






import pandas as pd
from sklearn.preprocessing import MultiLabelBinarizer
data=pd.read_csv("C:/Users/zlx/Desktop/jupyter/A1-F3(100-2).csv",index_col=False,encoding="gb18030")
labels=["Y","Y1"]
mlb=MultiLabelBinarizer()
encoded_labels = mlb.fit_transform(data[labels].apply(lambda x:",".join(x),axis=1).str.split(","))
#上边这一行是将data[labels]中每个元素用逗号连接起来,然后用str.split(",")将字符串拆成列表,最后用mlb.fit_transform方法将列表转换成二进制编码
encoded_df=pd.DataFrame(encoded_labels,columns=mlb.classes_)
print(encoded_df)
普通数据的多标签分类,需要将多标签进行编码,转换成二进制。假设有有1000个样本,每个样本有四个特征,每个样本有两个标签,第一个标签有六类,第二个有十六类,可以使用上述的代码将其转换成二进制,可以直接用于多标签分类
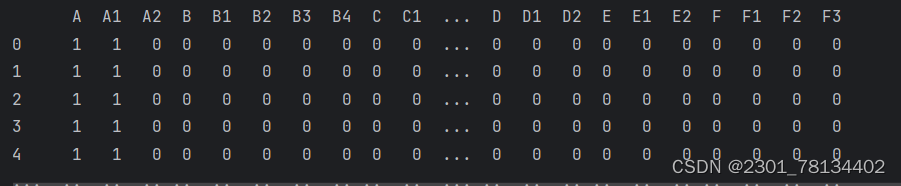 随机森林多标签分类
随机森林多标签分类
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
data =pd.read_csv("C:/Users/zlx/Desktop/jupyter/A1-F3(100-2).csv")#这里是我自己的文件名
X=data[["GL","AL","BL","BDCL"]]#这些是每个样本不同的特征列
Y=encoded_df#这里是二进制编码
x_train,x_test,y_train,y_test=train_test_split(X,Y,random_state=4,train_size=0.9)
rf=RandomForestClassifier(n_estimators=100,random_state=42)
rf.fit(x_train,y_train)
y_pred=rf.predict(x_test)
acc=accuracy_score(y_test,y_pred)
print(acc)
print(classification_report(y_test,y_pred))
这里正确率在classification_report 中不会出现,需要自己加进去
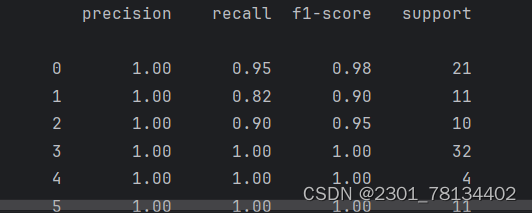
在这里最左侧的一列数字的每一行与二进制编码的每一列相对应,也就是数字0为类别A,数字1为类别A1















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









