






如果你正在学习Python,那么你需要的话可以,点击这里👉Python重磅福利:入门&进阶全套学习资料、电子书、软件包、项目源码等等免费分享!
前言介绍
在数据分析和信息获取领域,天气数据是一个常见且重要的数据源。通过Python编程,我们可以高效地爬取天气数据,用于各种应用场景,如气象分析、旅行规划、农业决策等。Python提供了丰富的库和工具,使得这一过程变得相对简单。本文将介绍如何使用Python爬取天气数据,包括所需的库、API接口的选择、数据请求与解析等关键步骤。
一、目标页面url
▋目标页面url获取
想要获取某地的历史天气数据,比如想要获取烟台的历史天气数据。页面地址https://lishi.tianqi.com/yantai/201101.html,页面部分区域截图如下,
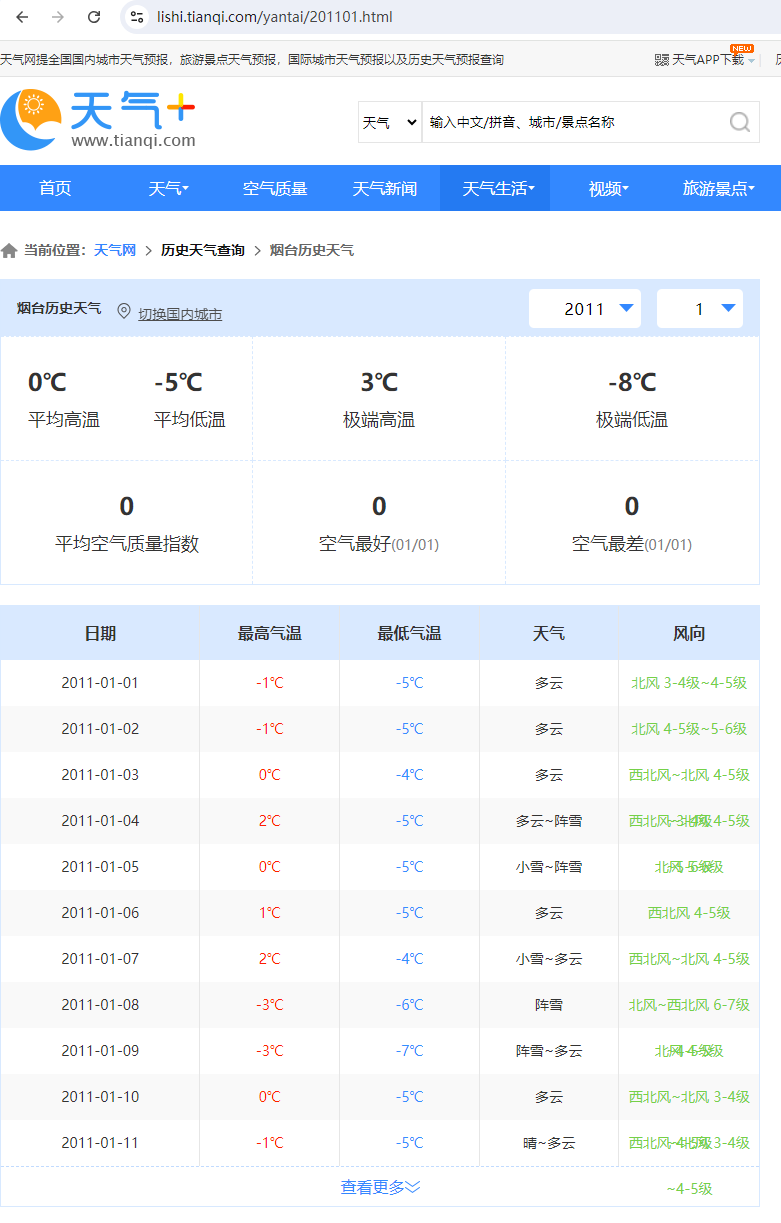
可以看到想要获取的天气数据,在页面上是以一个表格的形式展示的,我们需要获取其中的日期、最高气温、最低气温、天气和风向等数据。
根据页面地址可以分析出其组成规则,即以https://lishi.tianqi.com/+地区名称拼音+年份月份+.html组合成页面地址url。
思路:遍历循环年份和月份,拼装成一系列年份月份天气数据的页面地址url,以供后续访问。
代码实现:
for year in range(2011,2025):
for month in range(1,13):
if month < 10:
print(f"http://lishi.tianqi.com/yantai/{year}0{month}.html")
else:
print(f"http://lishi.tianqi.com/yantai/{year}{month}.html")以上代码片段执行结果部分截图,如下,
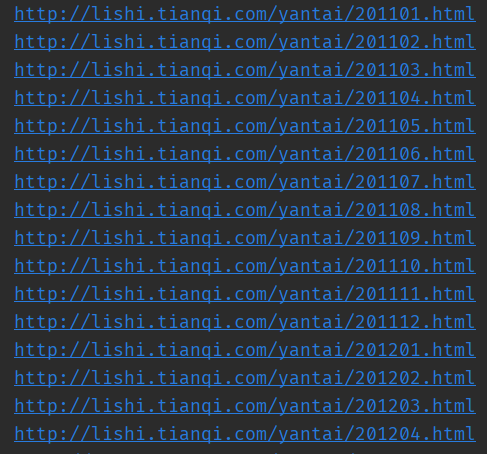
如图所示,我们需要爬取的历史天气数据所在页面的url就已经拼装好了。历史天气数据时间范围从201101~202412。
二、目标页面结构分析与数据获取
▋目标页面结构分析
接上,继续以烟台地区2011年01月份的历史天气数据页面(http://lishi.tianqi.com/yantai/201101.html)为例,分析其页面结构。
打开浏览器开发者工具,检查页面元素,
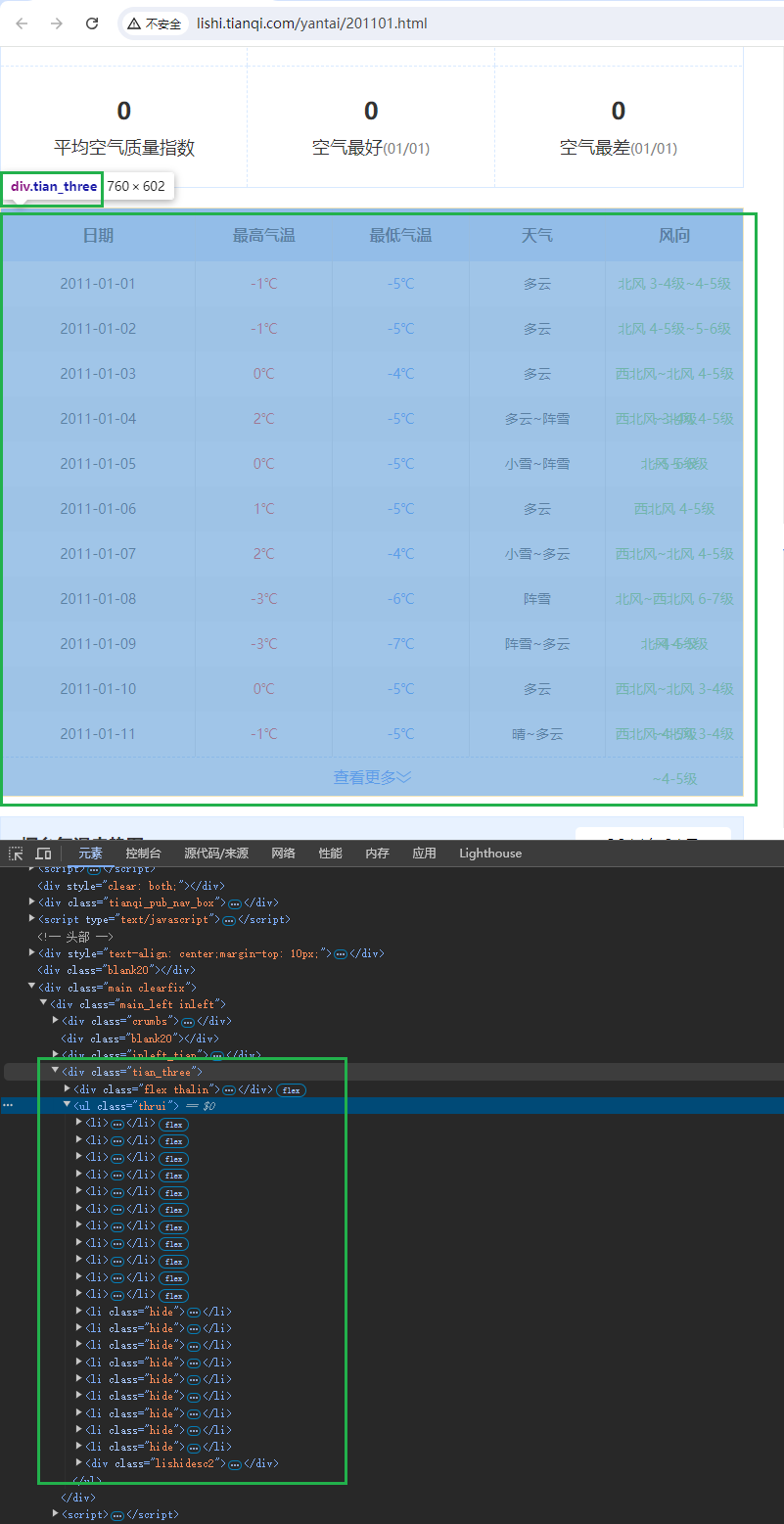
可以明确天气数据在页面结构中的位置,接下来我们会使用BeautifulSoup模块来提取目标数据。
