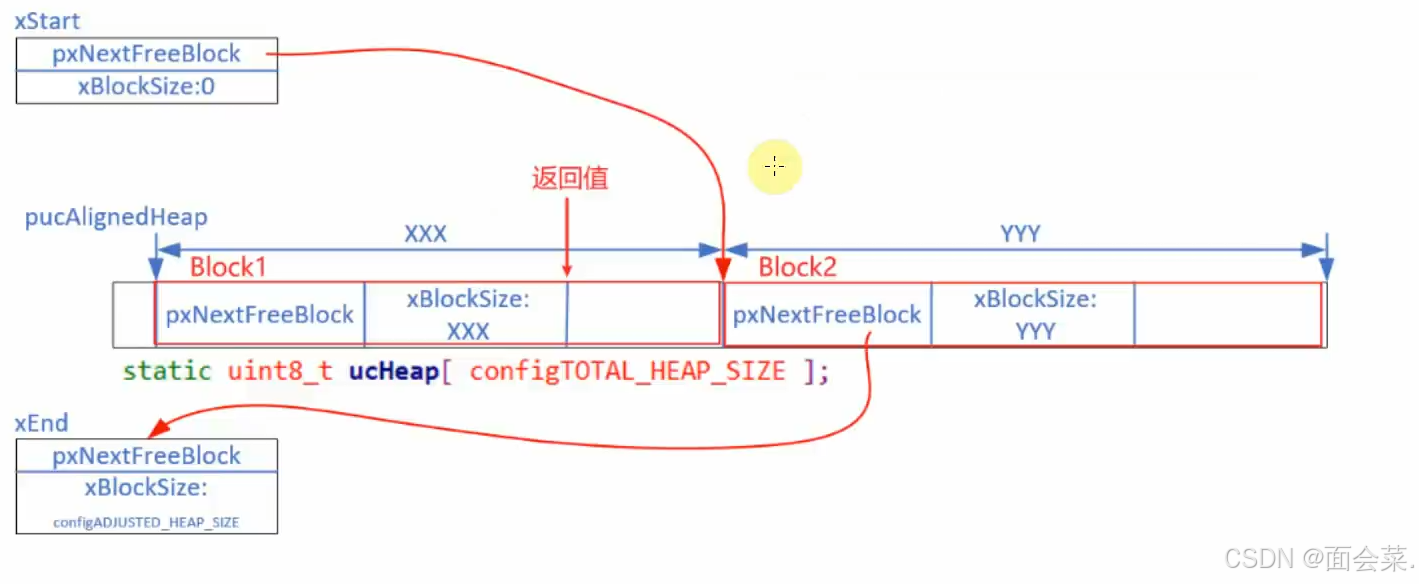
上面讲完原理了我们来看看代码,首先调用malloc函数的时候会暂停所有任务的调度,原因我已经讲过,接下来就是初始化整个堆,把整个数组初始化成一个block,然后把整个block放到一个链表中来,第一个调用这个函数的时候会初始化,然后进入条件判断来分配内存,一步一步分析,下面先看看初始化再看看内存怎么分配

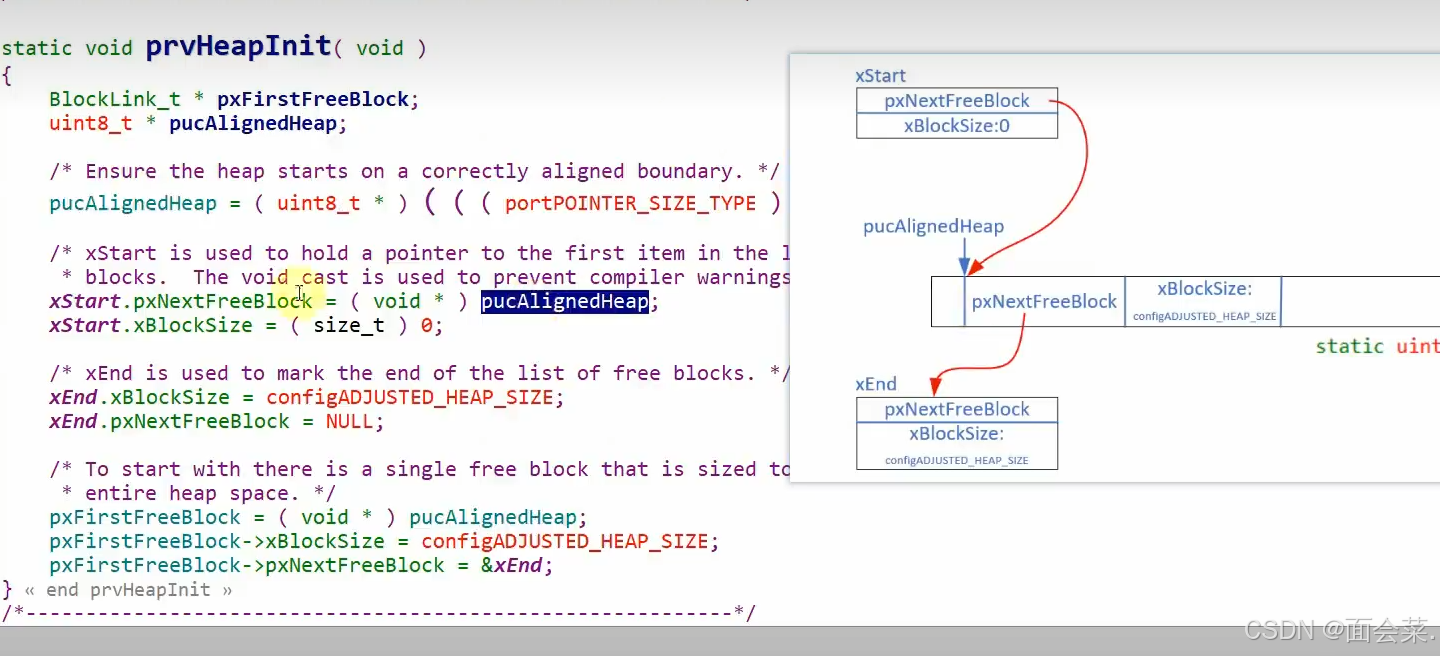
看看它这个链表初始化咋写的,先计算对齐字节,然后让链表头指向第一个block,字节数未分配就等于0,他这个链表尾的xBlockSize设置这么大是为了方便排序,保证他能始终处于最后一个,然后下面就是把第一个最大的空闲堆插入链表,初始化就结束了,初始化结束后会进行一些对齐字节和计算最终需要分配内存大小的操作,这里就不分析了
