






1、新建python文件
2、获取网页地址(百度、抖音、微博等)
3、打开开发者模式(F12)
3、复制网页cURL地址
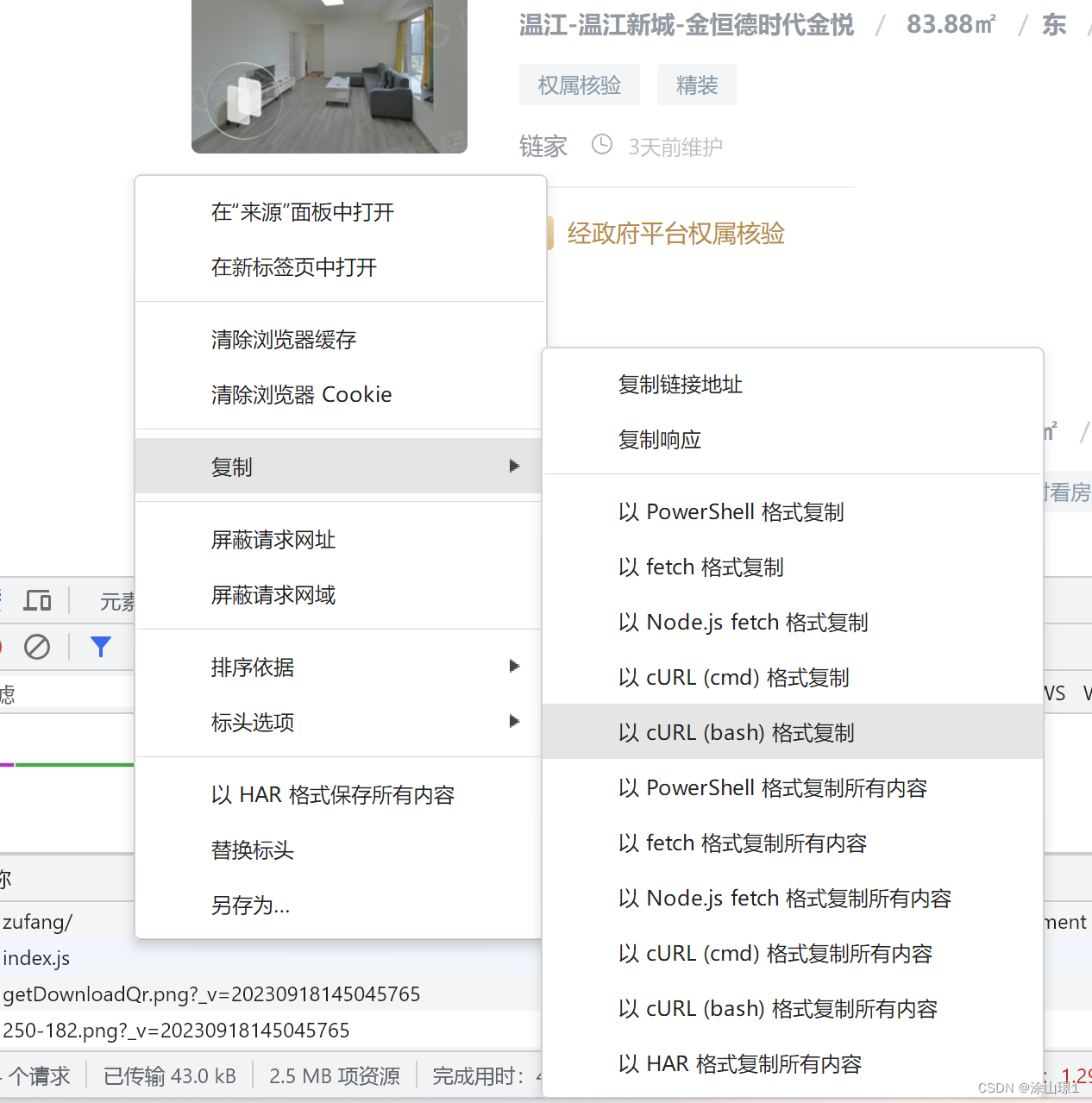
4、打开解析网页粘贴cURL内容(解析网页:https://curlconverter.com/)
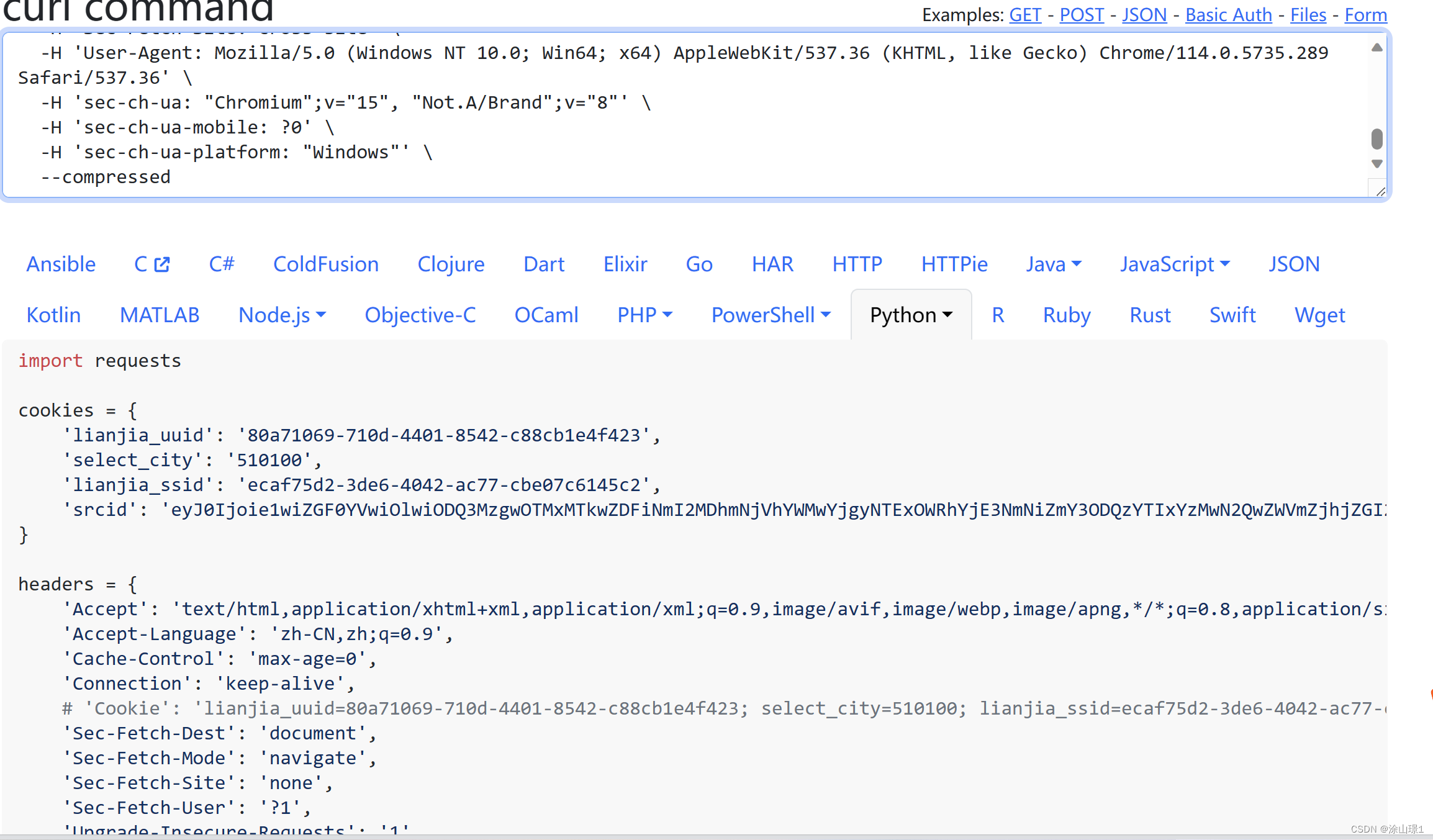
5、把解析内容(表头headers)复制在python文件中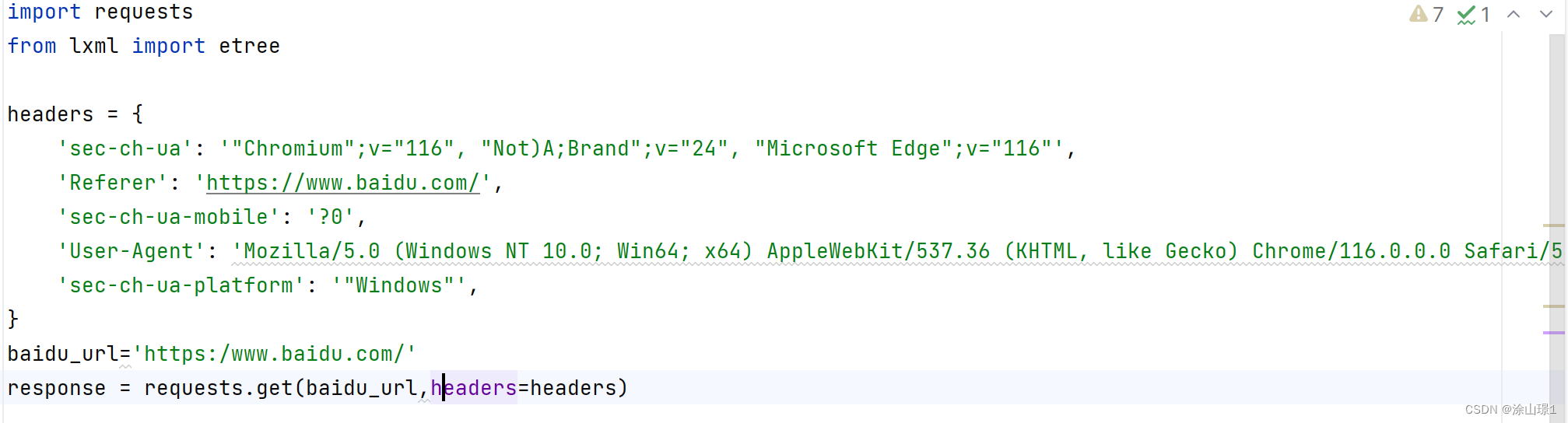
6、打印状态码
print(response.status_code)7、在此之前我们先要导入lxml库的etree包,使用etree来解析网页数据
#导入etree包
