






目录
一、项目背景与主要目的
这个项目旨在创建一个基于自然语言处理的简单问答系统,用户可以输入问题,系统会尝试从预先定义的问答数据中找到最匹配的答案进行回复。项目使用了Flask作为后端框架,结合TensorFlow和TensorFlow Hub中的预训练模型(Universal Sentence Encoder)来实现语义理解和文本嵌入功能。
二、项目实现概述
1.问答数据的准备:
使用一个文本文件(例如'QA.txt'),其中每一行包含一个问题和对应的答案,格式为(问题::答案),如图所示:

通过load_qa_pairs函数读取文件,解析成问题-答案对。
2、代码的实现过程
(1)必要库的导入
from flask import Flask, request, jsonify, render_template
import re
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text(2)初始化一个 Flask 应用程序对象
app = Flask(__name__)(3)读取问题与答案数据
def load_qa_pairs(filename):
qa_pairs = []
with open(filename, 'r', encoding='utf-8') as file:
for line in file:
if line.strip(): # 确保不是空行
parts = re.split(r'::', line.strip(), maxsplit=1)
if len(parts) == 2:
question, answer = parts
qa_pairs.append((question.strip(), answer.strip()))
else:
print(f"Warning: Invalid line format: {line.strip()}")
return qa_pairs
(4)文本嵌入的生成
使用Google的Universal Sentence Encoder(多语言大型版本)作为文本嵌入模型。这个模型能够将文本转换为多维度的向量表示,捕捉语义上的相似性。
# 使用BERT模型进行文本嵌入
def get_bert_embeddings(texts):
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3")
embeddings = embed(texts)
return embeddings
(5)问答处理功能:
respond函数接收用户的问题,首先将问题转换成BERT嵌入向量。然后计算用户问题与预先嵌入的所有问题的余弦相似度,找到最接近的问题的答案。如果相似度低于设定的阈值(此处设为-0.5),则回答"抱歉,我不明白你的问题。"
# 简单的问答处理函数
def respond(question, qa_pairs, qa_embeddings):
question_embedding = get_bert_embeddings([question])
similarities = tf.keras.losses.cosine_similarity(question_embedding, qa_embeddings)
closest_index = tf.argmin(similarities).numpy()
if similarities[closest_index].numpy() < -0.5: # 调整阈值以适应需求
return qa_pairs[closest_index][1]
else:
return "抱歉,我不明白你的问题。"
(6)Flask应用程序:
使用Flask框架建立Web应用程序。主页渲染为一个简单的HTML页面(通过render_template),用户可以在此页面输入问题。后端通过POST请求接收用户的问题,调用respond函数生成回复,并返回JSON格式的响应。
# 加载QA数据和预计算的嵌入
filename = 'QA.txt'
qa_pairs = load_qa_pairs(filename)