再往下我们初始化结束了,分配字节内存大小计算完成了,到了该分配堆空间的时候了,这是堆分配时候的源代码,去链表中遍历找出合适的空闲块,首先我们空闲内存块取了链表头的地址,准备遍历链表来查找符合我申请内存大小的块,在这个循环内去判断空闲块的大小是否符合我申请的条件,如果不符合就指向下一个空闲块,如果符合条件就把你删掉然后跳出,如果都不符合也跳出循环
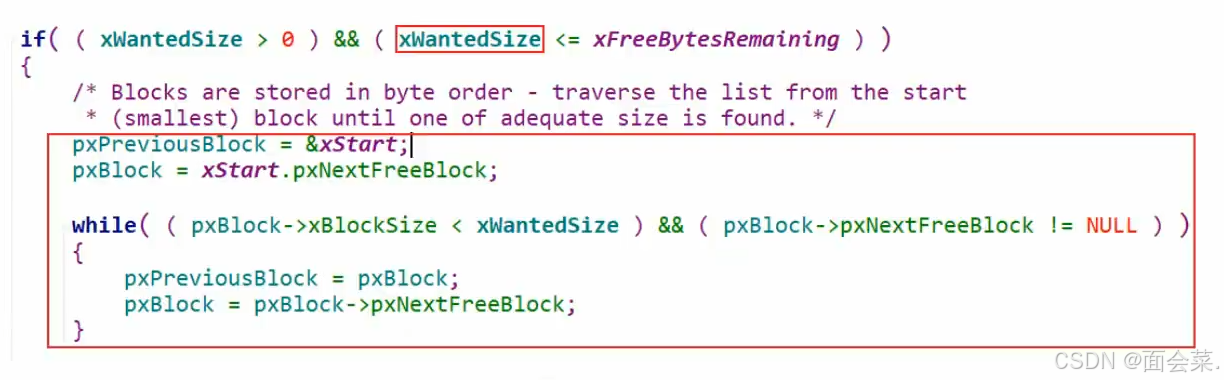
这个返回值就是我们得出来分配的块的内存大小,然后我们需要把这个块删除,就是让块的前一个指向后一个,最后我们还得判断一下我们使用的这个块是否需要分割一下

如果你找到的空闲块减去你申请的内存大小,还大于这个最小的空闲块,那么就有必要分割一下了,整个过程还是挺简单的,分一个大一个小的,多出来的那个插入链表