▋目标页面历史天气数据获取
安装BeautifulSoup模块后,使用requests模块请求url,解析返回页面元素,处理元素数据,直至提取出目标数据。
import requests
from bs4 import BeautifulSoup
url = 'http://lishi.tianqi.com/yantai/201101.html'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
tianqi_zone = soup.find(class_='tian_three')
tianqi_data = tianqi_zone.find(class_='thrui')
tianqi_data_a_month = tianqi_data.find_all('li')
for tianqi_data_a_day in tianqi_data_a_month:
print(tianqi_data_a_day.text.split())代码执行结果如下,
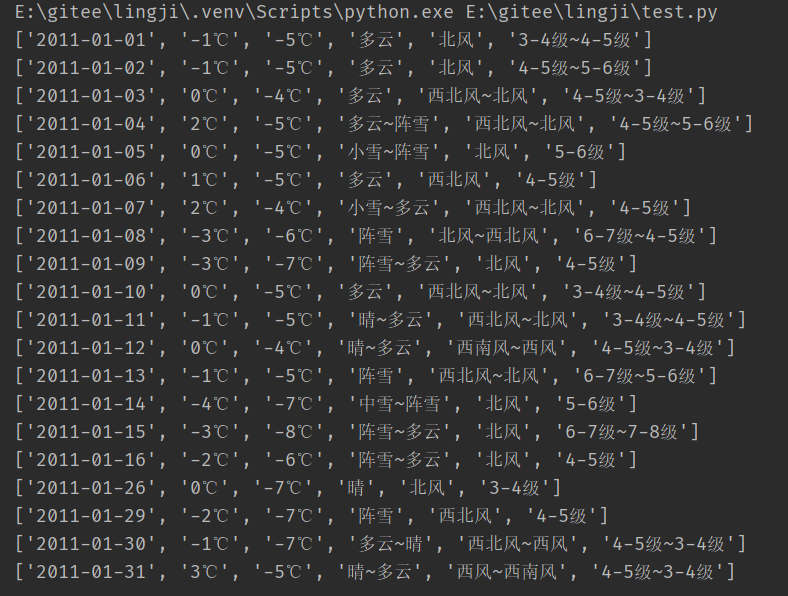
从执行结果中可以看出,成功提取到烟台在2011年1月份的天气数据,包括日期、最高气温、最低气温、天气和风向数据。
三、保存至本地
▋使用pandas模块保存数据至本地
使用pandas模块把爬取的天气数据保存至本地excel文件中,代码略作变更,代码实现如下,
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'http://lishi.tianqi.com/yantai/201101.html'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
tianqi_zone = soup.find(class_='tian_three')
tianqi_data = tianqi_zone.find(class_='thrui')
tianqi_data_a_month = tianqi_data.find_all('li')
a_month = [tianqi_data_a_day.text.split() for tianqi_data_a_day in tianqi_data_a_month]
print(a_month)
a_month_df = pd.DataFrame(a_month,