questions = [q for q, a in qa_pairs]
qa_embeddings = get_bert_embeddings(questions)
@app.route('/')
def home():
return render_template('index.html')
@app.route('/get_response', methods=['POST'])
def get_response():
data = request.get_json()
user_question = data['question']
response = respond(user_question, qa_pairs, qa_embeddings)
return jsonify({'response': response})
if __name__ == "__main__":
app.run(debug=True)(7) 使用Flask框架的选择和介绍
基础架构和用途: Flask 是一个轻量级的 Web 框架,专注于简单性和可扩展性,适合快速开发小型到中型的 Web 应用程序。它基于 Python,并提供了灵活的扩展性和易于理解的文档。Flask 不像其他大型框架(如Django)提供了强大的ORM、认证等功能,而是更专注于核心的路由、请求/响应处理和模板渲染。
选择原因:
- 轻量级和灵活性: 对于简单的问答系统,不需要复杂的 ORM 或者大型的开发团队,Flask 提供了足够的功能,并且易于上手和部署。
- Python 的一致性: 因为你的模型和数据处理都是在 Python 中完成的,使用 Flask 可以直接集成这些组件,避免了语言切换的复杂性。
- RESTful API 支持: Flask 能够很方便地创建 RESTful API,这对于前后端分离的应用来说非常适合。
其他框架的尝试和对比:
- Django: 功能更全面,包括自带的 ORM、认证系统等,但对于这个简单的问答系统可能显得过于笨重。
- FastAPI: 基于 Python 的现代、高性能的框架,适合需要高吞吐量的应用,但在这种简单场景下可能过于复杂。
- Starlette:这是一个轻量级的异步框架,特别设计用于构建高性能的 Web 服务。它提供了基本的工具和构建块,可以灵活地扩展和定制,适合于需要响应速度和高并发处理的应用场景。在简单的问答系统中,Starlette可以提供良好的性能和灵活性,但需要更多的自定义工作。
(8)超参数的调整和影响
在这个项目中,主要用到了预训练的多语言 Universal Sentence Encoder,其超参数已经在预训练过程中进行了优化。对于使用者来说,主要需要调整的可能是阈值 -0.5,用于确定最匹配的问题。通过调整这个阈值可以影响系统的回答精确度和模糊度。
3、项目文件结构说明
QA.txt:包含预定义问题和答案的文本文件。
app.py:Flask应用程序的主文件,包含了路由和主要的问答逻辑。
templates/index.html:前端页面,用于用户输入问题和显示回复。
4、前端交互流程
以下是问答系统前端的详细代码:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>问答系统</title>
<style>
/* 原有的 CSS 样式 */
.history {
margin-top: 20px;
padding: 10px;
border: 1px solid #ddd;
border-radius: 4px;
background-color: #fafafa;
max-height: 200px;
overflow-y: auto;
}
.history p {
margin: 5px 0;
}
</style>
</head>
<body>
<div class="container">
<h1>问答系统</h1>
<div class="input-group">
<input type="text" id="question-input" placeholder="请输入您的问题">
<button onclick="getResponse()">发送</button>