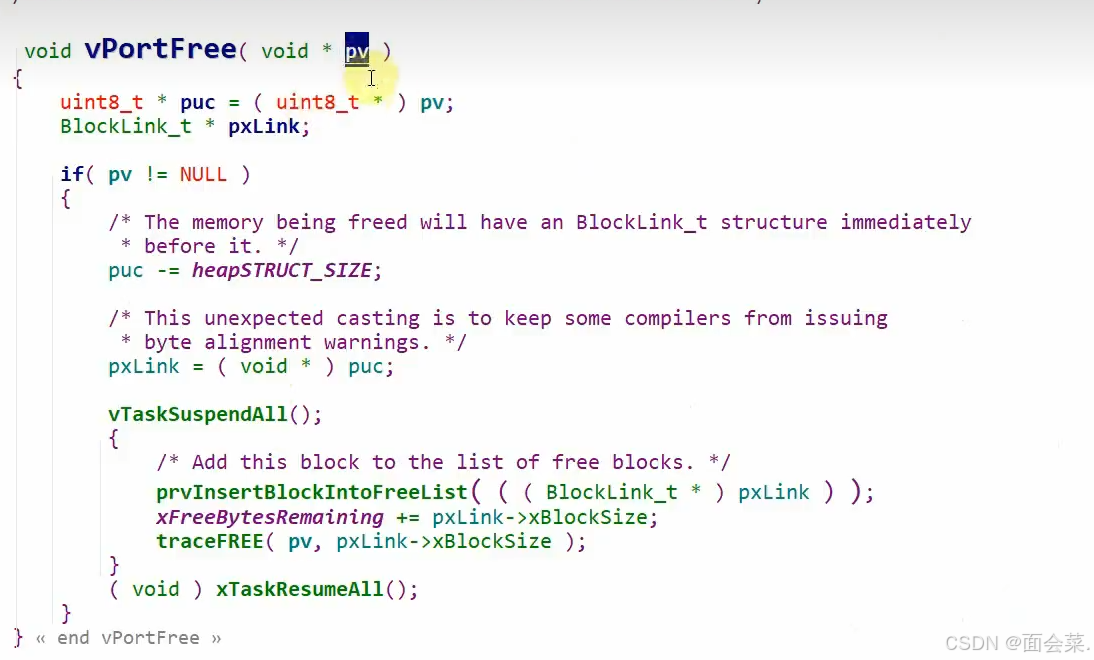
最后我们看看内存怎么回收,RTOS是怎么实现Free函数的,我们传入的参数的地址是申请块大小的首地址也是头部的末尾地址,减去头部内存大小就是头部的地址,根据头部地址我们就能得到一个结构体,根据结构体里的信息我们就能直接插入链表中等待继续被申请使用
6、heap_3代码不分析
这不用说了,平常基本上不用这个,就是调用C语言库中的malloc和free,速度慢内存大,时间还不确定
7、heap_4代码分析
我们先分析一下heap_2的缺点,例如说我申请了一块800字节大小的空间,遍历整个链表结果没有符合我要求的空闲块,但是我总共的空闲块空间大小加起来就足够的,这就是碎片化的缺点