from lxml import etree
#使用etree解析网页
selector = etree.HTML(response.text)8、在网页中定位想要爬取的数据
9、获取爬取数据的xpath路径并粘贴在python标签内容中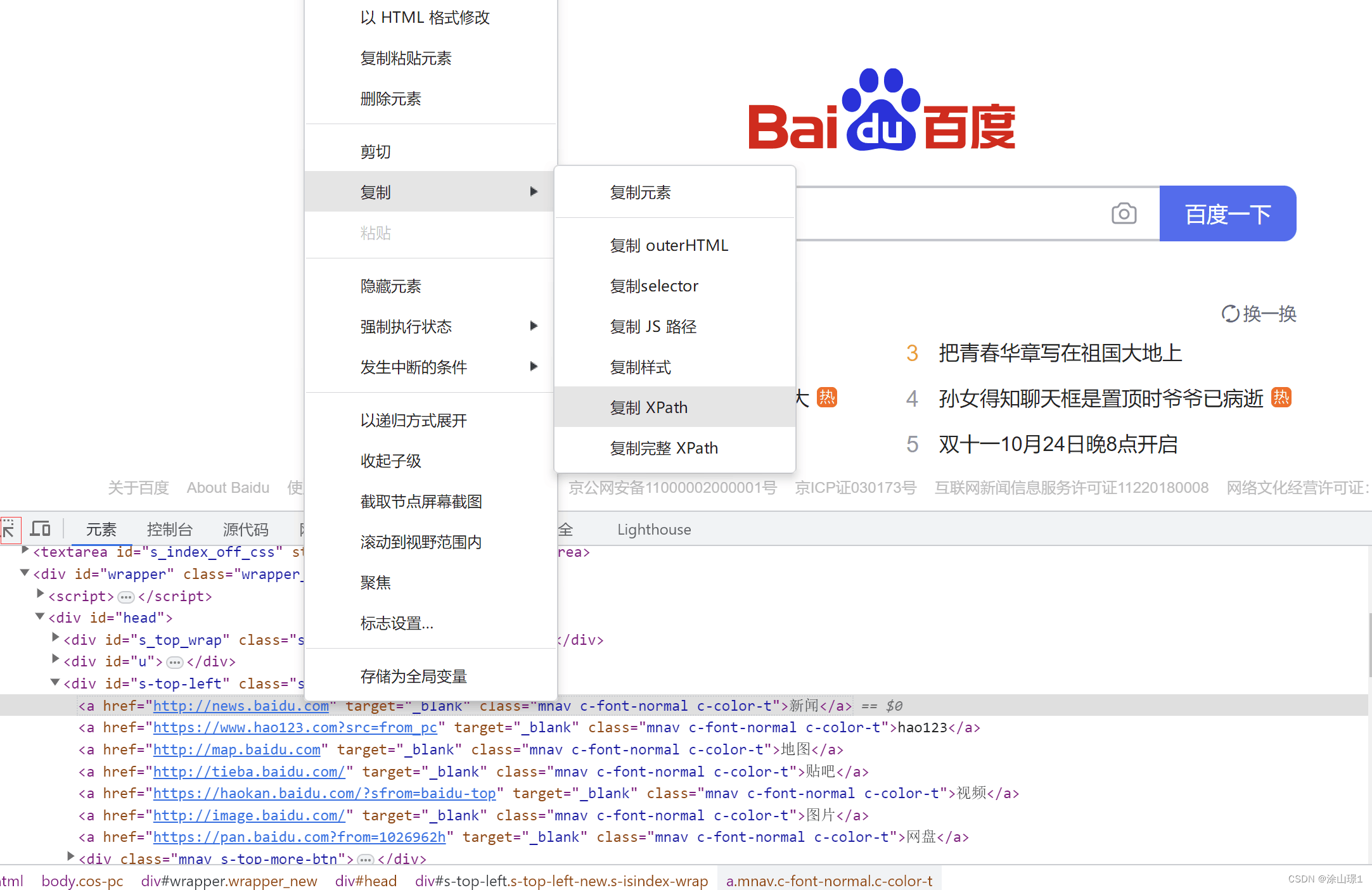
10、最后打印标签内容
import requests
from lxml import etree
headers = {
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'Referer': 'https://www.baidu.com/',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.76',
'sec-ch-ua-platform': '"Windows"',
}
baidu_url='https:/www.baidu.com/'
response = requests.get(baidu_url,headers=headers)
print(response.status_code)
selector = etree.HTML(response.text)
news_text = selector.xpath('//*[@id="s-top-left"]/a[1]/a[1]/text()"]')[0]
print(news_text)














 3783
3783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