</div>
<div class="response" id="response-output"></div>
<div class="history" id="history-output"></div>
</div>
<script>
async function getResponse() {
const question = document.getElementById('question-input').value;
const responseOutput = document.getElementById('response-output');
const historyOutput = document.getElementById('history-output');
const response = await fetch('/get_response', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ question: question })
});
const data = await response.json();
responseOutput.textContent = data.response;
// 更新问答记录
const historyEntry = document.createElement('p');
historyEntry.textContent = `问题: ${question}, 回答: ${data.response}`;
historyOutput.prepend(historyEntry);
}
</script>
</body>
</html>
实现结果的前端页面为:
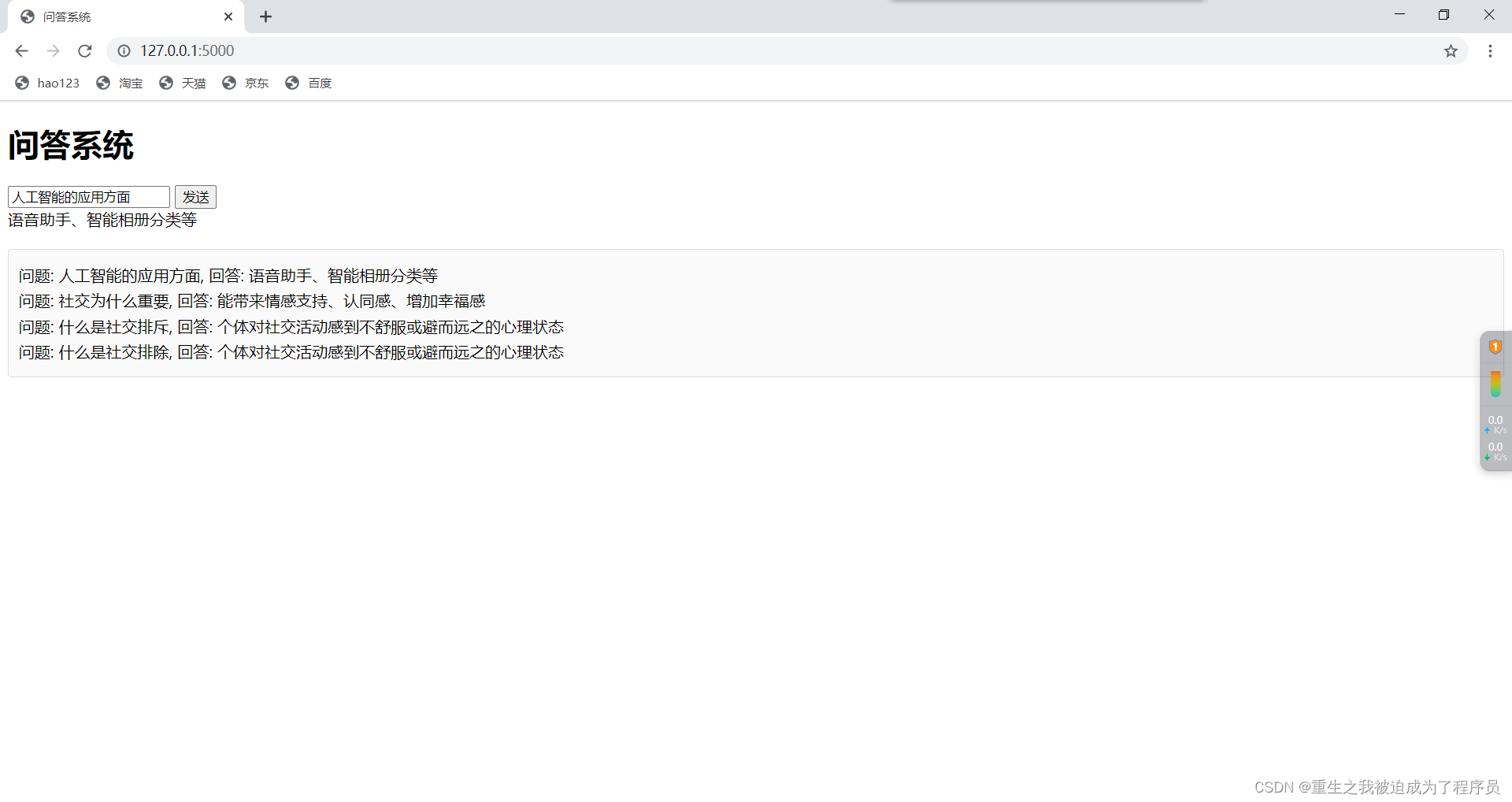
通过这个前端页面,还可以还出对于提问的问题我们还设置了问答记录。
三、项目流程说明
| 项目背景与主要目的 | 创建基于自然语言处理的问答系统,用户输入问题,系统返回最匹配的预定义答案。 |
| 技术实现概述 | 使用Flask作为后端框架,结合TensorFlow和Universal Sentence Encoder进行文本嵌入和语义理解。 |
| 问答数据的准备 | 从'QA.txt'加载问题和答案,格式为问题::答案。 |
| 文本嵌入的生成 | 使用Google的Universal Sentence Encoder生成多维度文本向量。 |
| 问答处理功能 | respond函数将用户问题转换成BERT嵌入向量,计算与预先嵌入问题的余弦相似度来选择最佳答案。 |
| Flask应用程序 | 建立Web应用,前端通过POST请求发送问题,后端返回JSON格式的回复。 |
| 项目文件结构 | QA.txt, app.py (Flask应用主文件), index.html (前端页面)。 |
| 前端交互流程 | 用户输入问题 -> 前端发送POST请求 -> 后端处理请求并返回JSON响应 -> 前端显示回复。 |
1、首页加载:
用户访问首页('/'),显示一个简单的界面,包含一个文本框和一个提交按钮。
2、用户输入问题:
用户在文本框中输入问题后,点击提交按钮。
3、前端发起请求:
前端通过JavaScript将用户输入的问题封装成JSON格式,通过POST请求发送给后端的/get_response端点。
4、后端处理请求:
Flask后端收到POST请求后,从JSON中提取用户问题,调用respond函数处理问题,并生成回复。
5、后端返回响应:
后端将生成的回复封装成JSON格式返回给前端。
6、前端显示回复:
前端接收到后端返回的JSON响应后,将回复显示在页面上,以便用户查看。
通过这种交互流程,用户可以简单地与问答系统进行交互,获取基于语义相似度的答案。
这个项目的核心在于利用现成的自然语言处理工具和技术,以简洁有效的方式实现一个基础的问答系统,为用户提供便捷的信息获取途径。

















 3732
3732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