以前在heap_2中是按照大小进行空闲块的排序,那么在heap_4中需要合并相邻的空闲块所以就需要使用地址进行排序,另外他们的初始化也不太一样,在heap_2中xEnd是个结构体,而在heap_4中xEnd是个指针指向堆空间的尾部
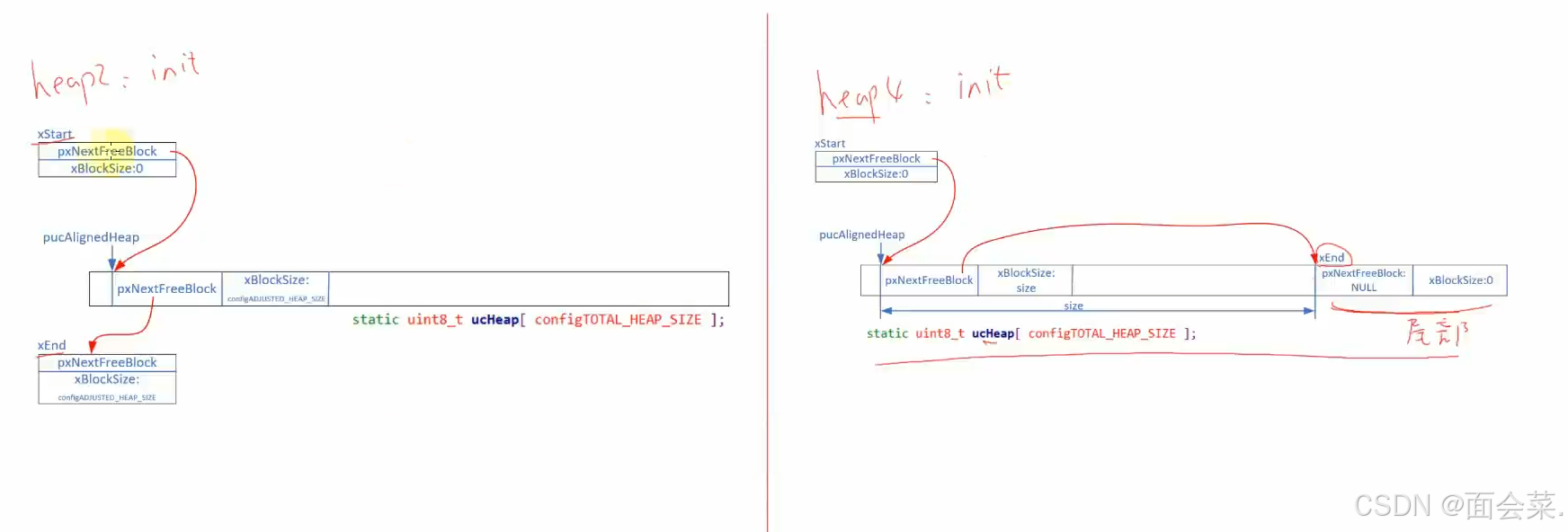
首先第一步还是初始化堆,照样老流程先对齐字节然后让链表头指向堆,这回是链表尾指向堆的结尾了,而不是堆的结尾指向链表尾部了,下面有一部分是统计信息用的不用管,最后一句话有点意思,他有点类似于标志位,来判断这个堆是否被使用,如果使用某一位地址就变成1,是经过下面这段话计算的,释放后就变成0,在Free函数中会通过这个来判断,防止重复释放
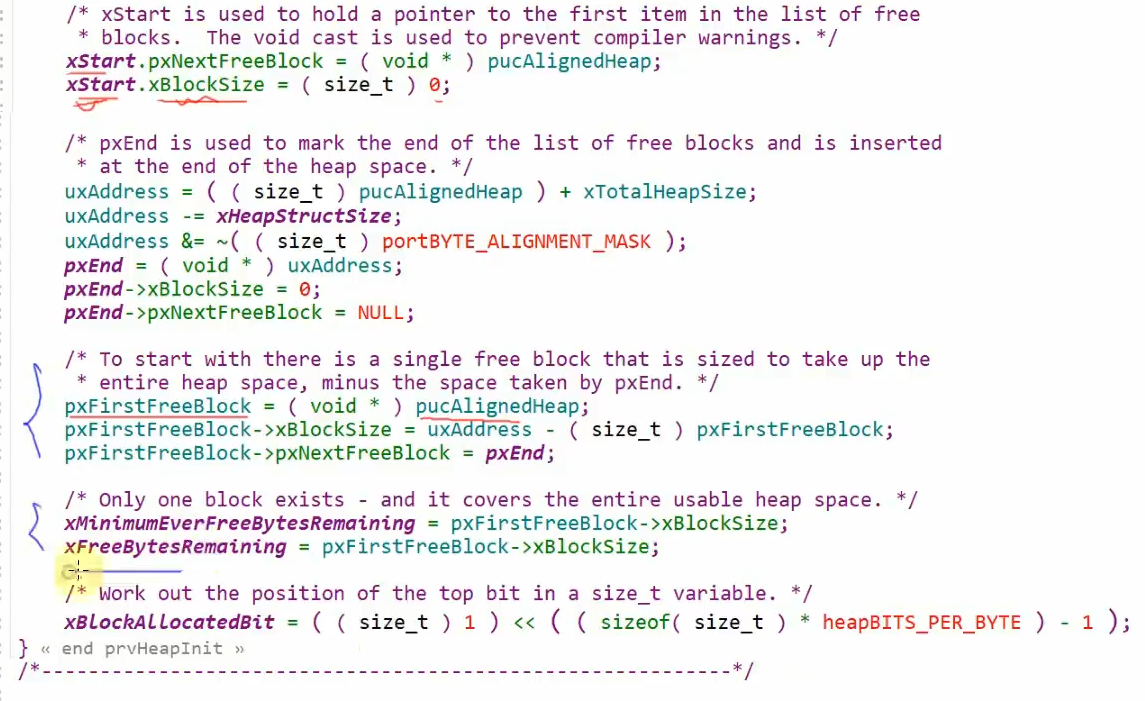