columns=['日期', '最高温度', '最低温度', '天气', '风向', '风力'])
a_month_df.to_excel('a.xlsx', index=False)其中print(a_month)打印出的结果如下,
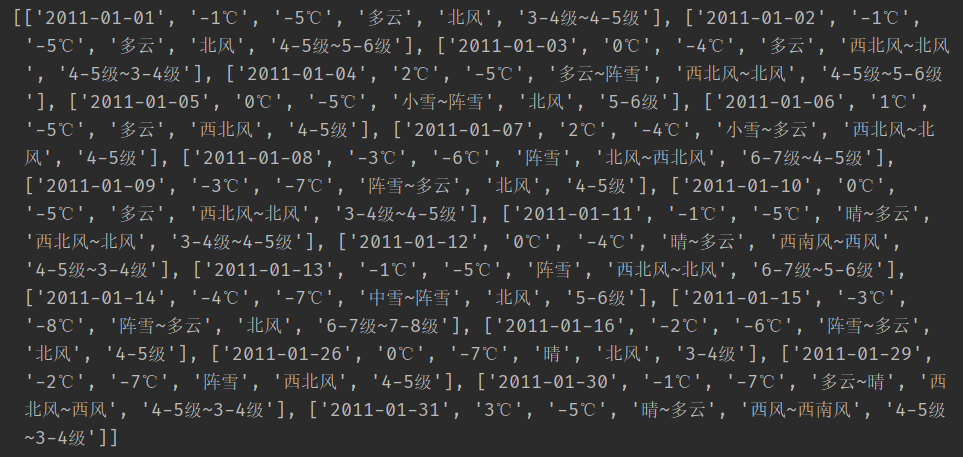
二维嵌套列表,转换成df数据类型后保存至本地的a.xlsx文件中。
四、完整代码以及项目信息
▋完整代码
以上小节中只保存了一个月的历史天气数据,想要保存近10年的历史数据,需要依次访问不同年份月份的url,爬取数据,依次保存至本地excel中。
完整代码如下,仅供参考,
import requests
from bs4 import BeautifulSoup
import pandas as pd
def save_a_month_data(url):
"""
保存一个月的天气历史数据,即一个页面中的数据
:param url: 页面url 保存有某年某月的月数据所在的页面
:return: 返回当月的二维天气数据列表
"""
# 返回的当月的天气数据列表a_month
a_month = []
# 请求头
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"}
# 请求url,响应r
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
tianqi_zone = soup.find(class_='tian_three')
try:
tianqi_data = tianqi_zone.find(class_='thrui')
except AttributeError:
print(tianqi_zone)
return a_month
tianqi_data_a_month = tianqi_data.find_all('li')
# 当月天气历史数据的处理
for tianqi_data_a_day in tianqi_data_a_month:
len_a_day_data = len(tianqi_data_a_day.text.split())
if len_a_day_data == 7:
a_day_data = tianqi_data_a_day.text.split()
a_day_data.remove(a_day_data[1])
a_month.append(a_day_data)
else:
a_month.append(tianqi_data_a_day.text.split())
return a_month
# 所有的历史数据保存变量 all_data
all_data = []
# 遍历201101~202412之间的所有历史数据
for year in range(2011, 2025):
for month in range(1, 13):
if month < 10:
url = f"http://lishi.tianqi.com/yantai/{year}0{month}.html"
# print(url)
a_month_data = save_a_month_data(url)
all_data += a_month_data
else:
url = f"http://lishi.tianqi.com/yantai/{year}{month}.html"
# print(url)
a_month_data = save_a_month_data(url)
all_data += a_month_data
df = pd.DataFrame(all_data)
# 保存所有的天气历史数据至本地excel文件中
df.to_excel('a.xlsx', index=False)以上完整代码在2024年8月16日验证可用。
▋项目相关信息
项目使用Python 3.10.6,以及依赖的模块版本如下,
requests==2.32.2
beautifulsoup4==4.12.3
pandas==2.2.2总结
通过Python编程,我们可以高效地爬取天气数据,并将其用于各种应用场景。在爬取过程中,我们需要选择合适的天气数据提供商和API接口,安装必要的Python库,发送网络请求并解析数据,处理异常和错误,以及保存和可视化数据。这些步骤构成了Python爬取天气数据的完整流程。
需要注意的是,在爬取天气数据时,我们需要遵守相关法律法规和提供商的使用协议,不得进行恶意爬取或滥用数据。同时,我们也需要关注数据的准确性和时效性,以便为后续的分析和决策提供可靠依据。
如果你正在学习Python,那么你需要的话可以,点击这里👉Python重磅福利:入门&进阶全套学习资料、电子书、软件包、项目源码等等免费分享!或扫描下方CSDN官方微信二维码获娶Python入门&进阶全套学习资料、电子书、软件包、项目源码:

















 2530
2530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