这部分代码首先先判断,我根据上文提到的标志位来判断是否还存在可用的空闲块,如果有那么往下就计算我整个分配内存空间的大小,再进行一些对齐的操作,跟前面流程都一样
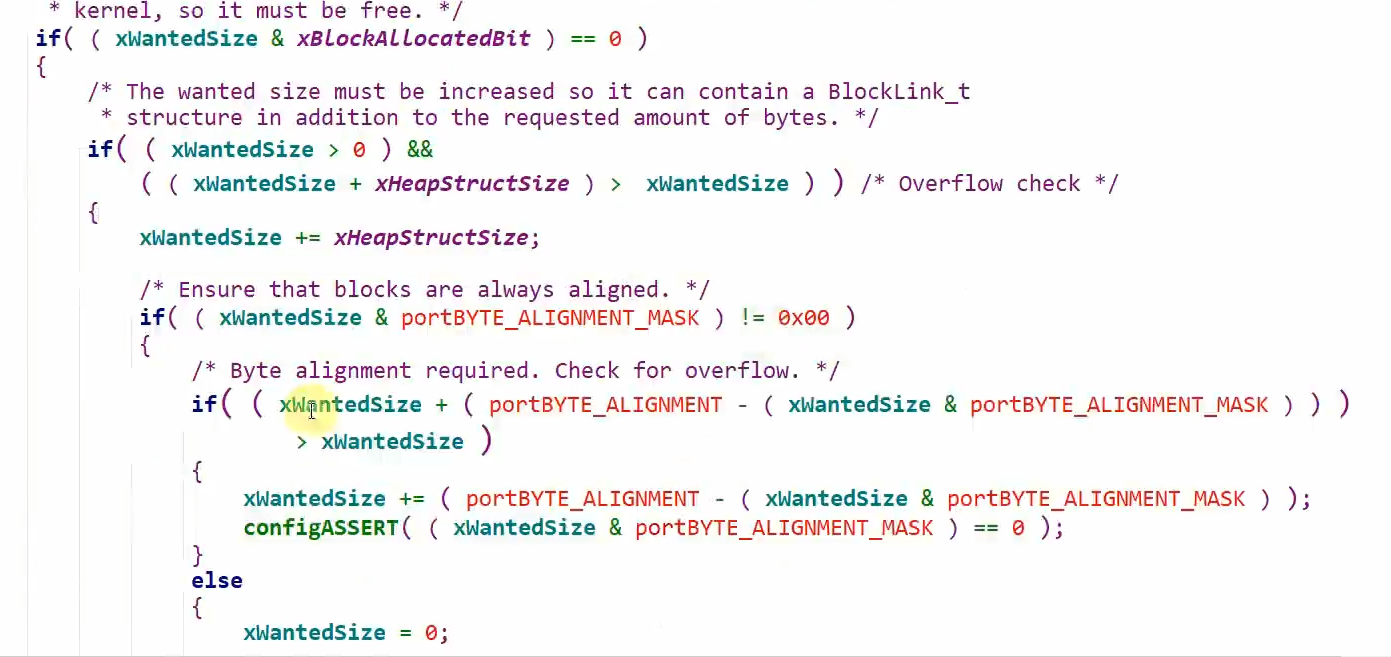
然后我们计算完了最终的大小之后,就开始从链表头轮询了,查找符合我们要求的空闲内存块,找到block之后分配内存的方式和heap_2一样就不多赘述了,删除链表插入链表之类的
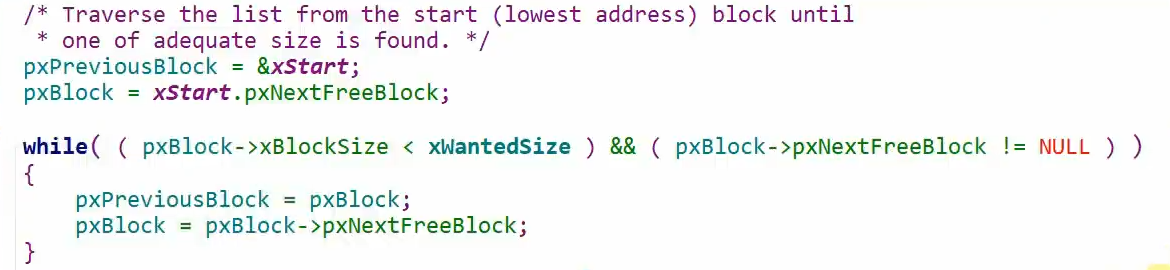
接下来我们讲解一下Free函数,因为我们知道heap_4和heap_2他们链表排序的方式不太一样,heap_4是根据地址来的,heap_2是根据大小来的,那么我此刻想插入一个新的空闲块,就得根据这个空闲块的地址,遍历链表寻找符合条件的位置插入,那么条件是什么,首先我这个地址需要大于前面的地址小于后面的地址,此刻就符合条件可以插入,如果此刻地址是相邻的,那么这三块空闲块就可以合并成一个
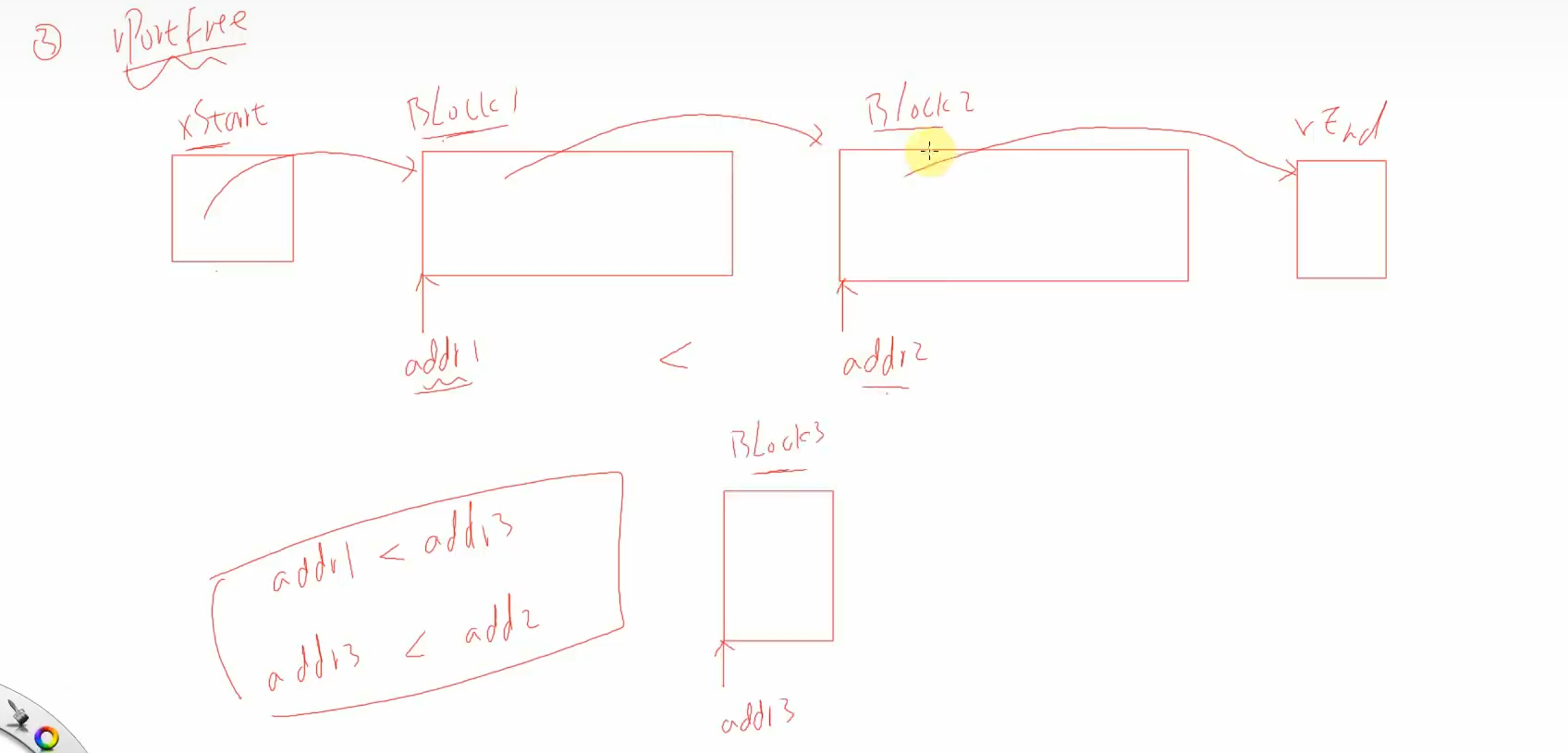
我们传入的pv指针指向空闲块开头的部分而不是头部这一点没有忘记吧,所以我们把pv指针的地址赋值给puc再用它减去头部的大小,指向的就是头部开头的地址,就可以通过访问头部来获取到信息了,下面判断位数的操作前面已经讲过了,这是一层保险,防止重复调用,然后我们就需要去操作链表,流程和之前都是一样的,其中操作链表插入的这一部分才算比较重要的内容,也是heap_4区别于heap_2最大的地方,那就是合并空闲内存块
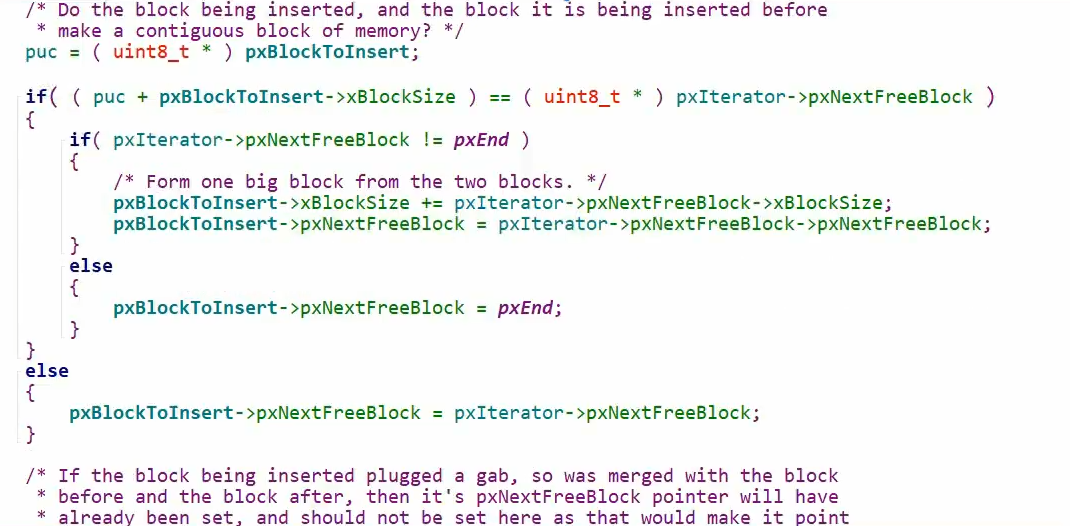
这就是heap_4最重点的地方,这第一个for循环就是我们之前提到过的,寻找插入位置的办法,我要插入的地址必须大于插入地址前面那个小于插入地址后面那个,然后就跳出循环了,首先我们这个puc指针指向我插入内存块的前一个的首地址,它的首地址加上自己内存块的大小如果等于我插入的这个新的内存块的首地址,那么两个内存块就可以合并,让前面的内存块把我新插入的内存块吞掉,也就是把前面的内存块大小设置成两个内存块加起来的大小,让地址指向前面的内存块,此刻合并就完成了,如果不相邻就正常插入链表,前面指针指向我新插入的这个,最后再判断一下我新合并的或者新插入的块能否与后面的合并



















 9687
9687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









